

【分布式】分布式之Quorum机制(法定人数机制)|WARO|强一致性、弱一致性、最终一致性、读写一致性、单调读、因果一致性
在了解Quorum机制(法定人数机制)之前,先回顾一下数据一致性
强一致性vs弱一致性
- 强一致性:在任意时刻,从任意不同副本取出的值都是一样的。
- 弱一致性:有时泛指最终一致性,是指在任意时刻,可能由于网络延迟或者设备异常等原因,不同副本中的值可能会不一样,但经过一段时间后,最终会变成一样。
显然,我们更想要做到强一致性的这种效果,那么有哪些方式可以实现呢,其中最为简单直接的就是WARO,也就是Write All Read one。
WARO协议
是一种简单的副本控制协议,当 Client 请求向某副本写数据时(更新数据),只有当所有的副本都更新成功之后,这次写操作才算成功,否则视为失败。这样的话,只需要读任何一个副本上的数据即可。但是WARO带来的影响是写服务的可用性较低,因为只要有一个副本更新失败,此次写操作就视为失败了。
到这里,再来看Quorum机制到底是个什么鬼?他比WARO又好在什么地方
Quorum机制(法定人数机制)
Quorum 的定义如下:假设有 N 个副本,更新操作 wi 在 W 个副本中更新成功之后,则认为此次更新操作 wi 成功,把这次成功提交的更新操作对应的数据叫做:“成功提交的数据”。对于读操作而言,至少需要读 R 个副本,其中,W+R>N ,即 W 和 R 有重叠,一般,W+R=N+1。

-
N = 存储数据副本的数量
-
W = 更新成功所需的副本
-
R = 一次数据对象读取要访问的副本的数量
听起来有些抽象,举个例子:
假设我有5个副本,更新操作成功写入了3个,另外2个副本仍是旧数据,此时在读取的时候,只要确保读取副本的数量大于2,那么肯定就会读到最新的数据。至于如何确定哪份数据是最新的,我们可以通过引入数据版本号的方式判断(Quorum 机制的使用需要配合一个获取最新成功提交的版本号的 metadata 服务,这样可以确定最新已经成功提交的版本号,然后从已经读到的数据中就可以确认最新写入的数据。)
Quorum的应用
Quorum在分布式系统中的应用很多,下面举几个比较典型的例子:
1、HDFS HA
为解决NameNode的单点问题,在Hadoop 2.0对HDFS的高可用进行了改进,使得系统中可以同时启动多个NameNode,一个Active,一个Standby,并使用ZKFC(ZKFailoverController)对两者进行监控,当发现Active的NameNode服务中断,Standby的NameNode的状态会自动变为Active,接替原ActiveNameNode对外提供服务。
要想实现上面的功能,那就必然需要一个机制来确保Active和Standby这两个NameNode中的数据一致,所以在该系统中还引入了一个QJM模块,全称为Quorum Journal Manager。该模块一般由奇数个结点构成,每个QJM结点对外有一个RPC接口,以供Active NameNode向QJM写入EditLog(操作日志),此时会要求半数以上的QJM都写入成功,才算此次操作成功。Standby的NameNode也会定期从QJM上获取最新的EditLog来更新自身的数据。
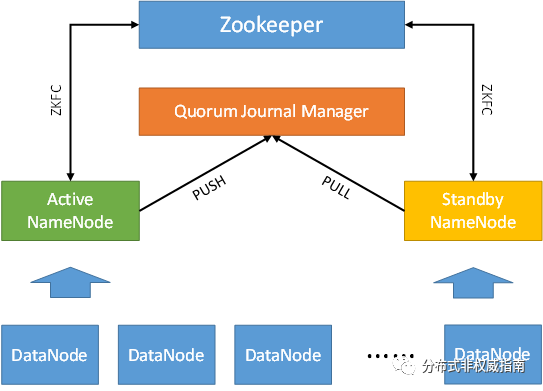
2、Zookeeper
Zookeeper的选举机制是遵循了Quorum的,这也是为什么我们部署Zookeeper必须要求有奇数个Cluster可用的原因。这样一是能保证Leader选举时不会出现平票的情况,避免出现脑裂。二是Leader在向Follower同步数据的时候,必须要超过半数的Follower同步成功,才会认为数据写入成功。
其实除了Zookeeper以外,很多支持分布式部署的模块,也都遵循和使用了这个设计,比如Redis的哨兵(sentinel)机制。
原文:分布式系统之Quorum机制 -https://www.cnblogs.com/zz-ksw/p/12772605.html
分布式系统理论之Quorum机制 - https://www.cnblogs.com/hapjin/p/5626889.html
强一致性、弱一致性、最终一致性、读写一致性、单调读、因果一致性区别与联系
强一致性 与 弱一致性
其实只有两类数据一致性,强一致性与弱一致性。
强一致性也叫做线性一致性,除此以外,所有其他的一致性都是弱一致性的特殊情况。所谓强一致性,即复制是同步的,弱一致性,即复制是异步的。
强一致性两个要求
任何一次读都能读到某个数据的最近一次写的数据。
系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。
简言之,在任意时刻,所有节点中的数据是一样的。
弱一致性
数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
最终一致性就属于弱一致性。
顺序一致性
两个要求:
任何一次读都能读到某个数据的最近一次写的数据。
系统的所有进程的顺序一致,而且是合理的。即不需要和全局时钟下的顺序一致,错的话一起错,对的话一起对。(强一致性的要求比顺序一致性更严格)
顺序一致性参考
最终一致性
不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。
最终两个字用得很微妙,因为从写入主库到反映至从库之间的延迟,可能仅仅是几分之一秒,也可能是几个小时
简单说,就是在一段时间后,节点间的数据会最终达到一致状态。
最终一致性的种类
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
因果一致性(Casual Consistency)。如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。与进程A无因果关系的进程C的访问,遵守一般的最终一致性规则。
“读己之所写(read-your-writes)”一致性。当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
会话(Session)一致性。这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话。
单调(Monotonic)读一致性。如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
单调写一致性。系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。
原文链接:https://blog.csdn.net/a3125504x/article/details/109407748
读写一致性
手机刷虎扑的时候经常遇到,回复某人的帖子然后想马上查看,但我刚提交的回复可能尚未到达从库,看起来好像是刚提交的数据丢失了,很不爽。
在这种情况下,我们需要读写一致性,也称为读己之写一致性。它可以保证,如果用户刷新页面,他们总会看到自己刚提交的任何更新。它不会对其他用户的写入做出承诺,其他用户的更新可能稍等才会看到,但它保证用户自己提交的数据能马上被自己看到。
如何实现读写一致性?
最简单的方案,对于某些特定的内容,都从主库读。举个例子,知乎个人主页信息只能由用户本人编辑,而不能由其他人编辑。因此,永远从主库读取用户自己的个人主页,从从库读取其他用户的个人主页。
如果应用中的大部分内容都可能被用户编辑,那这种方法就没用了。在这种情况下可以使用其他标准来决定是否从主库读取,例如可以记录每个用户最后一次写入主库的时间,一分钟内都从主库读,同时监控从库的最后同步时间,任何超过一分钟没有更新的从库不响应查询。
还有一种更好的方法是,客户端可以在本地记住最近一次写入的时间戳,发起请求时带着此时间戳。从库提供任何查询服务前,需确保该时间戳前的变更都已经同步到了本从库中。如果当前从库不够新,则可以从另一个从库读,或者等待从库追赶上来。
单调读
用户从某从库查询到了一条记录,再次刷新后发现此记录不见了,就像遇到时光倒流。如果用户从不同从库进行多次读取,就可能发生这种情况。
单调读可以保证这种异常不会发生。单调读意味着如果一个用户进行多次读取时,绝对不会遇到时光倒流,即如果先前读取到较新的数据,后续读取不会得到更旧的数据。单调读比强一致性更弱,比最终一致性更强。
实现单调读取的一种方式是确保每个用户总是从同一个节点进行读取(不同的用户可以从不同的节点读取),比如可以基于用户ID的哈希值来选择节点,而不是随机选择节点。
*因果一致性
在本文中阐述因果一致性可能并不是一个很好的时机,因为它往往发生在分区(也称为分片)的分布式数据库中。
分区后,每个节点并不包含全部数据。不同的节点独立运行,因此不存在全局写入顺序。如果用户A提交一个问题,用户B提交了回答。问题写入了节点A,回答写入了节点B。因为同步延迟,发起查询的用户可能会先看到回答,再看到问题。
为了防止这种异常,需要另一种类型的保证:因果一致性。 即如果一系列写入按某个逻辑顺序发生,那么任何人读取这些写入时,会看见它们以正确的逻辑顺序出现。
这是一个听起来简单,实际却很难解决的问题。一种方案是应用保证将问题和对应的回答写入相同的分区。但并不是所有的数据都能如此轻易地判断因果依赖关系。如果有兴趣可以搜索向量时钟深入此问题。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!