

【存储】什么是 WAL|数据库性能
什么是 WAL
WAL(Write Ahead Log)预写日志,是数据库系统中常见的一种手段,用于
1、保证数据操作的原子性和持久性。
2、使得随机写变为顺序写提高性能。
「预写式日志」(Write-ahead logging,缩写 WAL)是关系数据库系统中用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。在使用 WAL 的系统中,所有的修改在提交之前都要先写入 log 文件中。
log 文件中通常包括 redo 和 undo 信息。这样做的目的可以通过一个例子来说明。假设一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行的操作是成功了还是部分成功或者是失败了。如果使用了 WAL,程序就可以检查 log 文件,并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
WAL 允许用 in-place (放置)方式更新数据库。
另一种用来实现原子更新的方法是 shadow paging,它并不是 in-place 方式。用 in-place 方式做更新的主要优点是减少索引和块列表的修改。ARIES 是 WAL 系列技术常用的算法。在文件系统中,WAL 通常称为 journaling。PostgreSQL 也是用 WAL 来提供 point-in-time 恢复和数据库复制特性。
备份
我们想一想,如果想保证对一个数据的操作可以恢复。可以怎么做?你不用去想数据库是怎么实现的,也不用想太高深。其实这是一个很简单的问题,我们常常在处理这种问题。最简单的方法其实就是备份一份数据:当我需要对一条数据做更新操作前,先将这条数据备份在一个地方,然后去更新,如果更新失败,可以从备份数据中回写回来。这样就可以保证事务的回滚,就可以保证数据操作的原子性了。其实 SQLite 引入 WAL 之前就是通过这种方式来实现原子事务,称之为 rollback journal, rollback journal 机制的原理是:在修改数据库文件中的数据之前,先将修改所在分页中的数据备份在另外一个地方,然后才将修改写入到数据库文件中;如果事务失败,则将备份数据拷贝回来,撤销修改;如果事务成功,则删除备份数据,提交修改。
WAL
再继续上面的问题?如何做到数据的可恢复(原子性)和提交成功的数据被持久化到磁盘(持久性)?另一种机制就是WAL,WAL 机制的原理也很简单:「修改并不直接写入到数据库文件中,而是写入到另外一个称为 WAL 的文件中;如果事务失败,WAL 中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。」
WAL 的优点
- 读和写可以完全地并发执行,不会互相阻塞(但是写之间仍然不能并发)。
- WAL 在大多数情况下,拥有更好的性能(因为无需每次写入时都要写两个文件)。
- 磁盘 I/O 行为更容易被预测。
- 使用更少的 fsync()操作,减少系统脆弱的问题。
提升性能
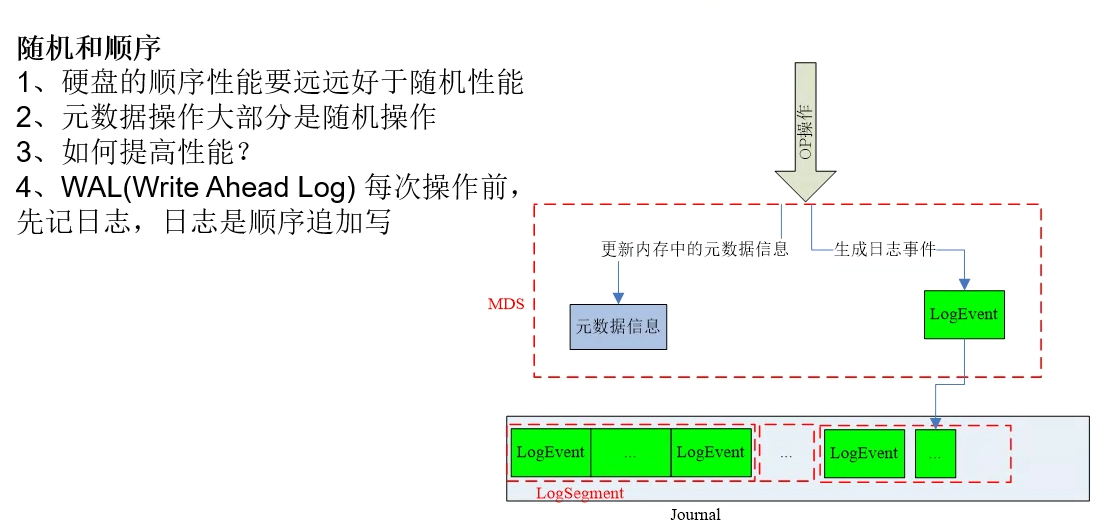
数据库的最大性能挑战就是磁盘的读写,提升数据存储性能上有方案最终总结出来就三种:「随机读写改顺序读写」、「缓冲单条读写改批量读写」、「单线程读写改并发读写」。
WAL 是两种思路的一种实现,一方面 WAL 中记录事务的更新内容,通过 WAL 将随机的脏页写入变成顺序的日志刷盘,另一方面,WAL 通过 buffer 的方式改单条磁盘刷入为缓冲批量刷盘,再者从 WAL 数据到最终数据的同步过程中可以采用并发同步的方式。这样极大提升数据库写入性能,因此,WAL 的写入能力决定了数据库整体性能的上限,尤其是在高并发时。
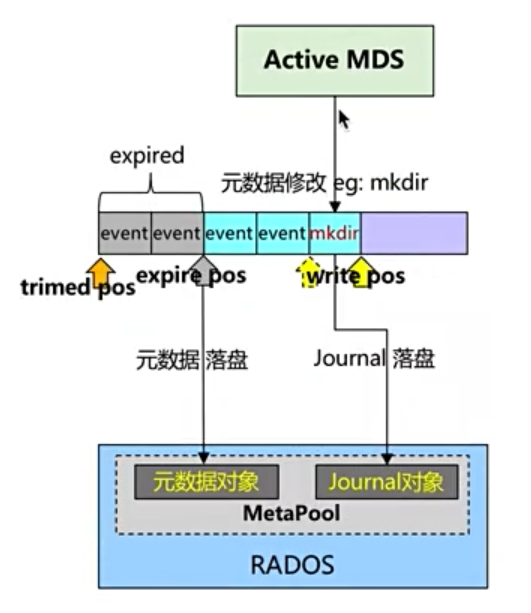
checkpoint
上面讲到,使用 WAL 的数据库系统不会再每新增一条 WAL 日志就将其刷入数据库文件中,一般积累一定的量然后批量写入,通常使用「页」为单位,这是磁盘的写入单位。 同步 WAL 文件和数据库文件的行为被称为 checkpoint(检查点),一般在 WAL 文件积累到一定页数修改的时候;当然,有些系统也可以手动执行 checkpoint。执行 checkpoint 之后,WAL 文件可以被清空,这样可以保证 WAL 文件不会因为太大而性能下降。
有些数据库系统读取请求也可以使用 WAL,通过读取 WAL 最新日志就可以获取到数据的最新状态。
具体实现
常见的数据库一般都会用到 WAL 机制,只是不同的系统说法和实现可能有所差异。mysql、sqlite、postgresql、etcd、hbase、zookeeper、elasticsearch 等等都有自己的实现。
mysql
mysql 的 WAL,大家可能都比较熟悉。mysql 通过 redo、undo 日志实现 WAL。redo log 称为重做日志,每当有操作时,在数据变更之前将操作写入 redo log,这样当发生掉电之类的情况时系统可以在重启后继续操作。undo log 称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。mysql 中用 redo log 来在系统 Crash 重启之类的情况时修复数据(事务的持久性),而 undo log 来保证事务的原子性。
zookeeper
和大多数分布式系统一样,ZooKeeper 也有 WAL(Write-Ahead-Log),对于每一个更新操作,ZooKeeper 都会先写 WAL, 然后再对内存中的数据做更新,然后向 Client 通知更新结果。另外,ZooKeeper 还会定期将内存中的目录树进行 Snapshot,落地到磁盘上。这么做的主要目的,一当然是数据的持久化,二是加快重启之后的恢复速度,如果全部通过 Replay WAL 的形式恢复的话,会比较慢。
elasticsearch
如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,elasticsearch 不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证可靠性,需要确保数据变化被持久化到磁盘。
在动态更新索引时,elasticsearch 说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,elasticsearch 仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?
Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。
etcd
用过 etcd 的同学可能会发现,etcd 的数据目录下有两个子目录wal和snap。它们的作用就是实现 WAL 机制用的。
wal: 存放预写式日志,最大的作用是记录了整个数据变化的全部历程。在 etcd 中,所有数据的修改在提交前,都要先写入到 WAL 中。
snap: 存放快照数据,etcd 防止 WAL 文件过多而设置的快照,存储 etcd 数据状态。
WAL 机制使得 etcd 具备了以下两个功能:
- 故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有 WAL 中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
- 数据回滚(undo)/重做(redo):因为所有的修改操作都被记录在 WAL 中,需要回滚或重做,只需要方向或正向执行日志中的操作即可
hbase
hbase 实现 WAL 的方法将 HLog,hbase 的 RegionServer 会将数据保存在内存中(MemStore),直到满足一定条件,将其 flush 到磁盘上。这样可以避免创建很多小文件。内存存储是不稳定的,HBase 也是使用 WAL 来解决这个问题:每次更新操作都会写日志,并且写日志和更新操作在一个事务中。
推荐系列
Mysql 大表问题和解决
Mysql 主键问题
列式存储
时间序列数据库(TSDB)初识与选择
十分钟了解 Apache Druid
Apache Druid 底层存储设计
Apache Druid 的集群设计与工作流程


