【RDMA】18. RDMA之MPA(Marker PDU Aligned framing)
简略
MPA负责在TCP层的负载中标记和识别出DDP Segment的边界,起到承上启下的作用,使得DDP及其上层协议可以适配TCP/IP协议栈。
正文
转自:https://zhuanlan.zhihu.com/p/435467605 作者:Savir
本文欢迎非商业转载,转载请注明出处。
我们在之前的文章中介绍了iWARP协议栈中的DDP和RDMAP层,它们分别起到了实现零拷贝和向上层提供RDMA语义的功能。本文中,我将给大家介绍iWARP协议栈中的最后一层,也是最复杂的一层——MPA。它负责在TCP层的负载中标记和识别出DDP Segment的边界,起到承上启下的作用,使得DDP及其上层协议可以适配TCP/IP协议栈。
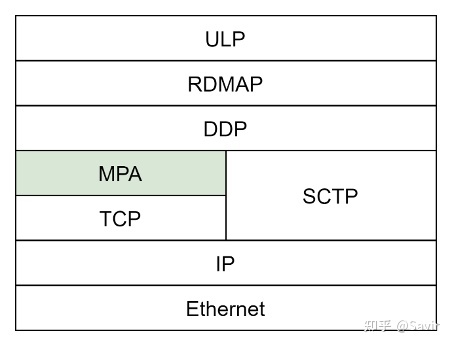
MPA在iWARP协议栈中的位置
阅读本文前,建议回顾下《DDP》一文。
概述
MPA的全称是Marker PDU(Protocol Data Unit) Aligned framing,其作为适配层,在基于消息的DDP和基于字节流的TCP协议间做转换。
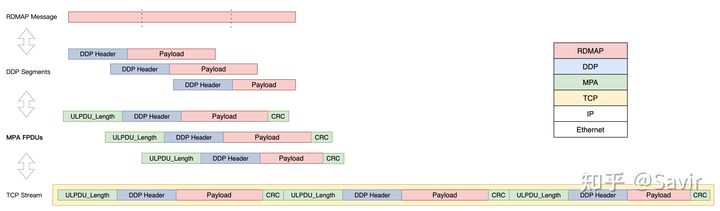
注意图中并没有表示出RDMAP Header,TCP Header等
读者可能会问“基于流”和“基于消息”是什么意思呢?它们是在计算机网络中传输信息两种模式,基于流的模式被称为Stream-based或者Bytestream-based,基于消息的模式被称为Message-based。它们的区别在于从协议的上层用户的视角来看, 数据是如何被协议"组织"到一起的。
基于流的协议
说到流,我们很容易想到水流和电流这种在某种通道里连续不断流动的介质,数据流也是如此。基于流的协议就像打电话,信息是连续不断的。
这种模式最典型的例子就是TCP协议,对于TCP层的ULP来说,它把数据交给TCP缓冲区后,TCP按照分段规则将其分段后交给IP层,这个分段大小与ULP的数据长度没有任何关系。TCP不关心数据的分界,它只保证数据能够准确、按照顺序的到达。至于如何分割和解析数据,那是上层用户的事情。
假如我们的应用想要发送“Hello World”,“This is a test”两句话给对端,虽然在应用层它们是两个独立的句子,但是基于TCP时,它们会被视为一条流,然后按照TCP的规则进行分段。接收端的用户可能从TCP层接收到前后三个分段“Hello Wo”、“rldThis i”、和“s a test”,即一系列有序的分段,这些分段连在一起就是字节流。当然,也可能被分段成”Hell","o Wo","rldT",“his ”,"is a",“ tes”和“t"或者其他不等长的形式。
但是无论中间怎么分段,从接收端的ULP来看,TCP层将分段还原之后传递给它的报文都是:“Hello WorldThis is a test ”,两个句子“黏”在了一起。此时必须依靠ULP自己的能力来将这个流还原成原本的信息,比如提前在其中加入标点符号分隔符等手段。
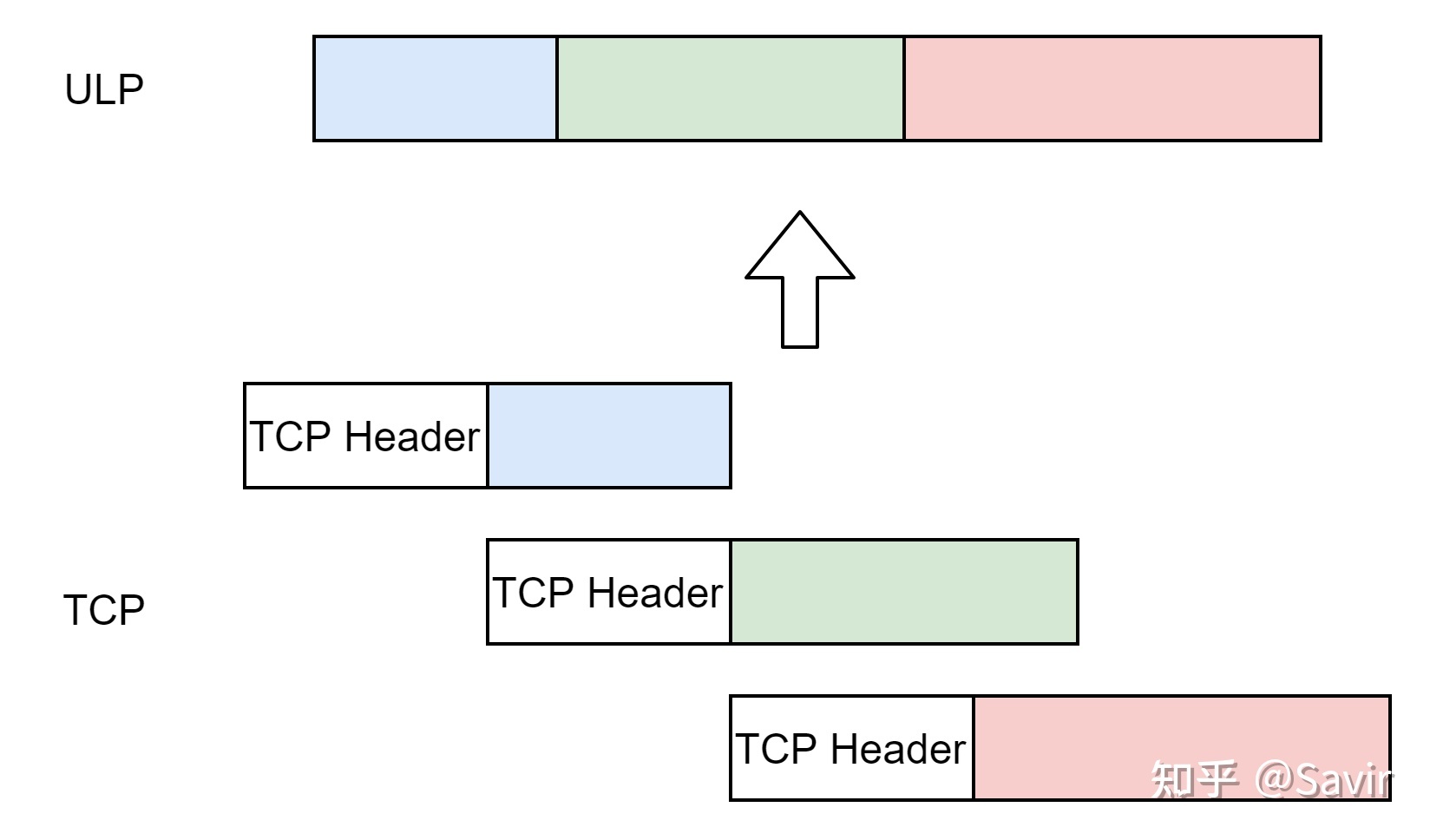
基于消息的协议
基于消息的协议就像是发短信,每一条短信都是完整而独立的。
这种模式一个典型的例子就是UDP,对于使用UDP协议通信的两端的ULP来说。发送端每次发送的数据有多长,接收端收到的就有多长;发送端发送几个消息,接收端就会接收几个消息。
而如果基于UDP的话,发送端如何分隔信息,接收端还会原封不动的收到信息,只是不保证顺序。还是举上面的例子,接收端一定会收到两个数据报:“This is a test”,“Hello World”。消息一定是有头有尾的到达的,至于顺序和可靠性,需要上层来保证。
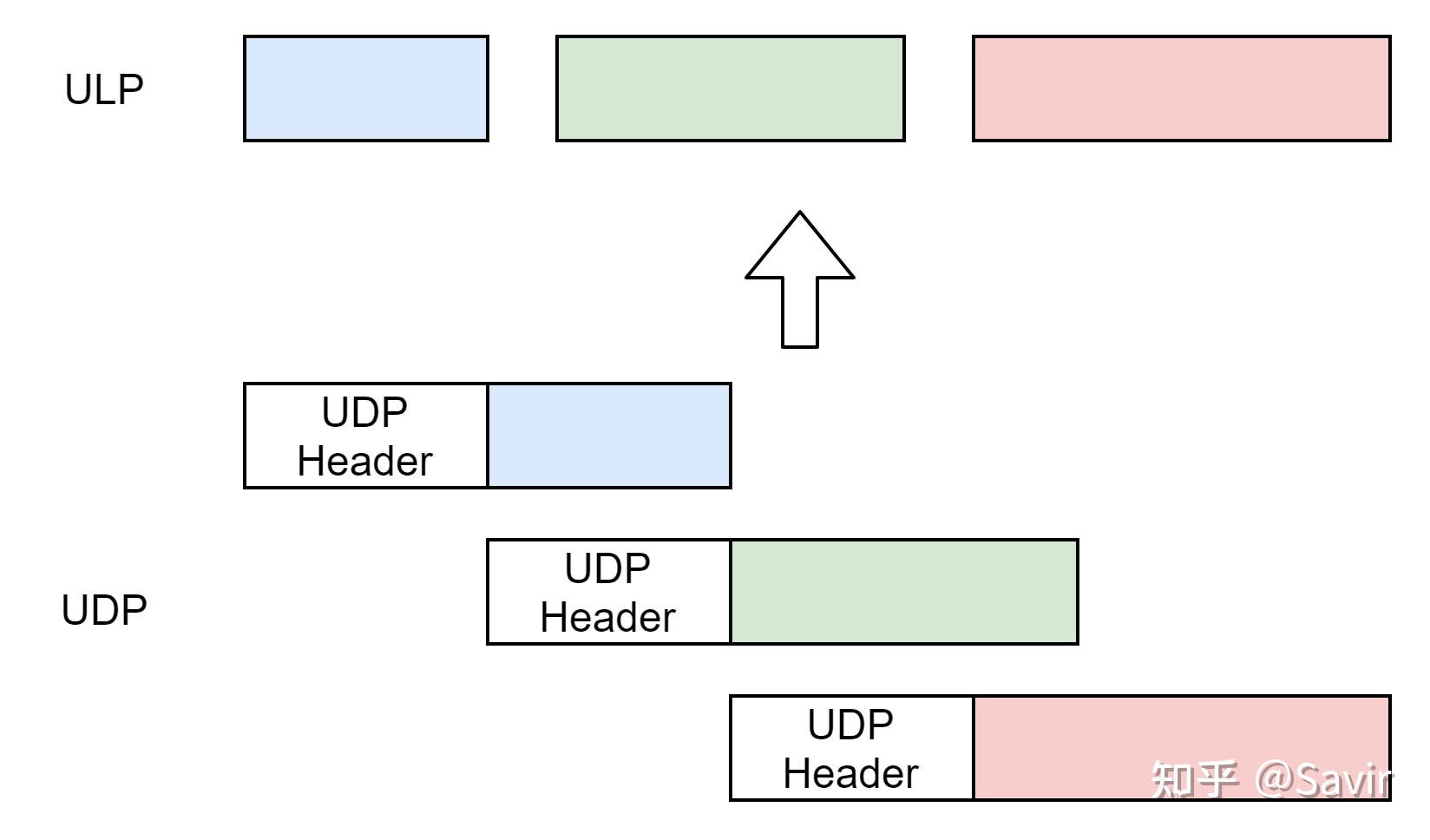
iWARP协议栈中的DDP层就是一种基于消息的协议,接收端的网卡每收到一个DDP分段,都可以根据其内容进行内存拷贝工作。
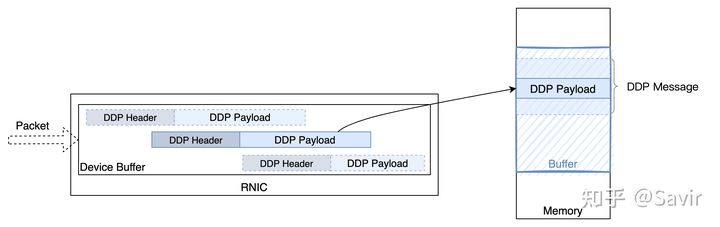
在有了上面的背景知识之后,我们很容易就能发现DDP over TCP面临的问题:DDP是以Segment为单位的,每个Segment都承载了一些Payload,但是它的Header中没有定义Payload长度。而TCP流是没有边界的,即使在流上只有一个DDP Segment的时候,接收端也无法知道Header后的Payload有多长,自然无法恢复数据。更何况大部分情况下,一个流上都会有多个DDP Segment,除了第一个Segment的Header之外,其他的Segment是无法定位出来的。下图是一条TCP流上首尾相连的多个DDP Segment(上帝视角):

但是从接收端ULP的视角看,从TCP层拿到的数据是下图这样的,没有边界,不知道该从哪里如何解析:

那么如何解决这个问题呢?有两种主流的思路:
- 在报文中插入固定值来方便定位分段,比如在每个DDP Segment之间插入一串约定好的bit,比如“0101 1010”,这样接收端每次检测到这个比特序列,都认为是DDP Segment的边界。但是DDP本身是可以携带Payload的,Payload由ULP传入,包含任何序列都是可能的,这种方法极有可能导致接收端的混淆。

- 在字节流的固定位置插入信息,方便接收端能够还原出原始的分段。原理如下图所示,两端都遵守协议的规定,那么收端就可以去约定好的位置去读取控制信息,然后识别出DDP Segment的边界。比如根据一个Control Field中的信息,推知下一个Control Field的位置。

本文的主角MPA协议便使用了后面这种方式,更具体地说,它主要是通过两种手段来实现的:
- 在每个DDP Segment前加入头部,标记DDP Segment的长度,这样接收端按照顺序处理TCP流时,就可以一个接一个的还原出每个DDP Segment了。

- 在约定好的位置插入被称为Marker的特殊标记,在乱序接收(见下文)时,Marker中包含的信息可以帮助接收方定位出最近的DDP Segment的头部,从而可以先完成一部分内存搬移工作,提高处理效率。
除此之外,MPA还加入了CRC校验机制,我们在下文再展开讲。
至于为什么DDP协议不自带长度等信息,我觉得是因为DDP被设计还可以应用于SCTP等这种能够帮助划分其界限的协议,而对于不能分界的TCP,就加一个中间层MPA来解决。DDP专注于指导数据搬移,MPA专注于识别DDP的边界,这是分层思想的一种体现。
术语
老规矩,我们先交代一下必须要了解的术语。
FPDU
Framed Protocol Data Unit,就不强行翻译了。Framed Protocol指的是MPA这层协议,所以FPDU指的就是MPA这一层的数据单元。从MPA这一层来看,它的包是以FPDU为单位的。
ULPDU
Upper Layer Protocol Data Unit,上层协议的数据单元。指的是MPA的上层传递给MPA这一层的数据的单位。在iWARP协议栈中,自然就是DDP层的数据单元,也就是DDP Segment。
FPDU是在ULPDU的基础上加上MPA头和CRC校验等控制信息得到的:

从数据包的角度看FPDU和ULPDU的关系

RFC 5044中关于ULPDU和FPDU的关系示意图
我们可以注意到每种协议都会定义Data Unit,只不过命名的方式不一样。比如TCP叫Segment,IP和UDP叫Datagram,以太网链路层叫Frame等等。我们理解FPDU和ULPDU时,跟它们做类比即可。
MULPDU
Maximum ULPDU,指的是DDP可以传给MPA层的最大ULPDU长度。为什么要有这个值呢,因为MPA的设计思想是尽量让一个TCP Segment可以容纳整数个FPDU,否则TCP分段可能导致一些DDP Segment被截断后放到两个TCP Segment中,这增加了iWARP接收端的处理难度,我们会在后文详细描述。MULPDU的值是从MPA传递给DDP层的的,DDP的Segment长度(传递给MPA层)不应该超过MULPDU。
EMSS
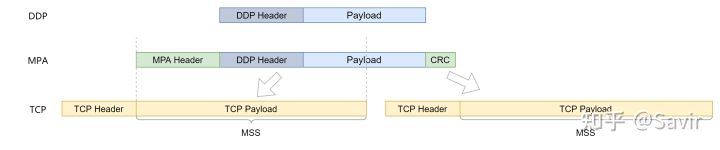
Effective Maximum Segment Size,有效最大分段的尺寸。在RFC 5044中,我们会取链路层的MTU和TCP层的MSS的最小值作为EMSS。MPA层会根据EMSS减去控制域段的长度,得到MULPDU之后将其传递给DDP层。当FPDU大于EMSS时,就一定会被分段,这不利于接收端的处理。
下图就是一个DDP加上MPA层的控制信息后大于TCP层的MSS,不得不被拆分的例子:
乱序接收(Out of order)
有些情况下数据包因为从源到目的地存在多条路径,会导致一个TCP流的不同TCP Segment不会按顺序到达目的地。而因为TCP本身是要保证顺序的,传统的TCP协议栈如果先收到后面的Segment,就只能先缓存下来,等到前面所有的Segment都到达之后再上送给上层的协议处理。
比如下图这个例子,虽然发送端按照顺序1、2、3发出了数据包,但是因为这几个包走的路径不同,导致到达的顺序变成了2、3、1。如果接收端不支持乱序接收,那么就需要把2和3先缓存下来,等1到达后再给ULP。
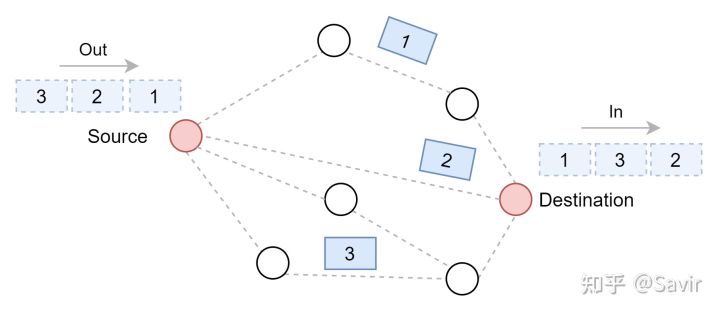
而支持乱序接收的TCP协议栈,可以先把后面的收到的Segment先送到上层。这一点对于DDP格外重要,因为每个DDP Segment都可以独立解析并且执行对应的内存搬移动作,不需要等待后续报文的到达。当然,只有完整的DDP Segment才会被送往上层,如果是片段的话,也要先缓存下来。
所以乱序接收这项技术,一方面节省了缓冲区空间,另一方面节省了ULP无事可做的时间,也就降低了总的处理时间。
报文格式
下面我们来看一下MPA的报文格式。
FPDU
我们在前文说过,FPDU是MPA这一层的数据单位。每个FPDU都是下面这个样子:

它由固定的几部分组成:
- ULPDU_Length - Upper Layer Protocol Data Unit Length: 2 Bytes
后面紧跟着的ULPDU的字节数,不包含CRC,PAD和其中的Marker。 - ULPDU - Upper Layer Protocol Data Unit: 1 ~ 64768 Bytes
即上层的DDP传递给MPA层的Segment的长度。受限于TCP over IP的最大IP数据包长度65536,去掉各种头部之后,ULPDU最大长度为64768。 - PAD: 0~3 Bytes
顾名思义,Pad本身有填补的意思,这个域段必须为全零,用于将ULPDU_Length和ULPDU不足4字节整数倍的长度补齐,以用于CRC校验。比如PAD前面的总长度是26个字节,那么就需要补2个字节的PAD,以达到28字节。 - CRC - Cyclic Redundancy Check: 4 Bytes
CRC32校验,用于保证数据传输的过程中没有错误产生。由两端协商是否启用,不启用时需要填0。校验的内容包括ULPDU_Length、ULPDU和PAD,以及属于该FPDU范围内的Marker。
从上面这些域段可以看出,不考虑Marker的话,MPA其实就是在DDP Segment外面“套了一层”长度信息和校验信息。
Marker
Marker用于让接收端的能够更高效的识别出FPDU的边界,它的结构很简单:

- Reserved: 16bits
保留域段,发送时必须设置为0。 - FPDUPTR - FPDU Pointer: 16bits
表示Marker的起始位置到ULPDU Length域段的起始位置的字节数。从命名就可以看出,它的作用是一个”指针“,指向了一个FPDU的头部。
举个例子,比如下图这个TCP的Segment,其中包含了前面一个FPDU的一部分Payload,以及一个完整的FPDU。这个分段中正好有一个Marker,那么接收方可以通过Marker来定位出后面那个完整FPDU的ULPDU_Length域段的位置,从而找到整个FPDU。然后由MPA提取出FPDU中的ULPDU,并交给DDP进行数据DMA拷贝。而遗留的属于前一个FPDU的Payload会在跟前一半拼成完整的FPDU之后再送给上层。

我们在前文中提到过,Marker是按照固定间隔插入到TCP流中的,RFC 5044中规定这个间隔为512 Bytes。所以在一条流中的Marker就是下图这个样子,每个Marker都指向其所归属的FPDU的头部。

除了上文描述的情况之外,还有几种特殊情况(M代表Marker):
Marker恰好在两个FPDU中间
则该Marker的FPDUPTR值为全0:

FPDU包含多个Marker
每个Marker必须都指向这个FPDU的的起始位置:

Marker之间包含多个FPDU
这些Marker指向各自所属的FPDU的首地址:

下面我们来举个例子,假如一次启用了Marker的MPA报文起始TCP Sequnce Number序列号是11,又因为Marker的间隔固定为512 Bytes,那么接收端就知道TCP序列号为11、523(512 + 11),1035(512 * 2 + 11)处一定是Marker。假设第二个Marker的值为0x00 00 00 0C,那么TCP序列号为523 - 12 = 511处一定是FPDU的头部,即ULPDU_Length域段的第一个字节的位置:

FPDU对齐
在详细描述通信流程之前,我们还必须了解一个重要的概念——FPDU对齐。所谓FPDU对齐,指的是FPDU的起始位置和TCP Payload的起始位置重合,而且这个TCP Segment中可以有整数个FPDU。
假设我们的一条TCP流上有三个连续的TCP Segment,下图是FPDU对齐的情况,可以看到每个TCP Segment都正好包含了整数个FPDU:
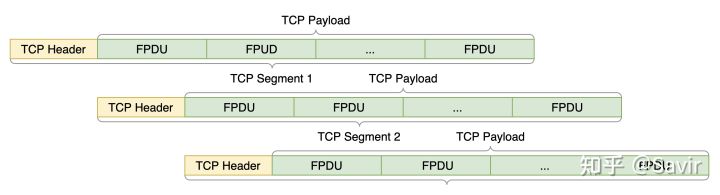
FPDU对齐
而下图是FPDU未对齐的情况,可以看到每个TCP Segment中都有FPDU被“拦腰截断”:
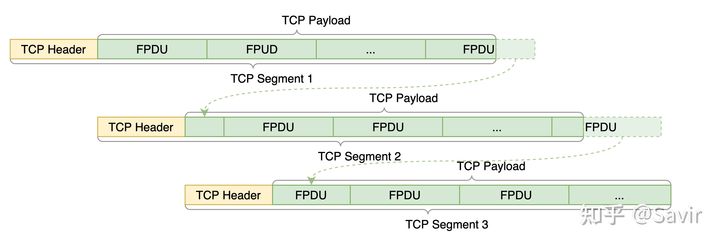
FPDU不对齐
FPDU对齐与否对接收端而言很重要。因为当不对齐的时候,接收端需要把很多不完整的FPDU片段存起来,等待它的另一半到达。在乱序接收的场景下,FPDU不对齐可能导致接收端耗费大量的缓冲区来存放FPDU片段,并且还原出完整的FPDU还需要额外的时间,这对时间和空间都造成了浪费。
所以发送端应该尽量保证FPDU对齐,通过上文中提到的EMSS来计算出合适的MULPDU传递给DDP层,以保证DDP Segment的大小合适,从而在加上MPA的各种控制域段之后,不会超过TCP层的MSS(不切分数据的上限)以及以太网链路层的MTU。
流程
背景知识都介绍完了,下面我们来讲一下MPA的收发两端是如何交互的。
作为一种RDMA协议,iWARP和RoCE/IB一样,实际应用时都应该是在网卡内部实现的。也就是说不仅RDMAP、DDP、MPA这三层,TCP和IP层也是由硬件完成的,而不是用标准的TCP/IP协议栈。这样硬件厂商们就可以选择专门针对iWARP进行优化,从而提高数据收发效率。
下文我们讲解流程的时候,会根据RFC 5044中的描述,分为非优化版本和优化版本的iWARP协议栈。
所谓“优化”,指的是将MPA层和TCP层实现在一起。下图是一个基于标准TCP/IP协议和Socket接口的MPA层,可以看到MPA和其他所有TCP的ULP一样,和TCP之间是完全独立的两层。
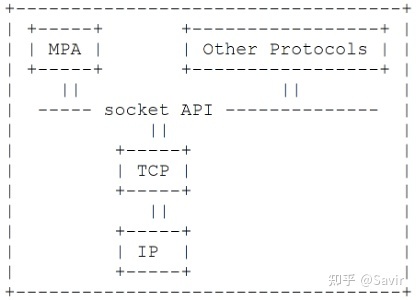
RFC 5044 Figure 7 完整的分层实现TCP/IP + MPA
这种实现的优点是不需要修改TCP/IP协议栈,相对简单。缺点有两个,一个是MPA层不知道TCP层的MSS,只能根据MTU计算MULPDU告知DDP层,这可能频繁的导致FPDU不对齐的情况,造成接收端的开销变大;另外一个缺点是,接收端无法支持乱序接收,也就是说,必须按照顺序把TCP Segment上送给MPA层,导致DDP层经常处于没有数据要处理的闲置状态,效率低下。
下图是优化后的TCP/IP + MPA,可以看到它们融合到了一起。普通的ULP仍然通过Socket API来和TCP/IP协议栈交互,而MPA则使用定制版本的TCP/IP。
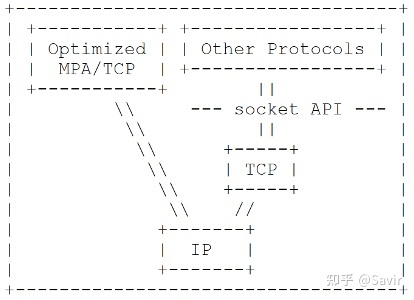
RFC 5044 Figure 11 优化的TCP/IP + MPA实现
这消除了基于标准TCP/IP实现的MPA的缺点:一方面,发送端MPA层可以知道此时TCP层的MSS,计算出EMSS,然后告知DDP层MULPDU。DDP层下发的Segment加上MPA的控制域段后再由TCP层处理为TCP Segment的时候,就能避免FPDU不对齐的情况。这样接收端就不用缓存大量的不完整的FPDU;另一方面,接收端可以支持乱序接收,收到任意TCP Segment之后,就可以交由MPA识别出其中完整的FPDU,然后给DDP层进行数据搬移,提高了处理效率。当然,也不是没有缺点,那就是需要对TCP/IP进行重新设计,实现难度较大。
发送方行为
- MPA + 标准TCP
在使用标准TCP/IP协议栈时,发送方的行为如下:
- 计算MULPDU并告知DDP,TCP可能不支持上报MSS,这种情况下会根据MTU计算。
- DDP根据MULPDU下发ULPDU给MPA。
- MPA生成FPDU:计算ULPDU_Length、插入Marker、补齐PAD到4字节整数倍,计算并加入CRC。
- MPA将FPDU传送给TCP层。
发送方会尽量保证对齐,但是当ULPDU小于MULPDU等情况下,仍然会造成对齐丢失。
下面我们举个例子,如下图所示,一共有三个待发送的DDP Segment。MPA层给他们加入ULPDU_Length、CRC和Marker(PAD省略未画出)之后,下发给TCP层。但是当前的ULPDU小于MULPDU,并且TCP的MSS中无法放入整数个FPDU时,那么后面一个FPDU就会被“截断”,一部分放入第一个TCP Segment,一部分放入第二个TCP Segment。从第二个TCP Segment开始,我们失去了FPDU对齐。

如何恢复FPDU对齐? 可以等待发送缓冲区中的内容都发送出去之后再下发FPDU,或者通过动态调整MULPDU来“修复”不对齐的问题。
- MPA + 优化的TCP
优化后的发送方行为如下:
- TCP层可以将当前的EMSS告知MPA层用于计算MULPDU,并知会DDP。
- DDP根据MULPDU下发ULPDU给MPA。
- MPA生成FPDU:计算ULPDU_Length、插入Marker、补齐PAD到4字节整数倍,计算并加入CRC。
- MPA将FPDU传送给TCP层,保证每个TCP Segment都是FPDU对齐的。(有些特殊情况,比如MTU改变,也可能导致对齐丢失)
这样一来,除了MTU改变的特殊情况,FPDU一直都是对齐的。还是上文的例子,当到第二个DDP Segment时,MPA会提前根据当前TCP MSS中剩余的空间,动态修改MULPDU并告知DDP层。这样当DDP就会调整Segment中Payload的大小,在一个TCP Segment中保持完整,不会被“截断”。

接收方行为
- MPA + 标准TCP
MPA + 标准TCP不支持乱序接收,TCP也不感知MPA的存在,TCP Segment必须按序处理。即某个TCP Segment必须等待前面的Segment都到达之后,才能上送给MPA处理。
因为数据是连续的,第一个TCP Segment的头部一定是FPDU起始位置,所以可以不依赖Marker找到每一个FPDU。也就是说,这种情况下,Marker是没有什么意义的(但是用户仍然可以选择启用)。
MPA通过ULPDU_Length和CRC确认完整性之后,就可以剥离控制域段,将ULPDU上送给DDP处理。DDP根据Header来搬移数据。
如果当前的FPDU不完整/后面的Segment先到达,则需要一个缓冲区来暂存收到的FPDU的片段,然后需要等待关联的Segment到达之后,还原出完整的FPDU再上送给DDP。
下面我们来举个例子,如下图所示,TCP Segment 1和2是两个连续的TCP分段。假如接收端先收到了TCP Segment 2,因为不支持乱序接收,所以需要将整个分段中的Payload都缓存起来。等收到前一个Segment 1之后,才可以开始处理给MPA层的消息。

收到TCP Segment 1后,因为第一个分段一定是FPDU对齐的,所以可以从中中取出一个FPDU,上送给MPA。紧接着处理下一个FPDU,通过校验ULPDU_Length发现其不完整,那么就根据TCP的Sequence Number(可以理解为每个字节按照顺序的编号)从缓冲区中找到这个FPDU的剩余部分,拼完整了之后再上送MPA。
之后,再根据TCP的Sequence Number找到下一个FPDU,从缓冲区中将其取出做完整性校验后会上送给MPA。
可以发现这种情况下,MPA一直是像”接龙“一样按顺序处理FPDU的,效率很低。并且如果乱序到达的TCP Segment很多的话,接收端需要申请大量的缓冲区来存放提前到达的分段。
- MPA + 优化的TCP
MPA + 优化的TCP支持乱序接收,即收到任意TCP Segment之后,一旦有完整的FPDU,就可以上送DDP。
通过Marker定位出其所属的FPDU,然后检测FPDU的完整性和CRC,如果合法则剥离控制域段后发送给DDP。
同一个Segment中,一个完整FPDU之后一定是另一个FPDU的起始位置,接收端按照这个逻辑依次处理后面的FPDU。
无法定位头部的部分/不完整的部分将会暂存到缓冲区中,等待剩余部分到达后再进行FPDU的还原。
还是举上文中的例子,但是要强调一个原则,无论是否是优化的MPA/TCP,接收端都不能假定每一个收到的包都是FPDU对齐的。因为总会有一些情况,比如用户改变MTU等会导致FPDU不再对齐。实际优化版本的MPA/TCP,是几乎不会出现TCP Segment 2中FPDU不对齐的情况的,本例子只是极端情况。

假如我们先收到了TCP Segment2。接收端因为知道哪个位置会有Marker(根据字节序号),所以可以直接去读这个Segment中Marker的值。然后它会发现Marker指向的ULPDU_Length,经过校验,发现这是一个完整的FPDU,那么可以直接由MPA剥离控制域段后上送DDP层进行数据搬移了。
如果在TCP Segment 2中,这个FPDU后面还有内容,那么可以继续解析,直到没有完整的FPDU为止。而这个FPDU之前的Payload以及之后不完整的FPDU会被暂存到缓冲区中,等待剩余部分的到达。
之后接收端收到了TCP Segment 1,TCP/MPA同样可以根据Marker或者是首个包来找到FPDU,并剥离MPA控制域段后送给DDP。剩余不完整的FPDU会和缓冲区中的片段拼接完整,然后上送给DDP。
我们可以发现,优化的MPA/TCP,一方面所需要的缓冲区减少了,另一方面DDP不用按顺序处理Message了,因此效率有较大的提升。
到这里MPA收发流程我们就介绍完了,下面我们介绍一下使用MPA协议的两端是如何开始工作的。
协商
RFC 5044中定义了MPA层的协商流程,相对篇幅比较多,所以这里单独作为一个章节描述。
MPA这一层存在的意义是识别和分隔DDP Segment,对于非DDP业务,也就是普通的TCP流量来说,如果MPA被错误的启用,那么它可能会识别出错误的信息,造成ULP业务的混乱。因此通信的两端是需要通过“握手”来确认什么时候MPA启用,什么时候MPA未启用,以及一些额外的控制信息,比如MPA需不需要CRC校验,Marker有没有使能等等。所谓“握手”,也称作“建链”,就是通过约定好的报文格式和交互顺序,来交换一些控制信息,并且对这些控制信息进行维护。
我们把MPA启用(即建链)前后分别称为Startup Phase和Full Operation Phase两个阶段。

Startup Phase
初始化阶段,或者叫Stream模式。这个阶段中TCP流就是普通的流,可以传输任何上层信息。这时候两端的MPA尚未启动,可以交换一些链接配置信息。
Full Operation Phase
完全操作阶段,或者叫DDP/MPA模式,亦或是RDMA模式。这个阶段表示建链完成,MPA可以开始交换FPDU了,也就是完成了从基于流到基于消息的转换。进入这个阶段之后,对应的TCP流之上只能传输MPA的报文。如果想恢复普通业务的传输,需要退出MPA模式才可以。
这两个阶段的含义相对比较好理解,我们来看一下协商是如何进行的:
协商报文

- Key: 16 Bytes
固定格式的消息标识符,用于区分MPA的请求和MPA的回复。内容很简单,就是”MPA ID Req Frame“和”MPA ID Rep Frame“对应的ASCII码。 - M - Marker Enable: 1 bit
用于告知对端是否使能Marker。收到MPA Request Frame/Reply Frame的节点,如果发现Frame中的M为0,那么发往对端的MPA报文中就不能携带Marker了。 - C - CRC Enable: 1 bit
标识是否使能CRC校验。跟Marker不一样,只要建链的两端有一段置了这个标记,那么两端都必须产生和校验CRC。 - Private Data:0~512 Bytes
私有数据,可以包含任何ULP数据。接收端的MPA层会把协商报文中的Private Data上送给ULP,由ULP判断是否接受其中描述的参数或者其他信息,如果不接受的话可以拒绝连接。这里面可以携带比如最大可以处理的Read Request请求数量等等配置信息。 - PD_Length - Private Data Length: 2 Bytes
表示Private Data域段的长度,如果该域段和Private Data的实际长度不符或者Private Data的长度超过了512字节,则要断开连接并报错。 - R - rejection: 1 bit
表示拒绝连接。在MPA Request Frame中固定为0。而在发送MPA Reply Frame的一端,如果不同意发送连接请求的一端在MPA Request Frame报文Private Data域段携带的参数,则将回复报文中的这个标记置为1。 - Res - Reserved: 5 bits
保留域段。 - Rev - Revision: 8 bits
MPA协议的版本,RFC 5044中固定为1。
协商流程
根据建立连接的时机,协商分为两种:立即协商和延迟协商。
立即协商
又称为Immediately Startup,是在下层的TCP连接建立好之后立即切换为DDP/MPA,不需要在流模式下进行协商。两端需要提前约定一个端口号,或者使用SLP(Service Location Protocol,服务定位协议)来发现一个用于MPA通信的端口。
延迟协商
又称为Delayed Startup,是在下层的TCP连接建立之后的某个时刻才切换为DDP/MPA模式。中间这段”空窗期”,TCP流上承载的是普通的非MPA业务。当两端准备协商时,需要通过某些方式来知会对方(比如发一个特定格式的消息,协议中举的例子是“Hello")。
这两种协商方式的差别仅在于发起的时机和方式,其它的交互的步骤都是相同的。
我们将发起MPA协商的一端称为Initiator,响应的一端称为Responder。

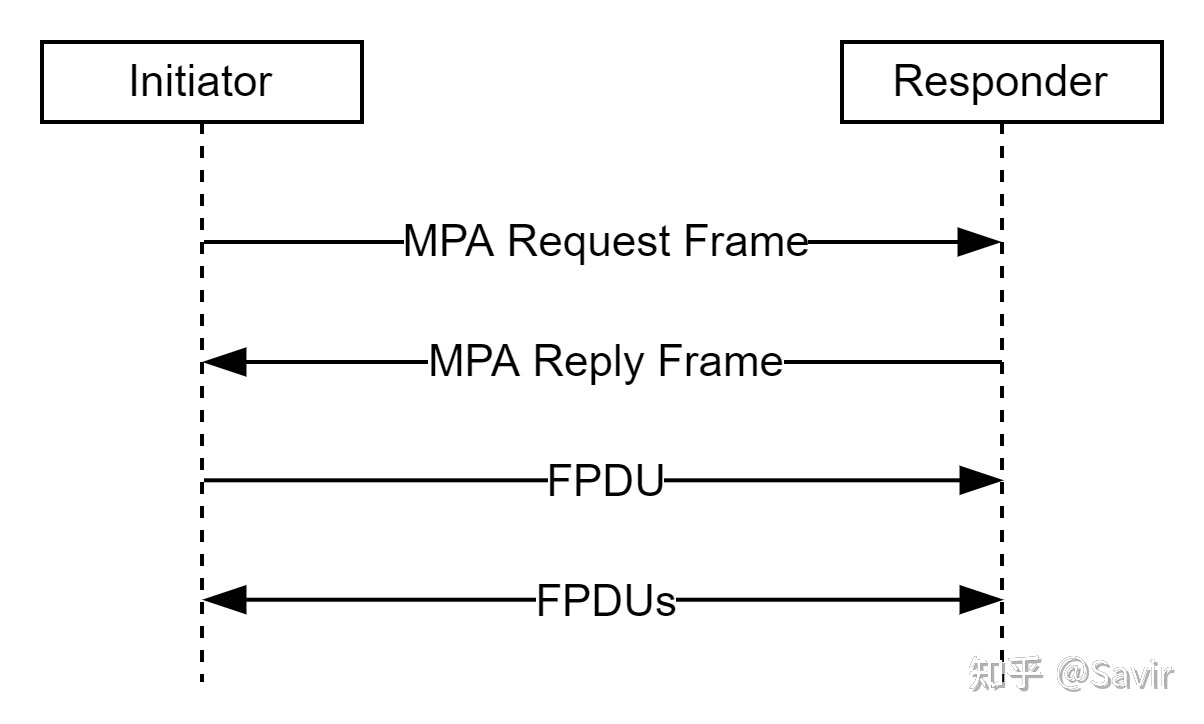
下面是协商步骤:
- Initiator发送一个MPA Request Frame,其中可能包含ULP提供的Private Data。
- Responder在进入MPA/DDP阶段前,必须一直等待MPA Request Frame,期间不能发送普通的TCP流。Responder还应该设置一个等待请求的超时时间,如果超过这个时间,就不再处理请求了。当收到MPA Request Frame之后:
- 如果MPA Request Frame格式不正确,Responder必须关闭TCP连接并且退出MPA。
- 如果MPA Request Frame格式正确,那么MPA会把Private Data传给ULP。但是如果ULP校验Private Data失败,那么MPA会回复一个R位为1的MPA Reply Frame(这个报文可以携带Private Data,说明错误原因或者携带其他信息),表示拒绝连接,然后退出MPA,但是保持TCP连接。ULP可以选择之后关闭TCP连接或者将TCP连接用于其他用途。
- 如果MPA Request Frame格式和内容都正确,那么回复一个R位为0的MPA Reply Frame,即为有效的连接。ULP可以在这个回复报文中携带Private Data。之后Responder应该准备接收对端发过来的第一个FPDU,它在接收和校验完一个FPDU之前不允许发送FPDU(因为对端可能还没准备好)。
- Initiator必须准备接收和校验MPA Reply Frame,当收到Reply之后:
- 如果格式不正确,Initiator必须退出MPA并且关闭TCP连接。
- 如果格式正确,但是给ULP的Private Data不正确,或者R位为1,则退出MPA,并且保持TCP连接。ULP可以选择稍后关闭TCP连接或者将TCP连接用于其他用途。
- 如果格式正确,Private Data也正确,则进入MPA/DDP Operation Phase。Initiator可以开始发送FPDU了。
上面的过程如下图所示:
额外说一句,经过对软件协议栈的观察,在libibverbs库中,iWARP协议的CM建链就是通过MPA协商实现的。
示例
因为Soft-iWARP不支持Marker:

drivers/infiniband/sw/siw/siw_cm.c
另外我手上暂时没有支持iWARP的网卡,所以也没有条件抓带marker的数据包。这次我们从Wireshark的官网直接看一下抓好的报文,请大家从以下链接获取,下载下图中的iwarp_rdma.tar.gz:
SampleCaptures · Wiki · Wireshark Foundation / wireshark · GitLab

用wireshark打开压缩包里面的read_write_long_run_mrkr,这是一个带Marker的长RDMA Write和RDMA Read的示例。
协商
首先可以看到在TCP的SYN之后紧接着就是MPA的Request,所以这是一次立即协商流程。

下面看MPA Request Frame,请求端使能Marker,不使能CRC,携带了7 Bytes的Private data,但是其具体是什么含义我们是解析不了的:
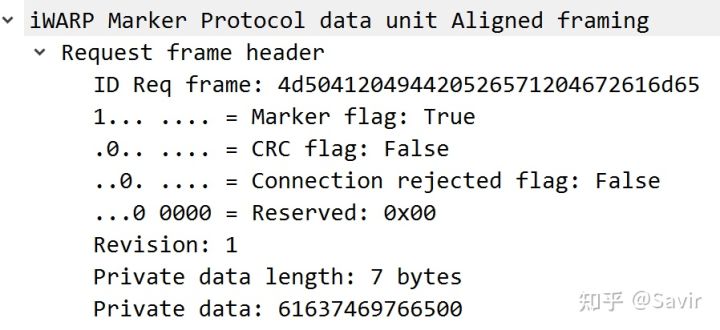
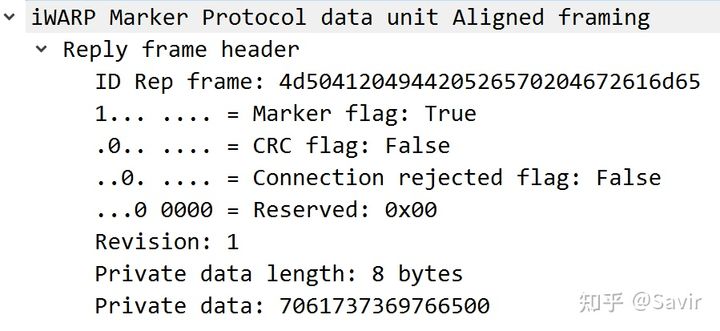
接着是MPA Reply Frame,回复的参数和请求端的请求中相同,Rejected标志也没有置位。所以协商的结果就是使能Marker,不使能CRC:
数据收发
最后我们随便找一个Write/Read的报文,可以看到DDP和RDMAP上层是MPA的控制域段。其中ULPDU_Length域段指出了后面不包含Marker的部分总长度为1038 Bytes;因为没有使能CRC,所以CRC这部分为全0:
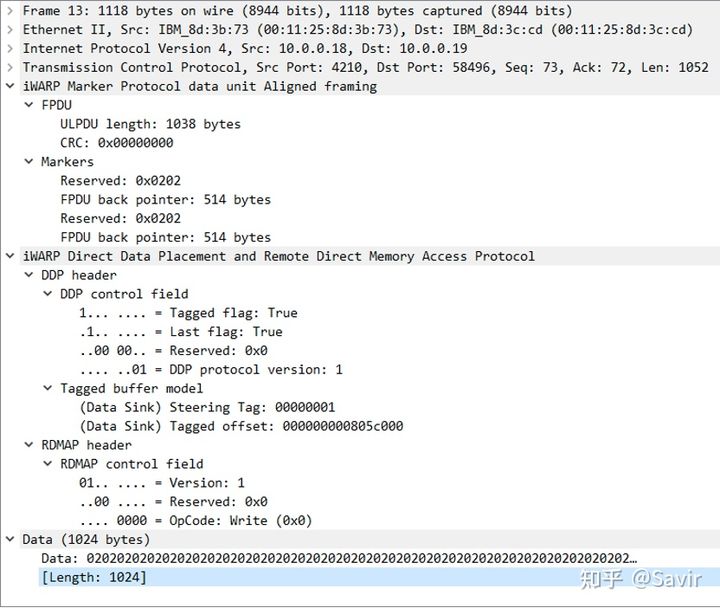
这个FPDU中有两个Marker,然后问题来了,这两个值相等的Marker明显是有问题的。首先,Reserved域段竟然不是零,另外这个TCP Segment中只有一个FPDU,也就是只有一个头部,而根据RFC 5044的描述,如果一个FPDU中有两个Marker,那么他们都指向这个FPDU的头部。而又因为Marker之间的距离恒为512Bytes,所以他们之间的值的差一定是512,不可能相等。
下图是这个包的Data部分,绿色为Wireshark识别的Marker,而紧跟在后面的两个用红色标记的4字节“0x 00 00 d8 01”和“00 00 d8 03”明显更符合Marker的格式。

把FPDU Pointer域段倒过来,即0x01D8和0x03D8,他们的间隔正好是512Bytes。第一个Marker的起始位置为0x21A,减去0x1D8之后的结果为0x42,另一个Marker也是一样,0x41A - 0x3D8 = 0x42,这个值正好是FPDU的起始位置。。。


另外,Data域段都是0x02的循环,更印证了我们的猜想。关于Wireshark对iWARP的支持,网上也能搜索到一个BUG的报告:
Wireshark中关于iWarp报文解析的两处bug | Chenny的Blog (chrtech.com)
所以结论是,要么是Wireshark对iWARP的协议支持有问题,要么是官方提供的示例包有问题,希望大家不要被误导。笔者发现问题之后已经在Wireshark的社区提了一个Issue,等待社区大佬回复后我会把最新进展更新到本篇文章。
至此,iWARP协议栈就给大家介绍完了。至于更多内容,包括重传、错误处理、保序机制等还请读者查阅几个RFC中的描述,由于精力和时间有限,就不给大家详细讲解了。
下一篇我将完成iWARP的综述,介绍一下它的历史和发展情况。
参考资料
[1] RFC 5044
[2] 关于基于流和基于消息的解释. 如何理解传输层的TCP面向字节流,UDP面向报文?二者是以是否会分段(mss)来定义? - 知乎
编辑于 2021-11-20 01:29


 浙公网安备 33010602011771号
浙公网安备 33010602011771号