
【RDMA】InfiniBand如何工作和小消息通信性能优化方案
目录
前言
bandaoyu 本文随时更新,地址:https://blog.csdn.net/bandaoyu/article/details/119204643
其他翻译:InfiniBand如何工作? - https://zhuanlan.zhihu.com/p/336504815
摘要:这篇文章描述了在 InfiniBand 互连环境中 传输消息并发出‘’信号完成’,CPU 和 NIC 之间通过 PCI Express 结构在幕后发生的一系列协同事件。
通过InfiniBand发送消息的主要方法是通过Verbs API。libibverbs是这个API的标准实现,由linux RDMA社区维护。Verbs有两种功能:慢路径功能和快路径功能。慢路径功能(如ibv_open_device、ibv_alloc_pd等)是与资源(如上下文、保护域和内存区域)的创建和配置相关的功能。它们之所以被称为“慢”,是因为它们涉及内核,因此会产生上下文切换的昂贵开销。快速路径功能(如ibv_post_send、ibv_poll_cq等)处理操作的启动和完成。它们被称为“快”,因为它们绕过内核,因此比慢路径功能快得多。通信的关键路径主要由快速路径功能和偶尔的慢路径功能组成,如ibv_reg_mr,以动态注册内存区域(取决于通信中间件)。本文主要讨论程序员执行ibv_post_send后发生的机制。
快速PCIe背景
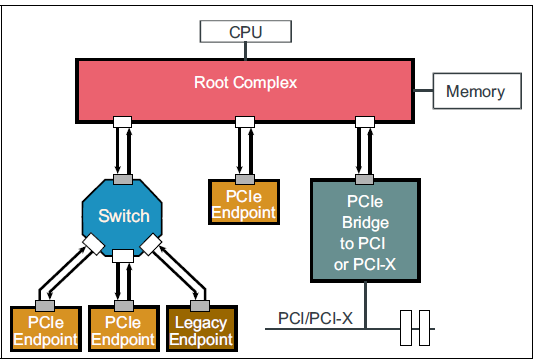
网络接口卡(NIC)通常通过PCI Express(PCIe)插槽连接到服务器。PCIe I/O子系统的主要导体(conductor )是根复合体(Roo Complex, RC)。RC将处理器和内存连接到PCIe结构。
CPU和Memory和PCIe结构通过RC(Roo Complex, RC)将连接在一起。
PCIe结构可以包括一个设备的层次结构。 连接到PCIe结构的外围设备称为PCIe端点(PCIe endpoints)。
PCIe总结--3层协议层补充_-https://blog.csdn.net/Fuji_Shikamaru/article/details/105329381
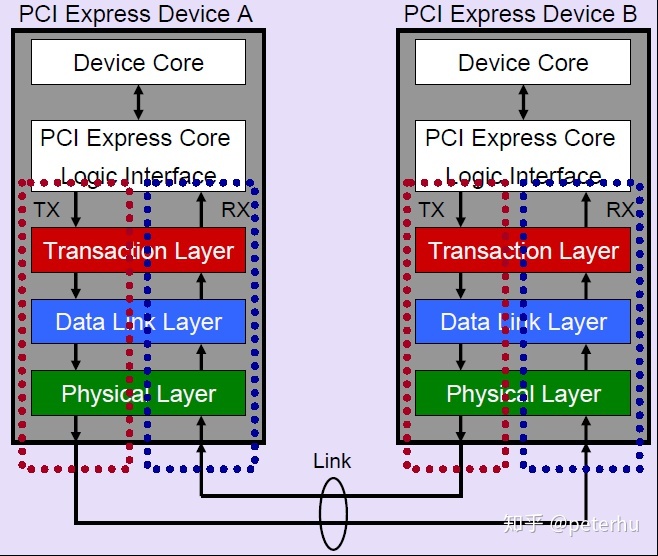
PCIe协议由三层组成:事务层、数据链路层和物理层。
第一层,最上层,描述发生的事务的类型。
对于本文,两种类型的传输层数据包(TLP)是相关的:Memory Write(MWr)和Memory Read(MRd)。与独立的MWr TLP不同,MRd TLP与来自目标PCIe端点的“带数据完成”( Completion with Data, CplD)事务耦合在一起,该事务包含启动器请求的数据。

数据链路层使用数据链路层分组(DLLP)确认(ACK/NACK)和基于Credits的流控制机制来确保所有事务的成功执行。发起方可以发出一个事务,只要它有足够的Credits额度。当它从它的邻居那里接收到更新流控制(UpdateFC)DLLPs时,它的Credits就会被补充。这种流控制机制允许PCIe协议具有多个未完成事务。
PCIe总结--3层协议层补充_https://blog.csdn.net/Fuji_Shikamaru/article/details/105329381
涉及的基本机制
首先,将描述如何使用完全卸载(即绕过内核)的方法发送消息,也就是说,CPU只通知网卡(NIC)有消息要传输;NIC将做剩下的所有其他事情来传输数据,如此一来,CPU就可以更多做其他事情。然而,这种方法可能不利于小消息的通信性能(这一点很快就会显现出来)。为了提高这种情况下的通信性能,InfiniBand提供了一些操作特性,将在下一节中介绍这些特性。
从CPU程序员的角度来看,存在一个传输队列(Verbs中是:队列对(Queue Pair,QP))和完成队列(Verbs中是:CQ)。用户将他们的消息描述符(MD;Work Queue Element/Entry(WQE;wookie)以Verbs形式post到传输队列,然后在CQ上轮询以确认所发布消息的完成。用户也可以要求得到有关完成情况的中断通知,但是,轮询方法是面向延迟的(更适合于要求低延迟的通信),因为关键路径中没有上下文切换到内核。消息在网络上的实际传输通过处理器芯片和网卡之间的协调来实现,使用内存映射I/O(MMIO)和直接内存访问(DMA)读写。下图中描述这些步骤。

(图中标明了步骤序号)
步骤0:用户首先将MD (wr ?)排队到TxQ (SQ ?)中。然后,CPU(网络驱动程序)准备特定于设备的 MD,其中包含 NIC 的标头和指向有效负载的指针。
步骤1:使用8字节的原子写入内存映射位置,CPU(网络驱动程序)按门铃(1)通知NIC消息已准备好要发送。RC使用MWr(MemoryWrite)PCIe事务 执行响门铃。
步骤2:门铃响后,网卡通过DMA读取MD。MRd PCIe事务执行DMA读取。
步骤3:(从MD知道待传输的数据在哪里)NIC将使用另一个DMA读取(另一个MRd TLP)从注册的内存区域获取有效负载。请注意,在NIC可以执行DMA读取之前,必须将虚拟地址转换为物理地址。
(2-3:先MRd PCIe dma读取MD获取负载信息,再MRd TLP dma读取有效负载)
步骤4:一旦网卡接收到有效载荷,它就会通过网络传输读取的数据。成功传输后,NIC从目标NIC接收确认(ACK)。
步骤5:接收到ACK后,NIC将通过DMA方式write(使用MWr TLP)一个完[成队列条目](CQE;vbers中称为cookie;Mellanox InfiniBand中为64字节)到与TxQ关联的CQ。然后CPU将轮询此CQE进行判断和后续。
总之,每个post的关键数据路径需要一次 MMIO 写入、两次 DMA 读取和一次 DMA 写入。DMA-reads转换为昂贵的往返 PCIe 延迟。例如,ThunderX2 机器的往返 PCIe 延迟约为 125 纳秒。
(一次 MMIO 写入:对映射内存的写入、两次 DMA 读取:第一次读取MD,第二次根据MD 读取负载和一次 DMA 写入:写入WC)
(ibv_post_send: 将wr 放到 SQ。驱动程序也将(处理过后)wr写入内存映射位置并通知网卡,网卡DMA读取wr,从wr里面得知待发送是数据在本地的地址和要发送到对端的地址。网卡根据本地地址从映射内存读取数据将其传输到对端地址)
操作特性
内联/inlining、Postlist、unsigned completion和Programmed I/O是IB的操作特性,有助于减少这种开销。考虑到QP的深度为n,将在下面描述它们。
- Postlist:IB允许应用程序通过一个调用ibv_post_send来发布WQE的链接列表,而不是每次只发布一个WQE。它可以将门铃响的次数从n减少到1。
- INLINE/内联:这里,CPU(网络驱动程序)将数据复制到WQE中 (WD ?)。因此,通过对WQE的第一次DMA读取,NIC也获得了有效载荷,从而消除了针对有效载荷的第二次DMA读取。
- unsigned Completions:IB默认是为每个WQE发送一个完成信号,但IB也允许应用程序关闭指定的WQE的完成(信号),但是注意每隔post n 个关闭信号的WQE,就要post一个开启完成信号的WQE 。(因为只有产生CQE,程序去读取了CQE之后才会清理发送队列SQ的SQE,如果一直没有CQE产生,则读取不断CQE也不就不会清理发送队列SQ,很快发送队列SQ就会撑满)
关闭Completion可以减少NIC对CQE的DMA writes。此外,应用程序轮询更少的CQE,从而减少了开销。
- BlueFlame:BlueFlame:BlueFlame 是 Mellanox 的编程 I/O 术语——它与 DoorBell 一起写入 WQE,切断 WQE 本身的 DMA 读取。请注意,BlueFlame 仅在没有 Postlist 的情况下使用。使用 Postlist,NIC 将 DMA 读取链表中的 WQE。
为了减少PCIe往返延迟的开销,开发人员通常将内联和BlueFlame一起用于小消息。它消除了两个PCIe往返延迟。虽然内联和BlueFlame的使用取决于消息大小,但是Postlist和unsigned completion的使用主要依赖于用户的设计选择和应用程序语义。
ibv_fork_init的调用也会对性能有影响
https://blog.csdn.net/bandaoyu/article/details/124327417?spm=1001.2014.3001.5501



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类