

【Ceph】Ceph中Bufferlist的设计与使用
目录
claim(list &bl, unsigned int flags = CLAIM_DEFAULT);
splice(unsigned off, unsigned len, list *claim_by = 0)
write(int off, int len, std::ostream &out)
bandaoyu,本文随时更新,链接:http://t.csdn.cn/vGW8N
参考OR摘抄原文:
1、Ceph中Bufferlist的设计与使用 - http://www.voidcn.com/article/p-kmnnilin-kd.html
2、ceph源码阅读 buffer - https://zhuanlan.zhihu.com/p/96659509
3、ceph:bufferlist实现 - https://www.jianshu.com/p/01e1f4e398df
背景:为什么要用bufferlist
为了免拷贝。
发送数据,传统的socket接口通常需要读取一段连续的内存。但是我们要发的数据内存不连续,所以以前的做法是申请一块大的内存,然后将不连续的内存内的数据拷贝到大内存块中,然后将大内存块地址给发送接口。
但是找一块连续的大内存并不容易,系统可能会为此做各种腾挪操作,而将数据拷贝的大内存中,又是一个拷贝操作。
RDMA的发送支持聚散表,不需要读取连续的内存。有bufferlist之后,我们可以通过bufferlist,将不连续的物理内存管理起来,形成一段“连续”的虚拟内存,然后将bufferlist的内存指针传递给聚散表,再把聚散表交给RDMA 发送接口即可。整个过程免去了内存拷贝操作。大大降低了CPU的消耗。
Bufferlist的设计
如果非要在整个Ceph中,找出一个类最重要,我觉得非Bufferlist莫属了,原因很简单,因为Bufferlist负责管理Ceph中所有的内存。整个Ceph中所有涉及到内存的操作,无论是msg分配内存接收消息,还是OSD构造各类数据结构的持久化表示(encode/decode),再到实际磁盘操作,都将bufferlist作为基础。
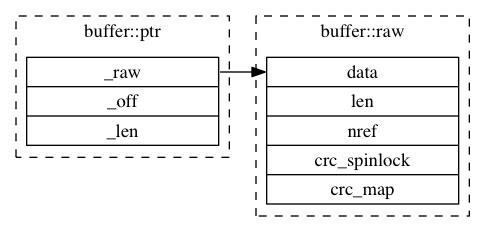
ceph::buffer是ceph非常底层的实现,负责管理ceph的内存。ceph::buffer的设计较为复杂,但本身没有任何内容,主要包含buffer::list、buffer::ptr、buffer::raw、buffer::hash。这三个类都定义在src/include/buffer.h和src/common/buffer.cc中。
buffer::raw:负责维护物理内存的引用计数nref和释放操作。
buffer::ptr:指向buffer::raw的指针。
buffer::list:表示一个ptr的列表(std::list<bufferptr>),相当于将N个ptr构成一个更大的虚拟的连续内存。ceph::buffer::list
class ceph{
class buffer {
class list
{
// my private bits
std::list<ptr> _buffers;
unsigned _len;
……
}
}
}buffer::hash:一个或多个bufferlist的有效哈希。
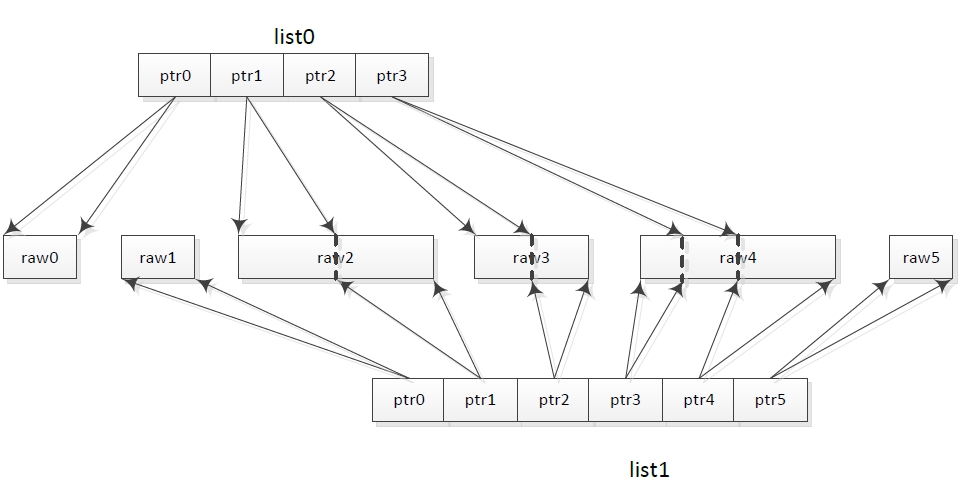
buffer这三个类的相互关系可以用下面这个图来表示:

图中蓝色的表示bufferlist,橙色表示bufferptr,绿色表示bufferraw。
在这个图中,实际占用的系统内存一共就三段,分别是raw0,raw1和raw2代表的三段内存。其中:
raw0被ptr0,ptr1,ptr2使用
raw1被ptr3,ptr4,ptr6使用
raw2被ptr5,ptr7使用
而list0是由ptr0-5组成的,list1是由ptr6和ptr7组成的。
从这张图上我们就可以看出bufferlist的设计思路了: 对于bufferlist来说,仅关心一个个ptr。bufferlist将ptr连在一起,当做是一段连续的内存使用。因此,可以通过bufferlist::iterator一个字节一个字节的迭代整个bufferlist中的所有内容,而不需要关心到底有几个ptr,更不用关心这些ptr到底和系统内存是怎么对应的;也可以通过bufferlist::write_file方法直接将bufferlist中的内容出到一个文件中;或者通过bufferlist::write_fd方法将bufferlist中的内容写入到某个fd中。
与bufferlist相对的是负责管理系统内存的bufferraw。bufferraw只关心一件事:维护其所管理的系统内存的引用计数,并且在引用计数减为0时——即没有ptr再使用这块内存时,释放这块内存。
连接bufferlist和bufferraw的是bufferptr。bufferptr关心的是如何使用内存。每一个bufferptr一定有一个bufferraw为其提供系统内存,然后ptr决定使用这块内存的哪一部分。bufferlist只用通过ptr才能对应到系统内存中,而bufferptr而可以独立存在,只是大部分ptr还是为bufferlist服务的,独立的ptr使用的场景并不是很多。
通过引入ptr这样一个中间层次,bufferlist使用内存的方式可以非常灵活,这里可以举两个场景:
1. 快速encode/decode
在Ceph中经常需要将一个bufferlist编码(encode)到另一个bufferlist中,例如在msg发送消息的时候,通常msg拿到的osd等逻辑层传递给它的bufferlist,然后msg还需要给这个bufferlist加上消息头和消息尾,而消息头和消息尾也是用bufferlist表示的。这时候,msg通常会构造一个空的bufferlist,然后将消息头、消息尾、内容都encode到这个空的bufferlist。而bufferlist之间的encode实际只需要做ptr的copy,而不涉及到系统内存的申请和Copy,效率较高。
2. 一次分配,多次使用
我们都知道,调用malloc之类的函数申请内存是非常重量级的操作。利用ptr这个中间层可以缓解这个问题,即我们可以一次性申请一块较大的内存,也就是一个较大的bufferraw,然后每次需要内存的时候,构造一个bufferptr,指向这个bufferraw的不同部分。这样就不再需要向系统申请内存了。最后将这些ptr都加入到一个bufferlist中,就可以形成一个虚拟的连续内存。
关于作者1:袁冬博士,UnitedStack产品副总裁,负责UnitedStack产品、售前和对外合作工作;云计算专家,在云计算、虚拟化、分布式系统和企业级应用等方面有丰富的经验;对分布式存储、非结构数据存储和存储虚拟化有深刻地理解,在云存储和企业级存储领域有丰富的研发与实践经验;Ceph等开源存储项目的核心代码贡献者。
相关文章:Bufferlist::list设计与实现 - https://www.jianshu.com/p/6c8b361cc665
源码分析 (ceph internal 之 buffer list-http://bean-li.github.io/bufferlist-in-ceph/)
buffer::raw
介绍buffer list之前,我们必须先介绍buffer::raw和buffer::ptr。相对于buffer list,这两个数据结构相对比较容易理解。
class buffer::raw {
public:
char *data;
unsigned len;
atomic_t nref;
mutable simple_spinlock_t crc_spinlock;
map<pair<size_t, size_t>, pair<uint32_t, uint32_t> > crc_map;
...
}
data:指向原始数据raw的指针。
len:记录了该buffer::raw数据区数据的长度。
nref:引用计数。
mempool:其对应的内存池的index,这个和data空间的分配有关。
crc_spinlock:读写锁。
注意,data指针指向的数据可能有不同的来源,最容易想到的当然是malloc,其次我们以可以使用mmap通过创建匿名内存映射来分配空间,甚至我们可以通过pipe管道+splice实现零拷贝获取空间。有些时候,分配的空间时,会提出对齐的要求,比如按页对齐。
这是因为这些来源不同,要求不同,buffer::raw也就有了一些变体:
buffer:raw_malloc
这个变体数据来源源自malloc,因此,创建的时候,需要通过malloc分配长度为len的空间,,而不意外,析构的时候,会掉用free释放空间。
class buffer::raw_malloc : public buffer::raw {
public:
explicit raw_malloc(unsigned l) : raw(l) {
if (len) {
data = (char *)malloc(len);
if (!data)
throw bad_alloc();
} else {
data = 0;
}
inc_total_alloc(len);
inc_history_alloc(len);
bdout << "raw_malloc " << this << " alloc " << (void *)data << " " << l << " " << buffer::get_total_alloc() << bendl;
}
raw_malloc(unsigned l, char *b) : raw(b, l) {
inc_total_alloc(len);
bdout << "raw_malloc " << this << " alloc " << (void *)data << " " << l << " " << buffer::get_total_alloc() << bendl;
}
~raw_malloc() {
free(data);
dec_total_alloc(len);
bdout << "raw_malloc " << this << " free " << (void *)data << " " << buffer::get_total_alloc() << bendl;
}
raw* clone_empty() {
return new raw_malloc(len);
}
};
buffer::raw_mmap_pages
顾名思义,也能够猜到,这个数据的来源是通过mmap分配的匿名内存映射。因此析构的时候,毫不意外,掉用munmap解除映射,归还空间给系统。
class buffer::raw_mmap_pages : public buffer::raw {
public:
explicit raw_mmap_pages(unsigned l) : raw(l) {
data = (char*)::mmap(NULL, len, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0);
if (!data)
throw bad_alloc();
inc_total_alloc(len);
inc_history_alloc(len);
bdout << "raw_mmap " << this << " alloc " << (void *)data << " " << l << " " << buffer::get_total_alloc() << bendl;
}
~raw_mmap_pages() {
::munmap(data, len);
dec_total_alloc(len);
bdout << "raw_mmap " << this << " free " << (void *)data << " " << buffer::get_total_alloc() << bendl;
}
raw* clone_empty() {
return new raw_mmap_pages(len);
}
};
buffer::raw_posix_aligned
看名字也看出来了,对空间有对齐的要求。Linux下posix_memalign函数用来分配有对齐要求的内存空间。这种分配方式分配的空间,也是用free函数来释放,将空间归还给系统。
class buffer::raw_posix_aligned : public buffer::raw {
unsigned align;
public:
raw_posix_aligned(unsigned l, unsigned _align) : raw(l) {
align = _align;
assert((align >= sizeof(void *)) && (align & (align - 1)) == 0);
#ifdef DARWIN
data = (char *) valloc (len);
#else
data = 0;
int r = ::posix_memalign((void**)(void*)&data, align, len);
if (r)
throw bad_alloc();
#endif /* DARWIN */
if (!data)
throw bad_alloc();
inc_total_alloc(len);
inc_history_alloc(len);
bdout << "raw_posix_aligned " << this << " alloc " << (void *)data << " l=" << l << ", align=" << align << " total_alloc=" << buffer::get_total_alloc() << bendl;
}
~raw_posix_aligned() {
::free((void*)data);
dec_total_alloc(len);
bdout << "raw_posix_aligned " << this << " free " << (void *)data << " " << buffer::get_total_alloc() << bendl;
}
raw* clone_empty() {
return new raw_posix_aligned(len, align);
}
};
后面还有基于pipe和splice的零拷贝方式,我们不赘述。从上面的函数不难看出,buffer::raw系列,就像他的名字一样,真的是很原生,并没有太多的弯弯绕,就是利用系统提供的API来达到分配空间的目的。
buffer::ptr
buffer::ptr是在buffer::raw系列的基础上,这个类也别名bufferptr。
src/include/buffer_fwd.h
#ifndef BUFFER_FWD_H
#define BUFFER_FWD_H
namespace ceph {
namespace buffer {
class ptr;
class list;
class hash;
}
using bufferptr = buffer::ptr;
using bufferlist = buffer::list;
using bufferhash = buffer::hash;
}
#endif
成员变量:
_raw:指向raw的指针
_off:数据偏移量
_len:数据长度
这个类的成员变量如下,这个类是raw这个类的包装升级版本,它的_raw就是指向buffer::raw类型的变量。
class CEPH_BUFFER_API ptr {
raw *_raw;
unsigned _off, _len;
......
}
很多操作都是很容易想到的:
buffer::ptr& buffer::ptr::operator= (const ptr& p)
{
if (p._raw) {
p._raw->nref.inc();
bdout << "ptr " << this << " get " << _raw << bendl;
}
buffer::raw *raw = p._raw;
release();
if (raw) {
_raw = raw;
_off = p._off;
_len = p._len;
} else {
_off = _len = 0;
}
return *this;
}
buffer::raw *buffer::ptr::clone()
{
return _raw->clone();
}
void buffer::ptr::swap(ptr& other)
{
raw *r = _raw;
unsigned o = _off;
unsigned l = _len;
_raw = other._raw;
_off = other._off;
_len = other._len;
other._raw = r;
other._off = o;
other._len = l;
}
const char& buffer::ptr::operator[](unsigned n) const
{
assert(_raw);
assert(n < _len);
return _raw->get_data()[_off + n];
}
char& buffer::ptr::operator[](unsigned n)
{
assert(_raw);
assert(n < _len);
return _raw->get_data()[_off + n];
}
int buffer::ptr::cmp(const ptr& o) const
{
int l = _len < o._len ? _len : o._len;
if (l) {
int r = memcmp(c_str(), o.c_str(), l);
if (r)
return r;
}
if (_len < o._len)
return -1;
if (_len > o._len)
return 1;
return 0;
}
ptr和raw的关系和golang中splice和array的关系有点像。raw是真正存储数据的地方,而ptr只是指向某个raw中的一段的指针。其数据成员 _raw为指向raw的指针,_off表示数据起始偏移,_len表示数据长度。
这边还有提一下ptr的append函数,直观上ptr不应该提供append函数,事实上ptr的append确实很局限,只有当ptr对应的raw区域后方有空闲空间的时候,才能append成功,至于空间不够的情况,应该是交给list等高层类来处理。代码如下:
unsigned buffer::ptr::append(const char *p, unsigned l)
{
assert(_raw);
assert(l <= unused_tail_length());
char *c = _raw->data + _off + _len;
maybe_inline_memcpy(c, p, l, 32);
_len += l;
return _len + _off;
}
bufferlist
bufferlist才是我们的目的地,前两个类其实是比较容易理解的,但是bufferlist相对复杂一点。
bufferlist是buffer::list的别名:
#ifndef BUFFER_FWD_H
#define BUFFER_FWD_H
namespace ceph {
namespace buffer {
class ptr;
class list;
class hash;
}
using bufferptr = buffer::ptr;
using bufferlist = buffer::list;
using bufferhash = buffer::hash;
}
#endif
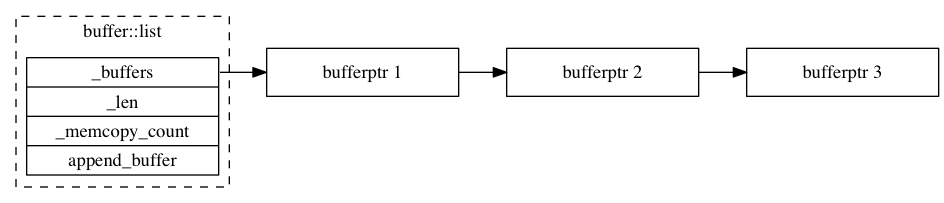
class CEPH_BUFFER_API list {
// my private bits
std::list<ptr> _buffers;
unsigned _len;
unsigned _memcopy_count; //the total of memcopy using rebuild().
ptr append_buffer; // where i put small appends
_root:链表头
_tail:链表尾
_size:链表节点数
bufferlist将数据以不连续链表的方式存储。
buffer::list是由ptr组成的链表,多个bufferptr形成一个list,这就是bufferlist。成员变量并无太多难以理解的地方,比较绕的是bufferlist的迭代器 ,理解迭代器,就不难理解bufferlist各个操作函数。
要理解bufferlist 迭代器,,首先需要理解迭代器成员变量的含义。
_buffers是一个ptr的链表,_len是整个_buffers中所有的ptr的数据的总长度,_memcopy_count用于统计memcopy的字节数,append_buffer是用于优化append操作的缓冲区,可以看出bufferlist将数据以不连续链表的方式存储。
template <bool is_const>
class CEPH_BUFFER_API iterator_impl
: public std::iterator<std::forward_iterator_tag, char>
{
protected:
bl_t *bl;
list_t *ls; // meh.. just here to avoid an extra pointer dereference..
unsigned off; // in bl
list_iter_t p;
unsigned p_off; // in *p
......
};- bl:指针,指向bufferlist
- ls:指针,指向bufferlist的成员 _buffers
- p: 类型是std::list::iterator,用来迭代遍历bufferlist中的bufferptr
- p_off : 当前位置在对应的bufferptr的偏移量
- off: 如果将整个bufferlist看成一个buffer::raw,当前位置在整个bufferlist的偏移量
这个递进关系比较明显,从宏观的bufferlist,递进到内部的某个bufferptr,再递进到bufferptr内部raw数据区的某个偏移位置。 此外还包含了当前位置在整个bufferlist的偏移量off。
注意p_off和off容易产生误解,请阅读seek函数仔细揣摩
seek(unsigned o),顾名思义就是将位置移到o处,当然o指的是整个bufferlist的o处。ceph实现了一个更通用的advance,接受一个int型的入参。
如果o>0,表示向后移动,如果o小于0,表示想前移动。移动的过程中可能越过当前的bufferptr之指向的数据区。
template<bool is_const>
void buffer::list::iterator_impl<is_const>::advance(int o)
{
//cout << this << " advance " << o << " from " << off << " (p_off " << p_off << " in " << p->length() << ")" << std::endl;
if (o > 0) {
p_off += o;
while (p_off > 0) {
if (p == ls->end())
throw end_of_buffer();
if (p_off >= p->length()) {
// skip this buffer
p_off -= p->length();
p++;
} else {
// somewhere in this buffer!
break;
}
}
off += o;
return;
}
while (o < 0) {
if (p_off) {
unsigned d = -o;
if (d > p_off)
d = p_off;
p_off -= d;
off -= d;
o += d;
} else if (off > 0) {
assert(p != ls->begin());
p--;
p_off = p->length();
} else {
throw end_of_buffer();
}
}
}
template<bool is_const>
void buffer::list::iterator_impl<is_const>::seek(unsigned o)
{
p = ls->begin();
off = p_off = 0;
advance(o);
}
除此以外,获取当前位置的ptr也很有意思,理解该函数也有帮助理解迭代器五个成员的含义。
template<bool is_const>
buffer::ptr buffer::list::iterator_impl<is_const>::get_current_ptr() const
{
if (p == ls->end())
throw end_of_buffer();
return ptr(*p, p_off, p->length() - p_off);
}
相当于多个bufferptr对应的buffer::raw组成了一个可能不连续的buffer列表,因此使用起来可能不方便,ceph出于这种考虑,提供了rebuild的函数。该函数的作用是,干脆创建一个buffer::raw,来提供同样的空间和内容。
void buffer::list::rebuild()
{
if (_len == 0) {
_buffers.clear();
return;
}
ptr nb;
if ((_len & ~CEPH_PAGE_MASK) == 0)
nb = buffer::create_page_aligned(_len);
else
nb = buffer::create(_len);
rebuild(nb);
}
void buffer::list::rebuild(ptr& nb)
{
unsigned pos = 0;
for (std::list<ptr>::iterator it = _buffers.begin();
it != _buffers.end();
++it) {
nb.copy_in(pos, it->length(), it->c_str(), false);
pos += it->length();
}
_memcopy_count += pos;
_buffers.clear();
if (nb.length())
_buffers.push_back(nb);
invalidate_crc();
last_p = begin();
}
从下面测试代码中不难看出rebuild的含义,就是划零为整,重建一个buffer::raw来提供空间
{
bufferlist bl;
const std::string str(CEPH_PAGE_SIZE, 'X');
bl.append(str.c_str(), str.size());
bl.append(str.c_str(), str.size());
EXPECT_EQ((unsigned)2, bl.buffers().size());
bl.rebuild();
EXPECT_EQ((unsigned)1, bl.buffers().size());
}
理解了上述的内容,bufferlist剩余的上千行代码,基本也就变成了流水账了,不难理解了,在此就不再赘述了。
更多文章:
《ceph源码阅读 buffer》ceph源码阅读 buffer - https://zhuanlan.zhihu.com/p/96659509
《ceph:bufferlist实现》https://www.it610.com/article/1231080926906257408.htm
ceph 博客:http://bean-li.github.io/
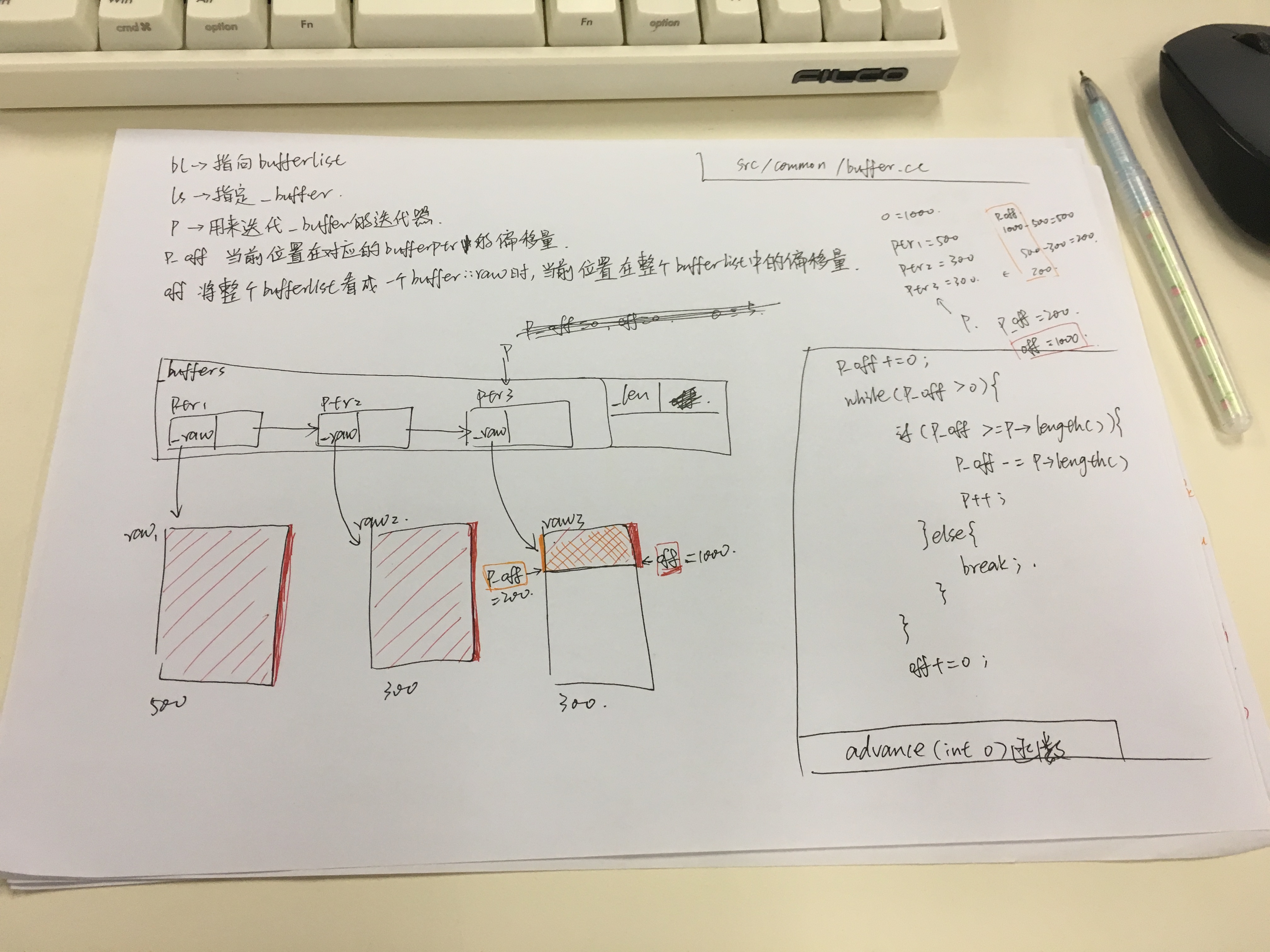
bufferlist是buffer::list的别名,其由来在 http://bean-li.github.io/bufferlist-in-ceph/ 中有非常详细的介绍
其p、p_off、off字段的含义可以通过advance(int o)函数来理解
简单来说,p就说指向_buffer的迭代器,p_off则是在当前buffer::ptr的_raw中的偏移,而off则是把_buffer中的_raw视为一个整体时的当前偏移。如下图中,o为1000时,则p为ptr3,p_off为200(由1000-500-300得来),而off则为1000.
buffer常见的函数
在:src/include/buffer.h和 src/common/buffer.cc中。
buffer主要的类:
class raw;
class raw_malloc;
class raw_static;
class raw_posix_aligned;
class raw_hack_aligned;
class raw_char;
class raw_claimed_char;
class raw_unshareable; // diagnostic, unshareable char buffer
class raw_combined;
class raw_claim_buffer;buffer的很多方法都在上面这些类的基础上实现的:
/*
* named constructors
*/
ceph::unique_leakable_ptr<raw> copy(const char *c, unsigned len);
ceph::unique_leakable_ptr<raw> create(unsigned len);
ceph::unique_leakable_ptr<raw> create(unsigned len, char c);
ceph::unique_leakable_ptr<raw> create_in_mempool(unsigned len, int mempool);
ceph::unique_leakable_ptr<raw> claim_char(unsigned len, char *buf);
ceph::unique_leakable_ptr<raw> create_malloc(unsigned len);
ceph::unique_leakable_ptr<raw> claim_malloc(unsigned len, char *buf);
ceph::unique_leakable_ptr<raw> create_static(unsigned len, char *buf);
ceph::unique_leakable_ptr<raw> create_aligned(unsigned len, unsigned align);
ceph::unique_leakable_ptr<raw> create_aligned_in_mempool(unsigned len, unsigned align, int mempool);
ceph::unique_leakable_ptr<raw> create_page_aligned(unsigned len);
ceph::unique_leakable_ptr<raw> create_small_page_aligned(unsigned len);
ceph::unique_leakable_ptr<raw> claim_buffer(unsigned len, char *buf, deleter del);void buffer::list::substr_of()
获取子字符串
other:指向原数据的bufferlist指针
off:数据的偏移
len:数据截取长度
void buffer::list::substr_of(const list& other, unsigned off, unsigned len)
{
if (off + len > other.length())
throw end_of_buffer();
clear();
// skip off
//curbuf获得other的链表头
auto curbuf = std::cbegin(other._buffers);
//找到和off对应的链表节点
while (off > 0 && off >= curbuf->length()) {
// skip this buffer
//cout << "skipping over " << *curbuf << std::endl;
off -= (*curbuf).length();
++curbuf;
}
ceph_assert(len == 0 || curbuf != std::cend(other._buffers));
//截取所需要的长度,创建新的节点加入到链表尾
while (len > 0) {
// partial?
if (off + len < curbuf->length()) {
//cout << "copying partial of " << *curbuf << std::endl;
_buffers.push_back(*ptr_node::create( *curbuf, off, len ).release());
_len += len;
break;
}
// through end
//cout << "copying end (all?) of " << *curbuf << std::endl;
unsigned howmuch = curbuf->length() - off;
_buffers.push_back(*ptr_node::create( *curbuf, off, howmuch ).release());
_len += howmuch;
len -= howmuch;
off = 0;
++curbuf;
}
}
buffer::create_aligned()
预对齐内存的分配
len:分配内存的大小
align:内存对齐的倍数
ceph::unique_leakable_ptr<buffer::raw> buffer::create_aligned(
unsigned len, unsigned align) {
return create_aligned_in_mempool(len, align,
mempool::mempool_buffer_anon);
}
void buffer::list::claim_append(list& bl, unsigned int flags)
将bl“剪贴”到_buffers的尾部/头部,然后将bl 这个list清空。
void buffer::list::claim_append(list& bl)
{
// steal the other guy's buffers
_len += bl._len;
_num += bl._num;
_buffers.splice_back(bl._buffers);
bl.clear();
}
std::unique_ptr<buffer::ptr_node, buffer::ptr_node::disposer> nb)
将bufferlist中_buffers链表中所有的ptr中的数据存到一个ptr中,并将_buffers原有数据clear,然后将新的单个ptr push到_buffers中。
bufferlist的函数
在:src/include/buffer.h和 src/common/buffer.cc中
面对bufferlist中我遇到的一些函数进行分析,其他函数遇到再说。
clear()
清空bufferlist中的内容
push_front(raw* / ptr &)
push_front(ptr& bp)、push_front(ptr&& bp)、 push_front(raw *r)
push_back(raw* / ptr &)
push_back(ptr& bp)、push_back(ptr&& bp)、 push_back(raw *r)
在_buffers的前面或后面增加新的ptr
rebuild()/rebuild(ptr &nb)
rebuild的含义,就是划零为整,重建一个buffer::raw来提供空间
将bufferlist中buffers链表中所有的ptr中的数据存到一个ptr中,并将_buffers原有数据clear,然后将新的单个ptr push到_buffers中。
带参数时使用参数传入的ptr作为目标ptr,不带参数时自己创建一个ptr。
bufferlist提供了一个rebuild函数,用来将整个buffterptr链表的所有bufferraw都copy到一个新建的bufferptr中,然后清空链表并将新建的这个bufferptr插入到链表中。
claim(list &bl, unsigned int flags = CLAIM_DEFAULT);
将bl的数据拿过来,替换原有的数据。调用后bl数据被清空。
void buffer::list::claim_append(list& bl, unsigned int flags)
将bl“剪贴”到_buffers的尾部/头部,然后将bl 这个list清空。
append(...)
将数据追加到_buffers尾部,已有ptr空间不够时,会自动分配新的ptr。
splice(unsigned off, unsigned len, list *claim_by = 0)
_buffers.splice(off, len, claim_by )将_buffers中总偏移off处长度为len的数据,move到claim_by对应的bufferlist的尾部。注意是move不是copy。
write(int off, int len, std::ostream &out)
将_buffers中总偏移量off处长度为len的数据,写入到ostream。注意是copy,不是move。
链接:https://www.jianshu.com/p/01e1f4e398df
1.bufferlist中的_memcopy_count|rebuild作用是什么?
bufferlist提供了一个rebuild函数,用来将整个buffterptr链表的所有bufferraw都copy到一个新建的bufferptr中,然后清空链表并将新建的这个bufferptr插入到链表中。_memcopy_count成员记录了在进行拷贝过程中每个bufferraw的长度之和。这个值用来在进行内存对齐时需要重新计算,然后比较两者的值,如果不相同就判断内存对齐成功,否则失败。
2.bufferlist是不是类似io buffer?
bufferlist是ceph中进行所有内存操作的管理类:
bufferraw(buffer::raw):对应一段真实内存,派生了十多种不同分配内存的子类,如raw_malloc,raw_static,raw_mmap_pages,raw_posix_aligned,raw_char,raw_pipe等
bufferptr(buffer::ptr):对应ceph实际使用的一段内存,可能多个bufferptr对应于同一个底层bufferraw,其成员off和len标识具体使用的一段内存
bufferlist(buffer::list):多个正在使用的bufferptr构成的一个链表,对应成员std::list<bufferptr> _buffers,其成员off表示整个链表构成的内存相对于起始位置的偏移,p_off表示当前使用的bufferptr的偏移
对于bufferlist来说,通过内部实现的bufferlist::iterator来访问多个bufferptr,能够逐个字节的访问整个内存的内容,不需要关心到底有多少个bufferptr存在,也不用关心bufferptr和底层bufferraw到底是怎么关联的,这种设计就是为了上层使用上的方便,与io buffer的缓存作用并没有太大关系。
上层用户可以直接使用write_file,write_fd等方法,将bufferlist的内容写入文件,可以完全忽略内存的来源、释放等问题,这些问题统一由bufferraw的派生子类和引用计数进行解决。
ceph中有两个使用bufferlist最广泛的场景:
快速encode/decode:messege层收到osd传递的消息(为一个bufferlist),需要加上消息头和消息尾等操作,这些消息头和尾本身都encode为bufferlist,就很容易与消息本身合并(prepend和append操作),而且这些encode、preprend、append操作都是指针操作,不涉及内存拷贝,提示效率。
减少内存分配次数和碎片:利用bufferptr这个中间层进行内存的多次使用,多个bufferptr可以引用同一段bufferraw的不同区域,这个bufferraw可以预先一次性申请较大一段连续内存,从而避免了多次申请内存以及内存碎片的产生。
原文链接:https://blog.csdn.net/u010487568/article/details/79572365
buffer 源码学习
ceph::buffer是ceph非常底层的实现,负责管理ceph的内存。ceph::buffer的设计较为复杂,但本身没有任何内容,主要包含buffer::list、buffer::ptr、buffer::hash。这三个类都定义在src/include/buffer.h和 src/common/buffer.cc中。
ceph源码阅读 buffer - https://zhuanlan.zhihu.com/p/96659509
头文件:
buffer_fwd.h
#ifndef BUFFER_FWD_H
#define BUFFER_FWD_H
namespace ceph
{
namespace buffer
{
inline namespace v15_2_0
{
class ptr;
class list;
}
class hash;
}
using bufferptr = buffer::ptr;
using bufferlist = buffer::list;
using bufferhash = buffer::hash;
}
#endifnamespace v15_2_0使用了内联 inline ,所以buffer:: buffer::ptr; bufferlist = buffer::list; 用的就是namespace v15_2_0的。
(关于内联inline与namespace使用-https://blog.csdn.net/bandaoyu/article/details/119246189)
buffer.h
namespace buffer
{
inline namespace v15_2_0
{
……
/*
* an abstract raw buffer. with a reference count.
*/
class raw;
class raw_malloc;
class raw_static;
class raw_posix_aligned;
class raw_hack_aligned;
class raw_char;
class raw_claimed_char;
class raw_unshareable; // diagnostic, unshareable char buffer
class raw_combined;
class raw_claim_buffer;
……
/*
* named constructors
*/
ceph::unique_leakable_ptr<raw> copy(const char *c, unsigned len);
ceph::unique_leakable_ptr<raw> create(unsigned len);
ceph::unique_leakable_ptr<raw> create(unsigned len, char c);
ceph::unique_leakable_ptr<raw> create_in_mempool(unsigned len, int mempool);
ceph::unique_leakable_ptr<raw> claim_char(unsigned len, char *buf);
ceph::unique_leakable_ptr<raw> create_malloc(unsigned len);
ceph::unique_leakable_ptr<raw> claim_malloc(unsigned len, char *buf);
ceph::unique_leakable_ptr<raw> create_static(unsigned len, char *buf);
ceph::unique_leakable_ptr<raw> create_aligned(unsigned len, unsigned align);
ceph::unique_leakable_ptr<raw> create_aligned_in_mempool(unsigned len, unsigned align, int mempool);
ceph::unique_leakable_ptr<raw> create_page_aligned(unsigned len);
ceph::unique_leakable_ptr<raw> create_small_page_aligned(unsigned len);
ceph::unique_leakable_ptr<raw> claim_buffer(unsigned len, char *buf, deleter del);
class ptr
{
void release();
unsigned append(char c);
unsigned append(const char *p, unsigned l);
void copy_in(unsigned o, unsigned l, const char *src, bool crc_reset = true);
void zero(bool crc_reset = true);
void zero(unsigned o, unsigned l, bool crc_reset = true);
unsigned append_zeros(unsigned l);
void swap(ptr &other) noexcept = delete;
void swap(ptr_node &other) noexcept = delete;
}
class list
{
void copy(unsigned len, char *dest);
void rebuild();
void rebuild(std::unique_ptr < ptr_node, ptr_node::disposer >? nb);
bool rebuild_aligned(unsigned align);
void claim(list &bl)
{
*this = std::move(bl);
}
void claim_append(list &&bl);
void append(char c);
void append(const char *data, unsigned len);
void append(std::string s);
}
}
class hash
{
}
}Bufferlist::list设计与实现
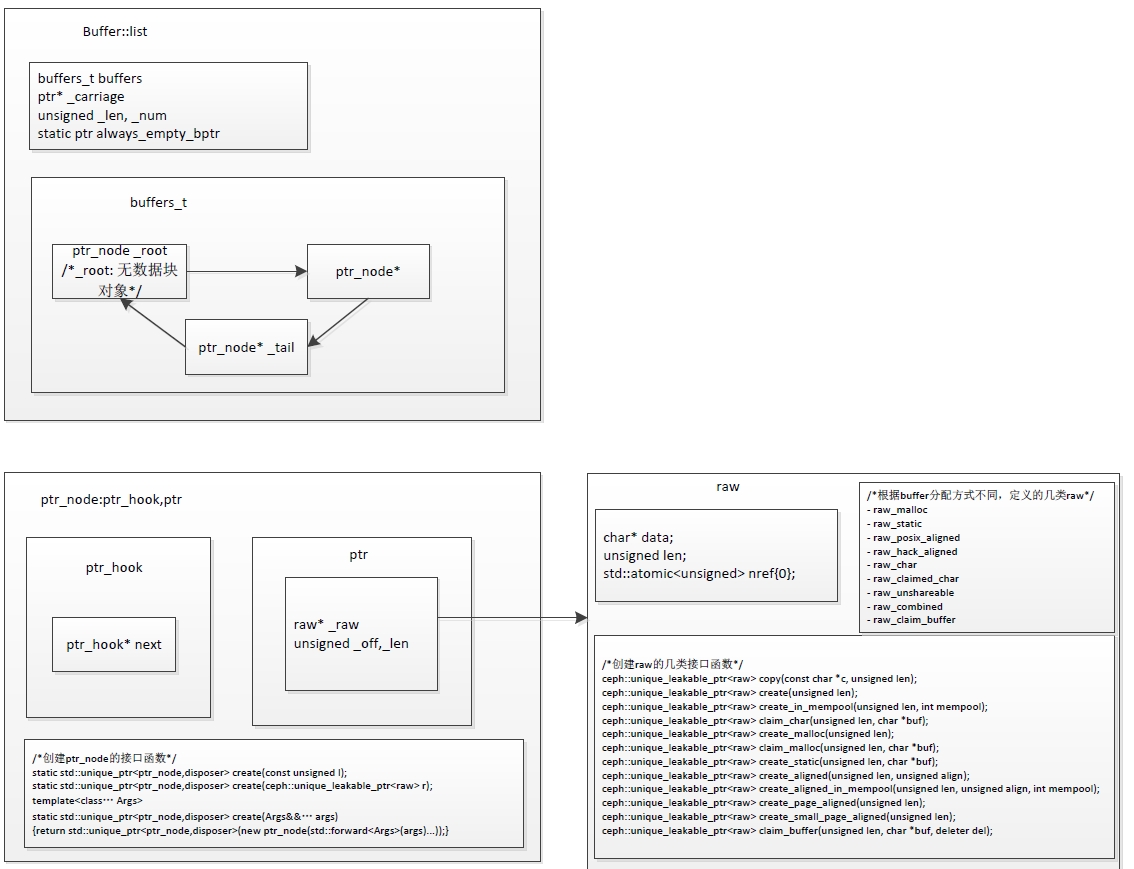
成员变量:
- buffers_t _buffers: ptr循环链表
- ptr* _carriage: 指向list中最后一个可修改的ptr指针
- unsigned _len, _num: _len list数据长度,_num list包含的ptr个数
- static ptr always_empty_bptr: 初始化_carriage
buffer::list迭代器:
class iterator_impl
class iterator: iterator_impl
iterator_impl的成员变量
typedef typename std::conditional<is_const,const list,list>::type bl_t;
typedef typename std::conditional<is_const,const buffers_t,buffers_t >::type list_t;
typedef typename std::conditional<is_const,typename buffers_t::const_iterator,typename buffers_t::iterator>::type list_iter_t;
- bl_t* bl; 指向list本身
- list_t* ls; 指向buffers_t,存储ptr的链表
- list_iter_t p; buffers_t的迭代器
- unsigned off; 相对于list.begin()的绝对偏移量,例如调用seek(o): off+=o;p_off更新为当前ptr内部的偏移量
- unsigned p_off; 在当前ptr中的偏移量,如此iterator指向ptr,则实际数据位置位于:_raw[ptr->_off+p_off]
iterator_impl中提供了copy的接口函数,主要是用于decode,将list中的数据拷贝出来。
template<bool is_const>
void buffer::list::iterator_impl<is_const>::copy(unsigned len, char *dest)
代码实现:
- seek(off): 定位iterator的数据位置,off是绝对偏移量,p指向对应的ptr,p_off在此ptr中的偏移量
- 数据读取,p->lenth()-p_off,ptr中包含的数据
- p->copy_out,调用ptr copy_out方法,读取数据
- *this += howmuch,定位下一次需要读取的数据位置
if (p == ls->end()) seek(off);
while (len > 0) {
if (p == ls->end())
throw end_of_buffer();
unsigned howmuch = p->length() - p_off;
if (len < howmuch) howmuch = len;
p->copy_out(p_off, howmuch, dest);
dest += howmuch;
len -= howmuch;
*this += howmuch;
}
list的接口函数:
向list中存储长度为len的数据
- free_in_last: 获取list中剩余空间,实际即是_carriage的剩余空间;get_append_buffer_unused_tail_length: _carriage->unused_tail_length()
- first_round: min(len, free_in_last),先将数据存储在剩余空间
- 判断_carriage是不是list中的最后一个元素,(1. 非通过list接口存储过ptr*,(2. _buffers被std::move(),或是claim_append(),则_carriage!=_buffers.back());
_carriage != &_buffers.back():
- 创建一个新的ptr,ptr指向的raw与_carriage是同一个raw
- 更新_carriage为新的ptr
- _buffers存储新的ptr
- _num自增
auto bptr = ptr_node::create(*_carriage, _carriage->length(), 0);
_carriage = bptr.get();
_buffers.push_back(*bptr.release());
_num += 1;
- _carriage存储第一部分数据
- 计算剩余待存储的数据
- 创建一个新的ptr=new_back,指向一个新建的raw缓存,更新_carriage = new_back, list::push_back(new_back)
- new_back.append()存储剩余的数据
auto& new_back = refill_append_space(second_round);
new_back.append(data + first_round, second_round);
auto refill_append_space(len):
{
/*
** 数据对齐
*/
size_t need = round_up_to(len, sizeof(size_t)) + sizeof(raw_combined);
size_t alen = round_up_to(need, CEPH_BUFFER_ALLOC_UNIT) - sizeof(raw_combined);
auto new_back = ptr_node::create(raw_combined::create(alen, 0, get_mempool()));
new_back->set_length(0); // unused, so far.
_carriage = new_back.get();
_buffers.push_back(*new_back.release());
_num += 1;
return _buffers.back();
}
encode接口:append的实现代码如下:
void buffer::list::append(const char *data, unsigned len)
{
_len += len;
const unsigned free_in_last = get_append_buffer_unused_tail_length();
const unsigned first_round = std::min(len, free_in_last);
if (first_round) {
// _buffers and carriage can desynchronize when 1) a new ptr
// we don't own has been added into the _buffers 2) _buffers
// has been emptied as as a result of std::move or stolen by
// claim_append.
if (unlikely(_carriage != &_buffers.back())) {
auto bptr = ptr_node::create(*_carriage, _carriage->length(), 0);
_carriage = bptr.get();
_buffers.push_back(*bptr.release());
_num += 1;
}
_carriage->append(data, first_round);
}
const unsigned second_round = len - first_round;
if (second_round) {
auto& new_back = refill_append_space(second_round);
new_back.append(data + first_round, second_round);
}
}
decode的接口: list::iterator_impl<is_const>::copy(unsigned len, char *dest):
bufferlist中的数据拷贝至dest,数据长度为len:
- 定位至数据开始位置
- 循环读取迭代器中的数据
template<bool is_const>
void buffer::list::iterator_impl<is_const>::copy(unsigned len, char *dest)
{
if (p == ls->end()) seek(off);
while (len > 0) {
if (p == ls->end())
throw end_of_buffer();
unsigned howmuch = p->length() - p_off;
if (len < howmuch) howmuch = len;
p->copy_out(p_off, howmuch, dest);
dest += howmuch;
len -= howmuch;
*this += howmuch;
}
}
**部分数据结构注释: **
以下数据结构用于获取相邻的可写空间:
struct reserve_t {
char* bp_data; // ptr数据结尾,剩余空间头
unsigned* bp_len; // ptr指针数据长度
unsigned* bl_len; // bufferlist的数据长度
};
class contiguous_appender {
ceph::bufferlist& bl;
ceph::bufferlist::reserve_t space;
char* pos;
bool deep;
/// running count of bytes appended that are not reflected by @pos
size_t out_of_band_offset = 0;
contiguous_appender(bufferlist& bl, size_t len, bool d)
: bl(bl),
space(bl.obtain_contiguous_space(len)),
pos(space.bp_data),
deep(d) {
}
}
/*
** 获取相邻可写空间的接口
** 1. 判断当前_carriage剩余空间是否满足需求
** 1.1 不满足,新建一个raw缓冲区,更新_carriage
** 1.2 满足,利用现有的_carriage缓冲区
** 返回 reserve_t,指向对应的缓冲区
*/
reserve_t obtain_contiguous_space(const unsigned len)
{
// note: if len < the normal append_buffer size it *might*
// be better to allocate a normal-sized append_buffer and
// use part of it. however, that optimizes for the case of
// old-style types including new-style types. and in most
// such cases, this won't be the very first thing encoded to
// the list, so append_buffer will already be allocated.
// OTOH if everything is new-style, we *should* allocate
// only what we need and conserve memory.
if (unlikely(get_append_buffer_unused_tail_length() < len)) {
auto new_back = buffer::ptr_node::create(buffer::create(len)).release();
new_back->set_length(0); // unused, so far.
_buffers.push_back(*new_back);
_num += 1;
_carriage = new_back;
return { new_back->c_str(), &new_back->_len, &_len };
} else {
if (unlikely(_carriage != &_buffers.back())) {
auto bptr = ptr_node::create(*_carriage, _carriage->length(), 0);
_carriage = bptr.get();
_buffers.push_back(*bptr.release());
_num += 1;
}
return { _carriage->end_c_str(), &_carriage->_len, &_len };
}
}
class contiguous_filler: 用于encode时,为元数据预留空间
buffers_t的数据结构如下:
class buffers_t {
/*
** _root用于连接ptr的头尾指针,本身无内容
*/
ptr_hook _root;
ptr_hook* _tail;
public:
/*
** buffers_t的迭代器
*/
template <class T>
class buffers_iterator {
public:
using value_type = T;
using reference = typename std::add_lvalue_reference<T>::type;
using pointer = typename std::add_pointer<T>::type;
using difference_type = std::ptrdiff_t;
using iterator_category = std::forward_iterator_tag;
};
typedef buffers_iterator<const ptr_node> const_iterator;
typedef buffers_iterator<ptr_node> iterator;
typedef const ptr_node& const_reference;
typedef ptr_node& reference;
};
encode、decode方法
前述内容中介绍了raw/ptr/list的定义及数据结构,encoding.h中定义了对不同类型变量的encode及decode的方法。
如下定义了char float double bool 等类型的encode/decode接口,Bool类型以一字节存储.
template<class T>
inline void encode_raw(const T& t, bufferlist& bl)
{
bl.append((char*)&t, sizeof(t));
}
template<class T>
inline void decode_raw(T& t, bufferlist::const_iterator &p)
{
p.copy(sizeof(t), (char*)&t);
}
#define WRITE_RAW_ENCODER(type) \
inline void encode(const type &v, ::ceph::bufferlist& bl, uint64_t features=0) { ::ceph::encode_raw(v, bl); } \
inline void decode(type &v, ::ceph::bufferlist::const_iterator& p) { ::ceph::decode_raw(v, p); }
WRITE_RAW_ENCODER(char)
WRITE_RAW_ENCODER(float)
WRITE_RAW_ENCODER(double)
inline void encode(const bool &v, bufferlist& bl) {
__u8 vv = v;
encode_raw(vv, bl);
}
inline void decode(bool &v, bufferlist::const_iterator& p) {
__u8 vv;
decode_raw(vv, p);
v = vv;
}
针对自定义类型,实际是调用类中自定义的encode方法:
#define WRITE_CLASS_ENCODER(cl) \
inline void encode(const cl& c, ::ceph::buffer::list &bl, uint64_t features=0) { \
ENCODE_DUMP_PRE(); c.encode(bl); ENCODE_DUMP_POST(cl); } \
inline void decode(cl &c, ::ceph::bufferlist::const_iterator &p) { c.decode(p); }
#define WRITE_CLASS_MEMBER_ENCODER(cl) \
inline void encode(const cl &c, ::ceph::bufferlist &bl) const { \
ENCODE_DUMP_PRE(); c.encode(bl); ENCODE_DUMP_POST(cl); } \
inline void decode(cl &c, ::ceph::bufferlist::const_iterator &p) { c.decode(p); }
#define WRITE_CLASS_ENCODER_FEATURES(cl) \
inline void encode(const cl &c, ::ceph::bufferlist &bl, uint64_t features) { \
ENCODE_DUMP_PRE(); c.encode(bl, features); ENCODE_DUMP_POST(cl); } \
inline void decode(cl &c, ::ceph::bufferlist::const_iterator &p) { c.decode(p); }
#define WRITE_CLASS_ENCODER_OPTIONAL_FEATURES(cl) \
inline void encode(const cl &c, ::ceph::bufferlist &bl, uint64_t features = 0) { \
ENCODE_DUMP_PRE(); c.encode(bl, features); ENCODE_DUMP_POST(cl); } \
inline void decode(cl &c, ::ceph::bufferlist::const_iterator &p) { c.decode(p); }
以自定义类型示例:
- 定义encode方法
- 定义decode方法
- 调用WRITE_CLASS_ENCODER(rgw_data_change),生成关于此自定义类型的encode/decode方法
struct rgw_data_change {
DataLogEntityType entity_type;
string key;
real_time timestamp;
void encode(bufferlist& bl) const {
ENCODE_START(1, 1, bl);
uint8_t t = (uint8_t)entity_type;
encode(t, bl);
encode(key, bl);
encode(timestamp, bl);
ENCODE_FINISH(bl);
}
void decode(bufferlist::const_iterator& bl) {
DECODE_START(1, bl);
uint8_t t;
decode(t, bl);
entity_type = (DataLogEntityType)t;
decode(key, bl);
decode(timestamp, bl);
DECODE_FINISH(bl);
}
void dump(Formatter *f) const;
void decode_json(JSONObj *obj);
};
WRITE_CLASS_ENCODER(rgw_data_change)
ENCODE_START(v, compat, bl)
- 计算元数据大小
- 在list中为元数据预留空间
- 预留空间的起始位置即为filler
/*
** 开始encoding模块
**
** @param v 当前encoding版本
** @param 能够decode的最老版本
** @param bl bufferlist
** Feature:
** bufferlist中预留空间用于存储v,compat,及数据长度
** filler: list::contiguous_filler,包含一个char* pos,指向预留空间的头
**
*/
#define ENCODE_START(v, compat, bl) \
__u8 struct_v = v; \
__u8 struct_compat = compat; \
ceph_le32 struct_len; \
auto filler = (bl).append_hole(sizeof(struct_v) + sizeof(struct_compat) + sizeof(struct_len)); \
const auto starting_bl_len = (bl).length(); \
using ::ceph::encode; \
do {
ENCODE_FINISH(bl)
encode收尾工作:
- 将struct_v、struct_compat、struct_len数据写入预留空间
/**
* finish encoding block
*
* @param bl bufferlist we were encoding to
* @param new_struct_compat struct-compat value to use
*/
#define ENCODE_FINISH_NEW_COMPAT(bl, new_struct_compat) \
} while (false); \
if (new_struct_compat) { \
struct_compat = new_struct_compat; \
} \
struct_len = (bl).length() - starting_bl_len; \
filler.copy_in(sizeof(struct_v), (char *)&struct_v); \
filler.copy_in(sizeof(struct_compat), (char *)&struct_compat); \
filler.copy_in(sizeof(struct_len), (char *)&struct_len);
#define ENCODE_FINISH(bl) ENCODE_FINISH_NEW_COMPAT(bl, 0)
decode(v,bl)
- decode出struct_compat,判断当前版本能否decode,v>=struct_compat说明可以decode
- 解析其余元数据,如struct_v、struct_len等数据
- 依次decode其余数据
/*
** start a decoding block
**
** @param v current version of the encoding that the code supports/encodes
** @param bl bufferlist::iterator for the encoded data
*/
#define DECODE_START(v, bl) \
__u8 struct_v, struct_compat; \
using ::ceph::decode; \
decode(struct_v, bl); \
decode(struct_compat, bl); \
if (v < struct_compat) \
throw ::ceph::buffer::malformed_input(DECODE_ERR_OLDVERSION(__PRETTY_FUNCTION__, v, struct_compat)); \
__u32 struct_len; \
decode(struct_len, bl); \
if (struct_len > bl.get_remaining()) \
throw ::ceph::buffer::malformed_input(DECODE_ERR_PAST(__PRETTY_FUNCTION__)); \
unsigned struct_end = bl.get_off() + struct_len; \
do {
DECODE_FINISH(bl)
- 对数据长度等做校验
- bl.get_off: return off;返回绝对偏移量
- struct_end: 根据struct_len计算出的数据结尾的绝对偏移量
- 如果off>struct_end: 说明读取了不该读取的内容
/**
* finish decode block
*
* @param bl bufferlist::iterator we were decoding from
*/
#define DECODE_FINISH(bl) \
} while (false); \
if (struct_end) { \
if (bl.get_off() > struct_end) \
throw ::ceph::buffer::malformed_input(DECODE_ERR_PAST(__PRETTY_FUNCTION__)); \
if (bl.get_off() < struct_end) \
bl += struct_end - bl.get_off(); \
}
使用
- 定义类中的encode/decode方法
- 类外: WRITE_CLASS_ENCODER(rgw_data_change),声明针对此类的encode、decode方法
encode:
rgw_data_change instance;
bufferlist bl;
encode(instance,bl);
decode:
bufferlist bl;
rgw_data_change instance;
read(bl);
auto iter = bl.cbegin();
decode(instance, iter);
链接:https://www.jianshu.com/p/6c8b361cc665
来源:简书


