

【RDMA】无损网络和PFC(基于优先级的流量控制)|ECN
目录
@bandaoyu 持续更新,链接: https://blog.csdn.net/bandaoyu/article/details/115346857
原文:《我们为什么需要RDMA?为什么需要无损网络?》https://www.sohu.com/a/258041228_100289134
(Priority-based Flow Control,基于优先级的流量控制)
前言
RDMA技术:降低数据中心内部网络延迟,提高处理效率。
当前RDMA在以太网上的传输协议是RoCEv2,RoCEv2是基于无连接协议的UDP协议,相比面向连接的TCP协议,UDP协议更加快速、占用CPU资源更少,但其不像TCP协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,依靠上层应用检查到了再做重传,会大大降低RDMA的传输效率。
所以要想发挥出RDMA真正的性能,突破数据中心大规模分布式系统的网络性能瓶颈,势必要为RDMA搭建一套不丢包的无损网络环境,而实现不丢包的关键就是解决网络拥塞。
(为什么需要无损网络:长期以来,HPC(高性能计算)的RDMA都是在Infiniband集群中使用,数据包丢失在此类群集中很少见,因此RDMA Infiniband传输层(在NIC上实现)的重传机制很简陋,既:go-back-N重传,但是现在RDMA的使用更广泛,在其他网络中,丢包的概率大于Infiniband集群,一旦丢包,使用RDMA的go-back-N重传机制效率非常低,会大大降低RDMA的传输效率,所以要想发挥出RDMA真正的性能,势必要为RDMA搭建一套不丢包的无损网络环境,go-back-N重传,见2.1 Infiniband RDMA and RoCE:https://blog.csdn.net/bandaoyu/article/details/115620365)
一、为什么会产生拥塞
产生拥塞的原因有很多,下面列举了在数据中心场景里比较关键也是比较常见的三点原因:
1.收敛比(总输入带宽/总的输出带宽)
进行数据中心网络架构设计时,从成本和收益两方面来考虑,多数会采取非对称带宽设计,即上下行链路带宽不一致,交换机的收敛比简单说就是总的输入带宽除以总的输出带宽。
交换机A:下行带宽480G,上行带宽240G,整机收敛比为2:1
交换机B:下行带宽1200G,上行带宽800G,整机收敛比为1.5:1
也就是说,当下联的服务器上行发包总速率超过上行链路总带宽时,就会在上行口出现拥塞。
2.ECMP(ECMP构建多条等价负载链路,HASH选择到已拥塞链路发送加剧拥塞)
当前数据中心网络多采用Fabric架构,并采用ECMP来构建多条等价负载的链路,并HASH选择一条链路来转发,是简单的,但这个过程没有考虑到所选链路本身是否有拥塞,对于已经产生拥塞的链路来说,很可能加剧链路的拥塞。
3.TCP Incast(多对一)
TCP Incast是Many-to-One(多对一)的通信模式,在数据中心云化的大趋势下这种通信模式常常发生,尤其是那些以Scale-Out方式实现的分布式存储和计算应用,包括Hadoop、MapReduce、HDFS等。
例如,当一个Parent Server向一组节点(服务器集群或存储集群)发起一个请求时,集群中的节点都会同时收到该请求,并且几乎同时做出响应,很多节点同时向一台机器(Parent Server)发送TCP数据流,从而产生了一个“微突发流”,使得交换机上连接Parent Server的出端口缓存不足,造成拥塞。
如下图,parent向所有node发出数据请求,多个node几乎同时向parent发出数据回复,形成多打一造成拥堵。
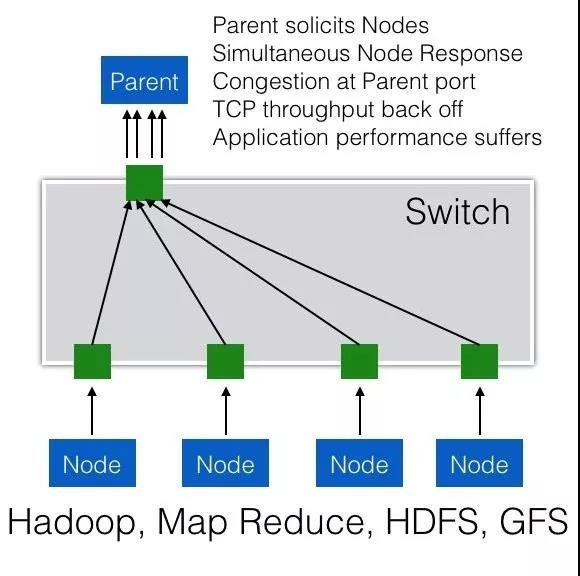
正如前面所说,RDMA和TCP不同,它需要一个无损网络。对于普通的微突发流量,交换机的Buffer缓冲区可以起到一定作用,在缓冲区将突发的报文进行列队等待,但由于增加交换机Buffer容量的成本非常高,所以它所能起到的作用是有限的,一旦缓冲区列队的报文过多,仍旧会产生丢包。
RDMA需要一个无损网络,交换机的Buffer缓冲应对网络拥堵防丢包作用有限,
为了实现端到端的无损转发,避免因为交换机中的Buffer缓冲区溢出而引发的数据包丢失,交换机必须引入其他机制,如流量控制,通过对链路上流量的控制,减少对交换机Buffer的压力,来规避丢包的产生。
二、PFC如何实现流控
(流控发展史:FC(整个链路流控)-->PFC(基于优先级流控)-->PFC+ECN(流控发生前避免拥塞)/PFC+ETS(分配带宽)+ECN)
IEEE 802.1Qbb(Priority-based Flow Control,基于优先级的流量控制)简称PFC,是流量控制的增强版。
FC(整个链路流控)
(下游发现拥堵,向上游发PAUSE帧)
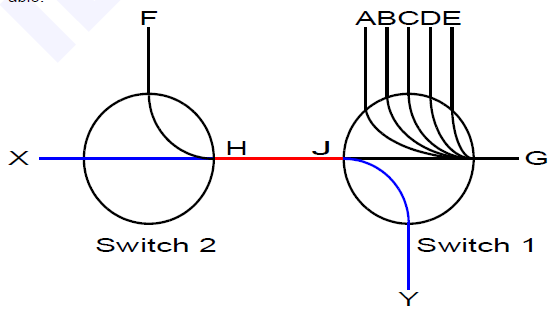
说PFC之前,我们可以先看一下IEEE 802.3X(Flow Control)流控的机制:当接收者没有能力处理接收到的报文时,为了防止报文被丢弃,接收者需要通知报文的发送者暂时停止发送报文。
如下图所示,端口G0/1和G0/2以1Gbps速率转发报文时,端口F0/1将发生拥塞。为避免报文丢失,开启端口G0/1和G0/2的Flow Control功能。
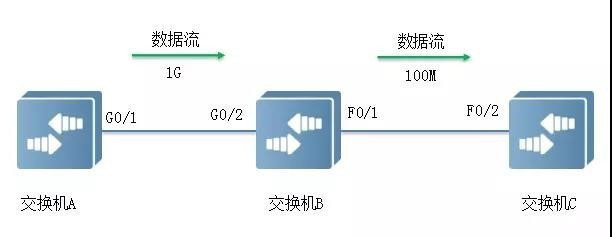
当F0/1在转发报文出现拥塞时,交换机B会在端口缓冲区中排队报文,当拥塞超过一定阈值时,端口G0/2向G0/1发PAUSE帧,通知G0/1暂时停止发送报文。
• G0/1接收到PAUSE帧后暂时停止向G0/2发送报文。暂停时间长短信息由PAUSE帧所携带。交换机A会在这个超时范围内等待,或者直到收到一个Timeout值为0的控制帧后再继续发送。
PFC(基于优先级流控)
(下游某一优先级发现拥堵,向上游某一优先级发PAUSE帧)
FC(IEEE 802.3X协议)缺点:一旦链路被暂停,发送方就不能再发送任何数据包,如果是因为某些优先级较低的数据流引发的暂停,结果却让该链路上其他更高优先级的数据流也一起被暂停了,其实是得不偿失的。
如下图中报文解析所示,PFC在基础流控IEEE 802.3X基础上进行扩展,允许在一条以太网链路上创建8个虚拟通道,并为每条虚拟通道指定相应优先级,允许单独暂停和重启其中任意一条虚拟通道,同时允许其它虚拟通道的流量无中断通过。

PFC将流控的粒度从物理(端口)细化到(8个虚拟通道),分别对应Smart NIC硬件上的8个硬件发送队列(这些队列命名为Traffic Class,分别为TC0,TC1,...,TC7),在RDMA不同的封装协议下,也有不同的映射方式。
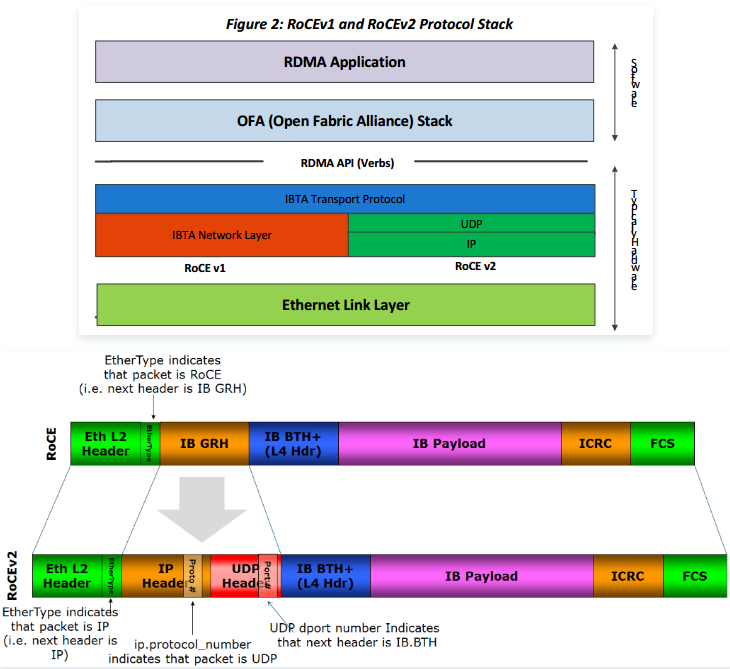
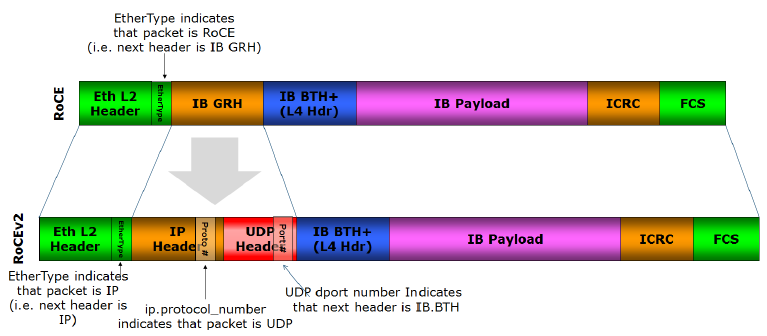
• RoCEv1(RDMA封装协议):
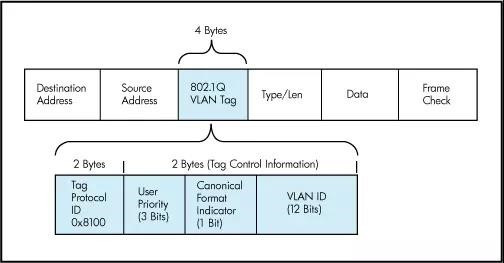
这个协议是将RDMA数据段封装到以太网数据段内,再加上以太网的头部,因此属于二层数据包。为了对它进行分类,只能使用VLAN(IEEE 802.1q)头部中的PCP(Priority Code Point)域3 Bits来设置优先级值。
RoCEv2(RDMA封装协议):
这个协议是将RDMA数据段先封装到UDP数据段内,加上UDP头部,再加上IP头部,最后再加上以太网头部,属于三层数据包。对它进行分类,既可以使用以太网VLAN中的PCP域,也可以使用IP头部的DSCP域。
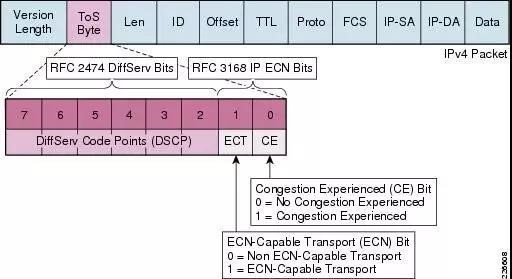
简单来说,在二层网络的情况下,PFC使用VLAN中的PCP位来对数据流进行区分,在三层网络的情况下,PFC既可以使用PCP、也可以使用DSCP,使得不同数据流可以享受到独立的流控制。当下数据中心因多采用三层网络,因此使用DSCP比PCP更具有优势。
RoCE 协议数据结构的详细说明:https://blog.csdn.net/bandaoyu/article/details/117560876
三、PFC存在的问题
- 死锁(PFCdeadlock)
虽然PFC能够通过给不同队列映射不同优先级来实现基于队列的流控,但同时也引入了新的问题,例如PFC死锁的问题。
PFC死锁,是指当多个交换机之间因微环路等原因同时出现拥塞,各自端口缓存消耗超过阈值,而又相互等待对方释放资源,从而导致所有交换机上的数据流都永久阻塞的一种网络状态。
正常情况下,当一台交换机的端口出现拥塞并触发XOFF水线时,即下游设备将发送PAUSE帧反压,上游设备接收到PAUSE帧后停止发送数据,如果上游设备本地端口缓存消耗超过阈值,则继续向上游反压。如此一级级反压,直到网络终端服务器在PAUSE帧中指定Pause Time内暂停发送数据,从而消除网络节点因拥塞造成的丢包。
但在特殊情况下,例如发生链路故障或设备故障时,BGP路由重新收敛期间可能会出现短暂环路,会导致出现一个循环的缓冲区依赖。如下图所示,当4台交换机都达到XOFF水线,都同时向对端发送PAUSE帧,这个时候该拓扑中所有交换机都处于停流状态,由于PFC的反压效应,整个网络或部分网络的吞吐量将变为零。
(BGP(Border Gateway Protocol,边界网关协议)是用来连接Internet上的独立系统的路由选择协议。)

即使在无环网络中形成短暂环路时,也可能发生死锁。虽然经过修复短暂环路会很快消失,但它们造成的死锁不是暂时的,即便重启服务器中断流量,死锁也不能自动恢复。
为了解除死锁状态,一方面是要杜绝数据中心里的环路产生,另一方面则可以通过网络设备的死锁检测功能来实现。锐捷RG-S6510-48VS8CQ上的Deadlock检测功能,可以检测到出现Deadlock状态后的一段时间内,忽略收到的PFC帧,同时对buffer中的报文执行转发或丢弃的操作(默认是转发)。
例如,定时器的监控次数可配置设置检测10次,每次10ms内检测是否收到PFC Pause帧。若10次均收到则说明产生Deadlock,对buffer中的报文执行默认操作,之后将设置100ms作为Recover时间后恢复再检测。命令如下:
priority-flow-control deadlock cos-value 5 detect 10 recover 100 //10次检测,100ms recover。
RDMA无损网络中利用PFC流控机制,实现了交换机端口缓存溢出前暂停对端流量,阻止了丢包现象发生,但因为需要一级一级反压,效率较低,所以需要更高效的、端到端的流控能力。
- 拥塞传播
[RoCE]拥塞控制机制(ECN, DC-QCN) - https://www.cnblogs.com/burningTheStar/p/8566746.html
[RoCE]拥塞控制机制(ECN, DC-QCN)_https://blog.csdn.net/weixin_30295091/article/details/95688326
- PauseStorm
由于PFC pause是传递的,所以很容器引起pause frame storm。比如,NIC因为bug导致接收缓冲区填满,NIC会一直对外发送pause frame。需要在NIC端和交换机端使用watchdog机制来防止pause storm。

1,服务器0的NIC发生故障,不断向其ToR交换机发送暂停帧;
2. ToR交换机依次暂停所有其余端口,包括到Leaf交换机的所有上游端口。
3.叶子交换机暂停脊椎交换机;
4. Spine交换机暂停其余的Leaf交换机;
5.其余的叶子交换机暂停其ToR交换机;
6. ToR交换机会暂停连接到它们的服务器。
PFC风暴问题的根本原因是NIC的接收管道中存在错误。 该错误使NIC无法处理收到的数据包。 结果,NIC的接收缓冲区已满,并且NIC一直一直发出暂停帧。
翻译原文:https://blog.csdn.net/qq_21125183/article/details/104637777
英文原文:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/11/rdma_sigcomm2016.pdf
QoS in RoCE - https://www.cnblogs.com/zafu/p/10804005.html
- 队头阻塞(HOL Blocking/堵塞问题)
Head-of-Line 堵塞问题
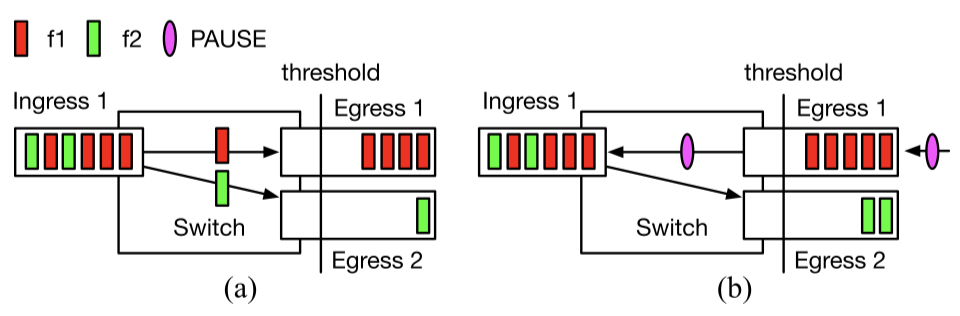
如上图 a),Flow 1 和 Flow 2 从同一个 Ingress 1 流向不同的 Egress 1 和 2。
图 b),Egress 1 触发了 PFC Pause,Ingress 1 暂停发送。Flow 2 并不需要经过 Egress 1,却受其影响也被暂停了。
RDMA 在数据中心的可靠传输 - https://zhuanlan.zhihu.com/p/257228128
- 不公平问题(PFCunfairness)

如上图 a),交换机上两个流入端口有数据流向同一个流出端口:Ingress 1 携带 Flow 1,Ingress 2 携带 Flow 2 和 3。
图 b) 触发了 PFC Pause,Ingress 1 和 2 同时暂停发送。
图 c) Egress 1 队列空闲,通知 Ingress 1 和 2 恢复发送。
图 d) 由于 Ingress 1 和 2 是同时暂停和恢复的,Flow 2 和 3 需要竞争 Ingress 2,导致 Flow 1 始终能够获得比 Flow 2 或 3 更高的带宽,出现了不同 Flow 带宽分配不公平。
RDMA 在数据中心的可靠传输 - https://zhuanlan.zhihu.com/p/257228128
四、利用ECN实现端到端的拥塞控制
当前的RoCE拥塞控制依赖ECN(Explicit Congestion Notification,显式拥塞通知)来运行。ECN最初在RFC 3168中定义,网络设备会在检测到拥塞时,通过在IP头部嵌入一个拥塞指示器和在TCP头部嵌入一个拥塞确认实现。
(RFC:Request For Comments,缩写为RFC,是由互联网工程任务组(IETF)发布的一系列备忘录。)
RoCEv2标准定义了RoCEv2拥塞管理(RCM)。启用了ECN之后,网络设备一旦检测到RoCEv2流量出现了拥塞,会在数据包的IP头部ECN域进行标记。

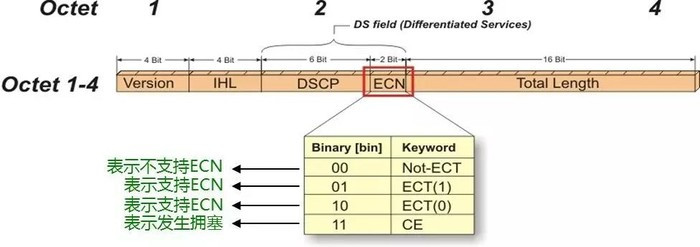
这个拥塞指示器被目的终端节点按照BTH(Base Transport Header,存在于IB数据段中)中的FECN拥塞指示标识来解释意义。换句话说,当被ECN标记过的数据包到达它们原本要到达的目的地时,拥塞通知就会被反馈给源节点,源节点再通过对有问题的Queue Pairs(QP)进行网络数据包的速率限制来回应拥塞通知。
五、ECN交互过程
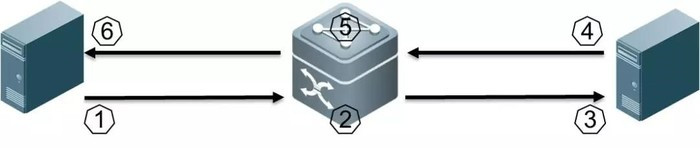
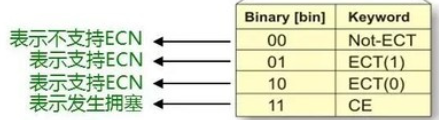
① 发送端发送的IP报文标记支持ECN(10); (ECT=10 or 01,发送端10,接收端01?)
② 交换机在队列拥塞情况下收到该报文,将ECN字段修改为11并发出,网络中其他交换机将透传;
③ 接收端收到ECN为11的报文发现拥塞,正常处理该报文;
④ 接收端产生拥塞通告,每ms级发送一个CNP(Congestion Notification Packets)报文,ECN字段为01,要求报文不能被网络丢弃。接收端对多个被ECN标记为同一个QP的数据包发送一个单个CNP即可(格式规定见下图);--(即对同一个QP的数据发送同一个CNP即可)
⑤ 交换机收到CNP报文后正常转发该报文;
⑥ 发送端收到ECN标记为01的CNP报文解析后对相应的流(对应启用ECN的QP)应用速率限制算法。
RoCEv2的CNP包格式如下:
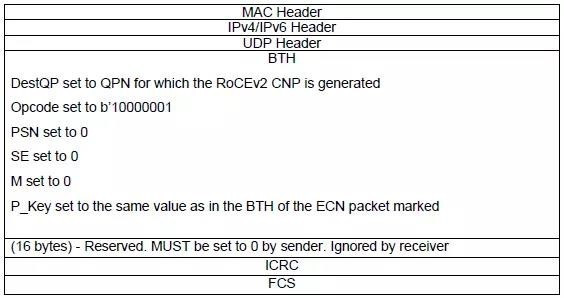
值得注意的是,CNP作为拥塞控制报文,也会存在延迟和丢包,从发送端到接收端经过的每一跳设备、每一条链路都会有一定的延迟,会最终加大发送端接收到CNP的时间,而与此同时交换机端口下的拥塞也会逐步增多,若发送端不能及时降速,仍然可能造成丢包。建议拥塞通告域的规模不要过大,从而避免因为ECN控制报文交互回路的跳数过多,而影响发送端无法及时降速,造成拥塞。
QC-QCN (网络工程师必会,ECN配置依据)
【网络】PFC背景和原理 、文档(DCB=PFC + ETS,DCBX=DCB扩展)_bandaoyu的博客-CSDN博客_dcb pfc背景在数据中心网络当中,典型的存在着以下两种流量:存储数据流:要求无丢包;普通数据流:允许一定的丢包和时延。很显然两种数据流对服务的要求是不同的,因而传统的数据中心也往往会部署两个网络来满足对数据中心的这些需求。这种网络在一定意义上来说是冗余的,会造成资源的浪费,当数据中心规模扩大时,这种方案就变的不可接受了。因此急需一种可以将两种网络统一起来的网络技术。当将这两个网络进行融合时,需要对两个网络进行考察:普通数据流:它没什么特殊要求存储数据流:存储网一般采用FC协议,存储也是传统数 https://blog.csdn.net/bandaoyu/article/details/117436019
https://blog.csdn.net/bandaoyu/article/details/117436019
PFC和ECN对比*
(详谈RDMA技术原理和三种实现方式-https://network.51cto.com/art/202103/648715.htm)
在 RoCE 网络中,需要构建无损以太网保证网络不丢包,构建无损以太网需支持以下关键特性:
- (必选)PFC(Priority-based Flow Control,基于优先级的流量控制):逐跳提供基于优先级的流量控制,能够实现在以太网链路上运行多种类型的流量而互不影响。
- (必选)ECN(Explicit Congestion Notification,显示拥塞通知):设备发生拥塞时,通过对报文 IP 头中 ECN 域的标识,由接收端向发送端发出降低发送速率的 CNP(Congestion Notification Packet,拥塞通知报文),实现端到端的拥塞管理,减缓拥塞扩散恶化。
- (建议)DCBX(Data Center Bridging Exchange Protocol,数据中心桥能力交换协议):使用 LLDP 自动协商 DCB 能力参数(包括 PFC 和 ETS 等)。一般用在接入交换机连接服务器的端口,与服务器网卡进行能力协商。
- (可选)ETS(Enhanced Transmission Selection,增强传输选择):将流量按服务类型分组,在提供不同流量的最小带宽保证的同时提高链路利用率,保证重要流量的带宽百分比。需要逐跳提供。
在 RoCE 环境中,PFC与ECN 需要同时使用,以在无丢包情况下带宽得到保证。二者的功能对比如下:
PFC 点到点逐跳反压,ECN端到端,向源头发送暂停通知。
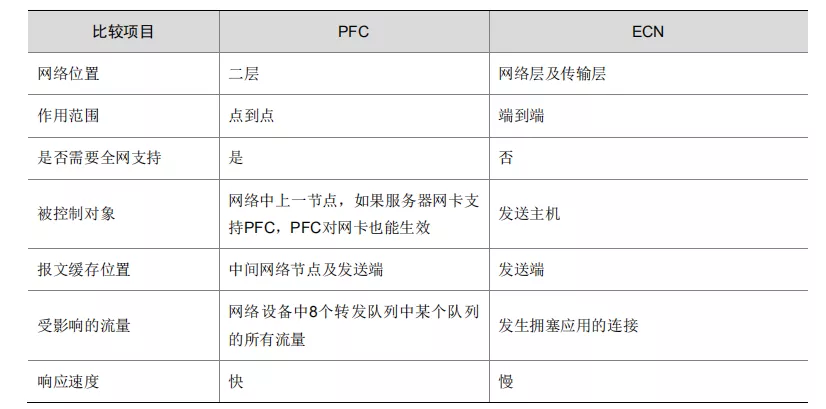
ECN优势:WRED 采用的丢弃报文的动作虽然缓解了拥塞对网络的影响,但将报文从发送端转发到被丢弃位置之间所消耗的网络资源已经被浪费了。因此,在拥塞发生时,如果能将网络的拥塞状况告知发送端,使其主动降低发送速率或减小报文窗口大小,便可以更高效的利用网络资源。
总结
RDMA网络正是通过在网络中部署PFC和ECN功能来实现无损保障。PFC技术让我们可以对链路上RDMA专属队列的流量进行控制,并在交换机入口(Ingress port)出现拥塞时对上游设备流量进行反压。利用ECN技术我们可以实现端到端的拥塞控制,在交换机出口(Egress port)拥塞时,对数据包做ECN标记,并让流量发送端降低发送速率。
从充分发挥网络高性能转发的角度,我们一般建议通过调整ECN和PFC的buffer水线,让ECN快于PFC触发,即网络还是持续全速进行数据转发,让服务器主动降低发包速率。如果还不能解决问题,再通过PFC让上游交换机暂停报文发送,虽然整网吞吐性能降低,但是不会产生丢包。
在数据中心网络中应用RDMA,不仅要解决转发面的无损网络需求,还要关注精细化运维,才能应对延迟和丢包敏感的网络环境
PFC的水线设置
RDMA流控|RDMA对于网络的诉求_https://blog.csdn.net/bandaoyu/article/details/115522737
无损网络测试规范
无损网络测试规范.pdf https://max.book118.com/html/2019/0927/5343023304002132.shtm
中国移动:《统一的以太网无损网络测试技术白皮书》统一的以太无损网络测试技术白皮书v2.0-http://www.doc88.com/p-25829298673562.html
开放数据中心委员会:《无损网络测试规范》:http://www.opendatacenter.cn/download/p-1169553273830920194.html
开放数据中心委员会(ODCC),其前身为天蝎联盟(2011成立),是由中国互联网企业和科研机构自主发起的标准推进组织。开放数据中心委员会(2014成立)的正式成员包括百度、阿里巴巴、腾讯、中国电信、中国移动、工信部电信研究院,英特尔担任技术顾问。委员会旨在通过制定统一的技术规范,推动我国数据中心向标准化、产业化发展。
开放数据中心成果发布页面:http://www.opendatacenter.cn/download/22
网络要求
&RoCE可以运行在无损网络环境和有损网络环境中,如果运行在有损网络环境中,称为弹性RoCE(Resilient RoCE);如果运行在无损网络环境中,称为无损RoCE(Lossless RoCE)。
-
弹性RoCE网络 - 可以发送RoCE流的有损网络环境,即无需开启PFC/ECN的网络环境
https://community.mellanox.com/s/article/introduction-to-resilient-roce---faq -
无损RoCE网络 - 网络中开启PFC流控功能,确保网络的无损特性
https://community.mellanox.com/s/article/roce-v2-considerations#jive_content_id_Resilient_RoCE
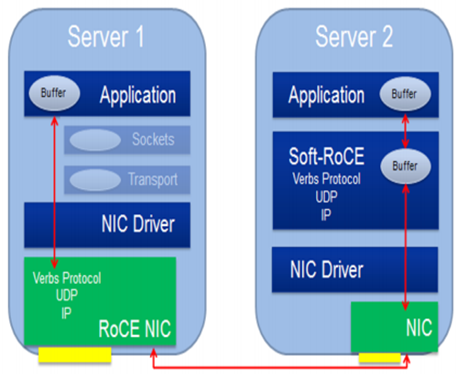
总结:尽管RoCE对链路层和物理层存在特殊依赖,但是在部署新型的数据中心时,对于较新型switch、NIC、SOC基本上都会集成网络融合DCB和RDMA支持。所以在新建Data Center、SAN时,性能最优的RoCE是最佳选择。而在旧DC、SAN扩容或者成本敏感型的优化时,仅需要RNIC的iWRAP或者完全不依赖任何硬件的softRoCE更加适合。
Ref
1 https://www.cnblogs.com/echo1937/p/7018266.html
2 http://hustcat.github.io/roce-protocol/
3 RoCE: An Ethernet-InfiniBand Love Story
4 InfiniBand™ Architecture Specification Release 1.2.1 Annex A16: RoCE
5 InfiniBand™ Architecture Specification Release 1.2.1 Annex A17: RoCEv2
6 RoCEv2 CNP Packet Format Example
链接:https://www.jianshu.com/p/85e7309c6187
文档
H3C 《无损网络数据中心应用概述》:http://www.cww.net.cn/article?id=461985
英文:RDMA Technology White Paper-6W100-- http://www.h3c.com/en/Support/Resource_Center/Technical_Documents/Home/Switches/00-Public/Trending/Technologies/RDMA_Technology_White_Paper-6W100/
百度低延迟网络的最佳实践《Baidu’sBest Practice with Low Latency Networks》:
@UESTC
RoCE帧结构

Soft-RoCE
指令记录
查看映射关系
mlnx_qos -i eth2 (mellonx)设置用L3做流控
mlnx_qos -i eth2 --trust=dscp (mellonx)修改dscp到priority 映射
dscp 30 映射到修改dscp到priority 6
# mlnx_qos -i eth2 --dscp2prio set,30,6 (mellonx)使能PFC
# mlnx_qos -i <interface> --pfc 0,0,0,1,0,0,0,0修改tc和prio的映射(默认除了tc0对应prio1,tc对应prio0,其他的都是对应的,如tc2-prio2,tc3-prio3,tc4-prio4……)
mlnx_qos -i ib3b-0 -p 0,1,2,3,4,5,6,7端口各优先级的收发计数
#测量该接口发送和接收的 Xon 和 Xoff(传输开启和关闭)帧的数量:
# watch -n 1 "ethtool -S eth1 | grep prio"
(intel
请注意,Rx 计数器全为 0。当适配器通过交换机连接时,rx_priority_* 计数器可能为 0,表明适配器尚未从交换机收到任何暂停帧。根据网络中的压力水平,如果交换机有足够的缓冲来跟上主机需求,这是可以接受的。但是,对于高压力流量(例如更大规模的 HPC 应用程序),交换机通常会向主机发送暂停帧。通常,预计会同时看到 tx 和 rx_priority 计数器。
请注意,某些 Tx 计数器具有相同的值。在 800 系列 QoS 实施中,如果为traffic class中的任何priority启用 PFC,则该traffic class中的所有priority都会获得暂停帧。这意味着同一 TC 中所有priority的计数器都会一致递增,而不管导致 PFC 触发的特定单个priority如何。如果所有priority都映射到同一个 TC,它们都会一致增加。)查看GID
show_gids (mellonx;intel自己也写同样的脚本,脚本内容见末尾)
show_gids mlx5_5 (mellonx)查看设备可用端口, gid_index, rmda版本查看端口丢弃
show_drop (mellonx;intel自己也写同样的脚本,脚本内容见末尾)
弃包统计
ethtool -S enp175s0f0 | grep dropwatch -n 1 “ethtool -S enp175s0f0 | grep drop” #1 s 刷新一次
各个优先级收发包统计
watch -n 1 "ethtool -S ib3b-0 | grep prio"
查看device
ibdev2netdev (mellonx;intel自己也写同样的脚本,脚本内容见末尾)ibdev2netdev –v (mellonx)
验证 InfiniBand 链接是否已启动hca_self_test.ofed (mellonx)
Mellanox OFED 安装的信息/etc/infiniband/info
看自动加载的模块列表
/etc/infiniband/openib.conf
检查Mellanox网卡是否安装和版本
[root@rdma61 ~]# lspci | grep Mellanox
查看系统里所有的网卡和工作状态:
[root@rdma63 tcpdump]# ip a[root@rdma63 tcpdump]# ibv_devices
device node GUID
------ ----------------
mlx5_1 98039b03009a4296
mlx5_0 98039b03009a2b3a[root@rdma63 tcpdump]# ibv_devinfo
或
[root@rdma63 tcpdump]# ibv_devinfo mlx5_0
重新启动RDMA驱动
/etc/init.d/openibd restart
如果驱动不正常,虽然service network restart 可以启动Ethernet端口,但实际rdma驱动并未成功加载。
执行/etc/init.d/openibd restart 可以看到很多的错误。(还有记得把ibacm启动, service ibacm start)The ibacm service is responsible for resolving names and addresses to InfiniBand path information and caching such data.
It should execute with administrative privileges.
The ibacm implements a client interface over TCP sockets, which is abstracted by the librdmacm library.
mellonx信息搜集/usr/sbin/sysinfo-snapshot.py
//****************************************************交换机****************************************
S6820《H3C S6820 系列以太网交换机 二层技术-以太网交换配置指导》P11:PFC 优先级高于FC,设置了PFC 则忽略FC
2.配置H3C交换机
a) 配置优先级信任模式为DSCP:
例如:
[H3C]sys
[H3C]interface HundredGigE1/0/6
[H3C-HundredGigE1/0/6] 6*配置信任模式为DSCP,交换机才会使用 报文自带的DSCP做映射。
设置信任模式为DSCP,则进入交换机的报文优先级映射会涉及到3个表:
进-->出 映射,
dscp-dot1p #入端口报文为dscp会被交换机映射到lp队列
dscp-dp #入端口报文为dscp会被交换机映射到dp队列
dscp-dscp #入端口报文的dscp会被交换机改为dscp转发
(优先级可分为两类:报文携带优先级和设备调度优先级。
设备调度优先级是指报文在设备内转发时所使用的优先级,只对当前设备自身有效。
设备调度优先 级包括以下几种:
• 本地优先级(LP):设备为报文分配的一种具有本地意义的优先级,每个本地优先级对应一 个队列,本地优先级值越大的报文,进入的队列优先级越高,从而能够获得优先的调度。
• 丢弃优先级(DP):在进行报文丢弃时参考的参数,丢弃优先级值越大的报文越被优先丢弃。)display qos map-table dscp-dot1p
b) 配置PFC功能的开启模式
例如:
[H3C]sys
[H3C]interface HundredGigE1/0/6
[H3C-HundredGigE1/0/6] priority-flow-control enable
6.显示接口的PFC信息
display priority-flow-control interface 显示全部
display priority-flow-control interface [ interface-type [ interface-number ] ] 显示某个关闭PFC:undo priority-flow-control
7,使能PFC后还需指定PFC作用的不弃包的等级priority-flow-control no-drop dot1p dot1p-list
如:
priority-flow-control no-drop dot1p 0
priority-flow-control no-drop dot1p 0,1,3(dot1p和dscp的映射见display qos map-table dscp-dot1p )
http://www.h3c.com/cn/d_201906/1206016_30005_0.htm显示端口是否开启FC:----不是PFC,设置了PFC就忽略FC
display interface [接口]
如: display interface HundredGigE1/0/2
缩写:dis int HundredGigE1/0/4(1、端口入方向报文计数错误字段解释
input errors:各种输入错误的总数。
runts:表示接收到的超小帧个数。超小帧即接收到的报文小于 64 字节,且包括有效的 CRC 字段,报文格式正确。
giants:是超过端口设置的 Maximum Frame Length 的报文个数。 CRC:表示接收到的 CRC 校验错误报文个数。
frame:端口接收时出错的报文。2、端口出方向报文计数错误字段解释
output errors:各种输出错误的总数。
aborts:表示发送失败的报文总数。
deferred:表示延迟报文的总数。报文延迟是指因延迟过长的周期而导致发送失败的报文,而这些报文由于发送媒质繁忙而等待了超过 2 倍的最大报文发送时间。
collisions:表示冲突帧总数,即在发送过程中发生冲突的报文。 l
ate collisions:表示延迟冲突帧,即发送过程中发生延迟冲突超过 512bit 时间的帧。
)
H3C 二层命令参考:http://www.h3c.com/cn/d_202104/1397802_30005_0.htm
****************************
显示和维护(H3C交换机)
****************************
1.显示指定优先级映射表配置情况
display qos map-table dot1p-dp | dot1p-exp | dot1p-lp | dscp-dot1p | dscp-dp | dscp-dscp | exp-dot1p | exp-dp ]
如:display qos map-table dscp-dscp2. 显示接口优先级信任模式信息(sys视图)
display qos trust interface [ interface-type interface-number ]
如:
display qos trust interface HundredGigE1/0/13. 显示端口简单信息
display interface brief
4. 显示端口在该间隔时间内统计的报文信息
display interface
5. 显示Qos trust设置
display qos trust int
6. 显示接口的PFC信息
display priority-flow-control interface 显示全部
display priority-flow-control interface [ interface-type [ interface-number ] ] 显示某个显示收发和暂停统计
-显示全部端口
-display interface
-显示某个端口
-display interface HundredGigE1/0/2查看拥塞drop包(弃包/丢包)
display packet-drop
display packet-drop interface HundredGigE1/0/4
《接口管理命令参考》http://www.h3c.com/cn/d_201906/1206016_30005_0.htm
//===============================================================================测试================================================================
Tos=============
--tos=<tos value> Set <tos_value> to RDMA-CM QPs. available only with -R flag. values 0-256 (default off)ibdump -d mlx5_0 -i 1 -w sniffer.acp #抓包
ib_send_bw -d mlx5_0 --rdma_cm #服务端
ib_send_bw 192.169.31.54 --rdma_cm --tos=12 –R #客户端1100
==========================
Intel show_gids
==========================
#!/bin/bash
function show_gid()
{
for device in ` ls /sys/class/infiniband/` #注意此处这是两个反引号,表示运行系统命令
{
echo "****************"
echo "Device:"${device}
for port in ` ls /sys/class/infiniband/${device}/ports/`
{
echo "IB port:"${port}
for gid in `ls /sys/class/infiniband/${device}/ports/${port}/gids`
{GID=`cat /sys/class/infiniband/${device}/ports/${port}/gids/${gid}` #在此处处理文件即可
if [[ $GID == *0000:0000:0000:0000:0000:0000:0000:0000* ]]
then
: #do nothing
#echo "包含"
else
#echo "不包含"
echo "GID"${gid}":"$GID
fi
}
}
}
}
show_gid
==========================
Intel show_drop
==========================
#!/bin/bash
function show_drop()
{
for device in `ls /sys/class/infiniband/`
{
echo ""
echo -e "\e[1;32m${device}\e[0m"
cd /sys/class/infiniband/${device}/hw_counters
for f in *Discards
{
echo -n "$f: "
cat "$f"
}
}
}
show_drop*intel官方提供的脚本:
# cd /sys/class/infiniband/irdma-enp175s0f0/hw_counters
# for f in *Discards; do echo -n "$f: "; cat "$f"; done
==========================
Inetl ibdev2netdev
==========================
#!/bin/bash
echo "--------------------------------------"
echo "script locate:/usr/bin/ibvdev2netdev"
echo "Author:liangchaoxi"
echo "***************************************"
ibv_devices|awk '{system("echo "$1"\"-->\"`ls /sys/class/infiniband/"$1"/device/net`")}' |& grep -Ev '/device/net|device|-------->'
echo "***************************************"
ip route
echo "--------------------------------------"Mellonx
显示GID
show_gids显示OFED显示
ofed_info显示网卡、驱动版本等信息
hca_self_test.ofed[root@rdma61 ~]# hca_self_test.ofed
---- Performing Adapter Device Self Test ----
Number of CAs Detected ................. 2
PCI Device Check ....................... PASS
Kernel Arch ............................ x86_64
Host Driver Version .................... OFED-internal-4.5-1.0.1: 4.14.0-49.12.x86_64
Host Driver RPM Check .................. PASS
Firmware on CA #0 NIC .................. v16.24.1000
Firmware on CA #1 NIC .................. v16.23.1020
Host Driver Initialization ............. PASS
Number of CA Ports Active .............. 2
Port State of Port #1 on CA #0 (NIC)..... UP 4X QDR (Ethernet)
Port State of Port #1 on CA #1 (NIC)..... UP 4X QDR (Ethernet)
Error Counter Check on CA #0 (NIC)...... PASS
Error Counter Check on CA #1 (NIC)...... PASS
Kernel Syslog Check .................... FAIL
REASON: Kernel syslog reported: Driver messages
[681196.776180] java invoked oom-killer: gfp_mask=0x14201ca(GFP_HIGHUSER_MOVABLE|__GFP_COLD), nodemask=(null), order=0, oom_score_adj=0
[681443.262537] devmgrdaemon invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=0
[684264.725346] objecter_timer invoked oom-killer: gfp_mask=0x14201ca(GFP_HIGHUSER_MOVABLE|__GFP_COLD), nodemask=(null), order=0, oom_score_adj=0
[782281.333718] themis invoked oom-killer: gfp_mask=0x14201ca(GFP_HIGHUSER_MOVABLE|__GFP_COLD), nodemask=(null), order=0, oom_score_adj=0
[782285.206503] devmgrdaemon invoked oom-killer: gfp_mask=0x14201ca(GFP_HIGHUSER_MOVABLE|__GFP_COLD), nodemask=(null), order=0, oom_score_adj=0
Node GUID on CA #0 (NIC) ............... 98:03:9b:03:00:9a:31:ba
Node GUID on CA #1 (NIC) ............... 98:03:9b:03:00:9a:4c:1a
------------------ DONE ---------------------
检查Mellanox网卡是否安装和版本
[root@rdma61 ~]# lspci | grep Mellanox
0000:18:00.0 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5]
0000:3b:00.0 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5]命令查看网口映射关系。
#ibdev2netdev
[root@rdma64 ibdump-master]# ibdev2netdev
mlx5_0 port 1 ==> eth18-0 (Up)
mlx5_1 port 1 ==> ib3b-0 (Up)ibv_devices 列出device
[root@rdma63 tcpdump]# ibv_devices
device node GUID
------ ----------------
mlx5_1 98039b03009a4296
mlx5_0 98039b03009a2b3a
打印出device信息
[root@rdma63 tcpdump]# ibv_devinfo或
[root@rdma63 tcpdump]# ibv_devinfo mlx5_0
hca_id: mlx5_0
transport: InfiniBand (0)
fw_ver: 16.29.1016
node_guid: 9803:9b03:009a:2b3a
sys_image_guid: 9803:9b03:009a:2b3a
vendor_id: 0x02c9
vendor_part_id: 4119
hw_ver: 0x0
board_id: MT_0000000010
phys_port_cnt: 1
Device ports:
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet
ibstatus更换网卡工作模式
有些网卡,当你安装好驱动后,通过 ibstatus 命令,会出现下面的情况:可以看到,该网卡现在处于 Ethernet 的工作模式,如果想要切换成infiniband模式,参考如下链接:
https://community.mellanox.com/s/article/howto-change-port-type-in-mellanox-connectx-3-adapter
查看当前工作模式:
sudo /sbin/connectx_port_config -s
输入以下命令切换工作模式:
sudo /sbin/connectx_port_config
如果提示如图,说明不支持infiniband模式,否则,就切换成功了,再次使用一下命令可以验证:
原文链接:https://blog.csdn.net/bandaoyu/article/details/115906185
1、常规 IB 监视命令ibv_asyncwatch 监视 InfiniBand 异步事件
ibv_devices or ibv_devinfo 列举 InfiniBand 设备或设备信息
ibv_rc_pingpong、ibv_srq_pingpong 或 ibv_ud_pingpong 使用 RC 连接、SRQ 或 UD 连接测试节点之间的连通性
mckey 测试 RDMA CM 多播设置和简单数据传输
rping 测试 RDMA CM 连接并尝试 RDMA ping
ucmatose 测试 RDMA CM 连接并尝试简单 ping
udaddy 测试 RDMA CM 数据报设置并尝试简单 ping
2、常规 IB 性能测试命令
rdma_client 或rdma_server 或rdma_xclient或 rdma_xserver 测试 RDMA 写处理确定流带宽或等待时间
ib_read_bw 或 ib_read_lat 测试 RDMA 读处理确定带宽或等待时间
ib_send_bw 或 ib_send_lat 测试 RDMA 发送处理确定带宽或等待时间
ib_write_bw 或 ib_write_bw_postlist 测试 RDMA 写处理,确定一次显示一个 I/O 请求的带宽或显示一系列 I/O 请求的发布列表带宽
ib_write_lat 测试 RDMA 写处理确定等待时间
ib_clock_test 测试系统时钟准确性
qperf 测量插槽与 RDMA 性能
RDS 监视与测试工具
rds-info 显示 RDS 内核模块信息
rds-ping 确定基于 RDS 的远程节点是否可访问
rds-stress 在基于 RDS 插槽的进程间发送消息
3、光纤网络诊断工具
iblinkinfo.pl 或 iblinkinfo 显示光纤网络中所有链路的链路信息
sminfo 查询 IB SMInfo 属性
ibstat 或 ibsysstat 查询 InfiniBand 设备状态或 IB 地址上的系统状态
perfquery or saquery 查询 IB 端口计数器或 sIB 子网管理属性
ibdiagnet 执行整个光纤网络诊断检查
ibcheckerrors 或 ibcheckerrs 验证 IB 端口(或节点)或 IB 子网并报告错误
ibaddr 查询 InfiniBand 的一个地址或多个地址
ibnetdiscover 搜索远程 InfiniBand 拓扑
ibping 验证 IB 节点之间的连通性
ibportstate 查询 IB 端口的物理端口状态和链接速度
ibroute 显示 InfiniBand 交换机转发表
ibtracert 跟踪 IB 路径
smpquery 或 smpdump 查询或转储 IB 子网管理属性
ibchecknet, ibchecknode, 或 ibcheckport 验证 IB 子网、节点或端口并报告错误
ibcheckportstate, ibcheckportwidth, ibcheckstate, or ibcheckwidth 验证已链接但不活动的 IB 端口、面向 1x (2.0 Gbps) 链路带宽的端口、IB 子网中已链接但不活动的端口或 IB 子网中的 lx 链路
ibclearcounters or ibclearerrors 对 IB 子网中的端口计数器或错误计数器进行清零
ibdatacounters or ibdatacounts 查询 IB 子网中的数据计数器或 IB 端口数据计数器
ibdiscover.pl 注释并比较 IB 拓扑
ibcheckerrors 或 ibcheckerrs 验证 IB 端口(或节点)或 IB 子网并报告错误
ibchecknet, ibchecknode, 或 ibcheckport 验证 IB 子网、节点或端口并报告错误
ibhosts 显示拓扑中的 IB 主机节点
ibnodes 显示拓扑中的 IB 节点
ibprintca.pl 显示来自 ibnetdiscover 输出的特定 CA 或 CA 列表
ibprintrt.pl 显示来自 ibnetdiscover 输出的特定路由器或路由器列表
ibprintswitch.pl 显示来自 ibnetdiscover 输出的特定交换机或交换机列表
ibrouters 显示拓扑中的 IB 路由器节点
ibstatus 查询 IB 设备的基本状态
ibswitches 显示拓扑中的 IB 交换机节点
ibswportwatch.pl
ibqueryerrors.pl 轮询特定交换机或端口上的计数器并报告更改信息速率
4、查询并报告非零 IB 端口计数器
ibprintswitch.pl 显示来自 ibnetdiscover 输出的特定交换机或交换机列表
set_nodedesc.sh 设置或显示针对 IB 主机控制器适配器 (HCA) 的节点描述字符串
dump2psl.pl 转储基于 opensm 输出文件的 PSL 文件,该输出文件用于信用循环检查
dump2slvl.pl 转储基于 opensm 输出文件的 SLVL 文件,该输出文件用于信用循环检查
ibis 针对 IB 管理带内服务的扩展 TCL shell
5、其常用指令
https://docs.oracle.com/cd/E19632-01/835-0783-03/bbggiggb.html#scrolltoc更多命令:
https://docs.oracle.com/cd/E56344_01/html/E54075/makehtml-id-7.html


