

【ceph】AsyncMessenger模块源码分析02 会话建立过程
目录
asyncMessenger 链接建立过程
被动接受连接
//第一阶段:建立tcp连接,交换RDMA GID等信息
ceph_osd.cc
Messenger::bind
AsyncMessenger::bind
|–p->bind(bind_addr, avoid_ports, &bound_addr);//Processor::bind
|–|–worker->listen(listen_addr, opts, &listen_socket);//RDMAWorker::listen <–从这里开始RDMA相关
|–|–|–p->listen(sa, opt);//RDMAServerSocketImpl::listen(entity_addr_t &sa, &……)
//TCP socket,RoCE创建RDMA通道之前需要借助TCP连接交互信息(QP的 id等)
|–|–|–|–rc = ::bind(server_setup_socket, sa.get_sockaddr(), sa.get_sockaddr_len());<—-TCP socket,
err = osd->init();
//messenger 放入消息分拣(处理)器,即messenger建立起来了,等下要接收和其他messenger交互消息了,收到的消息应该交给消息分拣(处理)器 去处理,见附录3:
|–|client_messenger->add_dispatcher_head(this);
|–|–|AsyncMessenger::ready()
|–|–|–|processors::start()
//create_file_event(listen_socket.fd(), EVENT_READABLE, listen_handler); }//创建event,是listen_handler[见附录1]
|–|–|–|–|worker->center.create_file_event(listen_socket.fd(), EVENT_READABLE, listen_handler);
——->
listen_handler=new C_processor_accept(this)–>pro->accept();–>processors::accept();
//进入TCP监听,accept():while(true)<—这条TCP连接会一直保持,用于节点之间交互RDMA 信息创建RDMA通道
|–|–|–|–|processors::accept();
|–|–|–|–|–|r = listen_socket.accept(&cli_socket, opts, &addr, w);//ServerSocket::accept
|–|–|–|–|–|–|return _ssi->accept(sock, opt, out, w);//virtual ServerSocketImpl::accept–>RDMAServerSocketImpl::accept
|–|–|–|–|–|–|–|sd = accept_cloexec(server_setup_socket, (sockaddr*)&ss, &slen);
|–|–|–|–|–|–|–|–|return fd = accept(sockfd, addr, addrlen);//tcp 的accpet <——-阻塞,等待tcp的connect到来(sd = fd )
|–|–|–|–|–|–|–|server->set_accept_fd(sd);//RDMAConnectedSocketImpl::set_accept_fd(sd);//sd = fd tcp连接的scoket fd
//tcp连接的scoket fd上添加了监听event,回调是con_handler=new C_handle_connection(this)),见附录2
|–|–|–|–|–|–|–|–|worker->center.submit_to(worker->center.get_id(), this {
worker->center.create_file_event(tcp_fd, EVENT_READABLE, con_handler);
}, true);
|–|–|–|–|–|–|–|–|–| c->dispatch_event_external(event);//放进event,马上执行worker->center.create_file_event(
|–|–|–|–|–|–|–|–|–|–| worker->center.create_file_event(sd, EVENT_READABLE, con_handler);//tcp连接的scoket fd上添加了监听event,等待client端发tcp消息触发【S1】
client try_connect infiniband->send_msg(cct, tcp_fd, my_msg); 发来信息后,触发回调con_handler=C_handle_connection
,server 把自己的my_msg(GID)发给client.进入建立RDMA 通道的握手流程
csi->handle_connection();//RDMAConnectedSocketImpl::handle_connection
|–|int r = infiniband->recv_msg(cct, tcp_fd, peer_msg);
|–|if (!is_server) {}else{} r = infiniband->send_msg(cct, tcp_fd, my_msg);//收到client的my_msg,也把自己的my_msg发过去
//第二阶段:根据交互的信息得知对方QP的 ID,激活RDMA 通道
r = activate();
state STATE_CONNECTING 切换到STATE_CONNECTING_RE
case STATE_CONNECTING_RE
//activate 成功后,async的链接建立成功
r = cs.is_connected() > 0,
//第三阶段:asyncMessenger 两端协商握手,直至连接的状态为 state STATE_OPEN
状态切换见图:
最后然后就可以messenger->send 发送数据
附录1
void Processor::start()
{
ldout(msgr->cct, 1) << __func__ << dendl;
// start thread
if (listen_socket) {
worker->center.submit_to(worker->center.get_id(), [this]() {
worker->center.create_file_event(listen_socket.fd(), EVENT_READABLE, listen_handler); }, false);
}
}
class Processor::C_processor_accept : public EventCallback {
Processor *pro;
public:
explicit C_processor_accept(Processor *p): pro(p) {}
void do_request(int id) override {
pro->accept();
}
};
Processor::Processor(AsyncMessenger *r, Worker *w, CephContext *c)
: msgr(r), net(c), worker(w),
listen_handler(new C_processor_accept(this)) {}
附录2
class C_handle_connection : public EventCallback {
RDMAConnectedSocketImpl *csi;
bool active;
public:
C_handle_connection(RDMAConnectedSocketImpl *w): csi(w), active(true) {}
void do_request(int fd) {
if (active)
csi->handle_connection();//RDMAConnectedSocketImpl::handle_connection
}
void close() {
active = false;
}
};
};
void RDMAConnectedSocketImpl::handle_connection() {
ldout(cct, 20) << __func__ << " QP: " << my_msg.qpn << " tcp_fd: " << tcp_fd << " notify_fd: " << notify_fd << dendl;
int r = infiniband->recv_msg(cct, tcp_fd, peer_msg);
int try_cnt = 0;
if (r < 0) {
if (r != -EAGAIN) {
dispatcher->perf_logger->inc(l_msgr_rdma_handshake_errors);
ldout(cct, 1) << __func__ << " recv handshake msg failed." << dendl;
fault();
}
return;
}
if (!is_server) {// syn + ack from server
my_msg.peer_qpn = peer_msg.qpn;
ldout(cct, 20) << __func__ << " peer msg : < " << peer_msg.qpn << ", " << peer_msg.psn
<< ", " << peer_msg.lid << ", " << peer_msg.peer_qpn << "> " << dendl;
if (!connected) {
for(try_cnt = 0;try_cnt < 3;try_cnt++) { //hanle "QAT: Device not yet ready."
r = activate();
if(0 == r) {
break;
}
}
assert(!r);
}
notify();
r = infiniband->send_msg(cct, tcp_fd, my_msg);
if (r < 0) {
ldout(cct, 1) << __func__ << " send client ack failed." << dendl;
dispatcher->perf_logger->inc(l_msgr_rdma_handshake_errors);
fault();
}
} else {
if (peer_msg.peer_qpn == 0) {// syn from client
if (active) {
ldout(cct, 10) << __func__ << " server is already active." << dendl;
return ;
}
r = infiniband->send_msg(cct, tcp_fd, my_msg);
if (r < 0) {
ldout(cct, 1) << __func__ << " server ack failed." << dendl;
dispatcher->perf_logger->inc(l_msgr_rdma_handshake_errors);
fault();
return ;
}
r = activate();
assert(!r);
} else { // ack from client
connected = 1;
cleanup();
submit(false);
notify();
}
}
}
附录3:
class OSD : public Dispatcher,
void OSD::_dispatch(Message *m)
{
switch (m->get_type()) {
......
case CEPH_MSG_OSD_MAP:
handle_osd_map(static_cast<MOSDMap*>(m));
break;
case MSG_PGSTATSACK:
handle_pg_stats_ack(static_cast<MPGStatsAck*>(m));
break;
case MSG_MON_COMMAND:
handle_command(static_cast<MMonCommand*>(m));
break;
case MSG_COMMAND:
handle_command(static_cast<MCommand*>(m));
break;
case MSG_OSD_SCRUB:
handle_scrub(static_cast<MOSDScrub*>(m));
break;
......
}
主动发起连接
//第一阶段:建立tcp连接,交换RDMA GID等信息
AsyncMessenger::create_connect(entity_addr_t &addr,int type,bool is_separate_wk)
|–|w=AsyncMessenger::stack->get_worker();
|–|conn = new AsyncConnection(cct,this,dispatch_queue,w,is_separate_wk,logArray)
AsyncConnection()
{
……
read_handler = new C_handle_read(this);
write_handler = new C_handle_write(this);
write_callback_handler = new C_handle_write_callback(this);
wakeup_handler = new C_time_wakeup(this);
tick_handler = new C_tick_wakeup(this);
……
}
|–|conn->connect(addr,type);//AsyncConnection::connect //<–AsyncConnection.h
|–|–|set_peer_type(type);
|–|–|set_peer_addrs(addrs);
|–|–|_connect(); //AsyncConnection::_connect
//创建event放入eventcenter中心马上执行,回调是read_handler=C_handle_read见附录1,所以执行的是AsyncConnection::process();
|–|–|–|state = STATE_CONNECTING; //注意这里,下一步的conn->process()的state 的初值
|–|–|–|center->dispatch_event_external(read_handler);
class C_handle_read : public EventCallback {
AsyncConnectionRef conn;
public:
explicit C_handle_read(AsyncConnectionRef c): conn(c) {}
void do_request(int fd_or_id) override {
conn->process();
}
};
conn->process()//AsyncConnection::process() ,state 的初值是STATE_CONNECTING ,所以进入 switch (state) 的defualt
*–_process_connection()
//–>RDMAWorker->connect(entity_addr_t &addr,SocketOptions &opts,ConnectedSocket *socket); //RDMAWorker in RDMAStack.cc
*—-r = worker->connect(get_peer_addr(), opts, &cs);
*——int r=p->try_connect(addr, opts);//RDMAConnectedSocketImpl::try_connect
*——–tcp_fd = net.connect(peer_addr, opts.connect_bind_addr); //与server 端建立起TCP连接
//往server 发送TCP数据,server端产生EVENT_READABLE事件回调con_handler,【S1】
*——–r = infiniband->send_msg(cct, tcp_fd, my_msg); //发送本端RDMA 通信需要的GID等信息
//client端也在tcp连接上注册event,回调con_handler,处理server 的tcp数据
*——–worker->center.create_file_event(tcp_fd, EVENT_READABLE, con_handler);
state STATE_CONNECTING 切换到STATE_CONNECTING_RE
client infiniband->send_msg(cct, tcp_fd, my_msg); try发一个my_msg给server,server 收到回复它的my_msg
触发client的回调con_handler=C_handle_connection
csi->handle_connection();//RDMAConnectedSocketImpl::handle_connection
|–| if (!is_server) {}else{} r = infiniband->send_msg(cct, tcp_fd, my_msg);//收到server的my_msg(GID),也把自己的my_msg(GID)发过去
//第二阶段:根据交互的信息得知对方QP的 ID,激活RDMA 通道
r = activate();
state STATE_CONNECTING 切换到STATE_CONNECTING_RE
//第三阶段:asyncMessenger 两端协商握手,直至连接的状态为 state STATE_OPEN
状态切换见图:
最后然后就可以messenger->send 发送数据
=============================================
各组件内的messenger如何知道连接对端的哪个messenger

每个实例内都会创建多个messenger,例如OSD
Messenger *ms_public = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "client", nonce);
Messenger *ms_cluster = Messenger::create(g_ceph_context, cluster_msg_type,
entity_name_t::OSD(whoami), "cluster", nonce);
Messenger *ms_hb_back_client = Messenger::create(g_ceph_context, cluster_msg_type,
entity_name_t::OSD(whoami), "hb_back_client", nonce);
Messenger *ms_hb_front_client = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "hb_front_client", nonce);
Messenger *ms_hb_back_server = Messenger::create(g_ceph_context, cluster_msg_type,
entity_name_t::OSD(whoami), "hb_back_server", nonce);
Messenger *ms_hb_front_server = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "hb_front_server", nonce);
Messenger *ms_objecter = Messenger::create(g_ceph_context, public_msg_type,
那么OSD.a 和OSD.b 通信的时候OSD.a 的ms_hb_back_client 怎么知道要连的是OSD.b的ms_hb_back_client?
messenger创建之后,会bind,如下:
public_messenger->bind()
|--|AsyncMessenger::bind()
|--|--|Processor::bind()
AsyncMessenger::bind实际是调用Processor::bind完成:
AsyncMessenger::bindv(){
AsyncMessenger::bindv(){
std::set<int> avoid_ports;
entity_addrvec_t bound_addrs;
unsigned i = 0;
for (auto &&p : processors) {
int r = p->bind(bind_addrs, avoid_ports, &bound_addrs);
}
}
Processor::bind中从bind_addrs中逐个拿出listen_addr ,遍历ms_bind_port_min到ms_bind_port_max内的port,找到一个本实例未使用的port(本实例使用过的放入avoid_ports)来bind。bind成功了就把port放入listen_addr中(listen_addr.set_port(port),这样就有IP和port了)
int Processor::bind(const entity_addrvec_t &bind_addrs,
const std::set<int>& avoid_ports,
entity_addrvec_t* bound_addrs)
{
……
listen_sockets.resize(bind_addrs.v.size());
*bound_addrs = bind_addrs;
for (unsigned k = 0; k < bind_addrs.v.size(); ++k) {
auto& listen_addr = bound_addrs->v[k];
//try a range of ports 在给定的端口范围内,找出一个没有被本进程使用过的端口,且能绑定上的
for (int port = msgr->cct->_conf->ms_bind_port_min;
port <= msgr->cct->_conf->ms_bind_port_max;
port++)
{
if (avoid_ports.count(port))
continue;
listen_addr.set_port(port);//找到一个端口,接下来尝试bind
worker->center.submit_to(
worker->center.get_id(),
[this, k, &listen_addr, &opts, &r]() {
r = worker->listen(listen_addr, k, opts, &listen_sockets[k]);
}, false);
if (r == 0)
break;
}
if (r < 0) {
lderr(msgr->cct) << __func__ << " unable to bind to " << listen_addr
<< " on any port in range "
<< msgr->cct->_conf->ms_bind_port_min
<< "-" << msgr->cct->_conf->ms_bind_port_max << ": "
<< cpp_strerror(r) << dendl;
listen_addr.set_port(0); // Clear port before retry, otherwise we shall fail again.
continue;
}
ldout(msgr->cct, 10) << __func__ << " bound on random port "
}
}
bind完成之后,将传入参数bind_addrs里的对应的v的port设置为 (ms_bind_port_min到ms_bind_port_max之间的某端口号,然后交给 worker->listen,如果listen成功就返回,传入参数entity_addrvec_t bind_addrs里的对应的v的port的值,就为刚才设置的值,传出去了。这样本地messenger的IP和port就有了。对端的messenger只要知道IP和port就可以连接上对应的messenger了。
int Processor::bind(const entity_addrvec_t &bind_addrs,……)
auto& listen_addr = bound_addrs->v[k];
listen_addr.set_port(port);
r = worker->listen(listen_addr, k, opts, &listen_sockets[k]);
Processor::bind实际是调用RDMAWorker::listen,RDMAWorker::listen调用socket的::bind和::listen 完成监听工作。
int RDMAWorker::listen(entity_addr_t &sa, unsigned addr_slot,
const SocketOptions &opt,ServerSocket *sock)
p = new RDMAServerSocketImpl(cct, ib, dispatcher, this, sa, addr_slot);
int r = p->listen(sa, opt);
int RDMAServerSocketImpl::listen(entity_addr_t &sa, const SocketOptions &opt)
{
int rc = 0;
server_setup_socket = net.create_socket(sa.get_family(), true);
if (server_setup_socket < 0) {
rc = -errno;
lderr(cct) << __func__ << " failed to create server socket: "
<< cpp_strerror(errno) << dendl;
return rc;
}
rc = net.set_nonblock(server_setup_socket);
if (rc < 0) {
goto err;
}
rc = net.set_socket_options(server_setup_socket, opt.nodelay, opt.rcbuf_size);
if (rc < 0) {
goto err;
}
rc = ::bind(server_setup_socket, sa.get_sockaddr(), sa.get_sockaddr_len()); <----------这里
if (rc < 0) {
rc = -errno;
ldout(cct, 10) << __func__ << " unable to bind to " << sa.get_sockaddr()
<< " on port " << sa.get_port() << ": " << cpp_strerror(errno) << dendl;
goto err;
}
rc = ::listen(server_setup_socket, cct->_conf->ms_tcp_listen_backlog);
if (rc < 0) {
rc = -errno;
lderr(cct) << __func__ << " unable to listen on " << sa << ": " << cpp_strerror(errno) << dendl;
goto err;
}
ldout(cct, 20) << __func__ << " bind to " << sa.get_sockaddr() << " on port " << sa.get_port() << dendl;
return 0;
err:
::close(server_setup_socket);
server_setup_socket = -1;
return rc;
}
通信两端的实例,如何知道对端的IP和各个messenger的port ? 这就涉及到OSDMap,
什么是OSDMap 和 PGMap
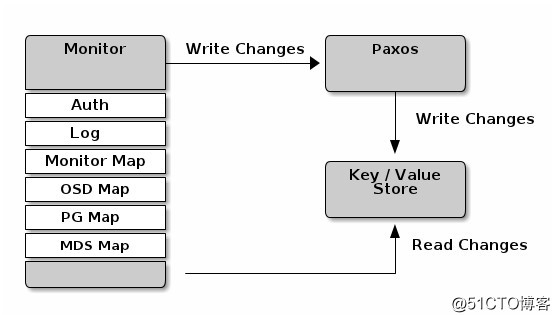
(摘自:Ceph 存储中OSDMap 和 PGMap介绍_Darren_Wen的技术博客_51CTO博客,源文:Analizar Ceph: OSD, OSDMap y PG, PGMap - programador clic)Monitor 作为Ceph的 Metada Server 维护了集群的信息,它包括了6个 Map,分别是 MONMap,OSDMap,PGMap,LogMap,AuthMap,MDSMap。其中 PGMap 和 OSDMap 是最重要的两张Map。
OSDMap
OSDMap 是 Ceph 集群中所有 OSD 的信息,所有 OSD 状态的改变如进程退出,OSD的加入和退出或者OSD的权重的变化都会反映到这张 Map 上。这张 Map 不仅会被 Monitor 掌握,OSD 节点和 Client 也会从 Monitor 得到这张表,因此实际上我们需要处理所有 “Client” (包括 OSD,Monitor 和 Client)的 OSDMap 持有情况。
……
*下面的内容还没有研究透
所以应该是OSD 启动之后,向monitor上报自己的map信息(包含自己的messenger和bind的端口),然后还向monitor获取到OSDmap(包含各个实例的messenger和bind的端口),这样各个messenger就可以向对端对应的messenger建立连接和发送消息了。
例如以心跳为例:
《心跳机制》ceph Heartbeat 分析 - 知乎
void OSD::heartbeat_entry()
{
Mutex::Locker l(heartbeat_lock);
if (is_stopping())
return;
while (!heartbeat_stop)
{
heartbeat();//发送消息
double wait = .5 + ((float)(rand() % 10) / 10.0) * (float)cct->_conf->osd_heartbeat_interval;//心跳间隔:在6s的基础上附加随机值
...
}
heartbeat() 遍历所有peers,发送心跳,往前端 i->second.con_front->send_message往后端 i->second.con_back->send_message,
void OSD::heartbeat()
{
...
//遍历所有peers,发送心跳
for (map<int, HeartbeatInfo>::iterator i = heartbeat_peers.begin(); <--------------遍历
i != heartbeat_peers.end();
++i) {
int peer = i->first;
i->second.last_tx = now;
if (i->second.first_tx == utime_t())
i->second.first_tx = now;
i->second.con_back->send_message(new MOSDPing(monc->get_fsid(),
service.get_osdmap()->get_epoch(),
MOSDPing::PING, now,
cct->_conf->osd_heartbeat_min_size));
if (i->second.con_front)
i->second.con_front->send_message(new MOSDPing(monc->get_fsid(),
service.get_osdmap()->get_epoch(),
MOSDPing::PING, now,
cct->_conf->osd_heartbeat_min_size));
}
...
这里可以看到,HeartbeatInfo里保存con_front和con_back ,这两个就是告诉heartbeat要发到哪里(哪个实例的哪个messenger)
struct HeartbeatInfo {
int peer; ///< peer
ConnectionRef con_front; ///< peer connection (front)
ConnectionRef con_back; ///< peer connection (back)
utime_t first_tx; ///< time we sent our first ping request
utime_t last_tx; ///< last time we sent a ping request
utime_t last_rx_front; ///< last time we got a ping reply on the front side
utime_t last_rx_back; ///< last time we got a ping reply on the back side
……
}
HeartbeatInfo里保存con_front和con_back 是在_add_heartbeat_peer里面赋值的
hi->con_back = cons.first.get();
hi->con_front = cons.second.get();
cons 是来自service.get_con_osd_hb(p, get_osdmap_epoch());
pair<ConnectionRef,ConnectionRef> cons = service.get_con_osd_hb(p, get_osdmap_epoch());
可以看到cons是get_con_osd_hb根据osdmap建立连接然后返回的,见下文
void OSD::_add_heartbeat_peer(int p)
{
if (p == whoami)
return;
HeartbeatInfo *hi;
map<int,HeartbeatInfo>::iterator i = heartbeat_peers.find(p);
if (i == heartbeat_peers.end()) {
pair<ConnectionRef,ConnectionRef> cons = service.get_con_osd_hb(p, get_osdmap_epoch());
if (!cons.first)
return;
assert(cons.second);
hi = &heartbeat_peers[p];
hi->peer = p;
auto stamps = service.get_hb_stamps(p);
auto sb = ceph::make_ref<Session>(cct, cons.first.get());
sb->peer = p;
sb->stamps = stamps;
hi->hb_interval_start = ceph_clock_now();
hi->con_back = cons.first.get();
hi->con_back->set_priv(sb);
auto sf = ceph::make_ref<Session>(cct, cons.second.get());
sf->peer = p;
sf->stamps = stamps;
hi->con_front = cons.second.get();
hi->con_front->set_priv(sf);
dout(10) << "_add_heartbeat_peer: new peer osd." << p
<< " " << hi->con_back->get_peer_addr()
<< " " << hi->con_front->get_peer_addr()
<< dendl;
} else {
hi = &i->second;
}
hi->epoch = get_osdmap_epoch();
}
get_con_osd_hb里面
OSDMapRef next_map = get_nextmap_reserved();
……
ret.first = osd->hb_back_client_messenger->connect_to_osd(
next_map->get_hb_back_addrs(peer));
ret.second = osd->hb_front_client_messenger->connect_to_osd(
next_map->get_hb_front_addrs(peer));
pair<ConnectionRef,ConnectionRef> OSDService::get_con_osd_hb(int peer, epoch_t from_epoch)
{
OSDMapRef next_map = get_nextmap_reserved();
// service map is always newer/newest
ceph_assert(from_epoch <= next_map->get_epoch());
pair<ConnectionRef,ConnectionRef> ret;
if (next_map->is_down(peer) ||
next_map->get_info(peer).up_from > from_epoch) {
release_map(next_map);
return ret;
}
ret.first = osd->hb_back_client_messenger->connect_to_osd(
next_map->get_hb_back_addrs(peer));
ret.second = osd->hb_front_client_messenger->connect_to_osd(
next_map->get_hb_front_addrs(peer));
release_map(next_map);
return ret;
}
const entity_addrvec_t &get_hb_back_addrs(int osd) const {
ceph_assert(exists(osd));
return osd_addrs->hb_back_addrs[osd] ? *osd_addrs->hb_back_addrs[osd] : _blank_addrvec;
}
返回 osd_addrs->hb_back_addrs[osd] ,是个entity_addrvec_t ,里面的entity_addr_t就有IP和port
(sockaddr sa; sockaddr_in sin; sin.sin_port)
struct entity_addrvec_t {
std::vector<entity_addr_t> v;
……
}
struct entity_addr_t {
……
__u32 type;
__u32 nonce;
union {
sockaddr sa;
sockaddr_in sin;
sockaddr_in6 sin6;
} u;
void set_port(int port) {
switch (u.sa.sa_family) {
case AF_INET:
u.sin.sin_port = htons(port);
break;
case AF_INET6:
u.sin6.sin6_port = htons(port);
break;
default:
ceph_abort();
}
}
……
}
上面的hb_back_addrs来自osd_addrs,osd_addrs是OSDMap 的成员,可见就是来自osdmap,就是来自monitor的osdmap
class OSDMap
{
……
std::shared_ptr osd_addrs;
……
}
OSD自身向monitor上报的信息中,含
class OSDMap {
……
struct addrs_s {
mempool::osdmap::vector<std::shared_ptr > client_addrs;
mempool::osdmap::vector<std::shared_ptr > cluster_addrs;
mempool::osdmap::vector<std::shared_ptr > hb_back_addrs;
mempool::osdmap::vector<std::shared_ptr > hb_front_addrs;
};
……
}
结论:
可见各个实例的messenger和对端的哪个messenger通信,是由实例的的map决定的。实例在创建messenger之后,把messenger的的IP和bind的端口记录到map中,然后上传至mon合并,并从mon获得map,然后通信的时候从map中获取对端的addr(内含ip和port):client_addrs 或 cluster_addrs或hb_back_addrs …… 相应的messenger的addrs ,然后connect 发送数据
sockaddr和sockaddr_in详解
struct sockaddr 和 struct sockaddr_in 这两个结构体用来处理网络通信的地址。
一、sockaddr
sockaddr在头文件#include <sys/socket.h>中定义,sockaddr的缺陷是:sa_data把目标地址和端口信息混在一起了,如下:
struct sockaddr {
sa_family_t sin_family;//地址族
char sa_data[14]; //14字节,包含套接字中的目标地址和端口信息
};
二、sockaddr_in
sockaddr_in在头文件#include<netinet/in.h>或#include <arpa/inet.h>中定义,该结构体解决了sockaddr的缺陷,把port和addr 分开储存在两个变量中,如下:
sin_port和sin_addr都必须是网络字节序(NBO),一般可视化的数字都是主机字节序(HBO)。
三、总结
二者长度一样,都是16个字节,即占用的内存大小是一致的,因此可以互相转化。二者是并列结构,指向sockaddr_in结构的指针也可以指向sockaddr。
sockaddr常用于bind、connect、recvfrom、sendto等函数的参数,指明地址信息,是一种通用的套接字地址。
sockaddr_in 是internet环境下套接字的地址形式。所以在网络编程中我们会对sockaddr_in结构体进行操作,使用sockaddr_in来建立所需的信息,最后使用类型转化就可以了。一般先把sockaddr_in变量赋值后,强制类型转换后传入用sockaddr做参数的函数:sockaddr_in用于socket定义和赋值;sockaddr用于函数参数。
————————————————
版权声明:本文为CSDN博主「阿卡基YUAN」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:sockaddr和sockaddr_in详解_阿卡基YUAN的博客-CSDN博客_sockaddr_in
=============================================
源文:
Ceph Async Messenger http://blog.wjin.org/posts/ceph-async-messenger.html
http://blog.wjin.org/posts/ceph-async-messenger.html
Server
服务端需要监听端口,等待连接请求到来,然后接受请求建立连接进行通信。
Initialization
以osd进程为例,在进程启动的过程中,会创建Messenger对象,用于管理网络连接,监听端口,接收请求,源码在文件src/ceph_osd.cc:
int main(int argc, const char **argv)
{
......
// public用于客户端通信
Messenger *ms_public = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "client",
getpid());
// cluster用于集群内部通信
Messenger *ms_cluster = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "cluster",
getpid());
......
}
// src/msg/Messenger.cc
Messenger *Messenger::create(CephContext *cct, const string &type,
entity_name_t name, string lname,
uint64_t nonce)
{
......
// 在src/common/config_opts.h文件中,目前需要配置async相关选项才会生效
// OPTION(enable_experimental_unrecoverable_data_corrupting_features, OPT_STR, "ms-type-async")
// OPTION(ms_type, OPT_STR, "async")
else if ((r == 1 || type == "async") &&
cct->check_experimental_feature_enabled("ms-type-async"))
return new AsyncMessenger(cct, name, lname, nonce);
......
return NULL;
}
AsyncMessenger 类的构造函数需要注意,虽然在osd进程的启动过程中,会创建6个messenger,但是他们全部共享一个WorkerPool(在12版本后改为stackSingleton), 函数lookup_or_create_singleton_object保证只会创建一个pool,因为传入的名称WokerPool::name是一样的:
AsyncMessenger::AsyncMessenger(CephContext *cct, entity_name_t name,
string mname, uint64_t _nonce)
: SimplePolicyMessenger(cct, name,mname, _nonce),
processor(this, cct, _nonce),
lock("AsyncMessenger::lock"),
nonce(_nonce), need_addr(true), did_bind(false),
global_seq(0), deleted_lock("AsyncMessenger::deleted_lock"),
cluster_protocol(0), stopped(true)
{
ceph_spin_init(&global_seq_lock);
cct->lookup_or_create_singleton_object<WorkerPool>(pool, WorkerPool::name); // 创建pool对象, 注意第二个参数是WorkerPool中的静态常量
// 创建一个本地连接对象用于向自己发送消息
local_connection = new AsyncConnection(cct, this, &pool->get_worker()->center);
init_local_connection(); // 初始化本地对象
}
template<typename T>
void lookup_or_create_singleton_object(T*& p, const std::string &name) {
ceph_spin_lock(&_associated_objs_lock);
if (!_associated_objs.count(name)) { // name决定了一个进程只会有一个pool
p = new T(this); // new一个对象,这里是WorkerPool
_associated_objs[name] = reinterpret_cast<AssociatedSingletonObject*>(p); // 加入map
} else {
p = reinterpret_cast<T*>(_associated_objs[name]);
}
ceph_spin_unlock(&_associated_objs_lock);
}
另外需要注意,这个进程的公共pool是在messenger的构造函数分配的,但pool的释放却不是messenger的析构函数负责,因为多个messenger共享一个pool, 一个messenger销毁了可能其他messenger还在用这pool。
这个pool的释放是CephContext的析构函数负责,pool的指针存放在CephContext成员变量_associated_objs中, 因为daemon进程有一个全局唯一的CephContext,当CephContext析构的时候,会释放pool指针的内存。
一个osd进程只会有一个WorkerPool,那这个pool在初始化的时候干什么事情了?顾名思义,Worker的Pool,肯定是用来管理Worker的, 构造函数中恰恰就是新建了Worker类的对象,而Worker类继承于线程类,肯定就是单独干活的线程,源码在文件 src/msg/async/AsyncMessenger.[h|c]中:
WorkerPool::WorkerPool(CephContext *c): cct(c), seq(0), started(false),
barrier_lock("WorkerPool::WorkerPool::barrier_lock"),
barrier_count(0)
{
assert(cct->_conf->ms_async_op_threads > 0);
for (int i = 0; i < cct->_conf->ms_async_op_threads; ++i) {
Worker *w = new Worker(cct, this, i); // 新建Worker类对象
workers.push_back(w); // 保存在vector容器中, 用于跟踪所有的worker
}
......
}
class Worker : public Thread { // 继承线程类,说明Worker类单独包含线程
static const uint64_t InitEventNumber = 5000; // 事件个数
static const uint64_t EventMaxWaitUs = 30000000; // 事件最大的等待时间, 30秒
CephContext *cct;
WorkerPool *pool;
bool done;
int id;
public:
EventCenter center; // 事件中心
Worker(CephContext *c, WorkerPool *p, int i)
: cct(c), pool(p), done(false), id(i), center(c) {
center.init(InitEventNumber); // 初始化事件驱动, 实际上就是初始化了epoll相关的结构
}
void *entry();
void stop();
};
为了代码通用,这里单独抽象了一层出来,即EventCenter,用来管理各种事件的驱动,比如epoll, kqueue, select等。 源码在src/msg/async/Event.[h]c]:
class EventCenter {
......
FileEvent *file_events; // 所有io事件
EventDriver *driver; // 具体的驱动
map<utime_t, list<TimeEvent> > time_events; // 所有时间事件
......
};
// EventDriver接口
// epoll的驱动继承此接口,接口的实现就是对epoll三个系统调用epoll_create, epoll_ctl,epoll_wait的封装
class EventDriver {
public:
virtual ~EventDriver() {} // we want a virtual destructor!!!
virtual int init(int nevent) = 0;
virtual int add_event(int fd, int cur_mask, int mask) = 0;
virtual void del_event(int fd, int cur_mask, int del_mask) = 0;
virtual int event_wait(vector<FiredFileEvent> &fired_events, struct timeval *tp) = 0;
virtual int resize_events(int newsize) = 0;
};
class EpollDriver : public EventDriver {
int epfd; // epoll fd
struct epoll_event *events; // 等待事件的结构体指针,可以查看epoll相关资料
CephContext *cct;
int size;
......
};
Worker构造函数中,调用了center的init函数,看看center.init干了些什么事情?
int EventCenter::init(int n)
{
......
driver = new EpollDriver(cct); // 新建一个驱动对象
int r = driver->init(n); // 初始化具体的驱动
int fds[2]; // pipe用来唤醒worker线程,后文会分析到
if (pipe(fds) < 0) {
lderr(cct) << __func__ << " can't create notify pipe" << dendl;
return -1;
}
notify_receive_fd = fds[0];
notify_send_fd = fds[1];
......
create_file_event(notify_receive_fd, EVENT_READABLE, EventCallbackRef(new C_handle_notify())); // 监听pipe的可读事件
return 0;
}
// 初始化epoll
int EpollDriver::init(int nevent)
{
events = (struct epoll_event*)malloc(sizeof(struct epoll_event)*nevent); // nevent就是Worker类中的InitEventNumber
memset(events, 0, sizeof(struct epoll_event)*nevent);
epfd = epoll_create(1024); // 获取一个epoll fd
size = nevent;
return 0;
}
从osd进程,到AsyncMessenger类,接着到所有messenger共享的WorkerPool,然后初始化进程唯一pool的每个Worker,然后worker中借助于EventCenter统一管理所有事件, 并且初始化了具体的事件处理机制,如epoll.
似乎所有工作已经就绪? 其实不然,首先,worker的线程并没有启动,其次,osd进程的messenger也并没有绑定到特定端口进行监听,所以osd启动的过程中,还得有其他步骤。
Bind and Listen
在messenger创建以后,会设置策略以及限流的参数,接下来就会绑定地址,对网络层套接字的处理,比如socket/bind/listen/accept等,主要是通过类Processor来管理:
// 继续ceph_osd.cc代码
int main(int argc, const char **argv)
{
......
// 设置协议
ms_cluster->set_cluster_protocol(CEPH_OSD_PROTOCOL);
......
// 设置策略以及限流
ms_public->set_default_policy(Messenger::Policy::stateless_server(supported, 0));
ms_public->set_policy_throttlers(entity_name_t::TYPE_CLIENT,
client_byte_throttler.get(),
client_msg_throttler.get());
......
// 绑定地址
r = ms_public->bind(g_conf->public_addr);
if (r < 0)
exit(1);
r = ms_cluster->bind(g_conf->cluster_addr);
if (r < 0)
exit(1);
......
ms_public->start(); // 启动线程
......
err = osd->init(); // 这里很关键, 后文分析
......
ms_public->wait(); // 等待线程结束
......
}
int AsyncMessenger::bind(const entity_addr_t &bind_addr)
{
......
// bind to a socket
set<int> avoid_ports;
int r = processor.bind(bind_addr, avoid_ports); // 调用processor对象进行处理
......
}
// processor的处理就是对socket API的封装:socket, bind, listen
// 创建套接字,绑定到特定端口,进行监听
int Processor::bind(const entity_addr_t &bind_addr, const set<int>& avoid_ports)
{
......
listen_sd = ::socket(family, SOCK_STREAM, 0);
......
rc = ::bind(listen_sd, (struct sockaddr *) &listen_addr.ss_addr(), listen_addr.addr_size());
......
rc = ::listen(listen_sd, 128);
......
msgr->init_local_connection(); // 更新地址,但是因为还没有dispatch对象,不会处理连接
return 0;
}
void init_local_connection() {
Mutex::Locker l(lock);
_init_local_connection();
}
void _init_local_connection() {
assert(lock.is_locked());
local_connection->peer_addr = my_inst.addr;
local_connection->peer_type = my_inst.name.type();
ms_deliver_handle_fast_connect(local_connection.get());
}
void ms_deliver_handle_fast_connect(Connection *con) {
for (list<Dispatcher*>::iterator p = fast_dispatchers.begin(); // fast_dispatchers 目前为空
p != fast_dispatchers.end();
++p)
(*p)->ms_handle_fast_connect(con);
}
Deal with Event
在绑定地址进行端口监听以后,就会等着连接到来,要处理连接请求,肯定得创建Worker线程来处理吧?
// ceph_osd.cc 会继续调用messenger->start(), 参见前面代码
int AsyncMessenger::start()
{
lock.Lock();
......
pool->start(); // 启动所有线程(在12版之后,pool被stack代替,stack在messager构造中start)
lock.Unlock();
return 0;
}
void WorkerPool::start()
{
if (!started) {
for (uint64_t i = 0; i < workers.size(); ++i) {
workers[i]->create(); // 创建线程
}
started = true;
}
}
// 线程入口函数
void *Worker::entry()
{
......
center.set_owner(pthread_self());
while (!done) { // 线程一直循环处理事件
int r = center.process_events(EventMaxWaitUs); // 借助于事件中心处理事件, 注意最大的等待时间是30秒
}
return 0;
}
// 通过epoll_wait返回所有就绪的fd,然后一次调用其callback
int EventCenter::process_events(int timeout_microseconds)
{
......
vector<FiredFileEvent> fired_events;
next_time = shortest;
numevents = driver->event_wait(fired_events, &tv); // 获取当前的io事件
for (int j = 0; j < numevents; j++) {
int rfired = 0;
FileEvent *event;
{
Mutex::Locker l(file_lock);
event = _get_file_event(fired_events[j].fd);
}
if (event->mask & fired_events[j].mask & EVENT_READABLE) {
rfired = 1;
event->read_cb->do_request(fired_events[j].fd); // 处理可读事件
}
if (event->mask & fired_events[j].mask & EVENT_WRITABLE) {
if (!rfired || event->read_cb != event->write_cb)
event->write_cb->do_request(fired_events[j].fd); // 处理可写事件
}
}
......
}
int EpollDriver::event_wait(vector<FiredFileEvent> &fired_events, struct timeval *tvp)
{
int retval, numevents = 0;
retval = epoll_wait(epfd, events, size,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1); // epoll_wait系统调用,等待就绪事件或超时返回
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = events + j;
if (e->events & EPOLLIN) mask |= EVENT_READABLE;
if (e->events & EPOLLOUT) mask |= EVENT_WRITABLE;
if (e->events & EPOLLERR) mask |= EVENT_WRITABLE;
if (e->events & EPOLLHUP) mask |= EVENT_WRITABLE;
// 记录下已经发生的事件
fired_events[j].fd = e->data.fd;
fired_events[j].mask = mask;
}
return numevents;
}
process_events函数中,需要注意的是,这里处理三种事件,
与fd相关的读写事件,
与时间相关的time事件,
还有添加的外部事件,
在处理fd的时候,如果没有fd就绪就会一直wait等待超时(最大超时时间不超过下次时间事件的值)。但是,在这个过程中, 有两种情况需要被唤醒,一是添加了一个更小的时间事件(最近发生),二是添加了外部事件。
Add Listen Fd
Worker线程循环不停的处理事件,其实就是调用epoll_wait,返回就绪事件的fd,然后调用fd对应的回调read_cb或write_cb,很明显,epoll_wait能够返回就绪的fd, 这个fd必然是之前添加进去的,什么时候添加的呢?还记得在第二步Bind的时候,Processor类中创建了listen_fd,要想监听来自这个fd的请求,必然要将其添加到epoll进行管理。
但是从osd代码运行到这里,似乎都没有添加的动作?在osd调用messenger->start()后,紧接着就是:
err = osd->init();
诀窍就在这里:
int OSD::init()
{
......
// i'm ready!
client_messenger->add_dispatcher_head(this);
cluster_messenger->add_dispatcher_head(this);
......
}
void add_dispatcher_head(Dispatcher *d) {
bool first = dispatchers.empty(); // 刚开始当然为空, first为true
dispatchers.push_front(d);
if (d->ms_can_fast_dispatch_any())
fast_dispatchers.push_front(d);
if (first)
ready(); // 准备添加fd到epoll
}
void AsyncMessenger::ready()
{
ldout(cct,10) << __func__ << " " << get_myaddr() << dendl;
Mutex::Locker l(lock);
Worker *w = pool->get_worker(); // 获取一个worker干活
processor.start(w); // listen_sd在Processor中
}
int Processor::start(Worker *w)
{
ldout(msgr->cct, 1) << __func__ << " " << dendl;
// start thread
if (listen_sd > 0) {
worker = w;
// 创建可读事件, 最终会调用epoll_ctl将listen_sd加进epoll进行管理
w->center.create_file_event(listen_sd, EVENT_READABLE,
EventCallbackRef(new C_processor_accept(this))); // 注意事件的callback
}
return 0;
}
Accept Connection
listen fd添加进去以后,初始化过程就算全部完成了。当新的连接请求到来,如前所述,worker线程会调用process_event函数,回调就会被执行:
// listen fd 的回调
class C_processor_accept : public EventCallback {
Processor *pro;
public:
C_processor_accept(Processor *p): pro(p) {}
void do_request(int id) {
pro->accept(); // 回调
}
};
void Processor::accept()
{
while (errors < 4) {
entity_addr_t addr;
socklen_t slen = sizeof(addr.ss_addr());
int sd = ::accept(listen_sd, (sockaddr*)&addr.ss_addr(), &slen); // 接受连接请求
if (sd >= 0) {
msgr->add_accept(sd); // 通过messenger处理接收套接字sd
continue;
} else {
......
}
}
}
AsyncConnectionRef AsyncMessenger::add_accept(int sd)
{
lock.Lock();
Worker *w = pool->get_worker();
AsyncConnectionRef conn = new AsyncConnection(cct, this, &w->center); // 创建连接
w->center.dispatch_event_external(EventCallbackRef(new C_conn_accept(conn, sd))); // 分发事件, 外部新的连接,所以叫external
accepting_conns.insert(conn); // 记录下即将生效的连接, 最终完成后会从此集合删除
lock.Unlock();
return conn;
}
void EventCenter::dispatch_event_external(EventCallbackRef e)
{
external_lock.Lock();
external_events.push_back(e); // 将事件的callback函数放入事件中心的队列中等待执行
external_lock.Unlock();
wakeup(); // 唤醒worker线程
}
不是很明白为什么需要放入队列,等待worker下一次的process_event调用,是否可以直接执行完毕?
不管怎么样,放入队列后,需要执行队列中的callback,什么时候会执行呢?很明显是在worker线程中的process_event函数, 但是worker线程可能睡眠在epoll_wait(epoll管理的所有fd都没就绪,只能等待超时),如果有新连接到来,需要立即接收连接请求, 所以要唤醒睡眠的worker线程,后面的wakeup函数就是达到此目的,这个函数向pipe的一端写入数据(pipe是在函数EventCenter::init()中创建的), 使得另一端可读,即notify_receive_fd就绪,epoll_wait会返回其可读事件,然后执行其回调(回调就是简单读pipe),使得worker线程得以继续处理, 然后执行刚才放入队列中的回调。
void EventCenter::wakeup()
{
ldout(cct, 1) << __func__ << dendl;
char buf[1];
buf[0] = 'c';
// wake up "event_wait"
int n = write(notify_send_fd, buf, 1); // 唤醒worker线程
// FIXME ?
assert(n == 1);
}
int EventCenter::process_events(int timeout_microseconds)
{
......
numevents = driver->event_wait(fired_events, &tv); // 本来worker线程可能睡眠在这里,会被wakeup唤醒
// 这时候至少有一个fd就绪,即notify_receive_fd
// 执行所有fd的callback, 对于notify_receive_fd,可以看其callback,就是简单读一下,什么也没干
for (int j = 0; j < numevents; j++) {
......
event->read_cb->do_request(fired_events[j].fd);
.....
}
......
// 紧接着处理刚才的队列, 这正是唤醒worker的目的
{
external_lock.Lock();
while (!external_events.empty()) {
EventCallbackRef e = external_events.front();
external_events.pop_front();
external_lock.Unlock();
if (e)
e->do_request(0); // 连接请求的callback
external_lock.Lock();
}
external_lock.Unlock();
}
......
}
Add Accept Fd
从分析看,连接请求的callback会很快被执行。前面已经有了accept接收请求的fd,现在需要将那个fd加入epoll结构,管理起来,然后就可以进行通信, callback最终就是做这些事情:
// 队列中的回调类型
class C_conn_accept : public EventCallback {
AsyncConnectionRef conn;
int fd;
public:
C_conn_accept(AsyncConnectionRef c, int s): conn(c), fd(s) {}
void do_request(int id) {
conn->accept(fd);
}
};
void AsyncConnection::accept(int incoming)
{
ldout(async_msgr->cct, 10) << __func__ << " sd=" << incoming << dendl;
assert(sd < 0);
sd = incoming;
state = STATE_ACCEPTING;
center->create_file_event(sd, EVENT_READABLE, read_handler); // sd就是连接成功的fd,加进epoll管理
process(); // 服务器端的状态机开始执行,会先向客户端发送BANNER消息
}
Communication
注意服务端AsyncConnection状态机的初始状态是STATE_ACCEPTING,服务器端的状态机会先向客户端发送BANNER消息。 以后收到消息,worker线程就会调用read_handler处理,然后调用process,状态机不停的转换状态:
// 注册的回调类
class C_handle_read : public EventCallback {
AsyncConnectionRef conn;
public:
C_handle_read(AsyncConnectionRef c): conn(c) {}
void do_request(int fd_or_id) {
conn->process(); // 调用connection处理
}
};
void AsyncConnection::process()
{
int r = 0;
int prev_state = state;
Mutex::Locker l(lock);
do {
prev_state = state;
// connection状态机
switch (state) {
case STATE_OPEN:
......
default:
{
if (_process_connection() < 0)
goto fail;
break;
}
}
}
return 0;
fail:
......
}
// 单独处理连接信息
int AsyncConnection::_process_connection()
{
int r = 0;
switch(state) {
case STATE_WAIT_SEND:
......
}
......
}
AsyncConnection就是负责通信的类,要理解这个状态机的原理,必须理解ceph的应用层通信协议, 可以参看官方文档的解释。
AsyncMessenger的框架就算介绍完成了,当有新的连接请求到来,就会重复执行以下这几步:
-
accept connection
-
add accept fd
-
communication
由此可以看出,线程数不是随连接数线性增加的,只由最开始初始化的时候启动了多少个worker决定。
Client
客户端的操作主要是发起connect操作,建立连接进行通信。所有的客户端都是基于librados库,然后通过RadosClient连接集群的:
int librados::Rados::connect()
{
return client->connect();
}
int librados::RadosClient::connect()
{
......
// 创建messenger
messenger = Messenger::create(cct, cct->_conf->ms_type, entity_name_t::CLIENT(-1),
"radosclient", nonce);
......
// 创建objecter
// 发送消息的时候,比如librbd代码,都是通过objecter处理
// objecter需要借助于messenger发送,所以需要将创建的messenger传给objecter类
objecter = new (std::nothrow) Objecter(cct, messenger, &monclient,
&finisher,
cct->_conf->rados_mon_op_timeout,
cct->_conf->rados_osd_op_timeout);
// 同理,连接monitor也需要处理消息的收发
monclient.set_messenger(messenger);
objecter->init();
messenger->add_dispatcher_tail(objecter);
messenger->add_dispatcher_tail(this);
messenger->start();
......
messenger->set_myname(entity_name_t::CLIENT(monclient.get_global_id())); // ID全局唯一,所以需要向monitor获取
......
}
connect操作只是初始化了messenger对象,真正需要通信的时候,才会去建立连接,以objecter.cc中的op_submit为例:
ceph_tid_t Objecter::_op_submit(Op *op, RWLock::Context& lc)
{
......
int r = _get_session(op->target.osd, &s, lc);
......
}
int Objecter::_get_session(int osd, OSDSession **session, RWLock::Context& lc)
{
......
// session 不存在,会创建新的session,
s->con = messenger->get_connection(osdmap->get_inst(osd));
......
}
ConnectionRef AsyncMessenger::get_connection(const entity_inst_t& dest)
{
......
conn = create_connect(dest.addr, dest.name.type());
......
}
AsyncConnectionRef AsyncMessenger::create_connect(const entity_addr_t& addr, int type)
{
// create connection
Worker *w = pool->get_worker();
AsyncConnectionRef conn = new AsyncConnection(cct, this, &w->center); // 创建connection
conn->connect(addr, type); // 连接
assert(!conns.count(addr));
conns[addr] = conn;
return conn;
}
void connect(const entity_addr_t& addr, int type)
{
set_peer_type(type);
set_peer_addr(addr);
policy = msgr->get_policy(type);
_connect();
}
void AsyncConnection::_connect()
{
state = STATE_CONNECTING; // 这个初始化状态很关键,是客户端状态机的起始状态
stopping.set(0);
center->dispatch_event_external(read_handler); // 放入队列等待worker处理
}
这里和前面一样,worker会处理这个外部事件,read_handler就会调用process函数,紧接着就过度到_process_connection:
int AsyncConnection::_process_connection()
{
int r = 0;
switch(state) {
case STATE_CONNECTING: // 初始状态
{
......
sd = net.connect(get_peer_addr()); // 通过net类的功能,实际上就是调用connect系统调用,建立socket通信
// 连接成功后,将socket fd加入epoll进行管理
center->create_file_event(sd, EVENT_READABLE, read_handler);
state = STATE_CONNECTING_WAIT_BANNER;
break;
}
}
}
接下来就是客户端和服务端的通信,都是通过AsyncConnection的状态机完成。同理,客户端即使创建多个messenger, 他们仍然共享一个workerpool,线程数由这个pool初始化的时候决定,不会随着连接的增加而线性增加。
Summary
-
进程中所有的AsyncMessenger共享一个workerpool管理所有worker
-
Worker线程通过EventCenter负责具体的事件处理
-
应用层的网络通信由AsyncConnection的状态机处理


