

【Ceph 】Async 通信会话建立过程--OSD--实际跟踪笔记
目录
with InfiniBand RDMA architecture
作于December 28, 2015,比较老,有一定的参考意义,但应该与现在的有一定差异。
一、前置知识
1、ceph Async 模型
ceph Async的IO 多路复用多线程模型
说明:
每个worker 有一个eventCenter,一条workerThread线程。workerpool管理着多个worker,AsyncConnection在创建时根据负载均衡绑定到对应的Worker中。

在Ceph Async模型里,一个Worker类对应一个工作线程和一个事件中心EventCenter。 每个socket对应的AsyncConnection在创建时根据负载均衡绑定到对应的Worker中,以后都由该Worker处理该AsyncConnection上的所有的读写事件。
2、Async Messenger机制图
图:
建立连接后的sd与worker的绑定
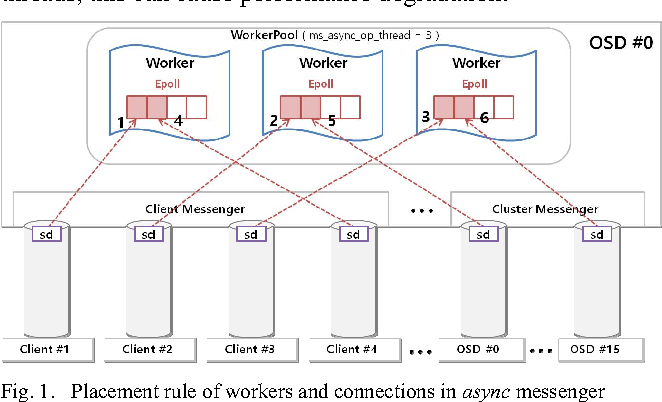
一个进程里只有一个workerpool,即使多个messager也是共享一个,里面包含有多个worker,一个worker一个thread,worker内一个eventcenter,eventcenter管理epoll

通信流图:

如图所示,在Ceph Async模型里,没有单独的main_loop线程,每个工作线程都是独立的,其循环处理如下:
- epoll_wait 等待事件
- 处理获取到的所有IO事件
- 处理所有时间相关的事件
- 处理外部事件
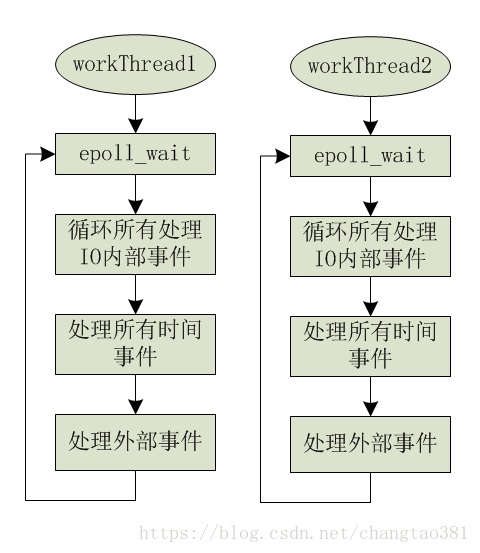
在这个模型中,消除了Half-sync/half-async的 队列互斥访问和 线程切换的问题。 本模型的优点本质上是利用了操作系统的事件队列,而没有自己去处理事件队列。
3、Async Messenger分层架构

NetworkStack 是单例模式,由AsyncMessenger创建,既由进程的第一个AsyncMessenger对象创建,后面的AsyncMessenger对象都再在创建而共用第一个对象创建的NetworkStack,所以上图画的AsyncMessenger和NetworkStack平行。
二、代码跟踪
研究对象:源码在文件src/ceph_osd.cc。
1、Server
服务端需要监听端口,等待连接请求到来,然后接受请求,建立连接,进行通信。
先来看核心代码
int main(int argc, const char **argv)
{
……
messenger = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::MON(-1),
"simple_server",
0 /* nonce */,
0 /* flags */);
……
r = messenger->bind(bind_addr); //posix中= (bind+listen)
……
messenger->start();
messenger->wait(); // can't be called until ready()
……
}
外观模式:
Simple、async“外观上”都是
messenger create –> bind->start-> wait
和socket相似
socket-->bind-->listen-->Epoll.wait
1)Initialization (create )
以osd进程为例,在进程启动的过程中,会创建Messenger对象,用于管理网络连接,监听端口,接收请求,源码在文件src/ceph_osd.cc:
int main(int argc, const char **argv)
{
......
// public用于客户端通信
Messenger *ms_public = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "client",
getpid());
// cluster用于集群内部通信
Messenger *ms_cluster = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "cluster",
getpid());
/*
Messenger *ms_hb_back_client = Messenger::create();
Messenger *ms_hb_front_client = Messenger::create();
Messenger *ms_hb_back_server = Messenger::create();
Messenger *ms_hb_front_server = Messenger::create();
Messenger *ms_objecter = Messenger::create();
*/
......
}
生成messenger用了工厂模式:
//src/msg/Messenger.cc
Messenger *Messenger::create(CephContext *cct, const string &type,
entity_name_t name, string lname,
uint64_t nonce)
{
......
// 在src/common/config_opts.h文件中,目前需要配置async相关选项才会生效
// OPTION(enable_experimental_unrecoverable_data_corrupting_features, OPT_STR, "ms-type-async")
// OPTION(ms_type, OPT_STR, "async")
else if ((r == 1 || type == "async") &&
cct->check_experimental_feature_enabled("ms-type-async"))
return new AsyncMessenger(cct, name, lname, nonce);
......
return NULL;
}类AsyncMessenger的构造函数需要注意,虽然在osd进程的启动过程中,会创建6个messenger,但是他们全部共享一个StackSingleton(内含NetworkStack指针), 函数lookup_or_create_singleton_object保证只会创建一个StackSingleton,因为传入的名称"AsyncMessenger::NetworkStack::"+transport_type是一样的:
| AsyncMessenger::AsyncMessenger(CephContext *cct, entity_name_t name, // 创建单例的StackSingleton,(内含NetworkStack指针) cct->lookup_or_create_singleton_object<StackSingleton>(single, "AsyncMessenger::NetworkStack::"+transport_type); |
下面的代码生成StackSingleton, if (!_associated_objs.count(name))下面的代码保证了同名的 StackSingleton只new一个
template<typename T>
void lookup_or_create_singleton_object(T*& p, const std::string &name) {
ceph_spin_lock(&_associated_objs_lock);
if (!_associated_objs.count(name)) {
p = new T(this);
_associated_objs[name] = new TypedSingletonWrapper<T>(p);
} else {
TypedSingletonWrapper<T> *wrapper =
dynamic_cast<TypedSingletonWrapper<T> *>(_associated_objs[name]);
assert(wrapper != NULL);
p = wrapper->singleton;
}
ceph_spin_unlock(&_associated_objs_lock);
}另外需要注意,这个进程唯一的StackSingleton是在第一个创建的messenger(这里是AsyncMessenger)的构造函数分配的,但messenger的析构函数并不负责释放StackSingleton的内存,因为多个messenger共享, 一个messenger销毁了并不代表其他messenger也一定会销毁。
这个StackSingleton的指针存放在CephContext成员变量_associated_objs中, 因为daemon进程有一个全局唯一的CephContext,当CephContext析构的时候,会释放StackSingleton指针的内存。
NetworkStack在StackSingleton中创建:
struct StackSingleton {
CephContext *cct;
std::shared_ptr<NetworkStack> stack;
StackSingleton(CephContext *c): cct(c) {}
void ready(std::string &type) {
if (!stack)
stack = NetworkStack::create(cct, type);
}
~StackSingleton() {
stack->stop();
}
};对底层协议做了一次抽象,还是一样用了工厂模式
| std::shared_ptr<NetworkStack> NetworkStack::create(CephContext *c, const string &t) lderr(c) << __func__ << " ms_async_transport_type " << t << |
具体的stack-->PosixNetworkStack/RDMAStack/DPDKStack构造函数,子类构造函数给父类构造函数入参,(父类构造函数中创建若干(num)个worker)
src\msg\async\rdma\RDMAStack.cc
| RDMAStack::RDMAStack(CephContext *cct, const string &t): NetworkStack(cct, t) { if (!global_infiniband) global_infiniband = new Infiniband( cct, cct->_conf->ms_async_rdma_device_name, cct->_conf->ms_async_rdma_port_num); ldout(cct, 20) << __func__ << " constructing RDMAStack..." << dendl; dispatcher = new RDMADispatcher(cct, global_infiniband, this); unsigned num = get_num_worker(); for (unsigned i = 0; i < num; ++i) { RDMAWorker* w = dynamic_cast<RDMAWorker*>(get_worker(i)); w->set_ib(global_infiniband); w->set_stack(this); } ldout(cct, 20) << " creating RDMAStack:" << this << " with dispatcher:" << dispatcher << dendl; } |
在NetworkStack(cct, t)中创建worker
| NetworkStack::NetworkStack(CephContext *c, const string &t): type(t), started(false), cct(c) for (unsigned i = 0; i < num_workers; ++i) { |
一个osd进程只会有一个WorkerPool NetworkStack,那这个pool NetworkStack在初始化的时候干什么事情了?顾名思义,Worker的Pool,肯定是用来管理Worker的,NetworkStack中有 vector<Worker*> workers;成员, 构造函数中新建了Worker类的对象放入workers形成workerpool,而Worker类继承于线程类,肯定就是单独干活的线程,源码在文件src\msg\async\Stack.cc中:
| NetworkStack::NetworkStack(CephContext *c, const string &t): type(t), started(false), cct(c) |
class Worker : public Thread { // 继承线程类,说明Worker类单独包含线程
| class Worker : public Thread |
EventCenter :为了代码通用,这里单独抽象了一层出来,即EventCenter,用来管理各种事件的驱动,比如epoll, kqueue, select等。 源码在ceph-12.0.0\src\msg\async\Event.h:
class EventCenter {
......
FileEvent *file_events; // 所有io事件
EventDriver *driver; // 具体的驱动
map<utime_t, list<TimeEvent> > time_events; // 所有时间事件
......
};
// EventDriver接口
// epoll的驱动继承此接口,接口的实现就是对epoll三个系统调用epoll_create, epoll_ctl,epoll_wait的封装
class EventDriver {
public:
virtual ~EventDriver() {} // we want a virtual destructor!!!
virtual int init(int nevent) = 0;
virtual int add_event(int fd, int cur_mask, int mask) = 0;
virtual void del_event(int fd, int cur_mask, int del_mask) = 0;
virtual int event_wait(vector<FiredFileEvent> &fired_events, struct timeval *tp) = 0;
virtual int resize_events(int newsize) = 0;
};
class EpollDriver : public EventDriver {
int epfd; // epoll fd
struct epoll_event *events; // 等待事件的结构体指针,可以查看epoll相关资料
CephContext *cct;
int size;
......
};Worker构造函数中,调用了center的init函数,看看center.init干了些什么事情?
Worker(CephContext *c, WorkerPool *p, int i)
: cct(c), pool(p), done(false), id(i), center(c) {
center.init(InitEventNumber); // 初始化事件驱动, linux下实际上就是初始化了epoll相关的结构//EventCenter::init-->EpollDriver::int-->epoll_create
}
int EventCenter::init(int n)
{
......
driver = new EpollDriver(cct); // 新建一个驱动对象
int r = driver->init(n); // 初始化具体的驱动
int fds[2]; // pipe用来唤醒worker线程,worker阻塞在epoll_wait了,来一个事件,
//写pipe让epoll_wait返回(其他epoll监听的fd我们没途径去写),让worker去处理事件,后文会分析到
if (pipe(fds) < 0) {
lderr(cct) << __func__ << " can't create notify pipe" << dendl;
return -1;
}
notify_receive_fd = fds[0];
notify_send_fd = fds[1];
......
create_file_event(notify_receive_fd, EVENT_READABLE, EventCallbackRef(new C_handle_notify())); // 监听pipe的可读事件
return 0;
}
// 初始化epoll
int EpollDriver::init(int nevent)
{
events = (struct epoll_event*)malloc(sizeof(struct epoll_event)*nevent); // nevent就是Worker类中的InitEventNumber
memset(events, 0, sizeof(struct epoll_event)*nevent);
epfd = epoll_create(1024); // 获取一个epoll fd
size = nevent;
return 0;
}从osd进程,到AsyncMessenger类,接着到所有messenger共享的WorkerPool NetworkStack (NetworkStack内一个workers的worker池),然后初始化进程唯一pool NetworkStack的每个Worker,然后worker中借助于EventCenter统一管理所有事件, 并且初始化了具体的事件处理机制,如epoll,似乎所有工作已经就绪?
其实不然,首先,worker的线程并没有启动,其次,osd进程的messenger也并没有绑定到特定端口进行监听,所以osd启动的过程中,还得有其他步骤。
总结:
主要工作
创建messenger (aysnc/simple/xio)
|---> 创建StackSingleton
| |--->创建NetworkStack(RDMA/DPDK/POSIX)
| | |--->创建多个worker
| | | |--->EventCenter::init ( Worker(CephContext *c, unsigned i) : cct(c),……, center(c))
| | | | |--->创建EventDriver(EventCenter::driver = new xxxDriver),工厂模式-->(linux下就是EpollDriver)-->EpollDriver::init (EpollDriver::epfd =epoll_create)
| | | | |--->创建pipe,
| | |--->worker放入workers
2)Bind and Listen
在messenger创建以后,会设置策略以及限流的参数,接下来就会绑定地址,对网络层套接字的处理,比如socket/bind/listen/accept等,主要是通过类Processor来管理:
// 继续ceph_osd.cc代码
int main(int argc, const char **argv)
{
/*
Messenger *ms_public = Messenger::create()
Messenger *ms_cluster = Messenger::create()
……
*/
......
// 设置协议
ms_cluster->set_cluster_protocol(CEPH_OSD_PROTOCOL);
......
// 设置策略以及限流
ms_public->set_default_policy(Messenger::Policy::stateless_server(supported, 0));
ms_public->set_policy_throttlers(entity_name_t::TYPE_CLIENT,
client_byte_throttler.get(),
client_msg_throttler.get());
......
// 绑定地址
r = ms_public->bind(g_conf->public_addr);
if (r < 0)
exit(1);
r = ms_cluster->bind(g_conf->cluster_addr);
if (r < 0)
exit(1);
......
ms_public->start(); // 启动线程
......
err = osd->init(); // 这里很关键, 后文分析
......
ms_public->wait(); // 等待线程结束
......
}
int AsyncMessenger::bind(const entity_addr_t &bind_addr)
{
……
// bind to a socket
set<int> avoid_ports;
for (auto &&p : processors)
{
int r = p->bind(bind_addr, avoid_ports, &bound_addr);
if (r)
{
……
return r;
}
}
……
_finish_bind(bind_addr, bound_addr);
}
// processor的处理就是对socket API的封装:socket, bind, listen
// 创建套接字,绑定到特定端口,进行监听
int Processor::bind(const entity_addr_t &bind_addr,
const set<int> &avoid_ports,
entity_addr_t *bound_addr){
/* bind to port */
for (int i = 0; i < conf->ms_bind_retry_count; i++)
{
……
entity_addr_t listen_addr = bind_addr;
……
if (listen_addr.get_port())
{
worker->center.submit_to(worker->center.get_id(), [this, &listen_addr, &opts, &r]()
{
r = worker->listen(listen_addr, opts, &listen_socket);
}, false);
……
}
// It seems that binding completely failed, return with that exit status
……
}
*bound_addr = listen_addr;
return 0;
}
上面的worker在底层选择Posix/RDMA/DPDK是分别是PosixWorker/RDMAWorker/DPDKWorker
//ceph-12.0.0\src\msg\async\PosixStack.cc
int PosixWorker::listen(entity_addr_t &sa, const SocketOptions &opt,
ServerSocket *sock)
{
……
int listen_sd = net.create_socket(sa.get_family(), true);
……
r = ::bind(listen_sd, sa.get_sockaddr(), sa.get_sockaddr_len());
……
r = ::listen(listen_sd, 128);
……
*sock = ServerSocket(
std::unique_ptr<PosixServerSocketImpl>(
new PosixServerSocketImpl(net, listen_sd)));
return 0;
}
void AsyncMessenger::_finish_bind(const entity_addr_t &bind_addr,
const entity_addr_t &listen_addr)
{
……
init_local_connection();
did_bind = true;
}
void _init_local_connection() {
assert(lock.is_locked());
local_connection->peer_addr = my_inst.addr;
local_connection->peer_type = my_inst.name.type();
ms_deliver_handle_fast_connect(local_connection.get());
}
void ms_deliver_handle_fast_connect(Connection *con) {
for (list<Dispatcher*>::iterator p = fast_dispatchers.begin(); // fast_dispatchers 目前为空
p != fast_dispatchers.end();
++p)
(*p)->ms_handle_fast_connect(con);
}3)Deal with Event
在绑定地址进行端口监听以后,就会等着连接到来,要处理连接请求,肯定得创建Worker线程来处理吧?
// ceph_osd.cc 会继续调用messenger->start(), 参见前面代码
int AsyncMessenger::start()
{
lock.Lock();
……
if (!did_bind) //上面finsh_bind的时候已经 _init_local_connection(),然后did_bind=ture
{
my_inst.addr.nonce = nonce;
_init_local_connection();
}
lock.Unlock();
return 0;
}
void WorkerPool::start()
{
if (!started) {
for (uint64_t i = 0; i < workers.size(); ++i) {
workers[i]->create(); // 创建线程
}
started = true;
}
}
// 线程入口函数
void *Worker::entry()
{
......
center.set_owner(pthread_self());
while (!done) { // 线程一直循环处理事件
int r = center.process_events(EventMaxWaitUs); // 借助于事件中心处理事件, 注意最大的等待时间是30秒
}
return 0;
}
// 通过epoll_wait返回所有就绪的fd,然后一次调用其callback
int EventCenter::process_events(int timeout_microseconds)
{
......
vector<FiredFileEvent> fired_events;
next_time = shortest;
numevents = driver->event_wait(fired_events, &tv); // 获取当前的io事件
for (int j = 0; j < numevents; j++) {
int rfired = 0;
FileEvent *event;
{
Mutex::Locker l(file_lock);
event = _get_file_event(fired_events[j].fd);
}
if (event->mask & fired_events[j].mask & EVENT_READABLE) {
rfired = 1;
event->read_cb->do_request(fired_events[j].fd); // 处理可读事件
}
if (event->mask & fired_events[j].mask & EVENT_WRITABLE) {
if (!rfired || event->read_cb != event->write_cb)
event->write_cb->do_request(fired_events[j].fd); // 处理可写事件
}
}
......
}
//driver->event_wait
int EpollDriver::event_wait(vector<FiredFileEvent> &fired_events, struct timeval *tvp)
{
int retval, numevents = 0;
retval = epoll_wait(epfd, events, size,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1); // epoll_wait系统调用,等待就绪事件或超时返回
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = events + j;
if (e->events & EPOLLIN) mask |= EVENT_READABLE;
if (e->events & EPOLLOUT) mask |= EVENT_WRITABLE;
if (e->events & EPOLLERR) mask |= EVENT_WRITABLE;
if (e->events & EPOLLHUP) mask |= EVENT_WRITABLE;
// 记录下已经发生的事件
fired_events[j].fd = e->data.fd;
fired_events[j].mask = mask;
}
return numevents;
}process_events函数中,需要注意的是,这里处理三种事件:
1、与fd相关的读写事件。
2、与时间相关的time事件。
3、还有添加的外部事件。
在处理fd的时候,如果没有fd就绪就会一直wait等待超时(最大超时时间不超过下次时间事件的值)。但是,在这个过程中, 有两种情况需要被唤醒,一是添加了一个更小的时间事件(最近发生),二是添加了外部事件。
4)Add Listen Fd
Worker线程循环不停的处理事件,其实就是调用epoll_wait,返回就绪事件的fd,然后调用fd对应的回调read_cb或write_cb,很明显,epoll_wait能够返回就绪的fd, 这个fd必然是之前添加进去的,什么时候添加的呢?还记得在第二步Bind的时候,Processor类中创建了listen_fd,要想监听来自这个fd的请求,必然要将其添加到epoll进行管理。
但是从osd代码运行到这里,似乎都没有添加的动作?在osd调用messenger->start()后,紧接着就是:
err = osd->init();
洞天就在这里:
int OSD::init()
{
......
// i'm ready!
client_messenger->add_dispatcher_head(this);
cluster_messenger->add_dispatcher_head(this);
......
}
void add_dispatcher_head(Dispatcher *d) {
bool first = dispatchers.empty(); // 刚开始当然为空, first为true
dispatchers.push_front(d);
if (d->ms_can_fast_dispatch_any())
fast_dispatchers.push_front(d);
if (first)
ready(); // 准备添加fd到epoll
}
void AsyncMessenger::ready()
{
ldout(cct,10) << __func__ << " " << get_myaddr() << dendl;
Mutex::Locker l(lock);
Worker *w = pool->get_worker(); // 获取一个worker干活
processor.start(w); // listen_sd在Processor中
}
int Processor::start(Worker *w)
{
ldout(msgr->cct, 1) << __func__ << " " << dendl;
// start thread
if (listen_sd > 0) {
worker = w;
// 创建可读事件, 最终会调用epoll_ctl将listen_sd加进epoll进行管理
w->center.create_file_event(listen_sd, EVENT_READABLE,
EventCallbackRef(new C_processor_accept(this))); // 注意事件的callback
}
return 0;
}5)Accept Connection
listen fd添加进去以后,初始化过程就算全部完成了。当新的连接请求到来,如前所述,worker线程会调用process_event函数,回调就会被执行:
// listen fd 的回调
class C_processor_accept : public EventCallback {
Processor *pro;
public:
C_processor_accept(Processor *p): pro(p) {}
void do_request(int id) {
pro->accept(); // 回调 Processor::accept()
}
};
void Processor::accept()
{
while (errors < 4) {
entity_addr_t addr;
socklen_t slen = sizeof(addr.ss_addr());
int sd = ::accept(listen_sd, (sockaddr*)&addr.ss_addr(), &slen); // 接受连接请求
if (sd >= 0) {
msgr->add_accept(sd); // 通过messenger处理接收套接字sd
continue;
} else {
......
}
}
}
AsyncConnectionRef AsyncMessenger::add_accept(int sd)
{
lock.Lock();
Worker *w = pool->get_worker();
AsyncConnectionRef conn = new AsyncConnection(cct, this, &w->center); // 创建连接
w->center.dispatch_event_external(EventCallbackRef(new C_conn_accept(conn, sd))); // 分发事件, 外部新的连接,所以叫external
accepting_conns.insert(conn); // 记录下即将生效的连接, 最终完成后会从此集合删除
lock.Unlock();
return conn;
}
void EventCenter::dispatch_event_external(EventCallbackRef e)
{
external_lock.Lock();
external_events.push_back(e); // 将事件的callback函数放入事件中心的队列中等待执行
external_lock.Unlock();
wakeup(); // 唤醒worker线程
}
不是很明白为什么需要放入队列,等待worker下一次的process_event调用,是否可以直接执行完毕?
不管怎么样,放入队列后,需要执行队列中的callback,什么时候会执行呢?很明显是在worker线程中的process_event函数, 但是worker线程可能sleep在epoll_wait(epoll管理的所有fd都没就绪,只能等待超时),如果有新连接到来,需要立即接收连接请求, 所以要唤醒睡眠的worker线程,后面的wakeup函数就是做这个事情(唤醒)的,这个函数向pipe的一端写入数据(pipe是在函数EventCenter::init()中创建的), 使得另一端可读,即notify_receive_fd就绪,epoll_wait会返回其可读事件,然后执行其回调(回调就是简单读pipe),使得worker线程得以继续处理, 然后执行刚才放入队列中的回调。
void EventCenter::wakeup()
{
ldout(cct, 1) << __func__ << dendl;
char buf[1];
buf[0] = 'c';
// wake up "event_wait"
int n = write(notify_send_fd, buf, 1); // 唤醒worker线程
// FIXME ?
assert(n == 1);
}
int EventCenter::process_events(int timeout_microseconds)
{
......
numevents = driver->event_wait(fired_events, &tv); // 本来worker线程可能睡眠在这里,会被wakeup唤醒
// 这时候至少有一个fd就绪,即notify_receive_fd
// 执行所有fd的callback, 对于notify_receive_fd,可以看其callback,就是简单读一下,什么也没干
for (int j = 0; j < numevents; j++) {
......
event->read_cb->do_request(fired_events[j].fd);
.....
}
......
// 紧接着处理刚才的队列, 这正是唤醒worker的目的
{
external_lock.Lock();
while (!external_events.empty()) {
EventCallbackRef e = external_events.front();
external_events.pop_front();
external_lock.Unlock();
if (e)
e->do_request(0); // 连接请求的callback
external_lock.Lock();
}
external_lock.Unlock();
}
......
}6)Add Accept Fd
从分析看,连接请求的callback会很快被执行。前面已经有了accept接收请求的fd (OSD.init添加的),现在需要将那个fd加入epoll结构,管理起来,然后就可以进行通信, callback最终就是做这些事情:
// 队列中的回调类型
class C_conn_accept : public EventCallback {
AsyncConnectionRef conn;
int fd;
public:
C_conn_accept(AsyncConnectionRef c, int s): conn(c), fd(s) {}
void do_request(int id) {
conn->accept(fd);
}
};
void AsyncConnection::accept(int incoming)
{
ldout(async_msgr->cct, 10) << __func__ << " sd=" << incoming << dendl;
assert(sd < 0);
sd = incoming;
state = STATE_ACCEPTING;
center->create_file_event(sd, EVENT_READABLE, read_handler); // sd就是连接成功的fd,加进epoll管理
process(); // 服务器端的状态机开始执行,会先向客户端发送BANNER消息
}7)Communication
注意服务端AsyncConnection状态机的初始状态是STATE_ACCEPTING,服务器端的状态机会先向客户端发送BANNER消息。 以后收到消息,worker线程就会调用read_handler处理,然后调用process,状态机不停的转换状态:
// 注册的回调类
class C_handle_read : public EventCallback {
AsyncConnectionRef conn;
public:
C_handle_read(AsyncConnectionRef c): conn(c) {}
void do_request(int fd_or_id) {
conn->process(); // 调用connection处理
}
};
void AsyncConnection::process()
{
int r = 0;
int prev_state = state;
Mutex::Locker l(lock);
do {
prev_state = state;
// connection状态机
switch (state) {
case STATE_OPEN:
......
default:
{
if (_process_connection() < 0)
goto fail;
break;
}
}
}
return 0;
fail:
......
}
// 单独处理连接信息
int AsyncConnection::_process_connection()
{
int r = 0;
switch(state) {
case STATE_WAIT_SEND:
......
}
......
}AsyncConnection就是负责通信的类,要理解这个状态机的原理,必须理解ceph的应用层通信协议, 可以参看官方文档的解释。
AsyncMessenger的框架就算介绍完成了,当有新的连接请求到来,就会重复执行以下这几步:
-
accept connection
-
add accept fd
-
communication
由此可以看出,线程数不是随连接数线性增加的,只由最开始初始化的时候启动了多少个worker决定。

2、Client
客户端的操作主要是发起connect操作,建立连接进行通信。所有的客户端都是基于librados库,然后通过RadosClient连接集群的:
int librados::Rados::connect()
{
return client->connect();
}
int librados::RadosClient::connect()
{
......
// 创建messenger
messenger = Messenger::create(cct, cct->_conf->ms_type, entity_name_t::CLIENT(-1),
"radosclient", nonce);
......
// 创建objecter
// 发送消息的时候,比如librbd代码,都是通过objecter处理
// objecter需要借助于messenger发送,所以需要将创建的messenger传给objecter类
objecter = new (std::nothrow) Objecter(cct, messenger, &monclient,
&finisher,
cct->_conf->rados_mon_op_timeout,
cct->_conf->rados_osd_op_timeout);
// 同理,连接monitor也需要处理消息的收发
monclient.set_messenger(messenger);
objecter->init();
messenger->add_dispatcher_tail(objecter);
messenger->add_dispatcher_tail(this);
messenger->start();
......
messenger->set_myname(entity_name_t::CLIENT(monclient.get_global_id())); // ID全局唯一,所以需要向monitor获取
......
}connect操作只是初始化了messenger对象,真正需要通信的时候,才会去建立连接,以objecter.cc中的op_submit为例:
ceph_tid_t Objecter::_op_submit(Op *op, RWLock::Context& lc)
{
......
int r = _get_session(op->target.osd, &s, lc);
......
}
int Objecter::_get_session(int osd, OSDSession **session, RWLock::Context& lc)
{
......
// session 不存在,会创建新的session,
s->con = messenger->get_connection(osdmap->get_inst(osd));
......
}
ConnectionRef AsyncMessenger::get_connection(const entity_inst_t& dest)
{
......
conn = create_connect(dest.addr, dest.name.type());
......
}
AsyncConnectionRef AsyncMessenger::create_connect(const entity_addr_t& addr, int type)
{
// create connection
Worker *w = pool->get_worker();
AsyncConnectionRef conn = new AsyncConnection(cct, this, &w->center); // 创建connection
conn->connect(addr, type); // 连接
assert(!conns.count(addr));
conns[addr] = conn;
return conn;
}
void connect(const entity_addr_t& addr, int type)
{
set_peer_type(type);
set_peer_addr(addr);
policy = msgr->get_policy(type);
_connect();
}
void AsyncConnection::_connect()
{
state = STATE_CONNECTING; // 这个初始化状态很关键,是客户端状态机的起始状态
stopping.set(0);
center->dispatch_event_external(read_handler); // 放入队列等待worker处理
}这里和前面一样,worker会处理这个外部事件,read_handler就会调用process函数,紧接着就过度到_process_connection:
int AsyncConnection::_process_connection()
{
int r = 0;
switch(state) {
case STATE_CONNECTING: // 初始状态
{
......
sd = net.connect(get_peer_addr()); // 通过net类的功能,实际上就是调用connect系统调用,建立socket通信
// 连接成功后,将socket fd加入epoll进行管理
center->create_file_event(sd, EVENT_READABLE, read_handler);
state = STATE_CONNECTING_WAIT_BANNER;
break;
}
}
}接下来就是客户端和服务端的通信,都是通过AsyncConnection的状态机完成。同理,客户端即使创建多个messenger, 他们仍然共享一个workerpool,线程数由这个pool初始化的时候决定,不会随着连接的增加而线性增加。
3、Summary
-
进程中所有的AsyncMessenger共享一个workerpool管理所有worker
-
Worker线程通过EventCenter负责具体的事件处理
-
应用层的网络通信由AsyncConnection的状态机处理

三、RDMA messenger
RDMA 技术有好几种规范来达到:
- InfiniBand: 这是正统,InfiniBand 设计之初就考虑了 RDMA,InfiniBand 从硬件级别保证可靠传输;
- iWARP: 基于 TCP or SCTP 做 RDMA,利用 TCP or SCTP 达到可靠传输,对网络设备的要求比较少;
- RoCE: 基于 Ethernet 做 RDMA,消耗的资源比 iWARP 少,支持的特性比 iWARP 多,需要FCoE做可靠传输。从wikipedia的评价看 RoCE 还是比正统的 InfiniBand 差点。
with InfiniBand RDMA architecture

Leveraging RDMA Technologies to Accelerate Ceph* Storage Solutions
with iWARP RDMA architecture

Leveraging RDMA Technologies to Accelerate Ceph* Storage Solutions



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!