

【Ceph】Ceph快照的原理和实现--未消化
快照原理
1、先了解一下文件系统的知识
https://blog.csdn.net/bandaoyu/article/details/125375996?spm=1001.2014.3001.5501
2、快照原理
https://blog.csdn.net/bandaoyu/article/details/120421383
实现
原文:https://docs.ceph.com/en/quincy/dev/cephfs-snapshots/
CephFS 支持快照,通常通过在 .snap目录中调用 mkdir 创建。请注意,这是一个隐藏的特殊目录,在目录列表中不可见。
1. OVERVIEW
通常,快照会像听起来那样做:它们在拍摄时创建文件系统的不可变视图。CephFS 快照的一些重要特性与您的预期不同:
-
任意子树(Arbitrary subtrees):快照在您选择的任何目录中创建,并覆盖该目录下文件系统中的所有数据。
-
异步(Asynchronous):如果您创建快照,缓冲的数据会被延迟刷新,包括来自其他客户端的数据。因此,“创建”快照非常快。
2. 重要的数据结构
-
SnapRealm:
每当您在新的位置创建快照时(或当快照索引节点移动到其父快照之外时),都会创建SnapRealm。SnapRealms包含一个sr_t srnode,以及作为快照一部分的inodes_with_caps。客户端也有一个SnapRealm概念,它维护的数据较少,但用于将SnapContext与每个打开的文件关联起来for写入。
-
sr_t:sr_t是磁盘快照元数据。它是containing目录的一部分,包含序列计数器、时间戳、关联快照 ID 列表和past_parent_snaps。
-
SnapServer:SnapServer 管理快照ID分配、快照删除和文件系统中有效快照的跟踪列表。一个文件系统只有一个 snapserver 实例。
-
SnapClient:SnapClient 用于与 snapserver 通信,每个 MDS rank 都有自己的 snapclient 实例。SnapClient 还会在本地缓存有效的快照。
3. 创建快照
CephFS 快照功能在新文件系统上默认启用。要在现有文件系统上启用它,请使用以下命令。
$ ceph fs set <fs_name> allow_new_snaps true
启用快照后,CephFS 中的所有目录都会有一个特殊 .snap目录。(如果您愿意,可以使用client snapdir设置配置不同的名称。)
要创建 CephFS 快照, 请使用您选择的名称创建一个.snap子目录。例如,要在目录“/1/2/3/”上创建快照,调用mkdir /1/2/3/.snap/my-snapshot-name。
客户端会将带有 CEPH_MDS_OP_MKSNAP 标记的MClientRequest传输到 MDS 服务器,最初在 Server::handle_client_mksnap() 中处理。它从 SnapServer 分配一个 snapid,用新的SnapRealm投射一个新的 inode,利用新的 SnapRealm创建并链接一个新的inode,然后将其提交到 MDlog,提交后会触发 MDCache::do_realm_invalidate_and_update_notify(),此函数将此 SnapRealm广播给所有对快照目录下任一文件有管辖权的客户端。它会通知所有客户端在“/1/2/3/”下的文件上限有关新的 SnapRealm。
客户端收到通知后,将同步更新本地 SanpRealm层级结构,并为新的SnapRealm结构生成新的 SnapContext,用于将快照数据写入 OSD 端。同时,快照的元数据会作为目录信息的一部分更新到OSD端(即sr_t)。整个过程是完全异步处理的。
请注意,这不是快照创建的同步部分!
To create a CephFS snapshot, create a subdirectory under <span class="pre">.snap</span> with a name of your choice. For example, to create a snapshot on directory “/1/2/3/”, invoke <span class="pre">mkdir</span><span> </span><span class="pre">/1/2/3/.snap/my-snapshot-name</span> .
This is transmitted to the MDS Server as a CEPH_MDS_OP_MKSNAP-tagged MClientRequest, and initially handled in Server::handle_client_mksnap(). It allocates a snapid from the SnapServer, projects a new inode with the new SnapRealm, and commits it to the MDLog as usual. When committed, it invokes MDCache::do_realm_invalidate_and_update_notify(), which notifies all clients with caps on files under “/1/2/3/”, about the new SnapRealm. When clients get the notifications, they update client-side SnapRealm hierarchy, link files under “/1/2/3/” to the new SnapRealm and generate a SnapContext for the new SnapRealm.
Note that this is not a synchronous part of the snapshot creation!
4. 更新快照
如果您删除快照,则会执行类似的过程。如果从其父 SnapRealm 中删除一个 inode,重命名代码会为重命名的 inode 创建一个新的 SnapRealm(如果 SnapRealm 不存在),将在原始父 SnapRealm 上有效的快照 ID 保存到新SnapRealm的 past_parent_snaps 中,然后遵循类似于创建快照的过程。
5. 生成 SNAPCONTEXT
RADOS SnapContext由快照序列 ID ( snapid ) 和对象已经属于的所有快照 ID 组成。为了生成该列表,我们将与SnapRealm关联的 snapid 和past_parent_snaps中的所有有效 snapid 结合起来。过时的 snapid被 SnapClient 缓存的有效快照过滤掉。
6. 存储快照数据
文件数据存储在 RADOS “自我管理”快照中。客户端在将文件数据写入 OSD 时要小心使用正确的SnapContext 。
7. 存储快照元数据
快照的 dentry(及其 inode)作为它们在快照时所在目录的一部分内嵌存储。所有的dentries 都包括它们对其有效的第一个和最后一个snapid。(非快照的 dentries 将其最后设置为 CEPH_NOSNAP)。
8. 快照回写
有大量代码可以有效地处理回写。当客户端收到MClientSnap消息时,它会更新本地SnapRealm 表示及其到特定Inode的链接,并为Inode生成CapSnap。CapSnap作为功能回写的一部分被刷新,如果有脏数据,CapSnap用于阻止新数据写入,直到快照完全刷新到 OSD。
在 MDS 中,我们生成代表快照的目录,作为刷新它们的常规过程的一部分。具有出色CapSnap数据的条目会被固定并保存在日志中。
9. 删除快照
快照通过在它们根目录的“.snap”目录上调用“rmdir”来删除。(尝试删除根快照的目录将失败;您必须先删除快照。)一旦删除,它们将进入 OSDMap列表被删除的快照和文件数据被 OSD 删除。当目录对象被读入和写回时,元数据被清理。
10. 硬链接
具有多个硬链接的 Inode 被移动到一个虚拟的全局 SnapRealm。虚拟 SnapRealm 覆盖文件系统中的所有快照。将为任何新快照保留 inode 的数据。这些保留的数据将涵盖 inode 的任何链接上的快照。
11. 多个文件系统
快照和多个文件系统不能很好地交互。具体来说,每个MDS集群独立分配snapid;如果您有多个文件系统共享一个池(通过命名空间),它们的快照会发生冲突,删除一个会导致其他文件数据丢失。(这甚至可能是不可见的,不会向用户抛出错误。)如果每个 FS 都有自己的池,那么事情可能会起作用,但这没有经过测试,可能不是真的。
12.实践
手动快照
创建快照:
从挂载 cephFS 的客户端,切换到要创建快照的目录。
[root@lab-ceph1 ~]# cd /mnt/cephfs/data/.snap
[root@lab-ceph1 data/]# cd .snap
[root@lab-ceph1 .snap]# mkdir new_snap_03-02-18
从快照中恢复文件:
从挂载 cephFS 的客户端,导航到要恢复文件的目录。
[root@lab-ceph1 ~]# cd /mnt/cephfs/data
[root@lab-ceph1 data]# cd .snap
找到正确的快照,
[root@lab-ceph1 .snap]# cd new_snap_03-02-18
找到要恢复的文件
[root@lab-ceph1 new_snap_03-02-18]# cp -R {file(s)} /mnt/cephfs/data
删除快照
[root@lab-ceph1 .snap]# cd /mnt/cephfs/data/.snap
[root@lab-ceph1 .snap]# rmdir new_snap_03-02-18
自动快照
使用cephfs-snap自动创建和删除旧快照。
下载文件到 /usr/bin
[root@lab-ceph1 ~]# curl -o /usr/bin/cephfs-snap http://images.45drives.com/ceph/cephfs/cephfs-snap
[root@lab-ceph1 ~]# chmod +x /usr/bin/cephfs-snap
配合cron 一起使用。{hourly,daily,weekly,monthly}
使用示例:
To take hourly snaps, and delete the old ones after 24, create a file "/etc/cron.hourly/cephfs-snap"
And place the following in the file
#!/bin/bash
cephfs-snap /mnt/cephfs/ hourly 24
To take monthly snaps and delete the old ones after 12 months, create a file "/etc/cron.monthly/cephfs-snap"
And place the following in the file
#!/bin/bash
cephfs-snap /mnt/cephfs monthly 12
创建的 cron 文件必须设置为可执行
[root@lab-ceph1 ~]# chmod +x /etc/cron.daily/cephfs-snap
要验证配置的 cron 任务是否会正确执行,请手动运行上述步骤中创建的 cron.* 脚本
[root@lab-ceph1 ~]# /etc/cron.daily/cephfs-snap
现在检查 .snap 目录中是否创建了 cephfs 快照
[root@lab-ceph1 ~]# ls -al /mnt/cephfs/.snap
如果 cron 没有按预期触发快照,请验证“/usr/bin/cephfs-snap”和“/etc/cron.*/cephfs-snap”文件是否可执行
参考文章:
https://docs.ceph.com/en/latest/dev/cephfs-snapshots
https://knowledgebase.45drives.com/kb/kb450160-cephfs-snapshots/
————————————————
摘抄自:https://blog.csdn.net/newtyun/article/details/123366908
转自:https://www.twblogs.net/a/5b82088d2b71772165af4e52
ceph的基本的特性之一,就是支持rbd的snapshot和clone功能。Ceph都可以完成秒级别的快照。
ceph支持两种类型的快照,一种poo snaps,也就是是pool级别的快照,是给整个pool中的对象整体做一个快照。另一个是self managed snaps. 目前rbd的快照就这类,用户写时必须自己提供SnapContex信息。
这两种快照时互斥的,两种不能同时存在。
无论是pool级别的快照,还是rbd的快照,其实现的基本原理都是相同的。都是基于对象COW(copy-on-write)机制。
本文举例时都用rbd实例。
基本概念和数据结构
head对象:也就是对象的原始对象,该对象可以写操作
snap对象:对某个对象做快照后的通过cow机制copy出来的快照对象,该对象只能读,不能写
snap_seq or seq:快照序号,每次做snapshot操作,系统都分配一个相应快照序号,该快照序号在后面的写操作的实现发挥重要的作用。
snapdir对象:当head对象被删除后,仍然有snap和clone对象,系统自动创建一个snapdir对象,来保存SnapSet信息。
在rbd端,librados/IoCtxImpl.h 定义了snap相关的数据结构
struct librados::IoCtxImpl {
......
snapid_t snap_seq;
::SnapContext snapc;
......
}
struct SnapContext {
snapid_t seq; // 'time' stamp
vector<snapid_t> snaps; // existent snaps, in descending order
}SnapContext 数据结构用来在客户端(rbd端)保存Snap相关的信息。这个结构持久化存储在rbd的元数据中。
seq 爲最新的快照序号
snaps 降序保存了该rbd的所有的快照序号。
IOCtxImpl里的 snapid_t snap_seq 一般也称之爲snap_id, 如果open时,如果是snapshot,那麽该snap_seq就是该snap对应的快照序号。否则snap_seq就爲CEPH_NOSNAP(-2),来表示操作的不是快照。
struct SnapSet {
snapid_t seq; //最新的快照序號
bool head_exists; //head對象是否存儲
vector<snapid_t> snaps; // descending //所有的快照序號
vector<snapid_t> clones; // ascending //所有的clone的對象
map<snapid_t, interval_set<uint64_t> > clone_overlap;
// clone對象之間overlap的部分
map<snapid_t, uint64_t> clone_size; //clone對象的size
}数据结构SnapSet用于保存server端,也就是OSD端与快照相关的信息。seq保存最新的快照序号,head_exists保存head对象是否存在,snaps保存所有的快照序号。clones保存所有快照后的写操作需要clone的对象记录。
这里特别强调的是 clones 和 snaps的区别。并不是每次打快照后,都要拷贝对象,只有快照后,有写操作,纔会触发copy操作,也就是clone操作。
clone_overlap 保存本次clone和上次clone的 overlap的部分,也就是重迭的部分。clone后,每次写操作,都要维护这个信息。这个信息用于以后数据恢复优化等其他操作纔会用在到,这里不涉及。clone_size 保存每次clone后的对象的size
SnapSet数据结构持久化保存在head对象的xattr的扩展属性中。
在Head对象的xattr中保存key 爲”snapset”,value爲SnapSet序列化的值
在snap对象的xattr中保存key爲user.cephos.seq的 snap_seq 值
RBD快照的原理
Rbd创建快照
Rbd快照基本步骤如下:
- 向monitor 发送请求,获取一个最新的快照序号snap_seq
- 把该image该快照的 snap_name 和 snap_seq 保存到rbd的元数据中
在rbd的元数据里,保存了所有快照的名字和对应的snap_seq号,并不会触发OSD端数据的操作,所以非常快。
快照后的写
当对一个image做了一个快照后,要对该image写,由于快照,需要copy-on-write机制。
客户端写操作,必须带SnapContex结构,也就是需要带最新的快照序号seq和所有的快照序号snaps. 在OSD端,对象的Snap相关的信息保存在SnapSet数据结构中,当写操作发生时,需要做如下的处理。
规则1
如果head对象不存在,创建该对象并写入数据,用SnapContext相应的信息更新SnapSet的信息。也就是snapSet的seq值设置爲SnapContex的seq值,SnapSet中的snaps的值,设置爲SnapContex的snaps值
规则2
如果写操作带的SnapContex的seq值,也就是最新的快照序号小于SnapSet的seq值,也就是OSD端保存的最新的快照序号, 直接返回-EOLDSNAP的错误。
ceph客户端始终保持最新的快照序号。如果客户端不是最新的快照需要,可能的情况是,多个客户端的情形下,其它的客户端有可能创建了快照,本客户端有可能没有获取到最新的快照序号,需客户端更新爲最新的快照序号。
ceph也有一套Watcher回调通知机制,当别的的客户端做了快照,产生了以新的快照序号,当该客户端访问,osd端知道最新快照需要变化后,通知相应的连接客户端更新最新的快照序号。如果没有及时更新,也没有太大的问题,客户端更新重新发起写操作。
规则3
如果写操作带的SnapContex的seq值 等于SnapSet的seq值,做正常的的读写。
规则4
如果写操作带的SnapContex的seq值 大于SnapSet的seq值:
- 用SnapContex的 seq和 snaps更新 SnapSet的的seq和snaps的值
- 对当前head对象做copy-on-write操作, clone出一个新的快照对象,该快照对象的snap序号爲最新的序号,并把clone操作记录在clones列表里,也就是把最新的快照序号加入到clones队列中。
- 写入最新的数据到head对象中
| 操作序列 | 操作 | Rbd 保存的元数据 | OSD对象 |
|---|---|---|---|
| 1 | write data1 snapContext{ seq=0,snaps={} } | SnapSet={ seq = 0,head_exists= true, snaps={},clones={} },obj1_head(data1) | |
| 2 | create snapshot name=”snap1” | (“snap1”,1) | |
| 3 | write data2 snapContext{ seq=1,snaps={1} } | snapSet={ seq = 1,head_exists= true,snaps={1},clones={1},obj1_1(data1) obj1_head(data2) | |
| 4 | create snapshot name=”snap3” | (“snap1”,1),(“snap3”,3) | |
| 5 | create snapshot name=”snap6” | (“snap1”,1)(“snap3”,3)(“snap6”,6) | |
| 6 | write data3 snapContext={ Seq=6, snaps={6,3,1}} | snapSet={seq = 6,head_exists= true,snaps {6,3,1},clones{1,6},obj1_1(data1),obj1_6(data2) obj1_head(data3) |
示列1 快照写操作示列
如示列1所示:
- 在操作1里,第一次写操作,写入的数据爲data1,SnapContext的初始seq爲0, snaps列表爲空, 按规则1,OSD端创建并写数据,用SnapContext的数据更新SnapSet中的数据。
- 在操作2里,创建了该rbd一个快照,名字爲snap1, 并向monitor申请分配一个快照序号爲:1
-
操作3里,写入数据data2,写操作带的SnapContext,seq爲1, snaps列表爲{1}, 在OSD端处理,此时SnapContext的seq大于SnapSet的seq,操作按照规则4:
- 更新SnapSet的seq爲1,snaps更新爲{1}
- 创建快照对象obj1_1,拷贝当前head数据data1到快照对象obj1_1(快照对象名字下划线爲快照序号,ceph目前快照对象的名字中含有快照序号),此时快照对象obj1_1的数据爲data1,并在clones中添加clone记录, clones={1}
- 向head对象obj1_head中写入数据data2
-
操作4,操作5连续分别做了两次快照操作,快照的名字爲snap3,snap6,分配的快照序号分别爲3,6 (在Ceph里,快照序号是有monitor分配的全局唯一,所有单个rbd的快照序号不一定连续)
- 操作6,写入数据data3,此时写操作带的SnapContext爲,seq=6, snaps爲{6,3,1}共三个快照。此时SnapSet的seq爲1,操作按规则4:
- 更新SnapSet的seq爲6,snaps爲{6,3,1}
- 创建快照对象obj1_6,拷贝当前head数据data2到快照对象obj1_6,更新clones={1,6}
- 向head对象obj1_head中写入数据data3
快照的读
快照读取时,输入参数爲rbd 的name和快照的名字。Rbd的客户端通过访问rbd的元数据,来获取快照对应的snap_id,也就是快照对应的snap_seq
在osd端,获取head对象保存的SnapSet数据结构。这个需要根据snaps和clones来计算快照所对应的正确的 快照对象。
例如在示列1中,最后的SnapSet ={seq=6, snaps={6,3,1},clones={1,6}, ……}, 这时候读取seq爲 3的快照, 由于seq 爲3 的快照并没有写入数据,也就没有对应的clone对象,通过计算可知,seq爲3的快照和snap 爲 6的快照对象数据是一样的,所有就读取obj1_6对象
可知,osd端根据SnapSet中保存的snaps和clones记录,不难推测具体快照对应的数据对象。
快照的rollback
快照的回滚,就是把当前的head对象,回滚到某个快照对象。 具体操作如下:
- 删除当前head对象的数据
- copy 相应的snap对象到head对象
快照的删除
删除快照时,直接删除SnapSet相关的信息,并删除相应的快照对象。需要计算该快照
是否被其它快照对象共享。例如在示列1中,obj1_6 是被 snap爲3 和snap 爲6 的对象共享,他们数据是相同的。当删除snap爲6的快照时,不能直接删除obj1_6就需要计算,做相应的处理。
ceph的删除是延迟删除,并不直接删除。
代码分析
入口:
客户端请求 client.cc Client::mksnap
服务端处理:Server.cc Server::handle_client_mksnap
snap相关(个人总结) - https://www.cnblogs.com/noblemore/p/4954330.html
专题
Ceph快照域SnapRealm
快照通过SnapRealm组织成树形结构,每个有快照信息的inode节点都会有对应的SnapRealm,没有快照信息的inode使用父节点路径上最近的SnapRealm,根节点默认有SnapRealm。在client端创建快照时mds会在对应的inode节点新建SnapRealm(仅首次创建时),普通文件inode中也会出现SnapRealm,但都是mds的cow机制创建的,client端无法直接操作。
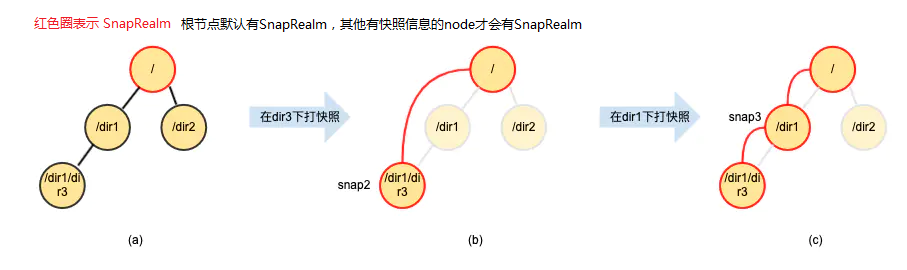
snaprealm创建及组织
链接:https://www.jianshu.com/p/4485601f3d4f
创建快照:
new Realm, 可以分为持久化和非持久化部分,持久化部分包括父域和子域的关联关系,用sanpid数组表示,这样可以记住一些以前的父域,以及本域附带的信息。
SnapRealm关联父SnapRealm,基于MDS的MDCache的全量Trace特性(即如果子目录or子文件在cache中,父目录到root目录的元数据就一定在cache中),逐层向上遍历,找到最近的域(被父目录的CInode关联),即父SnapRealm。然后关联到parent字段,父域的children数组中。
文件or目录关联自身所在的SnapRealm,在MDS给对应的client第一次分配权限的流程,issue_new_caps > add_client_cap,使用上述关联算法,找到最近的SnapRealm,将自身关联到所在SnapRealm的inodes_with_caps数组、client_caps数组(通过cap)中。
文件or目录解除和SnapRealm的关联,A)在MDS从MDCache中清理对应CInode的时候;B)在MDS对相关snap业务的权限有关键更新(具体是收到SNAPFLUSH消息并移除对应client的snapcaps),并落盘后,此CInode如果没有任何的给client的权限snapcaps,就解除关联域;C)收到Client的权限释放消息release caps(此消息不需要考虑caps值),若果所有client的caps都被回收了,就取消关联域(因为这说明没有client在使用文件,文件在client侧没有缓存,不需要考虑通知对应的client)。
SnapRealm的结构更新,域可以合并到父域(对应域的删除),也可以拆分到子域(对应域的增加),这时候MDS会遍历对应realm的所有inodes_with_caps,并且使用ancestor_of算法(就是简单查找父目录路径确定是否域的主inode在路径上),确定要迁移哪些inode到新的realm,重新关联到新inodes_with_caps、新children。
SnapRealm的数值更新,域相关的业务数值更新,快照业务相对特殊,是文件目录结构和mtime、size的版本变更,每次改变后形成新版本,且变化时做cow,一般不会针对快照域单独设置业务参数。
引子:
如果针对域的主节点,更改相关属性,并通过caps状态 lock切换 getxattr请求等方式同步到client。
Client侧的SnapRealm,和MDS侧的结构一致(是从属关系),对于已有的目录结构,创建、合并、拆分SnapRealm,MDS通过推送消息,告知Client域的变化。推送消息是设计成基于ino的,包括域的主ino,从属inos数组(即对应inodes_with_caps),children域inos数组。从属inos数组,children inos数组都是在需要推送小消息时,才组装的。在发消息之前,MDS用SnapRealm结构保存了这些关系,包括children域数组、parent关联。child realm和parent realm什么时候建立这种关联、inode什么时候和自子所在的realm建立这种关联,见上文。
Client收到对应的推送消息后,会直接更新本地域结构,建立和MDS同样的域关联关系,简单包括使用ino寻找inode,然后更新关联i_snaprealm。在域需要访问时,直接通过i_snap_realm链接到对应的域结构,即可使用域的数值。
SnapRealm何时创建?
1.从磁盘上加载的时候。open_snaprealm < decode_snap_blob < decode_store/decode_snap < _load_dentry < _omap_fetched
2.进行迁移的时候。open_snaprealm < decode_snap_blob < decode_store/decode_snap < decode_import < decode_import_inode < decode_import_dir
3.进行rejoin的时候 。 fetch < rejoin_invent_inode < handle_cache_rejoin_strong
4.创建快照的时候。open_snaprealm < pop_projected_snaprealm < pop_and_dirty_projected_inode < _mksnap_finish
5.replay的时候。decode_snap_blob < EMetaBlob::update_inode < EMetaBlob::replay
思考题:快照存储了指向具体数据的指针,如果数据删掉了,指针指向就找不到数据了,快照怎么恢复呢?
作者:吃瓜的瓜
链接:https://www.zhihu.com/question/537671655/answer/2529017655
快照的核心理念是所有在做过快照之后的修改都是COW(copy on write)。如果你想了解“删除”的话其实有两个相关的语义:unlink和rmdir。我们举个unlink的举例子吧。在没有snapshot的时候,unlink意味着要把一个dentry从父目录中删除(意味着父目录内容变化),如果没有hardlink(nlink==1)的时候,意味着需要把inode的所有数据空间回收,同时还需要inode以及一系列相应的元数据的变化和回收。
在snapshot创建之后的unlink,是不会释放和直接修改原有的数据/元数据块的。unlink把原先的inode本应该释放回收的数据块挂在snapshot上而不回收;对于把要修改的数据/元数据(父目录以及inode metadata),先把要修改的块内容copy到另外一个数据块上,然后有如下两种不同的实现处理方式:1、snapshot索引老的数据块,再修改copy出来的那个新数据块,让当前文件系统索引新的(copy并且修改过内容)的数据块;或者2、snapshot索引新的copy出来的数据块,直接修改老的数据块,当前文件系统指向老的修改过内容的数据块原址。
总之无论以上两种实现方式中的任何一种,snapshot索引的数据块的“内容”都是修改之前的。
所以在snapshot之后的unlink其实inode数据块没有释放,父目录索引中的内容是还包含这个文件dentry的,一系列的metadata内容都是发生unlink删除之前的状态。
因此snapshot之后的数据依然可以访问。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)