

【性能】Linux 页表、透明大页|大页内存|TLB和大页测试工具和指令
目录
Huge pages ( 标准大页 ) 和 Transparent Huge pages( 透明大页 )
作者:bandaoyu 链接:https://blog.csdn.net/bandaoyu/article/details/113352282
页表与MMU
CPU访问的是什么地址(虚拟地址,物理地址)?
其实CPU根本不关心它访问的是物理地址还是虚拟地址,它只访问一个地址,然后从数据线上获取数据。
启用MMU时,CPU访问地址是向MMU发送地址,然后从MMU获得数据,虚拟地址经过MMU转化为物理地址,从而访问外部内存里的数据。
禁用MMU时,CPU访问物理地址。
MMU如何工作
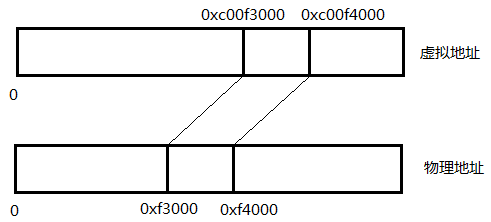
映射.png
页表:就是记录虚拟地址到物理地址映射规则的集合。
内存以4K为单位分成一块一块的,页表记录每一块物理内存的首地址和虚拟地址的映射关系,即只需记录上图中0xC00F3000和0xF3000之间的映射即可。
MMU是如何将虚拟地址转化为物理地址呢,它会去查询页表。
也就是说,MMU将虚拟地址转换为物理地址,不是按一个一个地址转换的,是以4k一页为单位转换的。
MMU中有几个概念:
PTE:页表项,即某条具体的转换规则,例如0x84050000这一页映射到0x8000物理页。
TLB:MMU中的cache,用来缓存最近用过的PTE

MMU对内存的保护
mmu的pte转换时按照4k大小的页为单位,32bit有12个bit是用不上的,在这些bit中设置访问权限的属性,如禁止访问、可读、可写和可执行等。
4K(12bit)为单位的MMU映射意味着,需要2^20 个条目用来映射4G空间,即占用4M内存(32bit=4byte*2^20 =4byte*1M=4M)。
每个进程的页表都是不同的(前3G映射不同,后1G相同),所以切换进程时候会将该进程的页表地址写进MMU中,从而更新整个MMU的映射规则。
为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage),后面我们以大页为重点。
多级页表
从上面可以看出,因为各个进程映射不同,每个进程必须有独立的页表。
系统中如果有100个进程,则需要4*100=400M内存来存储页表,这是不行的。那么能不能不映射一些页呢? 不行,4G的空间哪些不用是未知的,所以必须提前都预留映射。
假如一个进程需要使用100M的内存,那么1M个页表项中只有25k个是有用的,使用率百分之二,剩下的3.98M页表内存都浪费掉了。
想要节省页表内存,就不能以4K为单位映射,要以4M为单位映射,页表只需要1K个,占用4K内存。每一个页表项指向4M的地址,需要第二级页表,第二级页表按照4k为单位映射的话,每个4M需要1k个页表项,占用4k内存。再算算上述一个进程需要100M内存,首先一级页表是4K,二级页表只需要25张*4k,全部页表只占用104k内存,相比4M节省了大部分内存,仅浪费了3.99K的内存。
可以看到,使用多级页表,不仅节省每个进程的页表占用的内存,还能根据进程使用内存不同动态的调整页表占用内存的大小。
下面是一个虚拟地址0x3213 2160通过二级页表映射到物理地址的过程
事实上,在ARM架构中,这个访问过程是硬件实现的,但是页表的填充是软件维护的
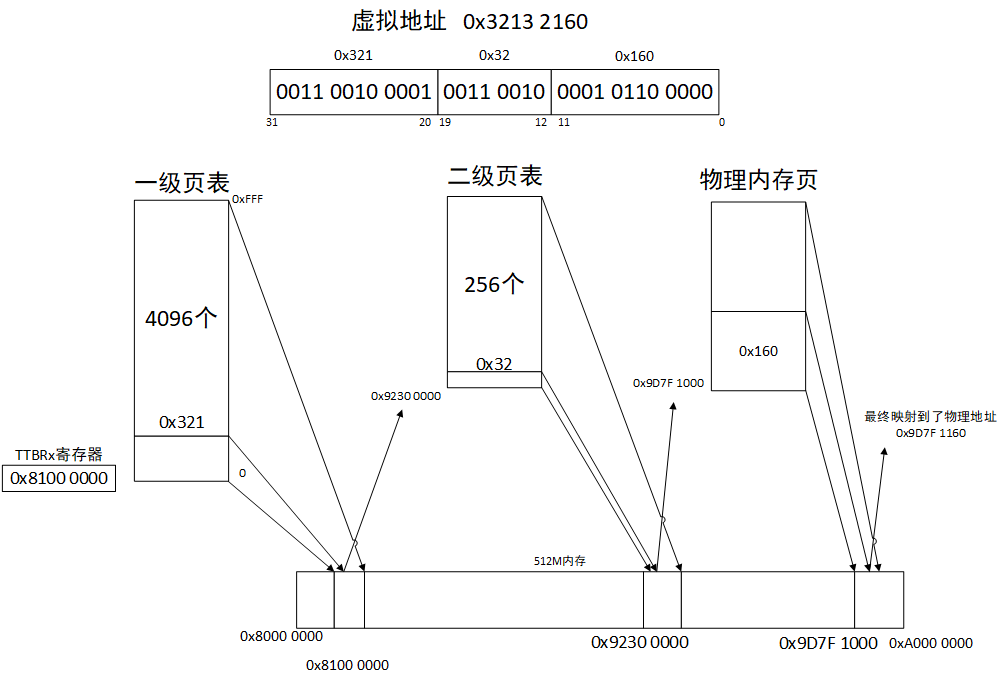
image.png
彩蛋:说到MMU,有个问题:为什么Uboot要关掉mmu?
kernel启动对环境是由要求的,关掉mmu,关掉dcache,icache无所谓
一、 内存映射与页表
1. 内存映射
我们通常所说的内存容量,指的是物理内存,只有内核才可以直接访问物理内存,进程并不可以。
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长(单个 CPU 指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和64 位系统:

既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。内存映射,其实就是将虚拟内存地址映射到物理内存地址。
2. 页表
为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:

页的大小只有 4 KB ,导致的另一个问题就是,当物理内存很大时,页表会变得非常大,占用大量物理内存。
4. 页表的简单工作原理
下图是比较简单情况下的示意图,用于描述在32位系统下,页大小为4K时,操作系统如何为进程的虚拟地址和实际物理地址进行转换:
-
目录表,是用于索引页表的数据结构,其中存储着目录项(共1024个、每个4B,因此目录表共4B*1024=4K ),每个目录项指向一个页表,即可以存储1024个页表。
-
页表,用来存放物理地址页的起始地址,即页表项(也是共1024个、每个4B,因此一个页表的大小也是4K),由于目录表最多可存1024个页表,因此页表的最大大小是1024*4K=4M。
-
页表项,每个页表项指向4K的物理内存页,因此页表一共可以指向的物理内存大小为:1024(页表数)*1024(每个页表的页表项数)*4K(一个页表项指向的物理内存大小)=4G
假如一个进程,访问的物理内存有1GB,即262144个内存页,在32位系统中,页表需要262144*4/1024/1024=1MB,而在64位系统下,页表占用的空间增加1倍,即2MB。
对于Linux系统中运行的Oracle数据库,假如数据库的SGA大小12GB,如果一个Oracle Process访问到了所有的SGA内存,其页表大小会是24MB,如果有300个左右的会话,那么这300个连接的页表会达到7200MB,只不过并不是每个进程都会访问到SGA中所有的内存。
页表大小可以通过 /proc/meminfo 的 PageTables部分查看。
Linux 页表、大页与透明大页_Hehuyi_In的博客-CSDN博客_linux 大页
大页
什么是大内存页huge page?
“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
为什么使用“大内存页”?
在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
Linux大页内存(hugepage)使用_weixin_35664258的博客-CSDN博客_查看大页内存
大页顾名思义,就是比较大的页,通常是2MB。由于页变大了,需要的页表项也就少了,占用物理内存也减少了。
(假设应用程序需要 2MB 的内存,如果操作系统以 4KB 作为分页的单位,则需要 512 个页面,进而在 TLB 中需要 512 个表项,同时也需要 512 个页表项,操作系统需要经历至少 512 次 TLB Miss 和 512 次缺页中断才能将 2MB 应用程序空间全部映射到物理内存;然而,当操作系统采用 2MB 作为分页的基本单位时,只需要一次 TLB Miss 和一次缺页中断,就可以为 2MB 的应用程序空间建立虚实映射,并在运行过程中无需再经历 TLB Miss 和缺页中断(假设未发生 TLB 项替换和 Swap)。
为了能以最小的代价实现大页面支持,Linux 操作系统采用了基于 hugetlbfs 特殊文件系统 2M 字节大页面支持。这种采用特殊文件系统形式支持大页面的方式,使得应用程序可以根据需要灵活地选择虚存页面大小,而不会被强制使用 2MB 大页面。)
1. 大页的优点
- 减少页表大小。每个Huge Page对应的是连续的2MB物理内存,这样12GB的物理内存只需要48KB的页表,与原来的24MB相比减少很多。
- Huge Page内存只能锁定在物理内存中,不能被交换到交换区,避免了交换引起的性能影响。
- 由于页表数量的减少,使得CPU中的TLB(可理解为CPU对页表的CACHE)命中率大大提高。
- Huge Page的页表在各进程之间可以共享,也降低了Page Table的大小。
2. 大页的缺点
- 要预先分配
- 不够灵活,需要重启主机生效
- 如果分配过多,会造成浪费,不能被其他程序使用。
分配的大页内存被钉住,不能swap出去,那么即使这些内存是空闲的,其他程序也抢不过来。此时即使free -g的buff/cache available 不为0,其他进程也拿不到这些内存。如果此时free为0就会出现无内存资源可用. (?待证实)
[SDS_Admin@rdma57 ~]$ free -g
total used free shared buff/cache available
Mem: 125 94 0 0 30 29
Swap: 3 1 2大页面内存引起的杯具_mseaspring的博客-CSDN博客
大内存页适用范围
大页内存也有适用范围,程序耗费内存很小或者程序的访存局部性很好,大页内存很难获得性能提升。所以,如果你面临的程序优化问题有上述两个特点,请不要考虑大页内存。
3. 大页的分配方法
1、检查/proc/meminfo,确认系统支持HugePage
[root@localhost ~]# cat /proc/meminfo | grep -i huge
AnonHugePages: 47708160 kB //透明页/proc/meminfo之谜 | Linux Performance
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
[root@localhost ~]#
Hugepagesize有值,说明系统支持large pages(如不支持,系统需要重新编译来支持)
HugePages Total表示系统中配置的大页数。
HugePages Free表示没有访问过的大页数,free容易引起误解,稍后会解释。
HugePages Rsvd表示已经分配但是还未使用的页面数。
Hugepagesize表示支持的大页size,这里为2MB,在有的内核配置中可能为4MB。
HugePages_Surp is short for "surplus," and is the number of huge pages in
the pool above the value in /proc/sys/vm/nr_hugepages. The
maximum number of surplus huge pages is controlled by
/proc/sys/vm/nr_overcommit_hugepages.(更详细的参数说明:https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt)
解释:
比如HugePages总计11GB,orcale程序的SGA_MAX_SIZE为10GB,SGA_TARGET为8GB。那么数据库启动后,会根据SGA_MAX_SIZE占用10GB内存,真正Free的HugePage内存为11-10=1G。但是SGA_TARGET只有8GB,那么会有2GB不会被访问到,则HugePage_Free为2+1=3GB,HugePage_Rsvd内存有2GB。这里实际上可以给其他实例使用的只有1GB,也就是真正意义上的Free只有1GB。
红帽说明:
14.3. Sizing Big Pages and Huge Pages Red Hat Enterprise Linux 5 | Red Hat Customer Portal
2、计划要设置的内存页数量
到目前为止,大页只能用于共享内存段等少量类型的内存。一旦将物理内存用作大页,那么这些物理内存就不能作其他用途,比如作为进程的私有内存。因此不能将过多的内存设置为大页。
通常将大页用作Oracle数据库的SGA,那么大页数量:HugePages_Total=ceil(需要的内存<SGA_MAX_SIZE>/Hugepagesize)+N
比如,为数据库设置的SGA_MAX_SIZE为18GB,那么页面数可以为ceil(18*1024/2)+2=9218。加N是需要将HugePage空间设置得比SGA_MAX_SIZE稍大,通常为1~2即可。
我们通过ipcs -m命令查看共享内存段的大小,可以看到共享内存段的大小实际上比SGA_MAX_SIZE略大。如果服务器上有多个Oracle实例,需要为每个实例考虑共享内存段多出的部分,即N值会更大。另外,Oracle数据库要么全部使用大内存页,要么完全不使用大内存页,因此不合适的HugePages_Total将造成内存的浪费。
除了使用SGA_MAX_SIZE计算,也可以通过ipcs -m所获取的共享内存段大小计算出更准确的HugePages_Total
HugePages_Total=sum(ceil(share_segment_size/Hugepagesize))
3、分配大页(设置大页)
- 修改/etc/sysctl.conf文件,增加:vm.nr_hugepages=9218,执行sysctl -p命令
然后检查/proc/meminfo,如果HugePages_Total小于设置的数量,表明没有足够的连续物理内存用于这些大内存页,需要重启服务器。
在/etc/security/limits.conf文件中增加如下行,设定oracle用户可以锁定内存的大小 ,以KB为单位,将memlock配置为unlimited也可以。
oracle soft memlock 18878464
oracle hard memlock 18878464
然后重新以oracle用户连接到数据库服务器,使用ulimit -a命令,可以看到:
max lockedmemory (kbytes, -l) 18878464
改为AUTO方式方式管理SGA
将SGA_TARGET_SIZE设为大于0的值。对于11g,由于HugePage只能用于共享内存,不能用于PGA,所以不能使用AMM,只能分别设置SGA和PGA,SGA同样只能是AUTO方式管理。
最后启动数据库,检查大页使用情况
检查/proc/meminfo中查看HugePages_Free是否已经减少。如果已经减少,表明已经使用到HugePage Memory。
三、 透明大页
在一些Linux系统中,transparent hugepage被默认开启,它允许大页做动态的分配,而不是系统启动后就分配好,根据Oracle MOS DOC:1557478.1,transparent hugepage导致了很多的问题,建议将其关闭。
Huge pages ( 标准大页 ) 和 Transparent Huge pages( 透明大页 )
LInux 标准大页和透明大页_Data & Analysis-CSDN博客_透明大页
在 Linux 中大页分为两种: Huge pages ( 标准大页 ) 和 Transparent Huge pages( 透明大页 ) 。
内存是以块即页的方式进行管理的,当前大部分系统默认的页大小为 4096 bytes 即 4K 。 1MB 内存等于 256 页; 1GB 内存等于 256000 页。
CPU 拥有内置的内存管理单元,包含这些页面的列表,每个页面通过页表条目引用。当内存越来越大的时候, CPU 需要管理这些内存页的成本也就越高,这样会对操作系统的性能产生影响。
Huge Pages
Huge pages 是从 Linux Kernel 2.6 后被引入的,目的是通过使用大页内存来取代传统的 4kb 内存页面, 以适应越来越大的系统内存,让操作系统可以支持现代硬件架构的大页面容量功能。
Huge pages 有两种格式大小: 2MB 和 1GB , 2MB 页块大小适合用于 GB 大小的内存, 1GB 页块大小适合用于 TB 级别的内存; 2MB 是默认的页大小。
Transparent Huge Pages
Transparent Huge Pages 缩写 THP ,这个是 RHEL 6 开始引入的一个功能,在 Linux6 上透明大页是默认启用的。
由于 Huge pages 很难手动管理,而且通常需要对代码进行重大的更改才能有效的使用,因此 RHEL 6 开始引入了 Transparent Huge Pages ( THP ), THP 是一个抽象层,能够自动创建、管理和使用传统大页。
THP 为系统管理员和开发人员减少了很多使用传统大页的复杂性 , 因为 THP 的目标是改进性能 , 因此其它开发人员 ( 来自社区和红帽 ) 已在各种系统、配置、应用程序和负载中对 THP 进行了测试和优化。这样可让 THP 的默认设置改进大多数系统配置性能。但是 , 不建议对数据库工作负载使用 THP 。
这两者最大的区别在于 : 标准大页管理是预分配的方式,而透明大页管理则是动态分配的方式。
标准大页的页面大小
[root@localhost ~]# grep Hugepagesize /proc/meminfo
Hugepagesize: 2048 kB
1. 查看是否启用
cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never] #未启用应该看到[never]
[always] madvise never #启用应该看到[always]
如果这个文件不存在,则检查
如果2个文件都不存在,说明系统内核中移除了THP,例如OEL 7。
2. 关闭透明大页
大页(huge pages) 系列四 ---Transparent HugePages_Lixora's DB Home-CSDN博客_[always] madvise never
How to check and disable transparent hugepages ( CentOS / RHEL 7 )
- Redhat & Centos
# 重启后失效
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
# 开机时设置never到以上文件中
vim /etc/rc.d/rc.local
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
chmod +x /etc/rc.d/rc.local
- SUSE Linux(区别在于开机设置never需要配置到的文件不同)
# 重启后失效
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
# 开机时设置never到以上文件中
vim /etc/init.d/boot.local
添加
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
chmod +x /etc/init.d/boot.local
参考
Oracle Memory Management and HugePage (连载二)_ITPUB博客
Oracle Memory Management and HugePage (连载三) _ITPUB博客
【云和恩墨】性能优化:Linux环境下合理配置大内存页(HugePage) - ^_^小麦苗^_^ - 博客园
《Linux性能优化实战》笔记(八)—— 内存是怎么工作的_Hehuyi_In的博客-CSDN博客
Linux之关闭大页【即关闭透明大页】_LawsonAbs's Spiritual Home-CSDN博客_关闭大页内存
HugePages on Oracle Linux 64-bit (文档 ID 361468.1)
使用大页实例
1.大页的作用
简单地说,linux的内存默认页大小是4K,大内存页是2M(或其他),Linux 操作系统上运行内存需求量较大的应用程序时,那么,cpu在对内存寻址的时候会寻多次地址找到所有的内存页,如果使用大内存页就会减少这种寻址次数,减少 TLB Miss 和缺页中断。如果使用大内存页就会减少这种寻址次数,比如在理想情况下,使用4KB页,cpu一次寻址2G的数据,如果是一般内存页,会寻1024*1024/2(2*1024*1024KB/4KB)次,如果是大内存页2M,会寻址1024次,前者是后者的516倍。当操作系统以 2MB 甚至更大作为分页的单位时,将会大大减少 TLB Miss 和缺页中断的数量,显著提高应用程序的性能。
2.大页的设置方法
查看操作系统是否支持大页
grep -i huge /proc/meminfo
hugepagesize的大小表示系统支持的大内存页的大小
查看大页尺寸及状态(未开启):
>cat /proc/meminfo | grep -i huge
AnonHugePages: 1265664 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
打开大页需要在操作系统上更改配置。
更改系统配置:
vi /etc/security/limits.conf 添加:
# HugePage up limit
* soft memlock 816521216 --778GB,物理主机1T内存
* hard memlock 816521216 --778GB
或指定哪个OS用户可以使用大页
# HugePage up limit
oracle soft memlock 5242880 --5G,物理主机8G内存
oracle hard memlock 5242880
memlock以K为单位的,可以让它的值稍微比系统的物理内存小就可以了。
查看oracle或mysql OS账户对应的group id,用对应账号登录linux,输入:
>id
uid=1036(mysql) gid=1038(mysql) groups=1038(mysql),500(oinstall)
vi /etc/sysctl.conf
vm.hugetlb_shm_group = 500
#使用mysql所在组ID
vm.nr_hugepages = 256885
#分配大页内存为 256885*2048KB=501GB,值略小于memlock
kernel.shmmax = 540938977280
--503GB配置了最大的内存segment的大小,这个设置应该比数据库定义使用的内存大小大一些。
kernel.shmall = 105652145
--单位为默认页大小4KB,shmall是全部允许使用的共享内存大小,shmmax是单个段允许使用的大小。shmall的大小为 105652145*4k/1024/1024=403GB
执行下面的命令 使上面的设置立即生效
/sbin/sysctl -p
对于内存为4G的服务器设置如下:
vi etc/security/limits.conf
# HugePage up limit,--3.5G
mysql soft memlock 3670016
mysql hard memlock 3670016
vi etc/sysctl.conf
vm.hugetlb_shm_group = 500
vm.nr_hugepages = 1024
在mysql配置my.cnf中添加large-pages启动大页
[mysqld]
large-pages
确认大页已被使用:
>cat /proc/meminfo | grep -i huge
AnonHugePages: 776192 kB
HugePages_Total: 1024
HugePages_Free: 1010
HugePages_Rsvd: 118
HugePages_Surp: 0
Hugepagesize: 2048 kB
配置大页后的性能比较:
1. 未开hugepage
>cat /proc/meminfo | grep -i huge
AnonHugePages: 546816 kB
HugePages_Total: 1024
HugePages_Free: 1024
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
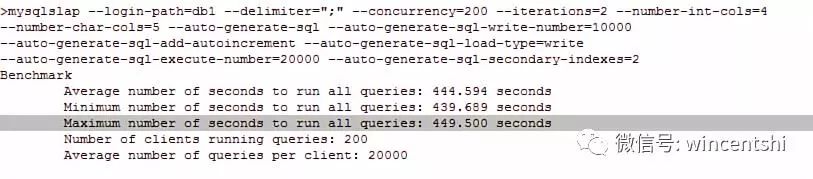
2. 启动大页:
vi ./db1.cnf
[mysqld]
large-pages
>cat proc/meminfo | grep -i huge
AnonHugePages: 339968 kB
HugePages_Total: 1024
HugePages_Free: 983
HugePages_Rsvd: 949
HugePages_Surp: 0
Hugepagesize: 2048 kB
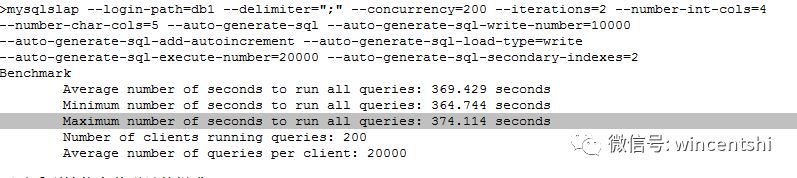
可以看到性能有着明显的提升。
1.大页的作用
简单地说,linux的内存默认页大小是4K,大内存页是2M(或其他),当内存使用较高,那么,cpu在对内存寻址的时候会寻多次地址找到所有的内存页,如果使用大内存页就会减少这种寻址次数,
如果使用大内存页就会减少这种寻址次数,比如在理想情况下,使用4KB页,cpu一次寻址2G的数据,如果是一般内存页,会寻1024*1024/2(2*1024*1024KB/4KB)次,如果是大内存页2M,会寻址1024次,前者是后者的516倍,所以在业务量较大时,大页会提高服务器性能。
2.大页的设置方法
查看操作系统是否支持大页
grep -i huge /proc/meminfo
hugepagesize的大小表示系统支持的大内存页的大小
如果大页为2M,要设置的SGA(SGA:SystemGlobal Area是OracleInstance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓.)为1.2G,页数=1.2*1024/2=918.2
实际页数应比这个稍大,在/etc/sysctl.conf中添加行
vm.nr_hugepages = 980
sysctl –p 生效
在/etc/security/limits.conf中添加行,memlock值应比大页值大,我这里设置的是3G
oracle hard memlock 3145728
oracle soft memlock 3145728
grid hard memlock 3145728
grid soft memlock 3145728
3 如何判断大页是否设置成功
grep -i huge /proc/meminfo
hugepagetotal的值=刚才设置的vm.nr_hugepages就可以了
4设置大页应注意的问题
1.数据库中use_large_page为true
2.设置了内存大页后不能使用AMM,只能用 ASMM,PGA自动管理,或者手动管理数据库内存
转载于:http://blog.itpub.net/31461640/viewspace-2140317/
2.1 Hugepages
Hugepages在/proc/meminfo中是被独立统计的,与其它统计项不重叠,既不计入进程的RSS/PSS中,又不计入LRU Active/Inactive,也不会计入cache/buffer。如果进程使用了Hugepages,它的RSS/PSS不会增加。
注:不要把 Transparent HugePages (THP)跟 Hugepages 搞混了,THP的统计值是/proc/meminfo中的”AnonHugePages”,在/proc/<pid>/smaps中也有单个进程的统计,这个统计值与进程的RSS/PSS是有重叠的,如果用户进程用到了THP,进程的RSS/PSS也会相应增加,这与Hugepages是不同的。
在/proc/meminfo中与Hugepages有关的统计值如下:
| 1 2 3 4 5 6 7 | MemFree: 570736 kB ... HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB |
HugePages_Total 对应内核参数 vm.nr_hugepages,也可以在运行中的系统上直接修改 /proc/sys/vm/nr_hugepages,修改的结果会立即影响空闲内存 MemFree的大小,因为HugePages在内核中独立管理,只要一经定义,无论是否被使用,都不再属于free memory。在下例中我们设置256MB(128页)Hugepages,可以立即看到Memfree立即减少了262144kB(即256MB):
| 1 2 3 4 5 6 7 8 9 10 | # echo 128 > /proc/sys/vm/nr_hugepages # cat /proc/meminfo ... MemFree: 308592 kB ... HugePages_Total: 128 HugePages_Free: 128 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB |
使用Hugepages有三种方式:
(详见 https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt)
- mount一个特殊的 hugetlbfs 文件系统,在上面创建文件,然后用mmap() 进行访问,如果要用 read() 访问也是可以的,但是 write() 不行。
- 通过shmget/shmat也可以使用Hugepages,调用shmget申请共享内存时要加上 SHM_HUGETLB 标志。
- 通过 mmap(),调用时指定MAP_HUGETLB 标志也可以使用Huagepages。
用户程序在申请Hugepages的时候,其实是reserve了一块内存,并未真正使用,此时/proc/meminfo中的 HugePages_Rsvd 会增加,而 HugePages_Free 不会减少。
| 1 2 3 4 5 | HugePages_Total: 128 HugePages_Free: 128 HugePages_Rsvd: 128 HugePages_Surp: 0 Hugepagesize: 2048 kB |
等到用户程序真正读写Hugepages的时候,它才被消耗掉了,此时HugePages_Free会减少,HugePages_Rsvd也会减少。
| 1 2 3 4 5 | HugePages_Total: 128 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB |
/proc/meminfo之谜 | Linux Performance
《程序性能优化提升方法之-内存大页》程序性能优化提升方法之-内存大页-qgx2009-ChinaUnix博客
查看缺页中断统计
可通过以下命令查看缺页中断信息
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中:
majflt代表major fault,中文名叫大错误,
minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
发成缺页中断后,执行了那些操作?
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
1、检查要访问的虚拟地址是否合法
2、查找/分配一个物理页
3、填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
4、建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
linux内存分配机制:Linux内存分配小结--malloc、brk、mmap_gfgdsg的专栏-CSDN博客_mmap分配内存(malloc和free是如何分配和释放内存?)
【测试】TLB和大页测试工具和指令
如何查看TLB miss?
perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses -p $PID
Performance counter stats for process id '21047':
627,809 dTLB-loads
8,566 dTLB-load-misses # 1.36% of all dTLB cache hits
2,001,294 iTLB-loads
3,826 iTLB-load-misses # 0.19% of all iTLB cache hits
多个进程
perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses -p $PID1,$PID2,$PID3……
(TLB缓存是个神马鬼,如何查看TLB miss? - 知乎)
perf 可探测 的所有 event ,均可以使用命令perf list获得。
本文举几个和内存相关的性能的几个event例子
探测 进程 的缺页中断数(page fault)
perf stat -e faults ./mem
能够统计 ./mem 执行 周期内,引发的 缺页中断数。
Performance counter stats for './mem':
100,126 faults
0.203315268 seconds time elapsed
探测正在运行的进程,则使用
perf stat -e faults -p $PID运行,命令掐断后,打印出命令开始到命令结束时,目标进程的缺页中断数。
可以 使用 perf record来探测 指定 event 的热点函数,例如
perf record -e faults ./mem
使用
perf report
输出结果。
Samples: 655 of event 'faults', Event count (approx.): 100151
Overhead Command Shared Object Symbol
99.57% mem mem [.] func
0.35% mem ld-2.17.so [.] _dl_lookup_symbol_x
0.06% mem ld-2.17.so [.] _dl_important_hwcaps
0.01% mem ld-2.17.so [.] _dl_start
0.00% mem ld-2.17.so [.] _start
0.00% mem [kernel.vmlinux] [k] __clear_user
0.00% mem [kernel.vmlinux] [k] copy_user_enhanced_fast_string
原理
在内核缺页中断处,有perf的钩子,用于统计缺页中断的次数:
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address);
内核源码中搜索 PERF_COUNT_SW_PAGE_FAULTS即可。
探测 进程 TLB相关event
perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses,L1-icache-load-misses ./mem
或者指定进程id进行探测
perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses,L1-icache-load-misses -p $PID
$perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses,L1-icache-load-misses ./mem
Performance counter stats for './mem':
89,946,326 dTLB-loads (80.09%)
17,030 dTLB-load-misses # 0.02% of all dTLB cache hits (40.47%)
10 iTLB-loads (39.96%)
137 iTLB-load-misses # 1370.00% of all iTLB cache hits (59.80%)
98,113 L1-icache-load-misses (79.65%)
0.201743107 seconds time elapsed
因为是 硬件event,所以不同的CPU架构,这些值代表的不一样。一样的是,dTLB代表了数据的TLB统计,iTLB代表的是指令的TLB统计。
相关 参考文档:http://web.eece.maine.edu/~vweaver/projects/perf_events/perf_event_open.html
————————————————
原文链接:https://blog.csdn.net/mrpre/article/details/83537311主机性能
| # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 |
CEPH 集群
查看ceph集群信息
#ceph -s
查看ceph默认配置:
# ceph --show-config
大页内存
查看操作系统是否支持大页
grep -i huge /proc/meminfo
hugepagesize的大小表示系统支持的大内存页的大小
查看大页尺寸及状态(未开启):
>cat /proc/meminfo | grep -i huge
AnonHugePages: 1265664 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
查看缺页中断统计:
可通过以下命令查看缺页中断信息
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中, majflt 代表 major fault ,指大错误, minflt 代表 minor fault ,指小错误。这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
其中 majflt 与 minflt 的不同是, majflt 表示需要读写磁盘,可能是内存对应页面在磁盘中需要 load 到物理内存中,也可能是此时物理内存不足,需要淘汰部分物理页面至磁盘中。
查看文件是否相同
md5sum -b 文件名


