

【ceph】Ceph 存储中 PGMap、OSDMap 和xxMap
目录
作者bandaoyu,随时更新本文链接:https://blog.csdn.net/bandaoyu/article/details/123097837
本文主要介绍ceph分布式存储架构中OSDMap和PGMap的原理及相关重要信息。
什么是OSDMap 和 PGMap
(摘自:https://blog.51cto.com/wendashuai/2511361,源文:Analizar Ceph: OSD, OSDMap y PG, PGMap - programador clic)
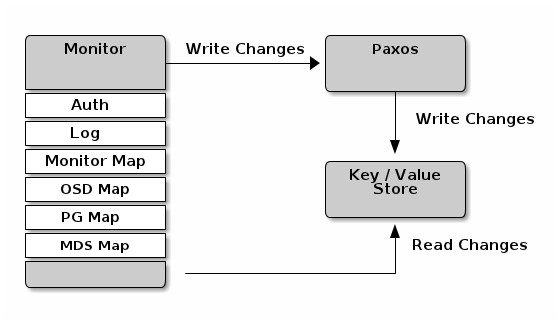
Monitor 作为Ceph的 Metada Server 维护了集群的信息,它包括了6个 Map,分别是 MONMap,OSDMap,PGMap,LogMap,AuthMap,MDSMap。其中 PGMap 和 OSDMap 是最重要的两张Map,本文会重点介绍。
OSDMap
OSDMap 是 Ceph 集群中所有 OSD 的信息,所有 OSD 状态的改变如进程退出,OSD的加入和退出或者OSD的权重的变化都会反映到这张 Map 上。这张 Map 不仅会被 Monitor 掌握,OSD 节点和 Client 也会从 Monitor 得到这张表,因此实际上我们需要处理所有 “Client” (包括 OSD,Monitor 和 Client)的 OSDMap 持有情况。
实际上,每个 “Client” 可能会具有不同版本的 OSDMap,当 Monitor 所掌握的权威 OSDMap 发生变化时,它并不会发送 OSDMap 给所有 “Client” ,而是需要那些感知到集群变化的 “Client” 会被 Push,比如一个新的 OSD 加入集群会导致一些 PG 的迁移,那么这些 PG 的 OSD 会得到通知。除此之外,Monitor 也会随机的挑选一些 OSD 发送 OSDMap。
那么如何让 OSDMap 慢慢传播呢?
比如 OSD.a, OSD.b得到了新的 OSDMap,那么 OSD.c 和 OSD.d 可能部分 PG 也会在 OSD.a, OSD.b 上,这时它们的通信就会附带上 OSDMap 的 epoch,如果版本较低,OSD.c 和 OSD.d 会主动向 Monitor pull OSDMap,而部分情况 OSD.a, OSD.b 也会主动向 OSD.c 和 OSD.d push 自己的 OSDMap (如果更新)。因此,OSDMap 会在接下来一段时间内慢慢在节点间普及。在集群空闲时,很有可能需要更长的时间完成新 Map的更新,但是这并不会影响 OSD 之间的状态一致性,因为OSD没有得到新的Map,所以它们不需要知晓新的OSDMap变更。
Ceph 通过管理多个版本的 OSDMap 来避免集群状态的同步,这使得 Ceph 丝毫不会畏惧在数千个 OSD 规模的节点变更,而导致集群可能出现的状态同步的问题。
新OSD启动OSDMap的变化
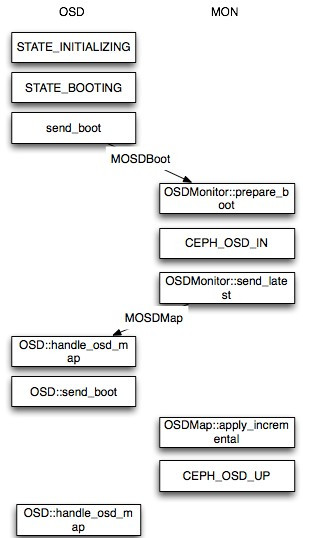
当一个新的 OSD 启动时,这时 Monitor 的最新 OSDMap 并没有该 OSD 的情况,因此该 OSD 会向 Monitor 申请加入,Monitor 在验证其信息后会将其加入 OSDMap 并标记为IN,并且将其放在 Pending Proposal 中会在下一次 Monitor “讨论”中提出,OSD 在得到 Monitor 的回复信息后发现自己仍然没在 OSDMap 中会继续尝试申请加入,接下来 Monitor 会发起一个 Proposal ,申请将这个 OSD 加入 OSDMap 并且标记为 UP 。然后按照 Paxos 的流程,从 proposal->accept->commit 到最后达成一致,OSD 最后成功加入 OSDMap 。当新的 OSD 获得最新 OSDMap 发现它已经在其中时。这时,OSD 才真正开始建立与其他OSD的连接,Monitor 接下来会开始给他分配PG。
OSD crash
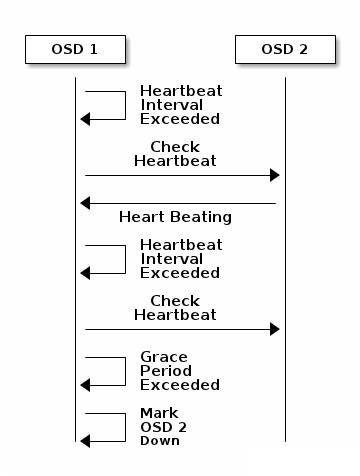
图C: OSD down过程
当一个 OSD 因为意外 crash 时,其他与该 OSD 保持 Heartbeat 的 OSD 都会发现该 OSD 无法连接,在汇报给 Monitor 后,该 OSD 会被临时性标记为 OUT,所有位于该 OSD 上的 Primary PG 都会将 Primary 角色交给其他 OSD(下面会解释)。
PG 和 PGMap
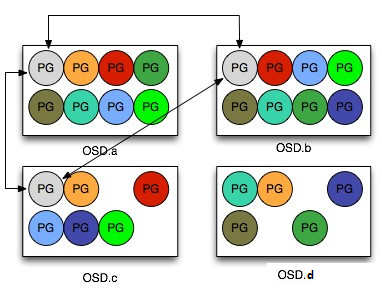
图D: PG和PGMap
PG(Placement Group)是 Ceph 中非常重要的概念,它可以看成是一致性哈希中的虚拟节点,维护了一部分数据并且是数据迁移和改变的最小单位。它在 Ceph 中承担着非常重要的角色,在一个 Pool 中存在一定数量的 PG (可动态增减),这些 PG 会被分布在多个 OSD ,分布规则可以通过 CRUSH RULE 来定义。
Monitor 维护了每个Pool中的所有 PG 信息,比如当副本数是三时,这个 PG 会分布在3个 OSD 中,其中有一个 OSD 角色会是 Primary ,另外两个 OSD 的角色会是 Replicated。Primary PG负责该 PG 的对象写操作,读操作可以从 Replicated PG获得。而 OSD 则只是 PG 的载体,每个 OSD 都会有一部分 PG 角色是 Primary,另一部分是 Replicated,当 OSD 发生故障时(意外 crash 或者存储设备损坏),Monitor 会将该 OSD 上的所有角色为 Primary 的 PG 的 Replicated 角色的 OSD 提升为 Primary PG,这个 OSD 所有的 PG 都会处于 Degraded 状态。然后等待管理员的下一步决策,所有的 Replicated 如果原来的 OSD 无法启动, OSD 会被踢出集群,这些 PG 会被 Monitor 根据 OSD 的情况分配到新的 OSD 上。
PG的peering过程
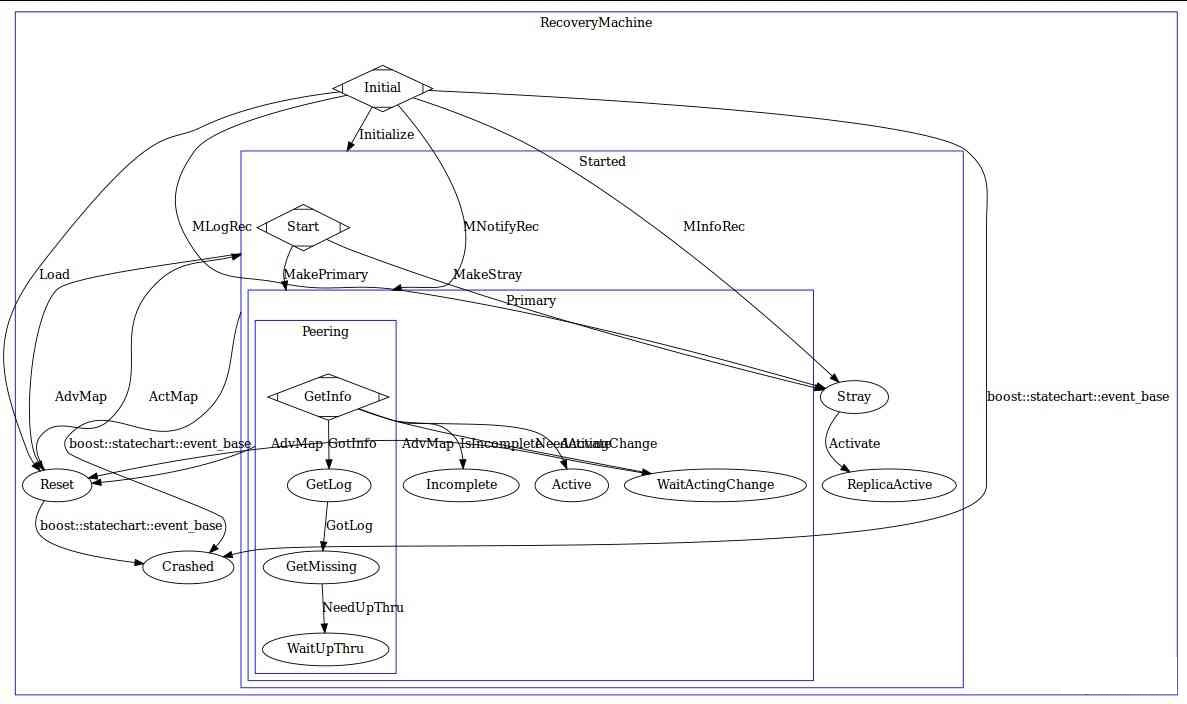
图E: PG的peering过程
在 Ceph 中,PG 存在多达十多种状态和数十种事件的状态机去处理 PG 可能面临的异常, Monitor 掌握了整个集群的 OSD 状态和 PG 状态,每个PG都是一部分 Object 的拥有者,维护 Object 的信息也每个 PG 的责任,Monitor 不会掌握 Object Level 的信息。因此每个PG都需要维护 PG 的状态来保证 Object 的一致性。但是每个 PG 的数据和相关故障恢复、迁移所必须的记录都是由每个 PG 自己维护,也就是存在于每个 PG 所在的 OSD 上。
PGMap 是由 Monitor 维护的所有 PG 的状态,每个 OSD 都会掌握自己所拥有的 PG 状态,PG 迁移需要 Monitor 作出决定然后反映到 PGMap 上,相关 OSD 会得到通知去改变其 PG 状态。在一个新的 OSD 启动并加入 OSDMap 后,Monitor 会通知这个OSD需要创建和维护的 PG ,当存在多个副本时,PG 的 Primary OSD 会主动与 Replicated 角色的 PG 通信并且沟通 PG 的状态,其中包括 PG 的最近历史记录。通常来说,新的 OSD 会得到其他 PG 的全部数据然后逐渐达成一致,或者 OSD 已经存在该 PG 信息,那么 Primary PG 会比较该 PG 的历史记录然后达成 PG 的信息的一致。这个过程称为 Peering ,它是一个由 Primary PG OSD 发起的“讨论”,多个同样掌握这个 PG 的 OSD 相互之间比较 PG 信息和历史来最终协商达成一致。
OSDMap 机制浅析
(摘自:https://cloud.tencent.com/developer/article/1664568)
OSDMap 机制是 Ceph 架构中非常重要的部分,PG 在 OSD 上的分布和监控由 OSDMap 机制执行。OSDMap 机制和 CRUSH 算法一起构成了 Ceph 分布式架构的基石。
OSDMap 机制主要包括如下3个方面:
1、Monitor 监控 OSDMap 数据,包括 Pool 集合,副本数,PG 数量,OSD 集合和 OSD 状态。
2、OSD 向 Monitor 汇报自身状态,以及监控和汇报 Peer OSD 的状态。
3、OSD 监控分配到其上的 PG , 包括新建 PG , 迁移 PG , 删除 PG 。
在整个 OSDMap 机制中,OSD充分信任 Monitor, 认为其维护的 OSDMap 数据绝对正确,OSD 对 PG 采取的所有动作都基于 OSDMap 数据,也就是说 Monitor 指挥 OSD 如何进行 PG 分布。
在 OSDMap 数据中 Pool 集合,副本数,PG 数量,OSD 集合这 4 项由运维人员来指定,虽然 OSD 的状态也可以由运维人员进行更改,但是实际运行的 Ceph 集群 A 中,从时间分布来看,运维人员对 Ceph 集群进行介入的时间占比很小,因此 OSD 的故障(OSD 状态)才是 Monitor 监控的主要目标。
OSD 故障监控由 Monitor 和 OSD 共同完成,在 Monitor 端,通过名为 OSDMonitor 的 PaxosService 线程实时的监控 OSD 发来的汇报数据(当然,也监控运维人员对 OSDMap 数据进行的操作)。在 OSD 端,运行一个 Tick 线程,一方面周期性的向 Monitor 汇报自身状态;另外一方面,OSD 针对 Peer OSD 进行 Heartbeat 监控,如果发现 Peer OSD 故障,及时向 Monitor 进行反馈。具体的 OSD 故障监控细节本文不做分析。
OSDMap 机制中的第1点和第2点比较容易理解,下面本文主要针对第3点进行详细分析。
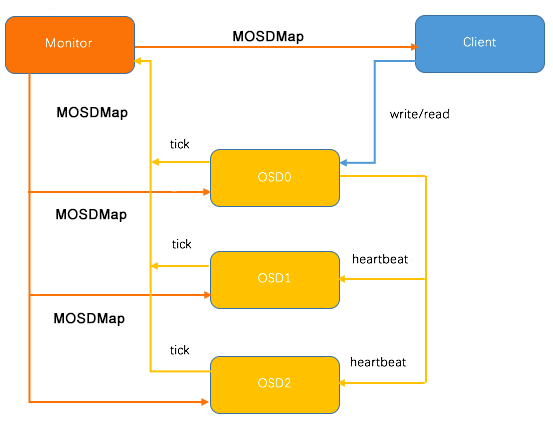
如上图所示,在3个 OSD 的 Ceph 集群中,Pool 的副本数为3,某个 PG 的 Primary OSD 为 OSD0, 当 Monitor 检测到 3 个 OSD 中的任何一个 OSD 故障,则发送最新的 OSDMap 数据到剩余的 2 个 OSD 上,通知其进行相应的处理。
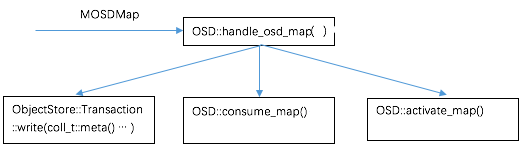
如上图所示,OSD 收到 MOSDMap 后,主要进行3个方面的处理
- ObjectStore::Transaction::write(coll_t::meta()) 更新 OSDMap 到磁盘,保存在目录 /var/lib/ceph/OSD/ceph-<id>/current/meta/,将 OSDMap 数据持久化,起到类似于 log 的作用。
- OSD::consume_map() 进行 PG 处理,包括删除 Pool 不存在的 PG; 更新 PG epoch(OSDmap epoch) 到磁盘(LevelDB); 产生 AdvMap 和 ActMap 事件,触发 PG 的状态机 state_machine 进行状态更新。
- OSD::activate_map() 根据需要决定是否启动 recovery_tp 线程池进行 PG 恢复。
在OSD端,PG 负责 I/O 的处理,因此 PG 的状态直接影响着 I/O,而 pgstate_machine 就是 PG 状态的控制机制,但里面的状态转换十分的复杂,这里不做具体分析。
下面开始分析 PG 的创建,删除,迁移
PG 的创建由运维人员触发,在新建 Pool 时指定 PG 的数量,或增加已有的 Pool 的 PG 数量,这时 OSDMonitor 监控到 OSDMap 发生变化,发送最新的 MOSDMap 到所有的 OSD。
在 PG 对应的一组 OSD 上,OSD::handle_pg_create() 函数在磁盘上创建 PG 目录,写入 PG 的元数据,更新 Heartbeat Peers 等操作。
PG 的删除同样由运维人员触发,OSDMonitor 发送 MOSDMap 到 OSD, 在 PG 对应的一组 OSD 上,OSD::handle_PG _remove() 函数负责从磁盘上删除PG 所在的目录,并从 PGMap 中删除 PG ,删除 PG 的元数据等操作。
PG 迁移较为复杂,涉及到两个OSD与monitor的协同处理。例如,向已有3个OSD的集群中新加入OSD3,导致 CRUSH 重新分布 PG , 某个 PG 的分配变化结果为 [0, 1, 2 ] -> [3, 1, 2]。当然,CRUSH 的分配具有随机性,不同的 PG 中,OSD3 既可能成为 Primary OSD,也可能成为 Replicate OSD, 这里取 OSD3 作为 Primary OSD为例。
新加入的OSD3取代了原有的 OSD0 成为 Primary OSD, 由于 OSD3 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,因此,这里引入 PG Temp 机制,即 OSD3 向 Monitor 发送 MOSDPG Temp,把 Primary OSD 指定为OSD1, 因为 OSD1 上保存了 PG 的数据,Client 发送到 PG 的请求都被转发到了 OSD1;与此同时,OSD1 向 OSD3 发送 PG 的数据,直到 PG 数据复制完成,OSD1 将 Primary OSD 的角色交还给 OSD3,Client 的 I/O 请求直接发送的 OSD3,这样就完成了 PG 的迁移。整个过程如下图所示。
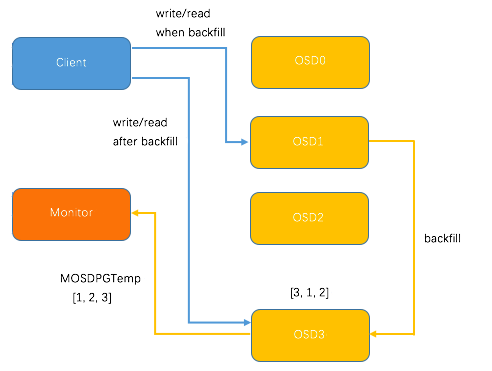
另外一种 PG 的迁移情景是 OSD3 作为 Replicate OSD 时,由 Primay OSD 向 OSD3 进行 PG 数据迁移,比上述 PG 迁移过程更为简单,这里不再详述。
本文从 PG 的视角阐述了 OSDMap 机制的基本原理,描述了 Monitor, OSD, PG 三者之间的关联。 在实际运维中,我们常常对于 OSD 状态和数量的变化引起的 PG 状态的变化感到疑惑,希望本文能够对解决的 PG 状态问题带来启发。
OSDMap 代码浅析
(摘自:https://gitee.com/wanghongxu/cephknowledge/blob/master/Ceph-OSDMap.md)
一、OSDMap模块简介
OSDMap是关于Ceph集群中所有OSD的信息,所有OSD节点的改变,踢出或加入集群,节点的权重改变都会 反映到这个Map上面。在Ceph集群中,所有的Server(MDS,MON和OSD...)和Client都得掌握这个 Map。
每个角色都可能持有不同epoch的OSDMap,如果客户端持有的map是过期的,可以利用OSD的回复来判断。
二、OSDMap模块数据结构
1.osd_info_t
struct osd_info_t {
epoch_t last_clean_begin;
epoch_t last_clean_end;
epoch_t up_from; // epoch osd marked up
epoch_t up_thru; // lower bound on actual osd death (if > up_from)
epoch_t down_at; // upper bound on actual osd death (if > up_from)
epoch_t lost_at; // last epoch we decided data was "lost"
...
};
-
last_clean_begin和last_clean_end: 以一个clean的osd关闭而结束的最终区间
-
up_from: osd被标记为up时的epoch
-
up_thru: 实际osd终止时的下界(如果它大于up_from)
-
down_at: 实际osd终止时的上界(如果它大于up_from)
-
lost_at: 决定数据已经丢失时的最终epoch
osd_info_t结构用来表述随着时间推移,各个状态的epoch。
我们跟踪在OSD存活且Clean时候的两个区间,最新的是[up_from,up_thru]。up_thru是已知OSD已经 启动的最后的epoch,即实际osd死亡的下界,down_at(如果它大于up_from)是实际osd死亡的上界。 第二个是last_clean区间[first,last],在这种情况下,last区间是已知完成的最后一个epoch,或 在此期间osd彻底关闭。如果可能的话,将last推送到osd被标记为down时的epoch。
lost_at用来允许build_prior不等待一个osd恢复的情况下进行。在某些情况下,进度可能被阻止, 因为osd可能包含更新(即,pg可能在一个区间内丢失读写)。如果osd无法在线,我们可以在已知丢失一些 确认写的情况下让强制进行。如果osd过会又好了,那也没关系,但是这些写依然会丢失(不同的对象会被 丢弃)。
2.osd_xinfo_t
struct osd_xinfo_t {
utime_t down_stamp;
float laggy_probability;
__u32 laggy_interval;
uint64_t features;
__u32 old_weight;
osd_xinfo_t() : laggy_probability(0), laggy_interval(0),
features(0), old_weight(0) {}
...
};
osd_xinfo_t结构为OSD的一些扩展信息
字段解释:
-
down_stamp: osd被标记为down时的时间戳
-
laggy_probability: 滞后概率,编码为__u32,0表示没有滞后,0xffffffff表示滞后
-
laggy_interval: 被标记为滞后和恢复中的平均间隔
-
features: 应该知道的osd所支持的特性
-
old_weight: 自动标记为out之前的权重
3.OSDMap
class OSDMap {
public:
class Incremental {
...
};
private:
uuid_d fsid;
epoch_t epoch; // what epoch of the osd cluster descriptor is this
utime_t created, modified; // epoch start time
int32_t pool_max; // the largest pool num, ever
uint32_t flags;
int num_osd; // not saved; see calc_num_osds
int num_up_osd; // not saved; see calc_num_osds
int num_in_osd; // not saved; see calc_num_osds
int32_t max_osd;
vector<uint8_t> osd_state;
struct addrs_s {
vector<ceph::shared_ptr<entity_addr_t> > client_addr;
vector<ceph::shared_ptr<entity_addr_t> > cluster_addr;
vector<ceph::shared_ptr<entity_addr_t> > hb_back_addr;
vector<ceph::shared_ptr<entity_addr_t> > hb_front_addr;
entity_addr_t blank;
};
ceph::shared_ptr<addrs_s> osd_addrs;
vector<__u32> osd_weight;
vector<osd_info_t> osd_info;
ceph::shared_ptr< map<pg_t,vector<int32_t> > > pg_temp;
ceph::shared_ptr< map<pg_t,int32_t > > primary_temp;
ceph::shared_ptr< vector<__u32> > osd_primary_affinity;
map<int64_t,pg_pool_t> pools;
map<int64_t,string> pool_name;
map<string,map<string,string> > erasure_code_profiles;
map<string,int64_t> name_pool;
ceph::shared_ptr< vector<uuid_d> > osd_uuid;
vector<osd_xinfo_t> osd_xinfo;
ceph::unordered_map<entity_addr_t,utime_t> blacklist;
epoch_t cluster_snapshot_epoch;
string cluster_snapshot;
bool new_blacklist_entries;
mutable uint64_t cached_up_osd_features;
mutable bool crc_defined;
mutable uint32_t crc;
...
public:
ceph::shared_ptr<CrushWrapper> crush;
...
}
OSDMap结构存储了包括集群id,epoch信息,创建及修改时间,pool信息,OSD信息(总的OSD,up的 OSD以及已经加入集群的OSD)等等。
字段解释:
-
fsid: 集群id
-
created, modified: epoch开始时间
-
pool_max: 从开始到现在的最大的pool id
-
pg_temp: 临时pg映射(比如重建)
-
primary_temp: 临时primary映射
-
flags: OSD的标志位(以jewel为例,常见的标志位有sortbitwise,require_jewel_osds),后 面会详细叙述
标志位在这里的作用是标识OSD集群的当前的一些状态,在使用ceph -s命令的时候会连同OSD信息(总 的OSD,up的OSD以及已经加入集群的OSD)一起输出,方便第一时间了解到一些异常情况。
另外,比如要设置OSD不进行数据清洗,可以通过ceph命令设置标志位为noscrub及nodeep-scrub
[root@cephdev ]# ceph osd set noscrub [root@cephdev ]# ceph osd set nodeep-scrub
之后,再次查看集群状态的时候就会发现多了这两个标志位:
[root@cephdev ]# ceph -s
cluster a7aaeb51-63d4-4a07-9e5f-b94d970a686e
health HEALTH_WARN
noscrub,nodeep-scrub,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 1 mons at {a=127.0.0.1:6789/0}
election epoch 4, quorum 0 a
osdmap e10: 1 osds: 1 up, 1 in
flags noscrub,nodeep-scrub,sortbitwise,require_jewel_osds
pgmap v12042: 8 pgs, 1 pools, 0 bytes data, 0 objects
840 MB used, 425 GB / 426 GB avail
8 active+clean
标志位解释:
-
nearfull: 磁盘快满了
-
full: 磁盘已经满了
-
pauserd: 暂停所有读
-
pausewr: 暂停所有写
-
pauserec: 暂停恢复
-
noup: 禁止OSD启动
-
nodown: 禁止标记OSD为down
-
noout: 禁止OSD自动标记为out
-
noin: 禁止OSD自动标记为in
-
nobakfill: 禁止OSD进行数据回填
-
norebalance: 禁止OSD回填,除非pg降级
-
norecover: 禁止OSD恢复和回填
-
noscrub: 设置OSD不进行数据清洗
-
nodeep-scrub: 设置OSD不进行数据的深度清洗
-
notieragent: 禁止
tiering agent -
sortbitwise: 使用hobject_t按位排序
-
require_jewel_osds: 这个标记从J版开始有,标志当前OSD的版本,升级的时候有用
4.Incremental
class Incremental {
public:
/// feature bits we were encoded with. the subsequent OSDMap
/// encoding should match.
uint64_t encode_features;
uuid_d fsid;
epoch_t epoch; // new epoch; we are a diff from epoch-1 to epoch
utime_t modified;
int64_t new_pool_max; //incremented by the OSDMonitor on each pool create
int32_t new_flags;
// full (rare)
bufferlist fullmap; // in lieu of below.
bufferlist crush;
// incremental
int32_t new_max_osd;
map<int64_t,pg_pool_t> new_pools;
map<int64_t,string> new_pool_names;
set<int64_t> old_pools;
map<string,map<string,string> > new_erasure_code_profiles;
vector<string> old_erasure_code_profiles;
map<int32_t,entity_addr_t> new_up_client;
map<int32_t,entity_addr_t> new_up_cluster;
map<int32_t,uint8_t> new_state; // XORed onto previous state.
map<int32_t,uint32_t> new_weight;
map<pg_t,vector<int32_t> > new_pg_temp; // [] to remove
map<pg_t, int32_t> new_primary_temp; // [-1] to remove
map<int32_t,uint32_t> new_primary_affinity;
map<int32_t,epoch_t> new_up_thru;
map<int32_t,pair<epoch_t,epoch_t> > new_last_clean_interval;
map<int32_t,epoch_t> new_lost;
map<int32_t,uuid_d> new_uuid;
map<int32_t,osd_xinfo_t> new_xinfo;
map<entity_addr_t,utime_t> new_blacklist;
vector<entity_addr_t> old_blacklist;
map<int32_t, entity_addr_t> new_hb_back_up;
map<int32_t, entity_addr_t> new_hb_front_up;
string cluster_snapshot;
mutable bool have_crc; ///< crc values are defined
uint32_t full_crc; ///< crc of the resulting OSDMap
mutable uint32_t inc_crc; ///< crc of this incremental
}
结构Incremental表示OSDMap的增量版本
字段解释:
-
encode_features: 编码的特征位,随后的OSDMap编码应该匹配
-
epoch: 新的epoch,从epoch-1到epoch的差异
-
new_pool_max: 当每个pool被创建时由OSDMonitor增加
-
fullmap: 代替变量crush
-
have_crc: crc值定义时为true
-
inc_crc: 该增量的crc
三、MOSDMap消息
该消息用来获取OSDMap信息。
四、OSDMap更新机制
在部署Monitor的时候,Monitor的KeyValueDB中只保存有epoch为1的osdmap,此时并没有osd在集 群中,当有OSD向Monitor去申请加入集群的时候,Monitor会将该OSD记录在OSDMap中并写入 KeyValueDB中。同时,当OSD有更新的时候,Monitor也会向OSD发送消息,然后OSD在 handle_osd_map中处理该消息。
当部署OSD的时候,OSD::mkfs期间,会在OSD数据目录创建meta目录并初始化,当OSD申请加入Ceph进 群成功后,该目录中就会存储有每个epoch的OSDMap信息。
五、OSDMap要点分析
六、获取OSDMap
Ceph提供了一个命令行工具osdmaptool,能让你创建,查看和操作OSD映射关系。更重要的是,使用该 工具能获取和导入Crushmap,并能模拟OSD的分布。
对于OSD来说,它保存了每个epoch时的OSDMap信息,默认存放在OSD数据目录的current/meta中。
1.查看当前集群最新epoch的OSDMap信息
使用ceph osd dump命令可以查看当前最新epoch的OSDMap信息。另外,确认当前OSDMap的最新 epoch后,在OSD数据目录的meta目录下找到以osdmap.{epoch}开头的文件即是。查看OSDMap信息, 使用--print参数即可。
osdmaptool --print osdmap.736__0_AC955C85__none
osdmaptool: osdmap file 'osdmap.736__0_AC955C85__none'
epoch 736
fsid d9650900-aa7a-465a-a483-a1e80e7c7efa
created 2016-11-05 23:03:48.070572
modified 2017-03-16 10:12:26.756716
flags sortbitwise,require_jewel_osds,require_kraken_osds
pool 7 'ssd' replicated size 3 min_size 1 crush_ruleset 0 object_hash rjenkins
pg_num 320 pgp_num 320 last_change 578 flags hashpspool stripe_width 0
removed_snaps [1~3]
pool 19 'images' replicated size 3 min_size 1 crush_ruleset 0 object_hash
rjenkins pg_num 2 pgp_num 2 last_change 620 flags hashpspool stripe_width 0
removed_snaps [1~3]
max_osd 6
osd.0 down out weight 0 up_from 393 up_thru 383 down_at 394 last_clean_interval
[389,389)192.168.108.11:6800/2582901 192.168.108.11:6801/2582901
192.168.108.11:6802/2582901 192.
168.108.11:6803/2582901 autoout,exists cfc90fe4-952c-495a-9b25-3d81b4cf441e
osd.1 up in weight 1 up_from 726 up_thru 735 down_at 724 last_clean_interval
[717,725) 192.168.108.11:6800/1937953 192.168.108.11:6805/2937953
192.168.108.11:6809/2937953 192.
168.108.11:6821/2937953 exists,up 6c614571-47db-490e-8f98-184e0e963430
osd.2 up in weight 1 up_from 735 up_thru 735 down_at 733 last_clean_interval
[648,734) 192.168.108.12:6804/312646 192.168.108.12:6801/5312646
192.168.108.12:6802/5312646 192.168.108.12:6803/5312646 exists,up
e1ed8e95-3900-491d-8f30-a6db0259698a
osd.3 up in weight 1 up_from 731 up_thru 735 down_at 729 last_clean_interval
[636,730) 192.168.108.12:6800/1675 192.168.108.12:6809/9001675
192.168.108.12:6810/9001675 192.168.108.12:6811/9001675 exists,up
f9d5146d-5a77-4d8f-b893-50860fc50f02
osd.4 down out weight 0 up_from 250 up_thru 346 down_at 348 last_clean_interval
[236,248) 192.168.108.13:6800/286476 192.168.108.13:6801/286476
192.168.108.13:6802/286476 192.168.108.13:6803/286476 autoout,exists
e4158fd4-84c6-41c6-b231-f4335edb9ff8
osd.5 down out weight 0 up_from 643 up_thru 649 down_at 651 last_clean_interval
[566,567) 192.168.108.13:6801/3857339 192.168.108.13:6802/3857339
192.168.108.13:6803/3857339 192.
168.108.13:6804/3857339 autoout,exists 9a17c533-24e0-4742-a977-2fdb14fd5415
pg_temp 7.1 [1,3,2]
...
如上所示,OSDMap中包含有当前map的epoch,集群id,创建修改时间,标志位,pool id,pool name, 副本数,最小副本数,使用的crush规则,pg和pgp数量,osd数量,各个osd在集群中的状态,权值, pg_temp映射关系等等。
注意:OSD中存储的OSDMap文件是Monitor维护的OSDMap的持久化形式,相当于log的作用。在Monitor 端,从epoch为1到当前epoch的所有的集群Map信息都会在Monitor的KeyValueDB中存储。
七、与OSDMap相关的参数配置
mon_osd_cache_size
-
描述:OSDMaps的缓存大小,不依赖于底层的存储缓存
-
类型:int
-
默认值:10
mon_osd_allow_primary_temp
-
描述:允许在OSDMap中设置primary_temp
-
类型:bool
-
默认值:false
mon_osd_prime_pg_temp
-
描述:prime osdmap with pg mapping changes
-
类型:bool
-
默认值:true
mon_min_osdmap_epochs
-
描述:
-
类型:int
-
默认值:500
osd_map_message_max
-
描述:每个MOSDMap消息最大的map数
-
类型:int
-
默认值:100
osd_map_dedup
-
描述:允许删除OSDMap里的重复项
-
类型:bool
-
默认值:true
osd_map_cache_size
-
描述:缓存的OSDMap个数
-
类型:int
-
默认值:200
八、疑点
1.is_up_acting_osd_shard
messenger 建立连接的时候bind的socket addr和socket port的指定
public_messenger->bind()
| -- | AsyncMessenger::bind()
| -- | -- | Processor::bind()
AsyncMessenger::bindv()
{
AsyncMessenger::bindv()
{
std::set<int> avoid_ports;
entity_addrvec_t bound_addrs;
unsigned i = 0;
for (auto &&p : processors)
{
int r = p->bind(bind_addrs, avoid_ports, &bound_addrs);
}
}
}
int Processor::bind(const entity_addrvec_t &bind_addrs,
const std::set<int>& avoid_ports,
entity_addrvec_t* bound_addrs)
{
……
//try a range of ports 在给定的端口范围内,找出一个没有被本进程使用过的端口,且能绑定上的
for (int port = msgr->cct->_conf->ms_bind_port_min;
port <= msgr->cct->_conf->ms_bind_port_max;
port++) {
if (avoid_ports.count(port))
continue;
listen_addr.set_port(port);//找到一个端口,接下来尝试bind
worker->center.submit_to(
worker->center.get_id(),
[this, k, &listen_addr, &opts, &r]() {
r = worker->listen(listen_addr, k, opts, &listen_sockets[k]);
}, false);
if (r == 0)
break;
}
if (r < 0) {
lderr(msgr->cct) << __func__ << " unable to bind to " << listen_addr
<< " on any port in range "
<< msgr->cct->_conf->ms_bind_port_min
<< "-" << msgr->cct->_conf->ms_bind_port_max << ": "
<< cpp_strerror(r) << dendl;
listen_addr.set_port(0); // Clear port before retry, otherwise we shall fail again.
continue;
}
ldout(msgr->cct, 10) << __func__ << " bound on random port "
}
bind完成之后,将传入参数bind_addrs里的对应的v的port设置为 (ms_bind_port_min到ms_bind_port_max之间的某端口号,然后交给 worker->listen,如果listen成功就返回,传入参数entity_addrvec_t bind_addrs里的对应的v的port的值,就为刚才设置的值,传出去了
int Processor::bind(const entity_addrvec_t &bind_addrs,……)
auto& listen_addr = bound_addrs->v[k];listen_addr.set_port(port);
r = worker->listen(listen_addr, k, opts, &listen_sockets[k]);
int RDMAWorker::listen(entity_addr_t &sa, unsigned addr_slot,
const SocketOptions &opt,ServerSocket *sock)
p = new RDMAServerSocketImpl(cct, ib, dispatcher, this, sa, addr_slot);
int r = p->listen(sa, opt);
int RDMAServerSocketImpl::listen(entity_addr_t &sa, const SocketOptions &opt) { int rc = 0; server_setup_socket = net.create_socket(sa.get_family(), true); if (server_setup_socket < 0) { rc = -errno; lderr(cct) << __func__ << " failed to create server socket: " << cpp_strerror(errno) << dendl; return rc; } rc = net.set_nonblock(server_setup_socket); if (rc < 0) { goto err; } rc = net.set_socket_options(server_setup_socket, opt.nodelay, opt.rcbuf_size); if (rc < 0) { goto err; } rc = ::bind(server_setup_socket, sa.get_sockaddr(), sa.get_sockaddr_len()); <----------这里 if (rc < 0) { rc = -errno; ldout(cct, 10) << __func__ << " unable to bind to " << sa.get_sockaddr() << " on port " << sa.get_port() << ": " << cpp_strerror(errno) << dendl; goto err; } rc = ::listen(server_setup_socket, cct->_conf->ms_tcp_listen_backlog); if (rc < 0) { rc = -errno; lderr(cct) << __func__ << " unable to listen on " << sa << ": " << cpp_strerror(errno) << dendl; goto err; } ldout(cct, 20) << __func__ << " bind to " << sa.get_sockaddr() << " on port " << sa.get_port() << dendl; return 0; err: ::close(server_setup_socket); server_setup_socket = -1; return rc; }
port 在 entity_addr_t 结构体里
/*
* an entity's network address.
* includes a random value that prevents it from being reused.
* thus identifies a particular process instance.
* ipv4 for now.
*/
struct entity_addr_t {
typedef enum {
TYPE_NONE = 0,
TYPE_LEGACY = 1, ///< legacy msgr1 protocol (ceph jewel and older)
TYPE_MSGR2 = 2, ///< msgr2 protocol (new in ceph kraken)
TYPE_ANY = 3, ///< ambiguous
} type_t;
static const type_t TYPE_DEFAULT = TYPE_MSGR2;
static std::string_view get_type_name(int t) {
switch (t) {
case TYPE_NONE: return "none";
case TYPE_LEGACY: return "v1";
case TYPE_MSGR2: return "v2";
case TYPE_ANY: return "any";
default: return "???";
}
};__u32 type;
__u32 nonce;
union {
sockaddr sa;
sockaddr_in sin;
sockaddr_in6 sin6;
} u;entity_addr_t() : type(0), nonce(0) {
memset(&u, 0, sizeof(u));
}
entity_addr_t(__u32 _type, __u32 _nonce) : type(_type), nonce(_nonce) {
memset(&u, 0, sizeof(u));
}
explicit entity_addr_t(const ceph_entity_addr &o) {
type = o.type;
nonce = o.nonce;
memcpy(&u, &o.in_addr, sizeof(u));
#if !defined(__FreeBSD__)
u.sa.sa_family = ntohs(u.sa.sa_family);
#endif
}uint32_t get_type() const { return type; }
void set_type(uint32_t t) { type = t; }
bool is_legacy() const { return type == TYPE_LEGACY; }
bool is_msgr2() const { return type == TYPE_MSGR2; }
bool is_any() const { return type == TYPE_ANY; }__u32 get_nonce() const { return nonce; }
void set_nonce(__u32 n) { nonce = n; }int get_family() const {
return u.sa.sa_family;
}
void set_family(int f) {
u.sa.sa_family = f;
}bool is_ipv4() const {
return u.sa.sa_family == AF_INET;
}
bool is_ipv6() const {
return u.sa.sa_family == AF_INET6;
}sockaddr_in &in4_addr() {
return u.sin;
}
const sockaddr_in &in4_addr() const{
return u.sin;
}
sockaddr_in6 &in6_addr(){
return u.sin6;
}
const sockaddr_in6 &in6_addr() const{
return u.sin6;
}
const sockaddr *get_sockaddr() const {
return &u.sa;
}
size_t get_sockaddr_len() const {
switch (u.sa.sa_family) {
case AF_INET:
return sizeof(u.sin);
case AF_INET6:
return sizeof(u.sin6);
}
return sizeof(u);
}
bool set_sockaddr(const struct sockaddr *sa)
{
switch (sa->sa_family) {
case AF_INET:
// pre-zero, since we're only copying a portion of the source
memset(&u, 0, sizeof(u));
memcpy(&u.sin, sa, sizeof(u.sin));
break;
case AF_INET6:
// pre-zero, since we're only copying a portion of the source
memset(&u, 0, sizeof(u));
memcpy(&u.sin6, sa, sizeof(u.sin6));
break;
case AF_UNSPEC:
memset(&u, 0, sizeof(u));
break;
default:
return false;
}
return true;
}sockaddr_storage get_sockaddr_storage() const {
sockaddr_storage ss;
memcpy(&ss, &u, sizeof(u));
memset((char*)&ss + sizeof(u), 0, sizeof(ss) - sizeof(u));
return ss;
}void set_in4_quad(int pos, int val) {
u.sin.sin_family = AF_INET;
unsigned char *ipq = (unsigned char*)&u.sin.sin_addr.s_addr;
ipq[pos] = val;
}
void set_port(int port) {
switch (u.sa.sa_family) {
case AF_INET:
u.sin.sin_port = htons(port);
break;
case AF_INET6:
u.sin6.sin6_port = htons(port);
break;
default:
ceph_abort();
}
}
int get_port() const {
switch (u.sa.sa_family) {
case AF_INET:
return ntohs(u.sin.sin_port);
case AF_INET6:
return ntohs(u.sin6.sin6_port);
}
return 0;
}operator ceph_entity_addr() const {
ceph_entity_addr a;
a.type = 0;
a.nonce = nonce;
a.in_addr = get_sockaddr_storage();
#if !defined(__FreeBSD__)
a.in_addr.ss_family = htons(a.in_addr.ss_family);
#endif
return a;
}bool probably_equals(const entity_addr_t &o) const {
if (get_port() != o.get_port())
return false;
if (get_nonce() != o.get_nonce())
return false;
if (is_blank_ip() || o.is_blank_ip())
return true;
if (memcmp(&u, &o.u, sizeof(u)) == 0)
return true;
return false;
}bool is_same_host(const entity_addr_t &o) const {
if (u.sa.sa_family != o.u.sa.sa_family)
return false;
if (u.sa.sa_family == AF_INET)
return u.sin.sin_addr.s_addr == o.u.sin.sin_addr.s_addr;
if (u.sa.sa_family == AF_INET6)
return memcmp(u.sin6.sin6_addr.s6_addr,
o.u.sin6.sin6_addr.s6_addr,
sizeof(u.sin6.sin6_addr.s6_addr)) == 0;
return false;
}bool is_blank_ip() const {
switch (u.sa.sa_family) {
case AF_INET:
return u.sin.sin_addr.s_addr == INADDR_ANY;
case AF_INET6:
return memcmp(&u.sin6.sin6_addr, &in6addr_any, sizeof(in6addr_any)) == 0;
default:
return true;
}
}bool is_ip() const {
switch (u.sa.sa_family) {
case AF_INET:
case AF_INET6:
return true;
default:
return false;
}
}std::string ip_only_to_str() const;
std::string get_legacy_str() const {
std::ostringstream ss;
ss << get_sockaddr() << "/" << get_nonce();
return ss.str();
}bool parse(const std::string_view s);
bool parse(const char *s, const char **end = 0, int type=0);void decode_legacy_addr_after_marker(ceph::buffer::list::const_iterator& bl)
{
using ceph::decode;
__u8 marker;
__u16 rest;
decode(marker, bl);
decode(rest, bl);
decode(nonce, bl);
sockaddr_storage ss;
decode(ss, bl);
set_sockaddr((sockaddr*)&ss);
if (get_family() == AF_UNSPEC) {
type = TYPE_NONE;
} else {
type = TYPE_LEGACY;
}
}// Right now, these only deal with sockaddr_storage that have only family and content.
// Apparently on BSD there is also an ss_len that we need to handle; this requires
// broader studyvoid encode(ceph::buffer::list& bl, uint64_t features) const {
using ceph::encode;
if ((features & CEPH_FEATURE_MSG_ADDR2) == 0) {
encode((__u32)0, bl);
encode(nonce, bl);
sockaddr_storage ss = get_sockaddr_storage();
encode(ss, bl);
return;
}
encode((__u8)1, bl);
ENCODE_START(1, 1, bl);
if (HAVE_FEATURE(features, SERVER_NAUTILUS)) {
encode(type, bl);
} else {
// map any -> legacy for old clients. this is primary for the benefit
// of OSDMap's blocklist, but is reasonable in general since any: is
// meaningless for pre-nautilus clients or daemons.
auto t = type;
if (t == TYPE_ANY) {
t = TYPE_LEGACY;
}
encode(t, bl);
}
encode(nonce, bl);
__u32 elen = get_sockaddr_len();
#if (__FreeBSD__) || defined(__APPLE__)
elen -= sizeof(u.sa.sa_len);
#endif
encode(elen, bl);
if (elen) {
uint16_t ss_family = u.sa.sa_family;encode(ss_family, bl);
elen -= sizeof(u.sa.sa_family);
bl.append(u.sa.sa_data, elen);
}
ENCODE_FINISH(bl);
}
void decode(ceph::buffer::list::const_iterator& bl) {
using ceph::decode;
__u8 marker;
decode(marker, bl);
if (marker == 0) {
decode_legacy_addr_after_marker(bl);
return;
}
if (marker != 1)
throw ceph::buffer::malformed_input("entity_addr_t marker != 1");
DECODE_START(1, bl);
decode(type, bl);
decode(nonce, bl);
__u32 elen;
decode(elen, bl);
if (elen) {
#if defined(__FreeBSD__) || defined(__APPLE__)
u.sa.sa_len = 0;
#endif
uint16_t ss_family;
if (elen < sizeof(ss_family)) {
throw ceph::buffer::malformed_input("elen smaller than family len");
}
decode(ss_family, bl);
u.sa.sa_family = ss_family;
elen -= sizeof(ss_family);
if (elen > get_sockaddr_len() - sizeof(u.sa.sa_family)) {
throw ceph::buffer::malformed_input("elen exceeds sockaddr len");
}
bl.copy(elen, u.sa.sa_data);
}
DECODE_FINISH(bl);
}void dump(ceph::Formatter *f) const;
static void generate_test_instances(std::list<entity_addr_t*>& o);
}


