
【Shell】Sed 删除、替换、增加字符串
目录
作者:bandaoyu,本文持续更新。地址:https://blog.csdn.net/bandaoyu/article/details/120047612
Sed语法
语法格式
调用sed命令有两种形式: sed [options] "command" file(s) sed [options] -f scriptfile file(s)
$ sed -i.bak '10 s#netmask#aaaaaaaaaaaa#' file
-i.bak 表示直接对原文件进行编辑的同时做备份;
常用参数说明
option:
-n :只打印模式匹配的行
-e :直接在命令行模式上进行sed动作编辑,此为默认选项
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
-r :支持扩展表达式
-i :直接修改文件内容
命令command:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
a\ 在当前行下面插入文本;
i\ 在当前行上面插入文本;
c\ 把当前行改为新的文本;
d 删除,将选择的内容删除
D 删除模板第一行
s 替换指定字符 (最常用)
p 打印模板块的行。(常常和 -n配合使用)
P 打印模板块的第一行;
标记:
g 表示行内全部替换,ng表示第n个匹配的开始进行替换
w 表示把行写入一个文件
\1 字串匹配标记(划重点)
& 已匹配字符串标记
原文链接:https://blog.csdn.net/y1412813204/article/details/83578281
全部参数说明
在本文末尾附录1 或sed 语法_xuqq999_51CTO博客
命令解释
/某字符串/ 匹配//中间放的字符串的行,加^表示匹配行首,如:
1、/^+/ 匹配行首字符串为“+”的行
s表示替换,s/字符串1/字符串2/ 表示用字符串2替换字符串1,.* 表示当前行,如:
s/.*/+x/ 替换当前行为+x
n;n; 读入下一行;再读入下一行
n; 读入下一行
2、'/ClientAliveCountMax/ s/^#//' 匹配含ClientAliveCountMax的行,s表示替换,^表示行首,既替换匹配含ClientAliveCountMax的行,将行首的#,替换为“”,即去掉#。
删除、替换、增加字符串
sed中的分割符不一定是"/"可以是任意的符号,如@
删除
删除匹配的行
sed -i "/Manager/d" employee.txt #删除含Manager的行
删除匹配字符之间的内容
# Delete text between patterns, excluding the lines containing these patterns(不删除所在行):
sed -i "/PATTERN-1/,/PATTERN-2/{//!d} "input.txt
# Delete text between patterns, including the lines containing these patterns(所在行也删除):
sed -i "/PATTERN-1/,/PATTERN-2/d " input.txt
# To delete all the lines after PATTERN, use this
sed -i "/PATTERN/,$d " input.txt
[sed] Delete the lines lying in between two patterns | *NIX Tricks
sed -i "/#hwBegin/,/#hwEnd/d " /etc/my.cnf #就是将#hwBegin行到#hwEnd行之间内容,包括
#hwBegin行和#hwEnd行都删除,-i表示编辑的是文件
#add '-----here is the content---' to CONF_DIR behind the "[mysql]"
#use command 'sed' to add A behind "pattern" :sed 's/pattern/&A/' filename
用命令'sed'在filename文件内匹配的字符"pattern"后面添加内容A
#!/bin/ash
CONF_DIR="/etc/my.cnf"
sed -i "s/\[mysqld\]/&\n \
wait_timeout=2073600\n \
interactive_timeout=2073600\n \
bulk_insert_buffer_size=16M\n \
max_allowed_packet=16M\n/" /etc/my.cnf添加
#匹配行前加
sed -i "/allow 361way.com/iallow www.361way.com " the.conf.file
#匹配行前后
sed -i "/allow 361way.com/aallow www.361way.com " the.conf.file
而在书写的时候为便与区分,往往会在i和a前面加一个反加一个反斜扛 。代码就变成了:
sed -i "/2222222222/a\3333333333 " test.txt
sed -i "/2222222222/i\3333333333 " test.txt
这就就可以很方便的看出要在某一行前或某一行后加入什么内容 。不过经常我记不住a 、i 那个是前那个是后。我的记法是a = after ,i = in front 。
替换
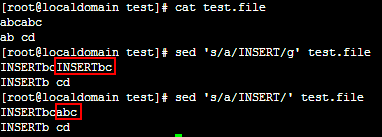
sed “s/要被替换的字符串/新的字符串/g”
替换文件内的内容:
sed -i “s/要被替换的字符串/新的字符串/g” test.txt
s表示替换,三根斜线中间是替换的样式,特殊字符需要使用反斜线”\”进行转义.
详见:http://www.jb51.net/LINUXjishu/155122.html
g代表每行出现的字符全部替换,如果没有g则只会替换每行第一个,而不继续往后找了
linux shell 用sed命令在文本的行尾或行首添加字符 - aaronwxb - 博客园
分割符不一定是"/"可以是任意的符号,如@
比如想把1.txt中
wav/dev/third_party/B00000/DEV_T0000000000/S00000.wav
wav/dev/third_party/B00000/DEV_T0000000001/S00000.wav
wav/dev/third_party/B00000/DEV_T0000000000/S00000.wav中的wav/dev/third_party/B00000 替换为wav:
$ sed -i "s@wav/dev/third_party/B00000@wav@ " 1.txt
替换/删除匹配的字符之间的内容
| 1 | #删除<\/schema>和<heartbeat>字符串之间的内容 #sed用单引号,所以里面的双引号不用转移符号 |
在每一行的行首/尾添加字符串
在每行的头添加字符,比如"HEAD",命令如下:
sed "s/^/HEAD&/g " test.file
在每行的行尾添加字符,比如“TAIL”,命令如下:
sed "s/$/&TAIL/g " test.file

几点说明:
1."^"代表行首,"$"代表行尾
linux shell 用sed命令在文本的行尾或行首添加字符 - aaronwxb - 博客园
在匹配行的行首/尾添加字符串
匹配含dddd的行,在行首添加666
sed -i "s/^.*dddd/666&/g" sed.txt
匹配含dddd的行,在行尾添加666
666& 表示添加到行首,&666 表示添加到行尾。
在第100行首/尾添加字符串
sed "100 s/^/HEAD&/g " test.file
sed "100 s/$/&TAIL/g " test.file
匹配字符串前添加
匹配含dddd的行,匹配字符串前添加
sed -i "s/^dddd/666&/g" sed.txt
https://www.jianshu.com/p/4de5d9901865
匹配行首,行尾后替换或添加字符
sed匹配某一行开头,替换整行内容
sed -i "/^cloud_server/ccloud_server_ip = update" name.txt
sed 匹配行中部分内容,替换整行
[root@centos8-38 opt]# sed '/.*dddd.*/c'$coud'' sed.txt
sed 也可以匹配行首或是行尾,中间部分内容后,
再行首或是行尾添加内容。
如下面:
666& 表示添加到行首,&666 表示添加到行尾。
[root@centos8-38 opt]# sed "s/^ccc/666&/g" sed.txt
作者:搬石头
链接:https://www.jianshu.com/p/4de5d9901865
提取字符串
现在有如下一串字符串:
"asdfkjasldjkf"shiner"df
需求:
需要提取出shiner子字符串。
命令如下:
[root@localhost /]$ echo "asdfkjasldjkf\"shiner\"df" | sed 's/\(.*\)"\(.*\)"\(.*\)/\2/g' #搜索shiner
命令解释
s: 表示替换命令
\(.*\)" : 表示第一个引号前的内容
"\(.*\)":表示两引号之间的内容
)"\(.*\):表示引号后的内容
\2: 表示第二对括号里面的内容
括号里的表达式匹配的内容,可以用\1,\2等进行引用,第n个括号对内的内容,就用\n引用。
这个命令的意思是:
用\2代表的第二个括号的内容(shiner)去替换整个字符串,这样就得到了我们所需要的子字符串了。
例子
其中的${1}是执行脚本是给的参数,例如 [root@hopewind]# setschema.sh 50
| 1 | #!/bin/sh |
匹配任意个空格
场景:
* soft nofile 630000
* hard nofile 654300
grep 匹配如上文本,由于最后一列数字是可变的,并且每列之间可能存在任意个空格或制表符
grep -E '^\*[[:space:]]+soft[[:space:]]+nofile|^\*[[:space:]]+hard[[:space:]]+nofile' /etc/security/limits.conf
将匹配的结果sed 替换最后一列数字
sed -n "s/\*[[:space:]]\+soft[[:space:]]\+nofile.*/\* soft nofile 654350/p;s/\*[[:space:]]\+hard[[:space:]]\+nofile.*/\* hard nofile 654350/p" /etc/security/limits.conf
区别,在匹配任意个数空格或制表符时,grep 的’+’ 不需要转义,sed 需要转义
补充:sed -r 可以实现正则表达式匹配
原文链接:https://blog.csdn.net/rockstics/article/details/111563857
例子:
要将vim /etc/onestor/onestor.conf中的
multi_cluster_set_ha = yes
handy_ha_needed = yes
改为:
multi_cluster_set_ha = no
handy_ha_needed = no
脚本:
sed -i "s/^multi_cluster_set_ha[[:space:]]\+=.*/multi_cluster_set_ha = no/" /etc/onestor/onestor.conf
sed -i "s/^handy_ha_needed[[:space:]]\+=.*/handy_ha_needed = no/"/etc/onestor/onestor.conf附录1:全部参数说明
3. Sed命令
调用sed命令有两种形式:
sed [options] 'command' file(s)
sed [options] -f scriptfile file(s)
a\ :在当前行后面加入一行文本。
b lable :分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。(转至命令:标记)
c\ :用新的文本改变本行的文本。
d :从模板块(Pattern space)位置删除行。
D:删除模板块的第一行。
i\ :在当前行上面插入文本。
h :拷贝模板块的内容到内存中的缓冲区。
H :追加模板块的内容到内存中的缓冲区
g :获得内存缓冲区的内容,并替代当前模板块中的文本。
G :获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l :列表不能打印字符的清单。
n :读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N :追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p :打印模板块的行。
P :打印模板块的第一行。
q :退出Sed。
r file :从file中读行。
t label :if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。(测试:若对当前行做了替换,转至标记)
T label :错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file :写并追加模板块到file末尾。
W file :写并追加模板块的第一行到file末尾。
! :表示后面的命令对所有没有被选定的行发生作用。
s/re/string :用string替换正则表达式re。
= :打印当前行号码。
# :把注释扩展到下一个换行符以前。
以下的是替换标记
g:表示行内全面替换。
p:表示打印行。
w:表示把行写入一个文件。
x:表示互换模板块中的文本和缓冲区中的文本。
y:表示把一个字符翻译为另外的字符(但是不用于正则表达式)
4. 选项
-e command, --expression=command
允许多台编辑。
-h, –help
打印帮助,并显示bug列表的地址。
-n, --quiet, –silent
取消默认输出。
-f, --filer=script-file
引导sed脚本文件名。
-V, –version
打印版本和版权信息。
5. 元字符集
^
锚定行的开始 如:/^sed/匹配所有以sed开头的行。
$
锚定行的结束 如:/sed$/匹配所有以sed结尾的行。
.
匹配一个非换行符的字符 如:/s.d/匹配s后接一个任意字符,然后是d。
*
匹配零或多个字符 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[]
匹配一个指定范围内的字符,如/[Ss]ed/匹配sed和Sed。
[^]
匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\)
保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
&
保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\<
锚定单词的开始,如:/\
\>
锚定单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\}
重复字符x,m次,如:/0\{5\}/匹配包含5个o的行。
x\{m,\}
重复字符x,至少m次,如:/o\{5,\}/匹配至少有5个o的行。
x\{m,n\}
重复字符x,至少m次,不多于n次,如:/o\{5,10\}/匹配5--10个o的行
注意事项和报错
sed里面需要用变量,要用双引号。
sed命令使用双引号的情况下,可以使用$var(变量)直接引用:
echo | sed "s/^/$RANDOM.rmvb_/g"
13562.rmvb_
sed命令使用单引号的情况下,可以使用'"$var"'引用(单引号,然后双引号,变量):
echo | sed "s/^/'"$RANDOM"'.rmvb_/g "
2442.rmvb_

扩展资料:
注意事项
在sed语句里面,变量替换或者执行shell命令,双引号比单引号少绕一些弯子;所以,sed和变量的关键词搜索的结果,众多都写上替换单引号为双引号。
sed命令中使用双引号的情况下,直接`shell command`或者$(shell command)引用命令执行。
echo | sed "s/^/$(date +"%Y%m%d").rmvb_/g"
20130401.rmvb_# 结果
# 使用环境变量$RANDOM以及旧式命令替换的例子:
echo | sed "s/^/`echo $RANDOM`.rmvb_/g"
29484.rmvb_# 结果



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?