【ceph】什么是Ceph?------(MinIO和ceph的区别|GFS(GlusterFS)、MFS、Ceph、Lustre|文档)
目录
ceph和GFS(GlusterFS)、MFS、Ceph、Lustre
什么是Ceph?
简介
Ceph则是一个统一分布式存储系统(统一:同时支持块存储、文件存储和对象存储),具有优异的性能、可靠性和可扩展性。
Ceph底层是RADOS,它是分布式对象存储系统,由自修复、自管理、智能的存储节点组成。可以通过LIBRADOS直接访问到RADOS的对象存储系统。RBD(块设备接口)、RADOS Gateway(对象存储接口)、Ceph File System(POSIX接口)都是基于RADOS的。
Ceph能够提供企业中三种常见的存储需求:块存储、文件存储和对象存储,Ceph在一个统一的存储系统中同时提供了对象存储、块存储和文件存储,即Ceph是一个统一存储,能够将企业企业中的三种存储需求统一汇总到一个存储系统中,并提供分布式、横向扩展,高度可靠性的存储系统,Ceph存储提供的三大存储接口:

更详细:Ceph分布式存储详述 - 知乎https://zhuanlan.zhihu.com/p/164775822Ceph分布式存储详述 - 知乎
什么是块存储、文件存储和对象存储以及区别?
见:
https://blog.csdn.net/bandaoyu/article/details/109666281
块存储:(ceph 虚拟成一个磁盘,文件系统在上层服务器上把ceph集群当成一个磁盘用)

文件存储:(ceph 虚拟成一个文件系统,可以在服务器上挂载成一个目录(文件夹),用户可以直接在文件夹里面创建和删改数据)

对象存储:

Ceph存储架构
Ceph 独一无二地用统一的系统提供了对象、块、和文件存储功能。
Ceph还拥有大规模可扩展(PB、甚至EB级的存储空间)、基于CRUSH算法的自我管理和修复、灵活的架构等优点,并且支持OpenStack、CloudStack、OpenNebula、Hadoop等云平台。
Ceph 节点以普通硬件和智能守护进程作为支撑点, Ceph 存储集群组织起了大量节点,它们之间靠相互通讯来复制数据、并动态地重分布数据。
Ceph的主要目标是提供高可扩展性和提供对象存储、块存储和文件系统的存储机制,是一个高扩展、高容错、高一致的开源分布式存储平台。


接下来,我们先来看一下Ceph的存储架构,了解Ceph的分布式架构,功能组件和涉及相关概念。Ceph分布式集群是建立在RADOS算法之上的,RADOS是一个可扩展性,高可靠的存储服务算法,是Ceph的实现的基础。
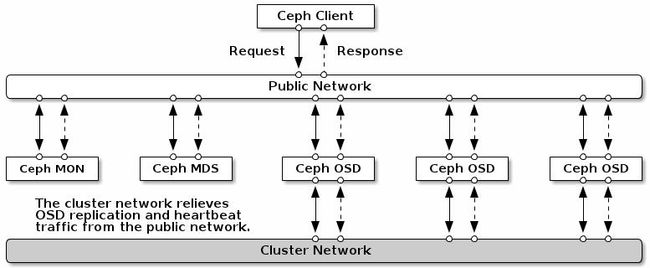
Ceph有两个重要的组件组成:Ceph Monitors(Ceph监视器)和Ceph OSDs(Ceph OSD 守护进程)。
其中Ceph Monitor作为集群中的控制中心,拥有整个集群的状态信息,Ceph Monitor肩负起整个集群协调工作;
同时Ceph Monitor还负责将集群的指挥工作,将集群的状态同步给客户端。
除了Ceph Monitor之外,还有一个重要的组件是OSD,集群中通常有多个OSD组成,OSD即Object Storage Daemon,负责Ceph集群中真正数据存储的功能,也就是我们的数据最终都会写入到OSD中。除了Monitor之外,根据Ceph提供的不同功能,还有其他组件,包括:
- ceph-mon(Ceph Monitors);
- ceph-osd (Ceph OSDs);
- ceph-mds (Ceph MDS),用于提供CephFS文件存储,提供文件存储所需元数据管理;
- ceph-rgw (Ceph RGW),用于提供Ceph对象存储网关,提供存储网关接入;
- ceph-mgr (Ceph Manager),ceph luminous版本新增组件,提供集群状态监控和性能监控:https://blog.csdn.net/bandaoyu/article/details/112009088
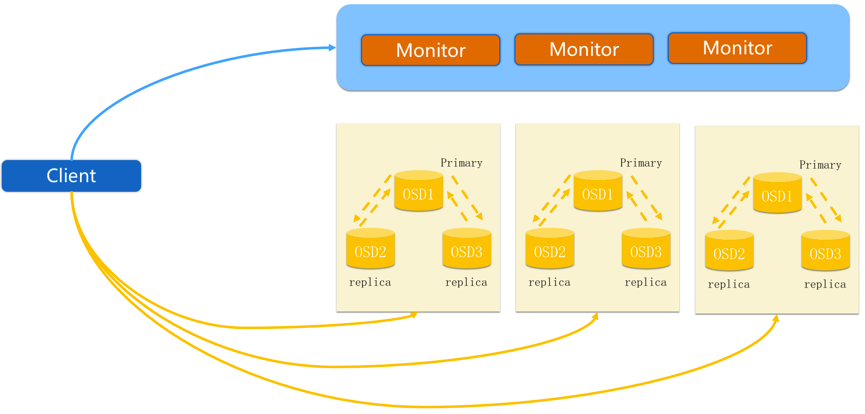
注:Ceph Monitor监视器维护着集群运行图的主副本。一个监视器集群确保了当某个监视器失效时的高可用性。存储集群客户端向 Ceph Monitor 监视器索取集群运行图的最新副本。而Ceph OSD 守护进程检查自身状态、以及其它 OSD 的状态,并报告给监视器们。存储集群的客户端和各个 Ceph OSD 守护进程使用 CRUSH 算法高效地计算数据位置,而不是依赖于一个中心化的查询表。它的高级功能包括:基于 librados的原生存储接口、和多种基于 librados 的服务接口。
Ceph数据的存储
Ceph中一切皆对象,不管是RBD块存储接口,RGW对象存储接口还是文件存储CephFS接口,其存储如到Ceph中的数据均可以看作是一个对象,一个文件需要切割为多个对象(object),然后将object存储到OSD中,如下图:
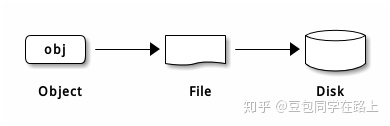
未完待续…… Ceph分布式存储详述 :https://zhuanlan.zhihu.com/p/164775822
Ceph开发如何入门
入门教程:《存储漫谈Ceph原理与实践》 https://developer.aliyun.com/profile/j7yibxh7iskfo/news_7?spm=a2c6h.13262185.profile.67.6ef61711nFA1AO
Ceph 是无中心分布式存储系统(计算模式)的典型代表。Ceph架构与 HDFS架构不同的地方在于该存储架构中没有中心节点(元数据不需要集中保存),客户端(Client)通过设备映射关系及预先定义算法,可直接本地计算出其写入数据的存储位置,这样客户端可以直接与存储节点(StorageNode)进行通信交互,避免元数据中心节点成为存储系统的性能瓶颈。Ceph系统架构如图 1-8所示。
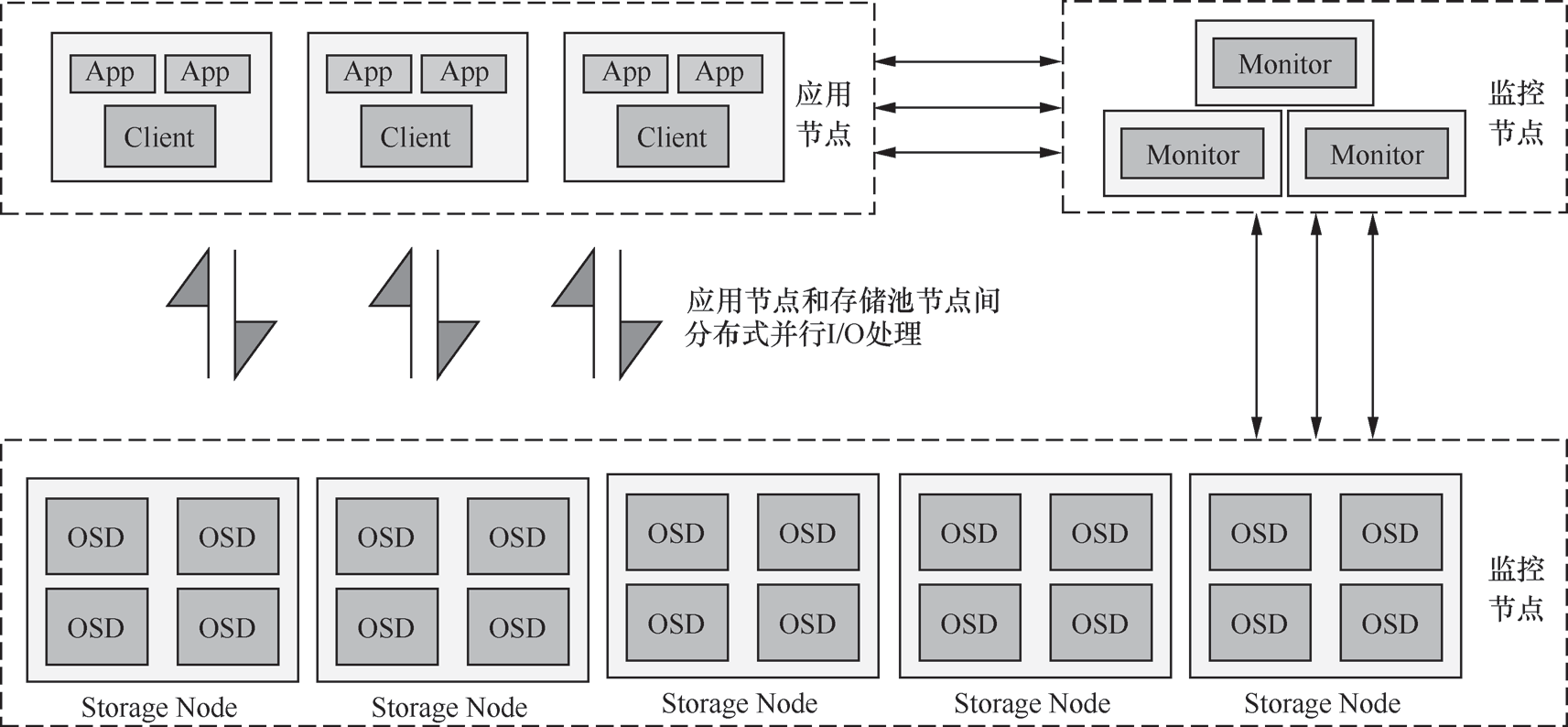
图 1-8Ceph系统架构
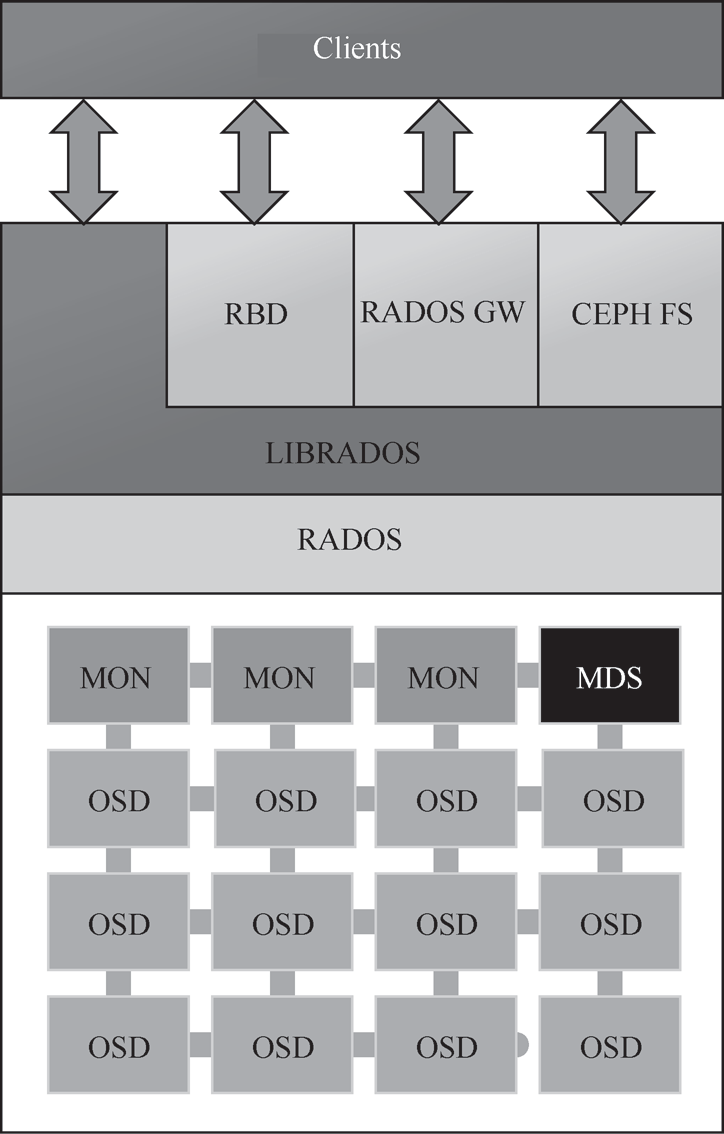
图 1-9展示了 Ceph 存储系统的核心组件。
(1) Mon服务
Mon为 Monitor的缩写,Ceph的 Monitor服务维护存储集群状态的各种图表,包括:
◆ 监视器图(MonitorMap),记录所有Monitor节点的信息,如集群 ID、主机名、IP和端口等。
◆ OSD图(OSDMap), 记 录CephPool的 PoolID、名称、类型、副本、PGP配置,以及 OSD的数量、状态、最小清理间隔、OSD所在主机信息等。
◆ 归置组图(PGMap),记录当前的PG版本、时间戳、空间使用比例以及每个PG 的基本信息。
◆ CRUSH图(CRUSHMap,CRUSH为ControlledReplicationUnderScalableHashing的 缩写),记录集群存储设备信息、故障层次结构以及存储数据时故障域规则信息。
这些图表(Map)保存着集群发生在Monitor、PG和 CRUSH 上的每一次状态变更,这些状态变更的历史信息版本称为epoch,可以用于集群的数据定位以及集群的数据恢复。
Monitor1通过集群部署的方式保证其自身服务的可用性,由于遵循Pasox 协议来进行leader选举,Monitor 集群通常为奇数个节点部署,且部署节点数量不小于 3个。
(2) OSD服务
OSD为 ObjectStorageDevice的缩写,Ceph的 OSD服务功能是存储数据、管理磁盘,以实现真正的数据读写,OSD 服务处理数据的复制、恢复、回填、再均衡等任务,并通过检查其他 OSD守护进程的心跳来向 CephMonitor服务提供监控信息。
通常一个磁盘对应一个OSD 服务,但使用高性能存储介质时,也可以将存储介质进行分区处理,启动多个 OSD 守护进程进行磁盘空间管理(每个 OSD守护进程对应一个磁盘分区)。
(3) MDS服务
MDS为MetadataServer 的缩写,Ceph的MDS服务为Ceph文件系统存储元数据,即Ceph的块设备场景和对象存储场景不使用 MDS服务。Ceph的 MDS服务主要负责CephFS 集群中文件和目录的管理,记录数据的属性,如文件存储位置、大小、存储时间等,同时负责文件查找、文件记录、存储位置记录、访问授权等,允许 Ceph的 POSIX文件系统用户可以在不对 Ceph存储集群造成负担的前提下,执行诸如文件的ls、find等基本命令。MDS 通过主备部署的方式保证其自身服务的可用性,进程可以被配置为活跃或者被动状态,活跃的 MDS为主 MDS,其他的 MDS处于备用状态,当主 MDS 节点故障时,备用MDS节点会接管其工作并被提升为主节点。
(4) RADOS
RADOS为 ReliableAutonomicDistributedObjectStore 的缩写,意为可靠、自主的分布式对象存储,从组件构成图中可见,RADOS由上述 3种服务(Mon、OSD、MDS)构成,其本质为一套分布式数据存储系统,即 RADOS 本身也是一套分布式存储集群。在 Ceph存储中所有的数据都以对象形式存在,RADOS负责保存这些对象,RADOS层可以确保对象数据始终保持一致性。从这个意义上讲,Ceph存储系统可以认为是在 RADOS对象存储系统之上的二次封装。
1Ceph的 Luminous版本推出了 MGR(ManagerDaemon)组件,该组件的主要作用是分担和扩展 Monitor服务的部分功能,减轻Monitor的负担,它从 Monitor 服务中拆解出了部分对外暴露的集群状态指标,对外提供集群状态的统一查询入口。
RADOS依据 Ceph 的需求进行设计,能够在动态变化和异构存储设备之上提供一种稳定、可扩展、高性能的单一逻辑对象存储接口,并能够实现节点的自适应和自管理。
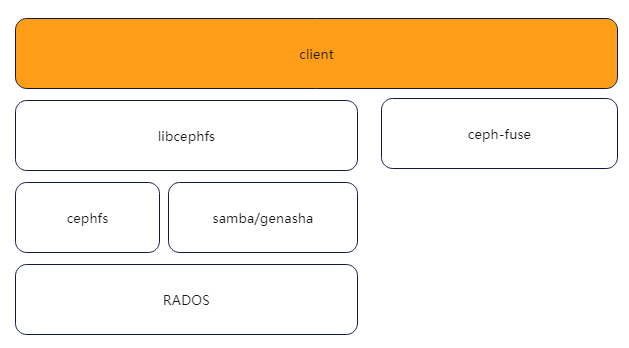
(5) librados
librados库为PHP、Ruby、Java、Python、C、C++ 等语言提供了便捷的访问RADOS接口的方式,即 librados允许用户不通过 RESTfulAPI、blockAPI或者 POSIX文件系统接口访问 Ceph存储集群。
libradosAPI 可以访问 Ceph 存储集群的 Mon、OSD 服务。
(6) RBD
RBD是 RADOSBlockDevice的缩写,Ceph的RBD 接口可提供可靠的分布式、高性能块存储逻辑卷(Volume)给客户端使用。RBD 块设备可以类似于本地磁盘一样被操作系统挂载,具备快照、克隆、动态扩容、多副本和一致性等特性,写入RBD 设备的数据以条带化的方式存储在 Ceph集群的多个 OSD中。
(7) RGW
RGW是 RADOSGateway的缩写,Ceph的 RGW接口提供对象存储服务,RGW基于 librados接口实现了 FastCGI服务封装,它允许应用程序和 Ceph对象存储建立连接,RGW提供了与AmazonS3和 OpenStackSwift兼容的RestfulAPI。对象存储适用于图片、音视频等文件的上传与下载,可以设置相应的文件访问权限以及数据生命周期。
(8) CephFS
CephFS是 CephFileSystem的缩写,CephFS接口可提供与 POSIX兼容的文件系统,用户能够对 Ceph 存储集群上的文件进行访问。CephFS是 Ceph集群最早支持的客户端,但对比 RBD和 RGW,它又是Ceph最晚满足productionready的一个功能。
回到 Ceph 组件示意图,客户端访问存储集群的流程可总结如下。
客户端在启动后首先通过 RBD/RGW/CephFS接口进入(也可基于 librados自行适配业务进行接口开发),从Mon服务拉取存储资源布局信息(集群运行图),然后根据该布局信息和写入数据的名称等信息计算出期望数据的存储位置(包含具体的物理服务器信息和磁盘信息),然后和该位置信息对应的OSD服务直接通信,进行数据的读取或写入。
Ceph是目前应用最广泛的开源分布式存储系统, 它已经成为 Linux操作系统和OpenStack开源云计算基础设施的“标配”,并得到了众多厂商的支持。Ceph可以同时提供对象存储、块存储和文件系统存储3 种不同类型的存储服务,是一套名副其实的统一分布式存储系统,总结其特点如下。
◆ 高性能
Ceph 存储系统摒弃了集中式存储元数据寻址的方案,转而采用私有的 CRUSH算法,元数据分布更加均衡,系统 I/O操作并行度更高。
◆ 高可用性
Ceph 存储系统考虑了容灾域的隔离,能够实现多种数据放置策略规则,例如数据副本跨机房、机架感知冗余等,提升了数据的安全性;同时,Ceph存储系统中数据副本数可以灵活控制,坚持数据的强一致性原则,系统没有单点故障,存储集群可进行修复自愈、自动管理,存储服务可用性高。
◆ 高可扩展性
Ceph 存储系统采用对称结构、全分布式设计,集群无中心节点,扩展灵活,能够支持上千台存储节点的规模,支持PB级的数据存储需求;且随着服务器节点的不断加入,存储系统的容量和 I/O处理能力可获得线性增长,拥有强大的scaleout能力。
◆ 接口及特性丰富
Ceph 存储系统支持块存储、文件存储、对象存储3种访问类型,且 3 个方向均已生产就绪:对象存储方面,Ceph支持Swift和 S3的API接口;块存储方面,除私有协议挂载外,Ceph社区也在积极推动 iSCSI方案,RBD设备支持精简配置、快照、克隆等特性;文件系统存储方面,Ceph支持 POSIX 接口,支持快照特性。同时,Ceph通过 librados可实现访问接口自定义,支持多种语言进行驱动开发。
2. 一致性 Hash模式
Swift是无中心分布式存储系统(一致性 Hash)的典型代表。Swift由Rackspace开发,用来为云计算提供高可扩展性的对象存储集群。与 Ceph通过自定义算法获得数据分布位置的方式不同,Swift通过一致性 Hash的方式获得数据存储位置。一致性Hash的方式就是将设备在逻辑上构建成一个Hash环,然后根据数据名称计算出的 Hash值映射到Hash 环的某个位置,从而实现数据的定位。
Swift中存在两种映射关系,对于一个文件,通过 Hash算法(MD5)找到对应的虚节点(一对一的映射关系),虚节点再通过映射关系(Hash环文件中的二维数组)找到对应的设备(多对多的映射关系),这样就完成一个文件存储在设备上的映射。
图 1-10展示了 Swift分布式存储系统的架构。
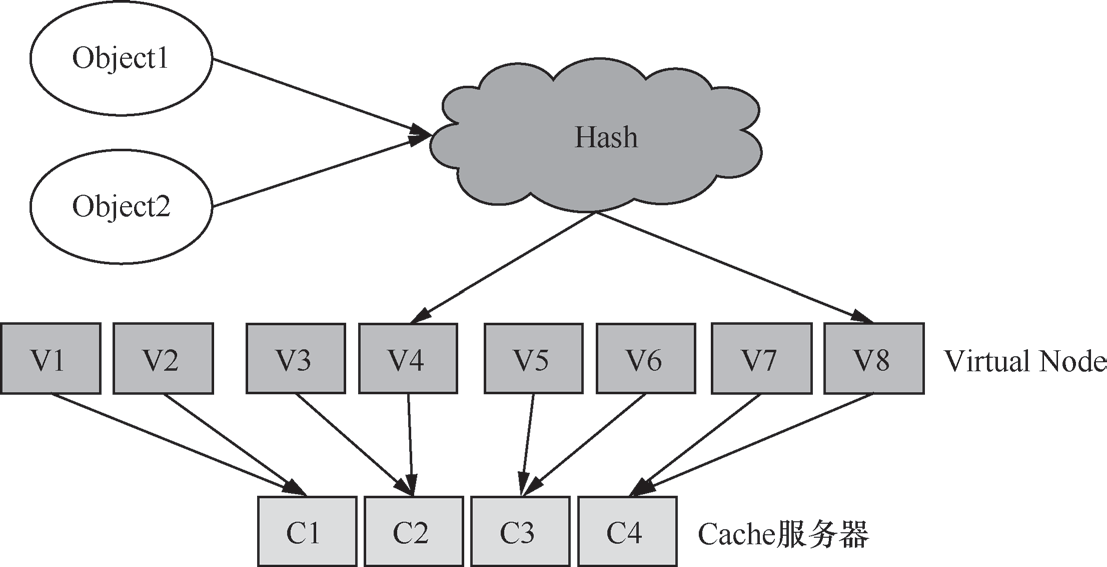
图 1-10Swft分布式存储系统架构
Swift主要面向的对象存储应用场景,和 Ceph 提供的对象存储服务类似,主要用于解决非结构化数据的存储问题。
Swift存储系统和 Ceph 存储系统主要区别如下。
◆ Swift仅提供对象存储服务能力,而Ceph在设计之初就比 Swift开放,除支持对象存储场景外,还支持块存储、文件存储使用场景;
◆ 数据一致性方面,Swift 提供数据最终一致性,在处理海量数据的效率上更占优势,主要面向对数据一致性要求不高,但对数据处理效率要求比较高的对象存储业务,而Ceph存储系统始终强调数据的强一致性,更适用于对数据存储安全性要求较高的场景;
◆ 二者在应用于对象存储多数据中心场景下时,Swift 集群支持跨地域部署,允许数据先在本地写入(数据本地写入完成后就返回写入成功),然后基于一致性设计在一段时间里复制到远程地域,而Ceph 存储系统则通常需要通过Master-Slave 模型部署两套集群,从Master到 Slave 进行数据异步复制,所以在多于两个地域时,基础架构上的负载分布会很不均衡 1。
部署实例
通过该实例,加深各个模块的作用和工作原理:
《深度学习后端分布式存储ceph技术建议书》
https://www.renrendoc.com/paper/102322127.html
MinIO和ceph
(http://slack.minio.org.cn/question/5)
之前一直使用MongoDB的GirdFS存储文件,在并发处理能力和扩容能力上没有遇到问题。但是使用总是不够便利,各种功能都需要自己开发。存储上是wt文件,无法直接识别。
所以,希望找一款替代产品。目前开源的文件存储系统比较多,比较了多个,我们的要求是要支持S3存储,最终选定了minio。
从对比中,目前文件存储在ceph和minio中进行比较选型
ceph优缺点
优点
- 成熟
红帽继子,ceph创始人已经加入红帽,国内有所谓的ceph中国社区,私人机构,不活跃,文档有滞后,而且没有更新的迹象。
从git上提交者来看,中国有几家公司的程序员在提交代码,星辰天合,easystack, 腾讯、阿里基于ceph在做云存储,但是在开源社区中不活跃,阿里一位叫liupan的有参与
- 功能强大
- 支持数千节点
- 支持动态增加节点,自动平衡数据分布。(TODO,需要多长时间,add node时是否可以不间断运行)
- 可配置性强,可针对不同场景进行调优
缺点
学习成本高,安装运维复杂。(或者说这个不是ceph的缺点,是我水平不行)
minio优缺点
优点
学习成本低,安装运维简单,开箱即用
目前minio论坛推广给力,有问必答
有java客户端、js客户端
缺点
社区不够成熟,业界参考资料较少
不支持动态增加节点,minio创始人的设计理念就是动态增加节点太复杂,后续会采用其它方案来支持扩容。
其缺点是目前不支持动态在线扩容。我们业务的使用量不会很大,所以这个问题先不考虑。
当然是用MinIO呀,MinIO的维护特别简单,并且性能和扩展也比Ceph要简单。
Ceph 维护起来多麻烦呀。运维成本太高了。
公司运维每年不投个几千万,ceph玩都别玩。
并且Ceph这玩意是超大型公司才玩玩的。
ceph和GFS(GlusterFS)、MFS、Ceph、Lustre

分布式文件系统MFS、Ceph、GlusterFS、Lustre的比较(资料比较老2011年,仅供参考):
分布式文件系统MFS、Ceph、GlusterFS、Lustre的比较_存储实验室-CSDN博客_ceph lustre

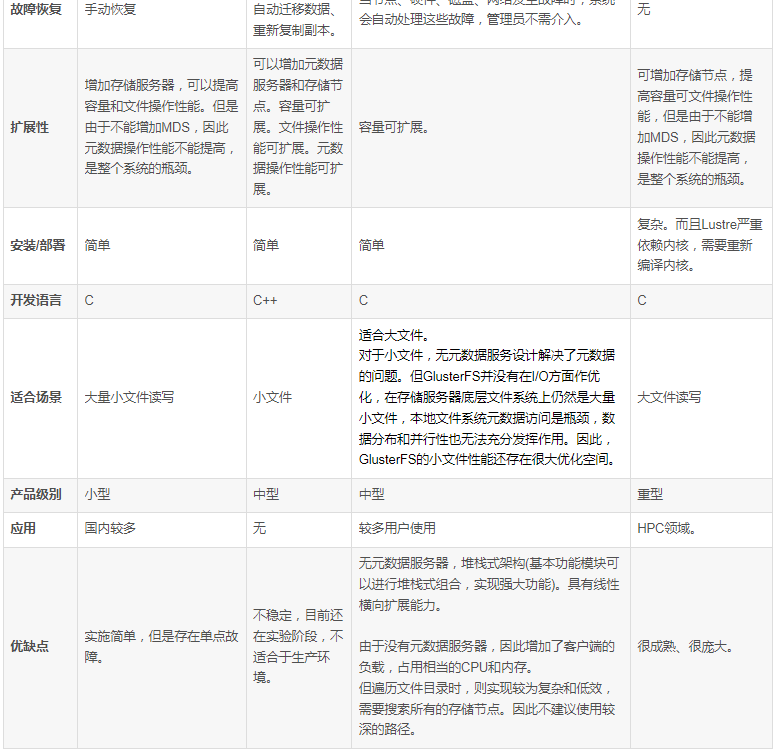
《GlusterFS与Ceph 性能测试报告》:
数据寻址的方式基本被归结为两大类,分别 是查表型寻址方式(有中心的非对称式架构)与计算型寻址方式(无中心的对称式架构)
GFS(查表型寻址方式)将所有元数据存储于所谓的 Master节点上,Master 节点应对前端对数据路由的查询和更新操作,是全局寻址信息的权威记录,这样的设计称为“中心化索引”,中心化索引的架构具备简单且高效的特性,基于数据、索引分离的设计理念使得 Master 节点不会成为整个系统 I/O操作的瓶颈,而面向大文件的设计场景也使得元数据的规模不会非常大, 有效地规避了拓展性问题。GFS 这类系统架构并不完美,在应对海量小文件的场景下会产生诸多问题。当然,GFS通过层级存储(LayeringStorage)的设计依靠 BigTable缓解了这一问题,但在海量小文件存储场景下,中心化索引面临的性能问题和架构劣势仍会逐步凸显出来。
《存储漫谈Ceph原理与实践》第二章Ceph 架构2.1数据寻址方案https://developer.aliyun.com/article/794621?spm=a2c6h.13262185.profile.31.12796645o1ffkc
GFS 学习:https://www.cnblogs.com/zhijiyiyu/p/15339674.html
ceph和hadoop

ceph 文档
《从零开始学Ceph(Ceph From Scratch)》https://www.bookstack.cn/books/ceph_from_scratch
《Ceph v10.0 中文文档》https://www.bookstack.cn/books/ceph-10-zh
《Ceph v15.2 Document》https://www.bookstack.cn/books/ceph-15.2-en
《Ceph 运维手册》https://www.bookstack.cn/books/ceph-handbook