【ceph】CephFS 内部实现(四):MDS是如何启动的?--未消化
MDS启动时要经历一系列状态装换,但mds的各个状态是如何产生、确定的?这些状态究竟在处理什么?本篇尝试以正常启动mds为背景解释这两个问题。
MDS和Monitor的交互
为提供FS服务,首先要ceph fs new命令创建filesystem,然后再启动mds进程。
其中ceph fs new命令由MDSMonitor组件处理,将一个文件系统信息(底层pool是哪些,一些feature等)写入monitor store,此时文件系统是没有关联mds的,所以是不可用的。
mds进程启动后,通过向MDSMonitor发送Beacon消息,并接收从MDSMonitor返回的MDSMap消息逐步启动自己。Beacon除了用于告知monitor关于mds的健康状态,还有want_state这一信息。want_state的值是在mds启动或者收到MDSMap后由mds自己决定的(如向resolve、reconnect、rejoin等转换)。MDSMonitor接收mds发来的Beacon消息,更新pending_fsmap,写入store。MDSMonitor::tick()在每次写完store后被调用,对pending_fsmap进行遍历,尝试给fsmap关联mds,然后更新pending_fsmap,再次写入store,完成后向mds发送MDSMap。关联到fsmap的mds分两类:一类是具有rank的,最终mds daemon会进入到STATE_ACTIVE状态,其中rank值由MDSMonitor分配;另一类是STATE_STANDBY_REPLAY,每个fsmap最多有一个,没有rank值。关联动作是通过遍历已创建fs map(如果创建了多个filesystem,那么此处就会有多个fs map),寻找可用的处于STATE_STANDBY状态的mds实现的,具体在MDSMonitor::maybe_expand_cluster()。
在众多mds状态中,由MDSMonitor路径负责的状态转换只有一部分,所以在MDSMonitor的代码里不会看到全部mds状态。其他状态转换是在mds端做的决策,此时monitor只是作为一个记录者,负责将状态写入store中。

MDS 状态
Monitor关于mds状态的处理
MDSMonitor每次写完store后都会由MDSMonitor::tick()做三件事:
- 查看是否有filesystem需要关联mds
- 查看是否有非健康的mds
- 查看是否需要将mds从
STATE_STANDBY变成STATE_STANDBY_REPALY
后两个相对简单些,这里就不再详述。对于第一个给filesystem关联mds,是由MDSMonitor::maybe_expand_cluster()完成。
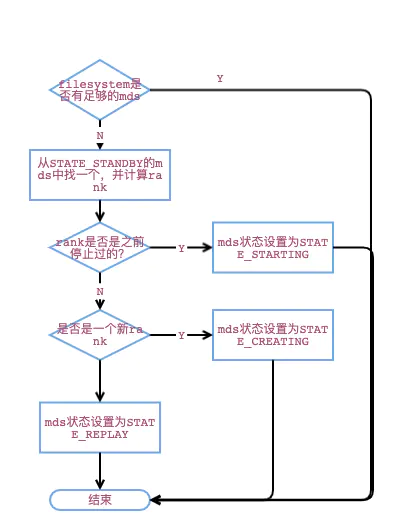
在正常启动阶段,MDSMonitor代码,已经MDSMonitor调用的FSMap::promote中主要使用了以下状态:
- STATE_STANDBY :收到BOOT beacon时直接设置mds为此状态,表明空闲可用
- STATE_STANDBY_REPLAY
- STATE_CREATING:全新的rank,表明mds需要准备journal对象等元数据,由于没有历史包袱,所以这里不需要load元数据或者replay日志之类的操作
- STATE_STARING:停止的rank,不需要创建journal等元数据,但需要load元数据
- STATE_REPLAY
对于resolve等状态MDSMonitor是不涉及的,这些是在MDS端处理。
mds侧关于mds状态的处理
MDS在启动时设置自己状态为STATE_BOOT,并通过beacon发送给MDSMonitor。后续将通过接收到的MDSMap来进一步决定自己的状态。
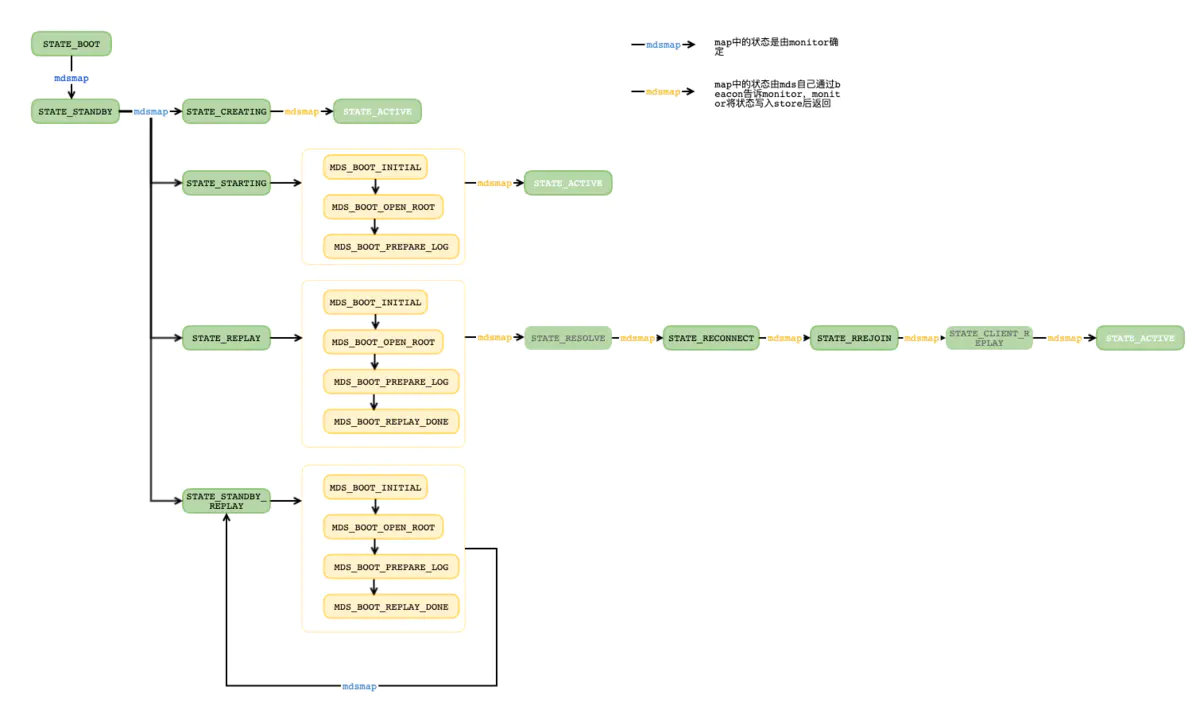
MDS_BOOT_xxx对应MDSRank::boot_start()中的步骤,每个步骤作用:
-
MDS_BOOT_INITIAL:从rados中读取并初始化inodetable,sessionmap,log等信息。 -
MDS_BOOT_OPEN_ROOT:初始化目录树的根目录(包括mdsdir和rootdir) -
MDS_BOOT_PREPARE_LOG:设置log的参数,如果mds处于replay,则会在此进行log-replay -
MDS_BOOT_REPLAY_DONE:log replay已完成,进行一些清理工作,准备进入下一个阶段(对于standby_replay不会再改变状态) -
STATE_RESOLVE:处理slave updates和subtree auth。
slave update是在多active MDS下,且op需要跨越两个或以上mds时才会产生。如对一个普通文件创建硬链接,目标和源在不同dir下,且两个dir被pin在不同mds时,就会产生slave op。
这一阶段要做的另外一件事是处理migrator进行到一半的import/export,进行到一半的import/export dir auth是无法确定的,需要在resolve阶段进行确定。slave op处理完后mds会互发subtree信息,这一步中存活的mds会根据从resolve状态的mds接收到的对subtree的声明来进行import_reverse或import_finish最终将subtree的auth确定下来。 -
STATE_RECONNECT:遍历sessionmap中的clients,等待client重新建立连接,超时后自动进入下一状态。这一步client可能会将自己对inode已拥有的cap进行声明,如果这些cap有误,可能是inode auth已经改变或者cache中没有inode,对于前者当前mds将inode记录到MDCache::cap_exports,表明会在下一阶段export到auth mds,对于第二种情况,则将inode记录到MDCache::cap_imports表明会在下一阶段对inode进行查找。 -
STATE_REJOIN
这一阶段要处理的事情有:- rejoin mds通过
MDCache::process_imported_caps查找导入的cap对应的inode。首先遍历mds,如果没有找到则从rados读取 - rejoin mds对需要export的inode进行处理
- 处理元数据。对于rejoin mds,replay并不能重建全部元数据信息,且由于subtree map只存在于每个LogSegment开头,所以replay后产生的subtree 信息也可能是过时的,这时如果其他节点有相应的元数据,则需要在rejoin阶段进行处理。rejoin mds需要确保其他 mds宣称自己应该拥有的auth元数据已经正确初始化,对于自己拥有的非auth元数据,要和其他mds保持一致。这些一致主要体现在锁和目录树结构上。rejoin mds缺少的auth元数据最后需要从rados读取。
- rejoin mds通过
-
STATE_CLIENT_REPLAYmds启动阶段block的op在此阶段继续处理 -
STATE_ACTIVEmds启动成功
其他状态
除了以上状态外,还有stop、dne等状态,本文没有涉及。
作者:宋新颖
链接:https://www.jianshu.com/p/742e18f53f3a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号