

【SWIM】SWIM:可伸缩的成员协议:谁是我的伙伴?
目录
转自:https://www.cnblogs.com/bugcai/p/13523060.html
什么是SWIM
定义:
SWIM(Scalable Weakly-consistent Infection-style Process Group Membership Protocol, 可伸缩的弱一致性传染式进程组成员协议),就是其中一种成员协议。
用途:
分布式系统中,一组节点,他们需要互相协作、互相发送消息。而要做到这一点,首先需要解决一个问题:谁是我的伙伴?
这就是成员协议要做的。
SWIM帮助分布式系统中的节点维护一个active节点的列表,同时当有节点加入、离开或失效时通知节点。
一、理解协议名称
可伸缩的弱一致性传染式进程组成员协议(Scalable Weakly-consistent Infection-style Process Group Membership Protocol),让我们将如此之长的协议名分解开来,逐一剖析一下,就能理解名字如此长的原因。
可伸缩(Scalable):在 SWIM 之前,大部分的成员协议使用心跳机制,每个结点每隔一段时间向集群中的每一个其他结点发送心跳消息。如果结点 N1 一段时间没有收到来自结点 N2 的心跳,它就会断定这个结点失效了。对于一个小型集群而言,这样做没问题;但是,随着集群中结点数量的增加,需要发送的心跳消息呈平方增长。如果有10个结点,每秒发送100条心跳消息问题不大;但是,对于1,000个结点,那就变成了每秒1,000,00条消息。因此心跳方式伸缩性上有问题。
弱一致性(Weakly-consistent):这意味着在一个给定的时间点,不同的结点会有不同的“世界观”。当然,他们最终将收敛到相同状态,但我们不要期待强一致性。
传染式(Infection-style):这就是通常所说的 流言(gossip) 或 传染病(epidemic)协议。这意味着一个结点只与一部分结点分享某个信息,然后他们再与另外一部分结点分享,直到整个集群都收到那条信息,就像谣言传播的方式一样。
成员(Membership):作为成员协议,我们要回答的一个基本问题就是:”谁是我的伙伴?“
二、SWIM协议的构成
心跳机制使用心跳消息解决了两个不同的的问题:探测到失效结点(即不再发送心跳的结点),以及维持集群中活跃结点(也就是发送心跳的结点)的列表。 SWIM 采用一种新的方式将这两个问题分解到不同组件上,因此他有 失效检测 和 信息传播 两个模块。
失效检测
集群中每一个结点随机选择一个结点(比如说,N2),然后向它发送 ping 消息,期待收到回复 ack。 ping 仅仅是一个探测消息,通常情况下将会收到 ack 消息并确认 N2 为活跃的。
当没有收到回复时,并不是立即将其标记为“挂了”,而是 借助 其他结点来试图探测它。随机从成员列表中选择 k 个其他结点,向它们发送 ping-req(N2) 消息
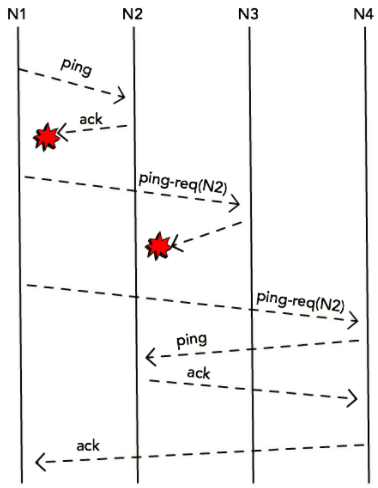
通过这种方式可以防止误报,比如因为某种原因 N1 没有收到来自 N2 的响应(或许是因为两者之间出现了网络拥塞),但实际上 N2 仍活着而且可以被 N4 访问。
如果该结点不能被这 k 个结点的任何一个访问到,那就可以被标记为“挂了”。
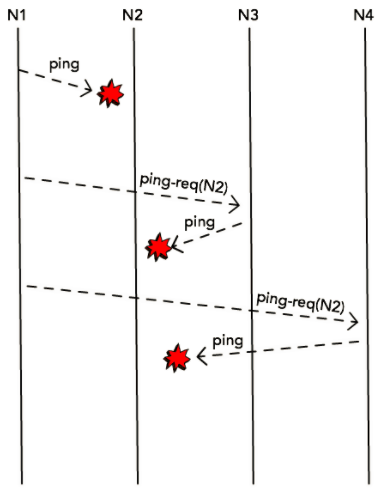
信息传播
当侦测到一个结点已经“挂了”后,协议将这个信息广播给集群中所有其他结点,每一个结点将会把 N2 从本地的活跃结点列表中删除。结点自愿离开或加入集群的信息可以采用类似的方式广播。
三、SWIM协议优化
以上所说的协议内容相当简单,不过针对协议健壮性和效率,在原始的 SWIM 论文中也提出了一些优化建议:
-
对于信息传播组件,使用传染式的方式传播信息,而不是广播的方式
-
对于失效检测,采用怀疑机制以降低误报率
-
循环式的选择探测目标,而不是随机选择结点
接下来,我们将对上述改进点逐一剖析,理解其背后的原因。
传染式信息传播
在使用这个多播方式传播信息时,我们需要注意(至少)两个问题:
-
IP multicast,在大部分环境下都是禁用的(例如,Amazon VPC 环境)这时,你就只能使用效率非常低下的点对点方式了。
-
即使你能用 IP multicast,通常也是 UDP 方式的,众所周知这是一种“尽最大努力”协议,意味着可能出现丢包情况,这样一来要维护一个可靠的成员列表就变得困难了。
SWIM 论文中推荐了一个更优雅的方案,不用再考虑广播的思路了,而是借助我们在失效检测中使用的三个消息: ping,ping-req 和 ack ,让它们捎带上我们需要传播的信息。没有添加任何新消息,只是复用已存在的消息,让这些消息也传输成员更新信息。
用于失效检测的怀疑机制
这个优化是,在断言结点已经“挂了”之前,仅仅是怀疑。目的是为了尽量减少误报,因为即便多花一些时间来侦测失效结点,也好过将一个正常结点错误的标记为“挂了”。不过,这是一种权衡,可能在特定场景下,这没有什么意义。
具体的工作方式是这样的:当结点 N1 不论是通过直接的 ping ,还是间接的 ping-req 都无法收到来自结点 N2 的 ack 消息时,不是立即将 N2 判定为“挂了”,而是怀疑 N2 “挂了”,并将这个怀疑传播出去。
嫌疑结点仍被当作非故障结点,像其他结点一样不断的收到 ping 消息。如果有结点能收到来自 N2 的 ack 消息,则会被再次标记为活跃结点,并将这个”喜讯“传播出去。N2 自身也会收到怀疑它”挂了“的消息,并向集群中其他结点宣告这个怀疑是错误的。
如果在预定义的超时后仍没有收到来自 N2 的任何消息,那么就可以断言这个结点”挂了“,并将这个”噩耗“传播出去。
轮流选择探测目标
在最初的协议定义中,是以随机的方式选择一个被探测的结点,即随机的向一个结点发送 ping 消息并期待收到 ack 。尽管可以保证,最终能够探测到某个结点失效,但运气不佳的话可能要花费比较长的时间。解决这个问题的办法是,维护一份待探测结点的列表,然后循环遍历(round-robin)这些结点,并且新加入集群的结点被随机的插入列表中。采用这种方式,我们的失效检测将会是“有时限的”(time-bounded),最差情况下选中失效结点所需的时间也是固定的,即 探测间隔 * 结点数。
四、总结
-
SWIM 是一个成员协议,它帮助我们知道那些结点在集群中,帮助我们维护一个不断更新的健康结点列表。
-
它将 成员问题 分成两个部分:失效检测 和 信息传播。
-
失效检测 随机地向结点发送 ping 消息,并期待收到 ack 消息;如果没有收到 ack ,将向 k 个结点发送 ping-req 消息,借助他们来间接的进行探测。
-
失效检测 的一个优化是,首先是标记结点“有嫌疑”,在超时后再标记为“挂了”。
-
对于 信息传播 的优化是,让失效检测消息( ping、ping-req 和 ack)捎带上 成员变化 信息,而不是使用 IP广播 机制。
-
对于失效检测时间的优化是,采用轮流(round-robin)选择结点的方式,而不是随机选择。
因此,SWIM 协议具备如下优势:
-
可伸缩性:失效发现时间、误报率以及每个成员所需的消息收发负载与集群大小无关。成员状态变更信息的传播与集群大小呈对数关系(log n)
-
健壮性:协议是完全区中心化的,对于结点故障或网络分区具有容错能力。
-
易于部署和维护:新成员联络任何一个现有成员即可加入集群;而成员离开时,无需任何特别措施即可维持集群健康。
-
实现的简单性:协议中只定义了为数不多的状态和消息类型。而且点对点的结构,无需进行初始配置或在成员变更时进行维护。
五、Serf的改进
-
(+)添加使用TCP进行探测的方式
使用UDP的同时,也尝试使用TCP方式,以解决由于网络配置原因导致UDP路由有错误的场景。
-
(+)定期的通过TCP与随机选择的另一个成员进行全状态同步
加速收敛,特别有助于快速地从网络分区中恢复。
-
(+)专门的gossip层
除了让探测消息捎带外,也定期发出自己的gossip消息。 这使得gossip率能够独立于失效检测率进行调整,有必要的话可以比后者更高,从而加快收敛速度。(如200毫秒一次 gossip ,1秒一次 失效检测)
-
(*) 在一段时间内保留失效节点的状态
关于失效节点的信息可以通过 全状态同步 传递,从而提高收敛速度。
从0.8版开始,引入Lifeguard技术,将SWIM变成一种自适应的协议。
-
(*)Local Health Aware Probe (LHA-Probe)
每个成员有一个“结点自我意识”计数器(Local Health Multiplier),计数器的值越大,探测间隔和超时就越大。快速的将非健康结点对集群的影响降到最低。
计数器增减规则:
-
-
成功的探测(对于直接或间接探测,在超时时间内收到 ack 消息):-1
-
失败的探测:+1
-
反驳对于自身的怀疑: +1
-
未收到 nack:+1 (注:收到 ping-req 的成员,在80%超时时间,发一个 nack 消息给间接探测发起者)
-
探测间隔和超时调整规则:
ProbeInterval = BaseProbeInterval * (LHM(S) + 1)
ProbeTimeout = BaseProbeTimeout * (LHM(S) + 1)
BaseProbeInterval 设为 1 秒
BaseProbeTimeout 设为 500 秒
S 默认为 8
-
(*)Local Health Aware Suspicion (LHA-Suspicion)
也称 叠罗汉(Dogpile)。对于怀疑确认,用动态时间代替固定的失效确认时间,当其他成员也产生相同的怀疑时,则时间呈对数减少。结果是,一个成员真的失效时,可以更快地得到确认;而降级结点,也会因为收不到确认而保持更长的超时,被怀疑结点因而有更多时间处理来反驳。
-
(+)伙伴机制(Buddy System)
代替捎带方式,直接通知受怀疑结点,以便其能更快速的反驳怀疑。


