

【存储】数据重删压缩
重删压缩是什么?
(个人觉得更好的翻译应该是:删重和压缩)
重删和压缩时完全不同的两种技术,解决不同的问题。
重删:就是说有很多分相同的数据,我只存储其中一份,其他的重复数据块我保留一个地址引用到这个唯一存储的块即可。
压缩:将一个大字符串中的子串用一个很简短的数字来标记,然后检索该字符串出现的位置,用个简单的字符来替代。从而来减少数据表达所需要的空间,带来空间节省。
比如说用1代表“AB”,用2代表“CD”,然后用255 来代表“hanfute”。1到255只需要8个bit,而“AB”“CD”或者“hanfute”则需要很多的空间,这样多次扫描替代之后,就可以快速的将数据缩减。
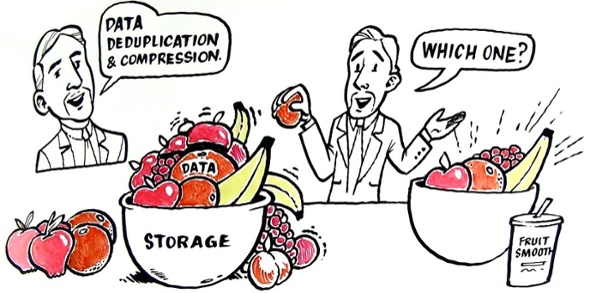
用通俗的话说:重删就是讲相同的东西只存储一次,而压缩则是改造数据排布用一种算法来统计数据的排布模式,从而达到减少数据存储的模式。
https://blog.51cto.com/u_13559412/2057144
重删的实现
重删的实现技术比较简单,最简单的使用就比如我们的邮件服务器,我转发一份邮件给100个人,大家收到我的邮件后就会产生100个一样的文件,假设大家的数据盘使用的共享存储,存储只需要在每个人存入文件的时候查询一下这个文件本地有没有,有我就不再存储。这样在存储上就只存储了一个文件。这是一个最朴素的理解。
这里面涉及到几个问题:
1, 存储怎么知道这个文件自己已经存储了?
2, 如果不是存文件,而是块存储该怎么办?
存储怎么知道这个文件自己已经有了呢?
在计算机里面有个技术名字叫做”指纹”,非常的形象生动,就好像每个人的指纹肯定不一样,那么我们是不是可以用一个很小的数据来标记一个文件的唯一信息。
这里有很多的算法可以快速的得到一个唯一值,比如说MD5算法、Sha算法。
l Sha算法是一种不可逆的数据加密算法,只能算指纹出来,但是无法通过指纹反推出来内容。
l 他可以经一个小于2^64的数据转化成一个160位的不重复的指纹,最关键的是他的计算还很快。
l 所以比较两个数据是否相同,就可以通过计算他的指纹,然后去对比指纹,而不是进行数据的逐字节比对。效率要高得多。
这个指纹有没有可能重复,比如说两个人的指纹相同?
按照sha256算法,在4.8*10^29个数据中出现两个数据指纹重复的概率大概小于10^-18.10^-18就是我们所说的16个9的可靠性。
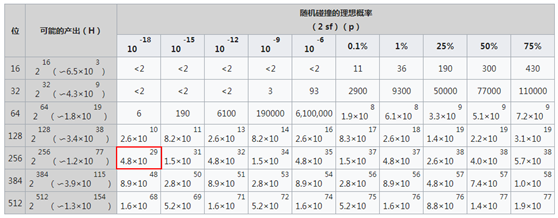
转化成存储语言我们来讨论一下。假如说我们的存储每秒钟写入的10万个文件,按照存储7*24*365天工作,那么每年写入的数据为365*24*3,600*10,000=3.15*10^12个文件。如果想让存储出现哈希碰撞而导致重删丢数据(概率大于10^-18),那么需要运行1.52*10^17年,可能会遇到一次。

其实我们主流存储设备的可靠性一般为99.9999%也就是我们常说的6个9,是远远不如哈希值可靠的。这也是很多人担心的重删会不会把我的数据删除没有了,导致我的数据损坏呢,其实不用这个担心。
但是还是有人会担心,怎么办呢?还有另外一种方法,那就是遇到一个新数据,我就用两种算法,存储两个hash值,遇到了重复数据进行两重hash比对。
但是有人还是对hash算法有担心,也简单,对于重复数据我们再进行一次逐字节比对嘛,不过就是会稍微影响性能。
如果不是文件,块存储该怎么处理?
重复数据删除技术在块存储的实现比较多样化。
最简单最基本的方式就是直接定长重删。所以写入的数据按照固定长度进行切片,切片后进行hash计算,然后进行写入处理,非重复数据就单独写入,重复数据就写入引用即可。

但是这种处理方式重删率是比较低的,比如说一个文件,我们只在文件上添加一个字符,然重新写入,这个文件采用定长方式切片后就无法找到和以前相同的块,导致无法被重删掉数据。因此业界也有很多的边长重删的算法。
但是变长重删对性能和算法要求都比较高,同时对于CPU内存消耗也大,影响了数据的实时处理效率。毕竟存储主要还是处理主机的IO读写响应的。只有在备份归档领域用的比较多,因为这个场景节省空间比快速响应要求高的多。
以下面这个图片为例,变长重删效率可能达到10:1,而定长重删只有3:1.
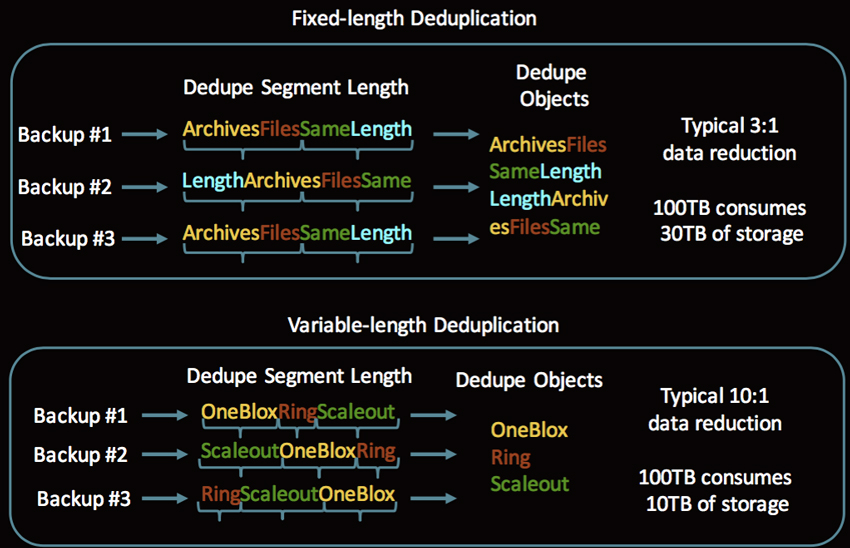
因此,对于全闪存存储这种响应要求高的,建议定长重删,速度快。对于归档、备份这种冷存储建议变长重删,重删率高节省成本。
重删总结
其实重删这个功能在全闪存市场用处并不大,因为很多时候定长重删的效果很有限,比较典型的比如数据库场景,重删率只有可怜的1.05:1几乎可以忽略不计。
对于全闪存来说压缩更有效,下面我们来看看压缩技术。
压缩技术的实现
压缩技术由来已久,分为无损压缩和有损压缩。

有损压缩主要用于图像处理领域,比如说我微信发一个照片,明明本地10M的高清图片传输到朋友手机里面就有300K的图片。这主要为了节省网络传输的流量以及微信存储空间节省。
存储系统领域用的压缩都是无损压缩。借助于算法的普及,业界主流存储厂商的压缩实现几乎都没有算法上的区别,只是在于压缩的实现选择上,主要考虑兼顾性能和数据缩减率。
压缩对存储的性能影响有多大
基于EMC Unity Sizer的性能评估工具,我们大概可以看到开启压缩相对于不开启压缩,IOPS从20万左右降低到了12万,存储性能下降大概是40%。
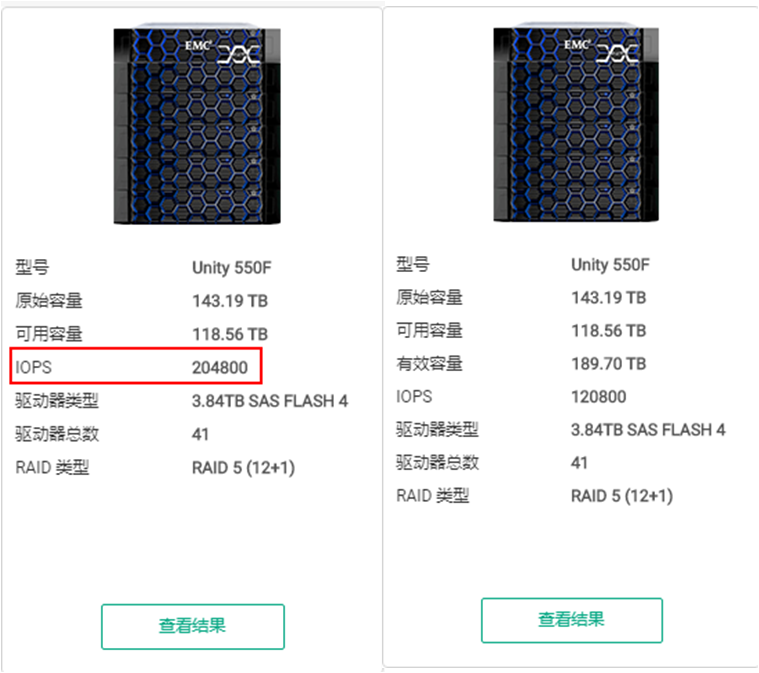
其实我们最新的intel CPU里面已经集成了压缩算法,我上次私下里和我们测试经理进行了数据的了解,在开启压缩,满负载的进行存储性能压力测试,存储CPU利用率75%的时候,其中用于压缩所消耗的CPU资源不到3%。为什么存储性能下降了这么多???
实现压缩带来的ROW架构性效率下降
我们传统的存储,不需要压缩的时候,我们每个数据都是由自己在硬盘上的固定地址的。比如说LUN1的LBA00xx64~00x128 存储在5号磁盘的低8个扇区的第X位开始的连续64bit地址上。如果我以8KB为存储的最小块大小,那么每个8KB都是存储在一个固定的8KB的物理盘片的具体物理地址上。在我第一次写入的时候被我所独占。

以后这个8KB不管怎么改写读取,都是8KB。记录这些数据存储的位置的方式非常简单。假如说一个LUN一共1TB,那么我就记录这么1TB分布在几个盘里面,用一个很简单的算法将他分布在那个盘的那个物理地址轻松地就算了出来。我只需要记录一共由几块盘,一共组成了几个RAID组,每个RAID条带深度是多少,起始地址是多少,就能在内存中快速的用这些基本数据算出数据对应的物理地址是多少。
这种基本的写入模式叫做COW(copy on write),就是说写前拷贝。

传统的RAID模式注定了 我们只要改写一个位,就需要将原有数据和校验数据同时读取,然后在内存中计算后再写进去。读取的原因是为了方式写入失败我可以恢复回去.
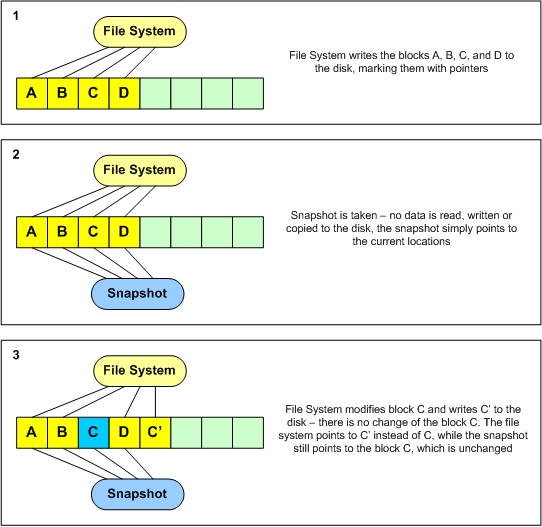
而写前拷贝并不是指的这个问题,而是指在有数据快照的情况下如何写入,这个时候我们不能破坏快照的数据,就只能将原有位置的数据拷贝到一个专门的快照存储区域。这称之为COW,他是相对于ROW(redirect on write)而发明的一个词。
国内很多人对于COW叫做“靠”架构。
由于压缩后一个8KB的数据有可能变成了1Kb、2KB、3KB也可能是8KB,那么我的数据就是一个可变的长度,如果还采用物理地址和逻辑地址一一对应的方式我就达不到节省空间的效果了。我将一个8KB的块压缩成了1KB,结果你还是给我分配了8KB物理空间来存储,这简直就是不合适。因此在压缩的实现上,存储一般都采用ROW架构来实现。
ROW带来了那些性能下降
1,由于ROW架构每个块都需要单独存储一次地址的映射关系,所以容量越大,产生的元数据量也越大,所以ROW架构一般容量越大,性能越差。
为了更好的处理数据,肯定想元数据全部在内存中缓存是效率最好的,所以ROW架构存储对内存的诉求很大。
2,由于ROW架构每次写入都需要记录地址元数据,处于可靠性考虑,我们肯定需要持久化,每次都要元数据下盘,这样一次写入就会产生两次的操作,写入元数据,写入数据。
3,由于ROW架构的数据写入采用了新找地址写入,这样原来逻辑上连续的数据会被不断的离散化,最终连续IO也会变成随机IO,对性能影响较大
4, ROW带来了另一个问题,以上图为例,我们如果没有快照,那么C这个数据块就是一个无效的数据,但是我们并不会在写入的时候立即的删除这个数据,因为会影响性能。我们就需要在没有连续空间或者业务空闲的时候专门来处理这些失效的块。这个也就是我们经常所说的垃圾回收,垃圾回收对性能影响很大,很多厂商干脆就不回收,而采用直接填空写入的方式。不管哪种方式对于垃圾空间的重复利用是对性能影响极大的一个操作。
这些问题在传统硬盘场景影响更为明显,这也是以前Netapp在HDD时代性能被诟病的一个原因。
而SSD盘内部的数据处理也是类似,SSD中开启垃圾回收导致的性能下降被称之为“写悬崖”

压缩总结:
压缩对于存储性能带来的冲击,根本不是来自与压缩本身,而是由于实现压缩的架构而带来的影响。
按照当前业界主流存储厂商的软件架构和效率来评估,一般ROW架构的存储相对于COW架构在性能上大概要下降35%左右,而压缩本身带来的性能损失一般在5%以内,所以对于整个存储系统来说,开启压缩性能下降幅度大概在40%左右
在ROW架构上实现重删还有有哪些冲击呢
相对于压缩在内存中计算完成后就直接写入,重删的影响更大:
1, 需要有单独的空间来存储指纹(带来了内存可支持存储空间越来越小)
2, 每次写入都需要进行指纹比对(读写时延增加)
3, 对于一个新数据块的写入产生了大幅的放大(指纹库记录一次、数据块写入一次、元数据记录映射一次),所以很多时候重删带来的性能主要在时延。
极端情况:一个典型的极端情况,如果是HDD存储环境,我们假设我们ROW系统的定长块大小是8KB,如果我写入一个128KB的数据,会被切片成16个数据片,进行16*3次数据下盘操作,最终的时延可以达到HDD本身的48倍,假设一个HDD响应是5ms,那么这个整个IO的响应时延达到了200ms以上,对于SAN存储来说这几乎是不可接受。
如何实现高效的重删压缩
重删压缩对性能的影响大家都知道,如何降低存储压缩带来的性能影响,我们在下一篇文章来详细的介绍。敬请期待
-----------------------------------
©著作权归作者所有:来自51CTO博客作者煮酒论IT的原创作品,请联系作者获取转载授权,否则将追究法律责任
浅谈存储重删压缩技术(一)
https://blog.51cto.com/u_13559412/2057144
重复数据删除的分类
按照重删执行的时间,重删可以分为在线重删和后处理重删:
在线重删:指数据在写入磁盘之前进行重删。
后处理重删:数据先写入磁盘,然后再读出来进行重删,重删之后的数据再写入磁盘中。通常在实际操作时,用户会根据所承载业务的负载,指定系统相对空闲的时间让重删包括压缩功能运行起来。
对于在线重删和后处理重删的定义,业界也存在不同的理解。如先将数据写入缓存,然后从缓存刷到磁盘上,数据在刷盘过程中被重删。对于这种实现方式,有厂商认为也是一种后处理重删。
按照数据分块的方式,重删可以分为定长重删和变长重删:
定长重删:数据按照固定长度进行分块,之后进行重删;
变长重删:数据被划分成不同大小的块进行重删。变长重删一般使用在备份场景中,这种分块重删方式一般可以获得比较好的重删效果。
按照重删的粒度,也可以分为块级重删和文件级重删:
块级重删:以数据块为粒度进行指纹计算,之后重删。
文件级重删:以整个文件为粒度计算指纹,然后重删。文件级重删又称为单一实例库重删。
关于数据块级重删和文件级重删,普遍存在一些误区,以为在文件系统中的重删就是文件级重删。其实在文件系统中,也可以将文件按照粒度分割成单个的数据块,实现数据块级的重删,这种方法也是统一存储中,友商实现重删功能的普遍做法。
按照重删发生的地方,重删可以分为源端重删和目标端重删:
源端重删:数据在源端经过分块并计算指纹,之后发送到目标端进行查重,如果是新的数据块,则通知源端将该数据块发送到目标端进行保存;如果是重复块,则不发送。源端重删的目主要是为了节省两端之间的传输带宽。
目标端重删:直接将数据传输到目标端,在目标端进行分块、计算指纹并查重下盘。
需要说明的是,在一套存储设备中,上述重删方式不是孤立的存在,通常都是几种方式的组合。如在备份场景中,一般都采用在线、变长、块级、目标端(或者源端)重删的方法。
3. 重复数据删除与数据压缩的区别与联系
数据压缩是一种字节级的数据缩减技术,其思想是采用编码技术,常用的如Huffman编码,将较长的数据用较短的、经过编码的格式来表示,以此达到减少数据大小的目的。
从效果上来看,可以认为重复数据删除是一种基于“数据块”的压缩,而数据压缩是一种基于“字节”的重复数据删除。
从应用上来看,重删和压缩通常会配合起来一起使用。如在备份场景中,为了提高数据的缩减效率,在数据经过重删之后会对唯一数据块再执行一次压缩。这样,数据的缩减效果就是重删和压缩效果的叠加。


