
【ceph】后端存储ObjectStore|BlueStore
目录
ObjectStore简介
object store是Ceph OSD的一部分,它完毕实际的数据存储。当前有三种不同的object store可用:
- FileStore: 文件系统+日志后备的存储
- KeyValueStore: 基于KV数据库(如:RocksDB、 LevelDB、memdb等)
- MemStore: 以内存作为存储(译注:全部数据全部位于内存中的STL::Map或者bufferlist)
- BlueStore,或称NewStore
相关文档
代码
object store源代码位于Ceph源代码文件夹下的os子文件夹。为方便:ceph github repository。以下的描写叙述基于Ceph commit-ish 6f8b54c from 2015-01-13。
OSD存储引擎实现;Ceph基础组件RADOS是强一致、对象存储系统,其OSD底层支持的存储引擎如下图所示:
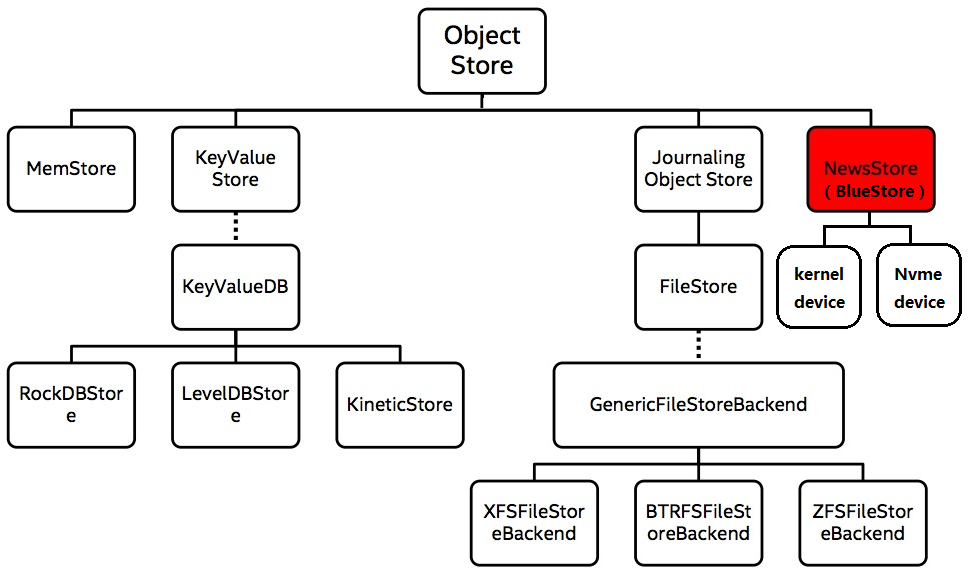
图:https://www.cnblogs.com/wuhuiyuan/p/ceph-newstore-intro.html
其中,ObjectStore层封装了下层存储引擎的所有IO操作,向上层提供对象(object)、事务(Transaction)语义的接口,MemStore为基于内存的实现;KeyValueStore主要基于KV数据库(如leveldb, rocksdb等)实现接口功能,事务实现也基于KV数据库自身;FileStore是Ceph目前默认的存储引擎(也是目前使用最多的存储引擎),其事务实现基于Journal机制(Journal文件或块设备);除了支持事务特性(consistency、atomic等)外,Journal还可将多个小IO写合并为顺序写Journal,以提升性能。
CEPH OBJECTSTORE API介绍
本文由 Ceph中国社区-Thomas翻译,陈晓熹校稿 。
英文出处:THE CEPH OBJECTSTORE API 欢迎加入 翻译小组
ObjectStore API
抽象类ObjectStore是OSD实现存储訪问的主要API。
这是一套类文件系统API。可是囊括了将状态转化为事务的操作。存储的是对象,而不是文件。
一个对象包括:
- 字节数据 - 相似于文件系统中的文件内容
- 扩展属性 - 相似于文件系统中文件的扩展属性。是键值对集合。
- omap - 在概念上与扩展属性相似,但有着不同的地址空间大小及訪问模式。
一个对象由下述两个id标示:
- 集合id -
coll_tcid(一个集合就是一组对象) - 对象id -
ghobject_toid
操作
以下不是一个完整的列表;仅仅是给你一个印象。注意:有些操作仅仅对事务可用。
事务操作:以事务作为參数
apply_transactionqueue_transactions
常规文件系统操作:
mountumountmkfsmkjournalstatfsneed_journalsyncflushsnapshot
对象操作:以coll_t cid和ghobject_t oid为參数
existsstatreadfiemapgetattrgetattrs
集合操作:以coll_t cid为參数
collection_getattrcollection_emptycollection_listlist_collectionscollection_existscollections_getattrs
Omap操作:
omap_getomap_get_headeromap_get_keysomap_get_valuesomap_check_keys
延伸阅读
- ObjectStore.h - 凝视部分
事务
定义:事务是原始的变更操作序列。类定义ObjectStore::Transaction。
支持的操作(摘自ObjectStore.h):
class Transaction {
public:
enum {
OP_NOP = 0,
OP_TOUCH = 9, // cid, oid
OP_WRITE = 10, // cid, oid, offset, len, bl
OP_ZERO = 11, // cid, oid, offset, len
OP_TRUNCATE = 12, // cid, oid, len
OP_REMOVE = 13, // cid, oid
OP_SETATTR = 14, // cid, oid, attrname, bl
OP_SETATTRS = 15, // cid, oid, attrset
OP_RMATTR = 16, // cid, oid, attrname
OP_CLONE = 17, // cid, oid, newoid
OP_CLONERANGE = 18, // cid, oid, newoid, offset, len
OP_CLONERANGE2 = 30, // cid, oid, newoid, srcoff, len, dstoff
OP_TRIMCACHE = 19, // cid, oid, offset, len **DEPRECATED**
OP_MKCOLL = 20, // cid
OP_RMCOLL = 21, // cid
OP_COLL_ADD = 22, // cid, oldcid, oid
OP_COLL_REMOVE = 23, // cid, oid
OP_COLL_SETATTR = 24, // cid, attrname, bl
OP_COLL_RMATTR = 25, // cid, attrname
OP_COLL_SETATTRS = 26, // cid, attrset
OP_COLL_MOVE = 8, // newcid, oldcid, oid
OP_STARTSYNC = 27, // start a sync
OP_RMATTRS = 28, // cid, oid
OP_COLL_RENAME = 29, // cid, newcid
OP_OMAP_CLEAR = 31, // cid
OP_OMAP_SETKEYS = 32, // cid, attrset
OP_OMAP_RMKEYS = 33, // cid, keyset
OP_OMAP_SETHEADER = 34, // cid, header
OP_SPLIT_COLLECTION = 35, // cid, bits, destination
OP_SPLIT_COLLECTION2 = 36, /* cid, bits, destination
doesn't create the destination */
OP_OMAP_RMKEYRANGE = 37, // cid, oid, firstkey, lastkey
OP_COLL_MOVE_RENAME = 38, // oldcid, oldoid, newcid, newoid
OP_SETALLOCHINT = 39, // cid, oid, object_size, write_size
OP_COLL_HINT = 40, // cid, type, bl
};
// ...
}
每个操作都在事务类中有一个相应的函数实现(如 OP_ZERO:zero(cid, oid off, len))
一个事务能够有例如以下三个回调:
on_appliedon_commiton_applied_sync
ObjectStore::Transaction对象主要用来发送来自OSD的操作序列。比如,OSD:mkfs运行下述操作来初始化meta集合:
ObjectStore::Transaction t;
t.create_collection(META_COLL);
t.write(META_COLL, OSD_SUPERBLOCK_POBJECT, 0, bl.length(), bl);
ret = store->apply_transaction(t);
ObjectStore::Transaction类还能从Buffer中反序列出操作序列(注:即从字节流重建Transcation对象)。日志重做机制就是使用这样的方式来重做事务(注:从日志中读取字节流重建出Transcation对象,再Apply这个对象)。
日志
日志对故障恢复非常重要。
基类ObjectStore没有实现日志功能。在子类JournalingObjectStore中加入了日志能力。
JournalingObjectStore中加入了例如以下方法:
- journal_start
- journal_stop
- journal_write_close
- journal_replay
更要的是:
- _op_journal_transactions - 加入事务到日志
- do_transactions - 应用日志的纯虚函数.
mount过程中的replay_journal中有一个调用样例。
实现
当前仅仅有一个Journal实现:
ObjectStore 实现
FileStore
因为KeyValueStore还处于实验阶段。而MemStore很多其它的还是一种參考/demo实现,FileStore成为眼下使用最广的一种实现。
FileStore实现了JournalingObjectStore类。相应地也就实现了ObjectStore类。该类既实现了ObjectStore::Transaction中的操作也实现了其它成员操作。
事务操作在_do_transaction中实现并分发给_$OPERATION方法完毕详细的工作。因为每个文件系统的特性不同,有些操作及特性检查方法被提取出来放到了抽象类FileStoreBackend中。一个与文件系统代码相关的特殊操作是:fiemap。
关于fiemap
fiemap同意你訪问文件的扩展数据。基本上,你请求Linux系统将指向文件数据区的索引返回给你。这对稀疏文件非常实用。Ceph FileStore在FileStore::_do_sparse_copy_range中使用了它。
延伸阅读:
FileStore后端
FileStore后端将大部分与文件系统相关的优化和生僻特性从FileStore的实现中抽象剥离。
假设底层的文件系统支持检查点,FileStore后备将使用文件系统的快照特性实现检查点。它还会运行特征检查,如检測是否支持fiemap。
全部的详细类都继承至共同的基类GenericFileStoreBackend。
特定文件系统的支持情况:
- ZFS - 用ZFS快照实现检查点
- XFS - 通过
set_alloc_hint设置XFS扩展大小 - Btrfs - 用Btrfs快照实现检查点。用COW实现高效的文件克隆
KeyValueStore
KeyValueStore是ObjectStore的一个适配类同一时候是KeyValueDB的一个详细子类。
KeyValueDB是KV数据库的一个通用接口类,在Ceph代码的其它地方也实用到它。适配器中最大的一部分操作是将使用集合id及对象id的类文件系统操作映射为扁平的KV接口。KV数据库中的键值不是通常的随意大小。因此。KV映射及键值的条带化都须要类StripObjectMap来完毕。它是KeyValueStore的一部分。
对象映射
GenericObjectMap是ghobject_t、coll_t到KV映射器的公共基类。它有点相似于KeyValueDB API,但并没有实现它。而是採用KeyValueDB代理实现。
StripObjectMap
StripObjectMap是KeyValueStore源代码的一部分而且实现了GenericObjectMap。它加入了条带和缓存功能。默认条带大小为4096字节(可配置)。
数据库后端
kinetic 希捷kinetic客户端github repository
leveldb Google LevelDB
rocksdb Facebook RocksDB
MemStore
MemStore将一切都存储在内存。在mount/umount时支持转储和恢复。为便于对象和组查找,它环绕着C++对象及哈希表来构建。
与它的实现相关的第一条提交记录是对ObjectStore 1的一种參数实现。该实现仍然是1,537 SLOC.
怎样加入新的ObjectStore
因为已经有处理文件系统和KV数据库的代码。写一个全新的ObjectStore不总是有必要。
一个粗略的指南告诉你从哪里開始:
想支持的是何种后端?
- KV数据库: 从
KeyValueDB的一个实现開始(注:參考LevelDBStore.cc/h 和 RocksDBStore.cc/h) - 文件系统:
- 看下
FileStoreBackend中的detect_features方法。文件系统是否须要特殊处理? - 是否支持快照?假设是,參考
BtrfsFileStoreBackend、ZFSFileStoreBackend
- 看下
- 全然不一样的实现?看看
MemStore(注:以了解须要实现哪些方法,以及这些方法最简单的的原型实现)。
Newstore(BlueStore)存储引擎的出现
FileStore最初只是针对机械盘进行设计的,并没有对固态硬盘的情况进行优化,而且写数据之前先写journal也带来了一倍的写放大。为了解决FileStore存在的问题,Ceph推出了BlueStore。BlueStore去掉了journal,通过直接管理裸设备的方式来减少文件系统的部分开销,并且也对固态硬盘进行了单独的优化。BlueStore架构如下图所示。

原文链接:https://blog.csdn.net/cyq6239075/article/details/107429211
在社区使用过程中,FileStore也暴露了若干问题:
(1)Journal机制使一次写请求在OSD端变为两次写操作(同步写Journal,异步写入object);
(2)对前一个问题,社区通常做法是使用专门设备(如SSD)用作Journal以解耦Journal和object写操作的相互影响,但持续循环写入Journal会降低SSD设备的使用寿命;
(3)写入的每个object都一一对应OSD本地文件系统的一个物理文件,对于大量小object存储场景,OSD端无法缓存本地所有文件的inode等元数据,使读写操作可能需要多次本地IO,系统性能差;
(4)object对应的本地物理文件的文件名,包含了object name、rados namespaces、object name hash、snapshot等信息,可能会超过本地文件系统对文件名长度的限制。
面对上述问题,新的存储引擎NewStore(又被称为KeyFileStore)出现,其关键数据结构如下图所示:
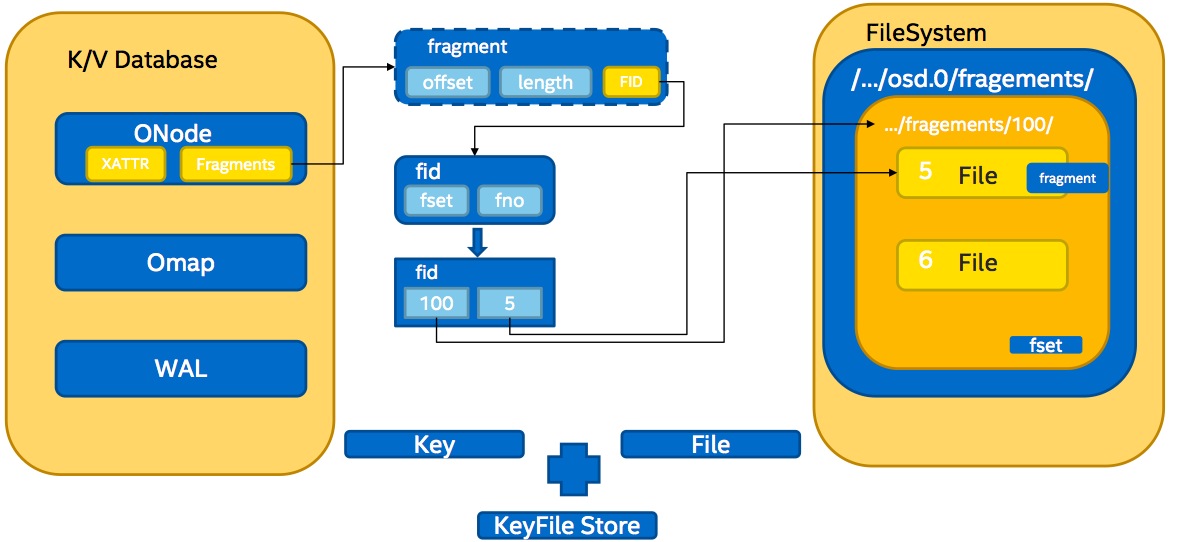
其主要特点有:
(1)解耦object与本地物理文件间的一一对应关系,通过索引结构(上图中ONode)在object和本地物理文件建立映射关系,并使用KV数据库存储索引数据;
(2)在保证事务特性的同时,对于object的create/append/overwrite(fragement aligned)操作,无需Journal支持;(3)对于unaligned update操作,先同步写入write-ahead-log(简称为WAL,使用KV存储),再异步写入相应的fragement文件;
(4)在KV数据库上层建立Onode数据cache以加速读取操作;
(5)单个object可以有多个fragement文件,多个object也可共存于一个fragement文件;
FileStore的上述问题,在NewStore结构中已基本解决;
NewStore还采用以下策略来减小WAL的性能开销:
(1)在update写入fragement文件后,立即将相应WAL从KVdb中删除(WAL已完成使命,无需保存);
(2)增大KVdb的write buffer,尽量将WAL保留在buffer中,避免不必要的dump;
(3)在write buffer数据dump到磁盘前,强制合并多个buffer数据,以避免不必要的dump。在初步的随机读写测试中,NewStore相对于FileStore有60%的性能提升;
本博客的上篇博文《海量小文件存储与Ceph实践》从元数据管理、本地存储引擎两个方面对海量小文件存储问题进行了分析描述,并通过object class接口层对FileStore存储结构做了改进优化,虽不如NewStore彻底,但也在很大程度上优化了小文件存储性能;NewStore则直接在存储引擎层进行重新设计实现,解耦object与本地物理文件间的对应关系,并允许多个object共存于一个fragement文件;但二者对小文件本地存储引擎优化的本质思想是相通的,即合并存储+索引;不过目前NewStore还在密集开发阶段,到线上部署还需要一段时间;相信以后随着NewStore引擎的逐步部署与成熟,海量小文件存储难题也不再是难题。
另外,基于object class接口层的改进优化方案相关代码实现已放到github,欢迎测试使用及批评指正。
参考:
图片和相关内容摘自2015年6月份Beijing Ceph Day《Newstore》讲稿
http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/23414/focus=23417
http://docs.ceph.com/docs/master/rados/configuration/journal-ref/
http://www.sebastien-han.fr/blog/2014/02/17/ceph-io-patterns-the-bad/
http://tracker.ceph.com/projects/ceph/wiki/Optimize_Newstore_for_massive_small_object_storage
http://www.cnblogs.com/wuhuiyuan/p/ceph-small-file-compound-storage.html
http://www.wzxue.com/ceph-filestore/
http://www.wzxue.com/ceph-keyvaluestore/
https://github.com/yxgup/ceph/tree/omap_indexed_compound
------------------------------------
http://www.cnblogs.com/wuhuiyuan/p/4907984.html
《大咖带你揭秘CEPH对象存储底层对象分布》 https://www.talkwithtrend.com/Article/242647


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}