

【RDMA】qp数量和RDMA性能(节选)|连接数
目录
作者:bandaoyu,原始连接:https://blog.csdn.net/bandaoyu/article/details/122947096?spm=1001.2014.3001.5502
QP数量上升性能下降
https://icnp21.cs.ucr.edu/papers/icnp21camera-paper30.pdf
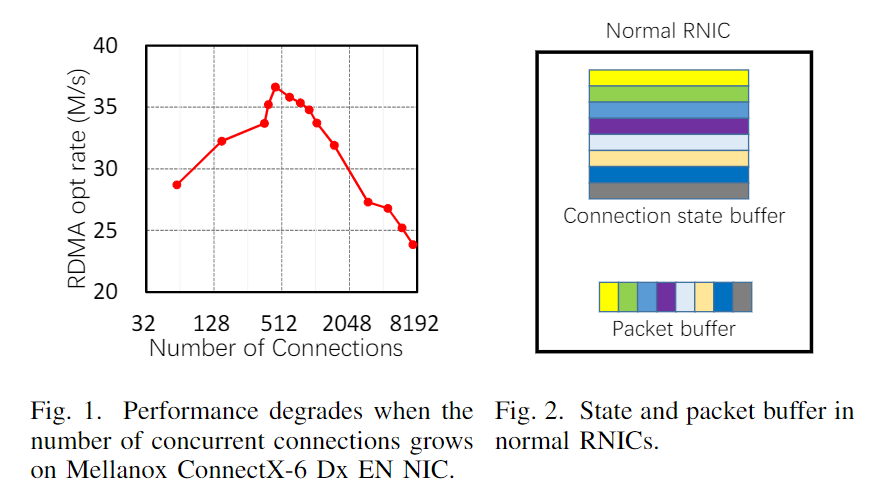
在现代云数据中心中,大规模分布式应用通常构建在许多机器上,需要使用大量并发连接进行频繁的网络通信[4]–[6]。但是,RDMA的性能会随着连接数的增加而降低。我们的测试台测量(图1)表明,即使是最新的RNIC(NIC=Network Interface Card ,网络接口卡、网卡,RNIC即 RDMA Network Interface Card)要保持峰值性能最多能支持450个并发连接,(详细设置见§II-B)
从本质上讲,RDMA可扩展性以上的问题是CPU减负的副作用。为了在不涉及主机CPU的情况下完成网络传输和数据DMA,RNIC必须维护一系列与连接相关的状态(DMA相关、网络相关和安全相关)。因此,当并发连接过多时,RNIC有限的板载内存会被耗尽,它必须频繁地通过慢速PCIe总线从主机内存获取连接状态,这会严重影响性能。
即使认识到这个问题,以前基于软件的方案不论是缓解方案(例如,使用大内存页面 [7] 或连接分组 [8]),或解决方案(例如,使用不可靠的数据报 [9]),始终无法解决 RNIC 可伸缩性问题。
在本文中,我们问,我们能否完全消除RNIC的可伸缩性约束?为了解决这个问题,我们提出了无状态RNIC(StaR)。特别是,需要高并发性的应用程序通常具有非对称通信模式,即网络通信中只有一方(称为服务器)有许多连接,而另一方(称为客户端)只有少数[5],[9]–[11]。观察到这一点,StaR的关键见解是将所有连接状态移动到客户端,并在服务器RNIC上保持零连接相关状态。具体来说,客户端RNIC跟踪服务器的所有状态,并引导服务器的RNIC完成其所有数据传输,包括接收或发送数据包、通知应用程序和生成ACK包等。。因此,由于RNIC内存不再限制其可扩展性,StaR可以显著提高服务器端具有大量扇入/扇出功能的应用程序的性能。
虽然直觉很简单,但在实现上面临两大挑战:
1)如何在NIC上无状态的情况下完成RDMA功能?
2) 如何确保NIC上无状态的安全性?
我们根据以下见解应对StaR中的上述挑战:
•在数据包中携带必要的状态。具体来说,客户机跟踪服务器的传输状态,并生成向服务器传送必要状态的数据包。
然后,服务器的无状态RNIC依赖于接收到的数据包中携带的连接状态来完成其RDMA处理。
•确保客户的安全。由于StaR针对的是数据中心场景,即所有物理机器都由一家运营商管理,因此我们可以通过控制客户端NIC发送的数据包来确保安全性。
特别是,我们向每个NIC添加一个安全模块,它实际上是一个检查所有出站数据包的匹配操作表,只允许合法数据包进入服务器的无状态RNIC。
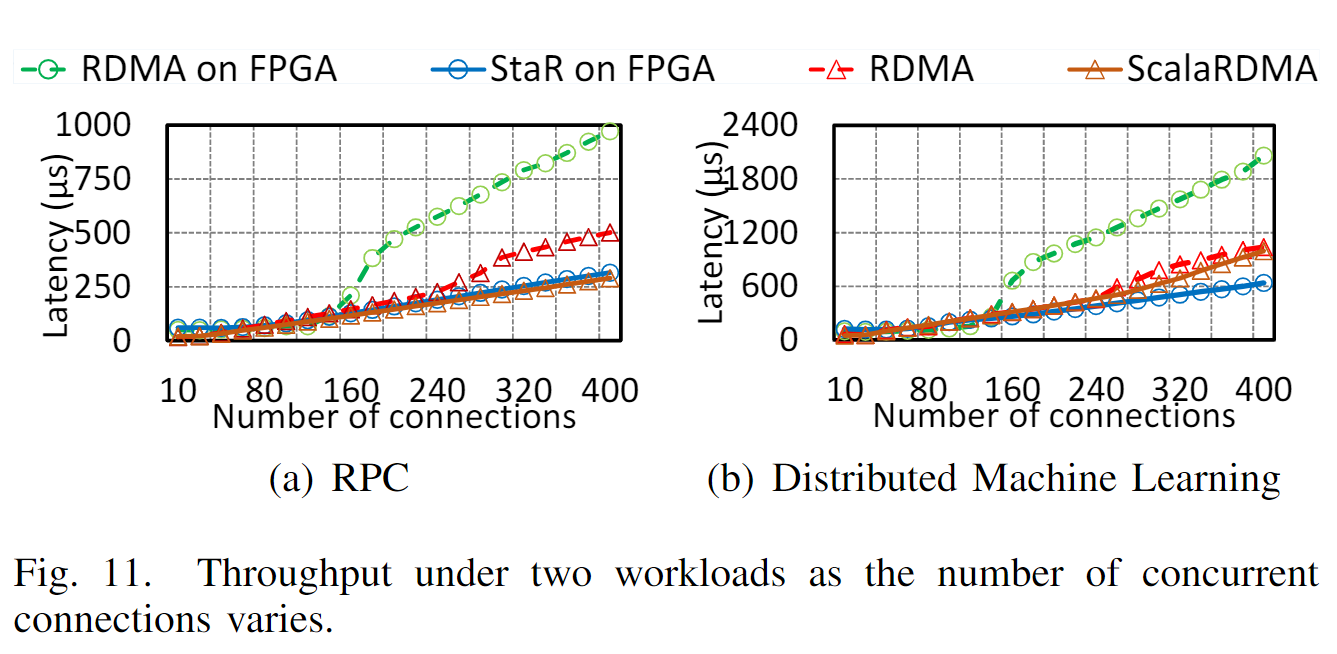
我们已经在基于FPGA的10Gbps NIC原型上实现了StaR,并构建了一个由9台机器组成的测试平台,每台机器都配备了一个StaR RNIC。测试台评估结果表明,随着连接数的增加,StaR能够保持最大带宽,与原始RNIC和最新基于软件的应用相比,上层应用的性能提高了4.14倍和1.35倍
……
B.RDMA的伸缩性较差
1) 实验结果:之前的许多工作已经测量了RNIC[7]–[9],[18],[19]中的可伸缩性问题。
然而,他们的结果基于几年前发布的RNIC,目前尚不清楚此类问题是否仍然存在,以及对当前高端RNIC的严重程度。因此,我们进行以下实验,以评估Mellanox ConnectX-6(CX6)Dx EN上的RDMA可伸缩性NIC,这是最新的RNIC(于2019年发布,写这篇论文的时间。)
具体来说,我们使用带有100Gbps端口的CX6 NIC,通过华为100Gbps交换机,将1台服务器计算机与3台客户端计算机(多个客户端以避免客户端NIC出现瓶颈)连接起来。服务器同时发出RDMA读取请求,通过多个RC连接从所有三个客户端获取32字节的数据,在每个连接上保持一个外部读取3。为了避免CPU瓶颈(双插槽Intel Xeon E5-2650 CPU),我们在服务器上使用多个线程以足够快的速度发出读取请求。为了评估RNIC的可伸缩性,我们改变并发连接的数量,并测量服务器的总体吞吐量(每秒完成的读取操作)。图1显示了结果。
当并发性较低时,总体吞吐量会随着并发连接数量的增加而增加,因为在连接上有更多的外部读取请求。然而,当并发连接的数量超过450个时,总吞吐量开始快速下降,并且低于450个的。
当连接数超过3000个时,性能峰值的70%,而CPU利用率仍然很低。正如我们所看到的,尽管CX6比以前的CX5或CX4 NIC具有更高的端口速度和更多的片上资源,但RNIC的可扩展性问题仍然存在。
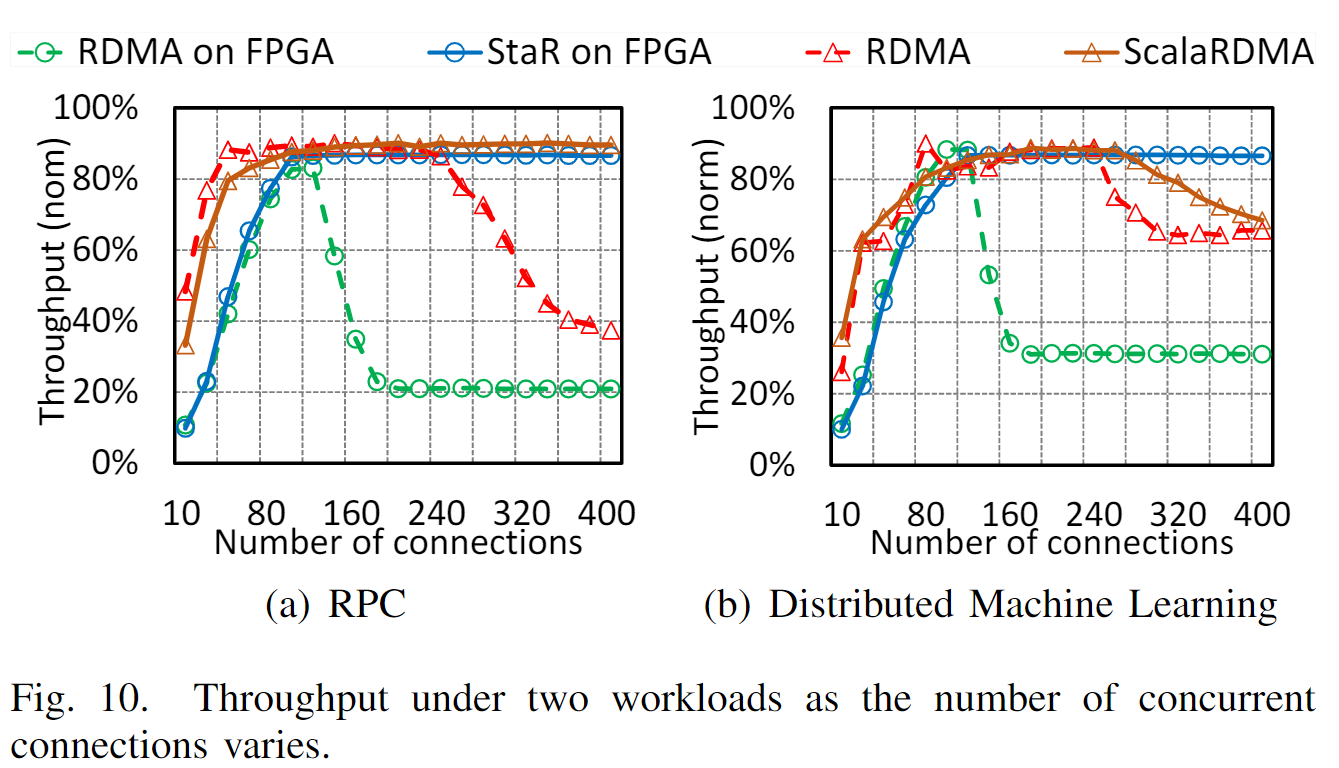
2) 基本问题:由于成本问题,RNIC片上存储器非常小,通常仅用作部分连接的缓存,所有连接的全部状态都存储在主机存储器(4)中。
当并发性很高,在处理 状态 未存储在NIC上的连接时,NIC必须暂停,并通过慢速PCIe总线从主机内存获取状态,这会严重影响性能。
如图2所示,

RNIC上通常有一个小的数据包缓冲区,用于临时保存数据包,从而分摊每个数据包的硬件处理延迟,以便RNIC可以饱和带宽。当带宽延迟积(BDP)增长时,它需要一个更大的数据包缓冲区来容纳更多的数据包。然而,数据包可能属于不同的连接,需要不同的连接相关状态来处理。因此,保存连接状态的缓冲空间必须更大。在高带宽网络中处理许多小RDMA请求时,这个问题变得更加重要,因为数据包缓冲区中会有大量小数据包,这可能需要许多连接状态,很容易导致NIC内存上的状态丢失。此外,高并发下的连接状态缓存未命中将导致数据包处理的临时暂停(来自PCIe的等待状态),这反过来需要更大的数据包缓冲区来容纳传入的数据包(从而进一步加重NIC内存的负担),否则,如果没有足够的内存,NIC必须暂停管道并停止接收数据包,影响性能。
C 现有的解决方案和限制
现有的解决方案主要集中在限制上层软件的使用,从而避免底层RNIC的可扩展性问题。具体而言,它们可以分为两类:
•通过使用软件中间件来控制应用程序通信模式,避免生成过多连接[8]、[20]、[21]。他们试图安排多个连接之间的通信需求,并有目的地在特定时间段内仅为RNIC上的部分连接提供服务,从而避免RNIC上的高并发性。例如,ScalaRDMA[8] 《Scalable RDMA RPC on
Reliable Connection with Efficient Resource Sharing》将连接分为几个组,通过阻止其他组即将启动操作的连接,一次只允许一个组运行,从而减轻了底层RNIC的负担。然而,使用中间件会将开销带回CPU,这与RDMA的原理相反。此外,以下中间件中连接之间的不可知调度可能会损害上层应用程序的性能,因为不同的连接之间可能存在依赖关系。例如,在具有服务器-工作者结构的分布式机器学习中,下一轮参数分配只能在上一轮参数计算完成后开始(假设使用最广泛的同步模式)。这要求服务器节点及时分发参数并接收所有响应。然而,如果在中间件中调度RDMA连接与此应用程序要求无关,则性能将受到显著影响,尽管RNIC并发性没有那么高(请参见§V中的结果)。
•在不可靠模式下使用RNIC,而不是可靠模式[9]、[22]、[23]。尽管RNIC不需要在不可靠模式下保持连接相关状态,因此没有可伸缩性问题,但它可能会导致两方面的问题:
1)当网络有损时(即使在精心设计的数据中心[12]),由于缺乏传输可靠性,它的性能可能非常低,
2)或者它可能会产生非常高的CPU成本,因为它必须在软件中处理传输可靠性[24]
……
FPGA 改造RDMA 后的结果:

QP数量上升性能下降的原因
《RDMA性能优化经验浅谈(一)》https://zhuanlan.zhihu.com/p/522332998
首先,当我们创建了QP之后,系统是需要保存状态数据的,比如QP的metadata,拥塞控制状态等等,除去QP中的WQE、MTT、MPT,一个QP大约对应375B的状态数据。这在以前RNIC的SRAM比较小的时候会是一个比较重的存储负担,所以以前的RDMA工作会有QP Sharing的研究,就是不同的处理线程去共用QP来减少meta data的存储压力,但是这会带来一定的性能的损失[1]。现在新的RNIC的SRAM已经比较大了,Mellanox的CX4、CX5系列的网卡的SRAM大约2MB,所以现在新网卡上,大家还是比较少去关注QP带来的存储开销,除非你要创建几千个,几万个QP。
当待请求的数据地址在RNIC SRAM中的MTT/MPT没有命中的时候,RNIC需要通过PCIe去在内存中的MTT和MPT进行查找,这是一个耗时的操作。尤其是当我们需要 high fan-out、fine-grained的数据访问时,这个开销会尤为的明显。这或许就是性能下降的原因


