ArcGIS教程 - 9 矢量数据空间分析
链接:https://pan.baidu.com/s/1MhG2875Zzt-6VFLus7SYzQ 提取码:w47i
第9章 矢量数据空间分析
空间分析是基于地理对象的位置和形态的空间数据分析方法,目的在于提取和传输空间信息。空间分析是地理信息系统的主要特征和核心部分。空间分析配合空间数据的属性信息,能提供强大而丰富的数据查询功能。
空间分析主要分为矢量数据空间分析和栅格数据空间分析。
矢量数据空间分析主要表现为:一般不存在模式化的分析处理方法;处理方法表现为多样性和复杂性。矢量数据空间分析方法主要包含提取分析、叠加分析、邻域分析、统计分析和网络分析等。本章主要介绍前四种空间分析方法,网络分析在后面章节会详细介绍。
矢量数据空间分析常用的工具位于ArcToolbox的【Analyst Tool】(【分析工具】)。
9.1 提取分析
GIS 数据集通常包含比实际需要更多的数据。提取分析工具允许根据查询(SQL 表达式)或空间提取所选要素类或表中的要素和属性。
9.1.2裁剪
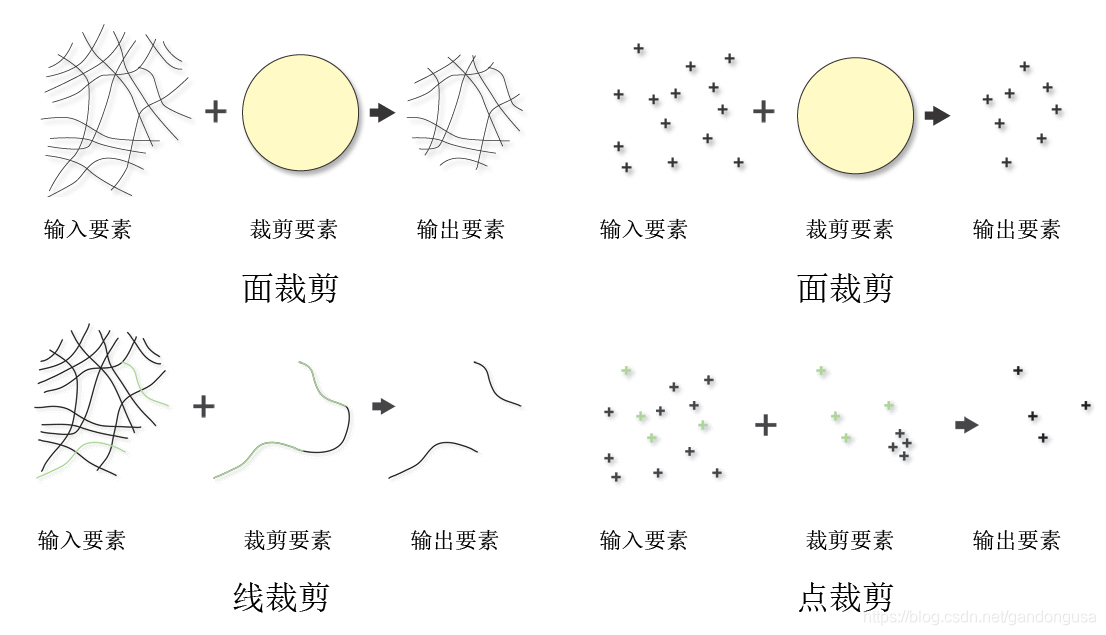
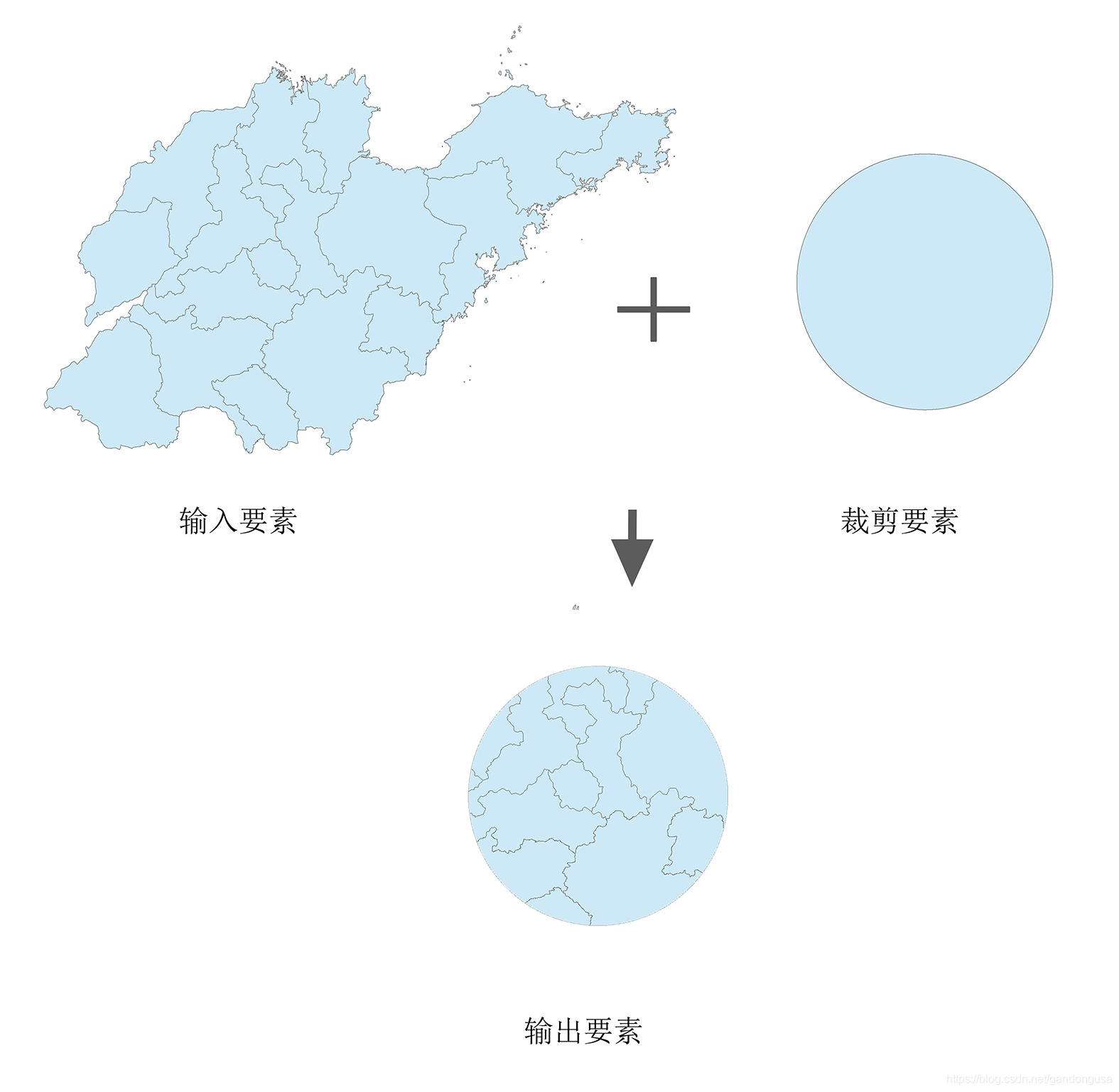
裁剪(Clip)操作提取与裁剪要素相重叠的输入要素(图XX)。此工具用于以其他要素类中的一个或多个要素作为模具来剪切掉要素类的一部分。在您想要创建一个包含另一较大要素类的地理要素子集的新要素类(研究区域或感兴趣区域 (AOI))时,裁剪工具尤为有用。
|
图XX 裁剪示意 |

裁剪要素可以是点、线和面,具体取决于输入要素的类型(图XX)。
当输入要素为面时,裁剪要素也必须为面;
当输入要素为线时,裁剪要素可以为线或面。用线要素裁剪线要素时,仅将重合的线或线段写入到输出要素中;
当输入要素为点时,裁剪要素可以为点、线或面。用点要素裁剪点要素时,仅将重合的点写入到输出要素中。用线要素裁剪点要素时,仅将与线要素重合的点写入到输出要素中。
输出要素类将包含输入要素的所有属性,同时输入要素类的属性值将被复制到输出要素类。
|
图XX 裁剪方法 |
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【提取分析】,双击【裁剪】工具,打开【裁剪】对话窗口。
或者在ArcMap中单击【地理处理】菜单项,选择【裁剪】命令打开【裁剪】对话窗口。
(2)在打开的【裁剪】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Extract\Clip” 目录下
输入要素:Input.shp
裁剪要素:Clip.shp
输出要素类:Input_Clip.shp
|
图XX 裁剪窗口 图XX 裁剪结果 |

(3)【XY容差】选项保持默认
(4)裁剪结果如图XX所示。
9.1.3分割
分割(Split)操作输入要素会创建由多个输出要素类构成的子集(图XX)。
|
图XX 分割示意 图XX 分割对话窗口 |

分割要素数据集必须是面。
分割字段数据类型必须是字符,其唯一值生成输出要素类的名称。分割字段的唯一值必须以有效字符开头。
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【提取分析】,双击【分割】工具,打开【分割】对话窗口。
或者在ArcMap中单击【地理处理】菜单项,选择【分割】命令打开【分割】对话窗口。
(2)在打开的【分割】对话窗口中设置如下(图XX):
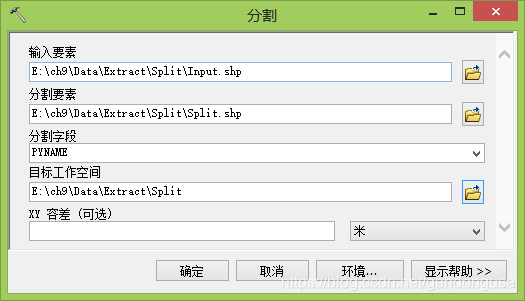
数据位置:“\ch9\Data\Extract\Split” 目录下
输入要素:Input.shp
裁剪要素:Split.shp
分割字段:PYNAME
目标工作空间:\Split
(3)【XY容差】选项保持默认。
(4)分割结果和分割后属性表如图XX、图XX所示。
|
图XX 分割结果 图XX 分割后属性表 |


9.1.3筛选
筛选(Select)操作从输入要素类或输入要素图层中提取要素(通常使用选择或结构化查询语言 (SQL) 表达式),并将其存储于输出要素类中。
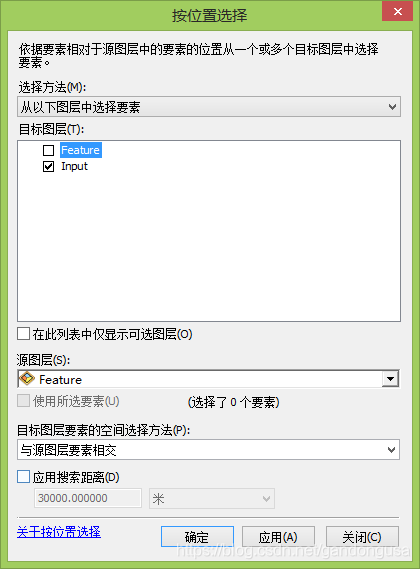
选择操作可以通过在ArcMap菜单栏【选择】下的【按照属性选择】或【按照位置选择】实现(图XX、图XX)。
|
图XX 按属性选择 图XX 按位置选择 |

使用结构化查询语言(SQL)也可以实现选择操作。
结构化查询语言(Structured Query Language,SQL)是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。
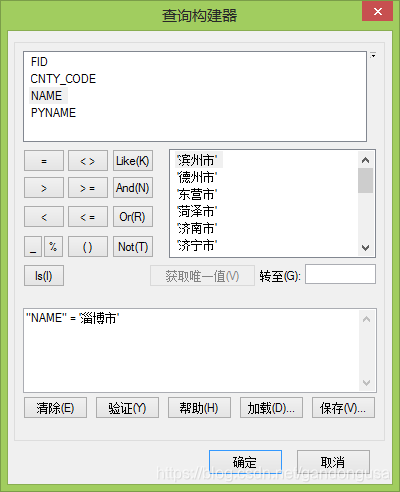
SQL查询实在【查询构建器】中实现的(图XX)。SQL详细内容请参考相应资料。
|
图XX 查询构建器 |
9.1.4表筛选
表筛选操作与结构化查询语言 (SQL) 表达式匹配的表记录并将其写入输出表。与筛选操作不同的是此工具只能输入表进行筛选操作。
9.2 叠加分析
叠加分析(Overlay)也叫做叠置分析,是将有关图层组成的各个数据层进行叠置而产生一个新的图层,其结果综合了原有多个图层要素的属性,同时还生成了新的空间关系,并且将输入的多个数据图层的属性联系起来产生了新的属性关系。
叠加分析通常包含以下七叠加分析。
示例数据输入要素为山东政区图(面),操作数据为某突发事件影响范围(面)。
9.2.1 标识
标识(Identity)操作分析计算输入要素和标识要素的几何交集。与标识要素重叠的输入要素或输入要素的一部分将获得这些标识要素的属性(图XX)。
输入要素可以是点、多点、线或面。注记要素、尺寸要素或网络要素不能作为输入。
标识要素必须是面要素,或与输入要素的几何类型相同。
|
图XX 标识操作 图XX 标识对话窗口 |

具体操作过程为:
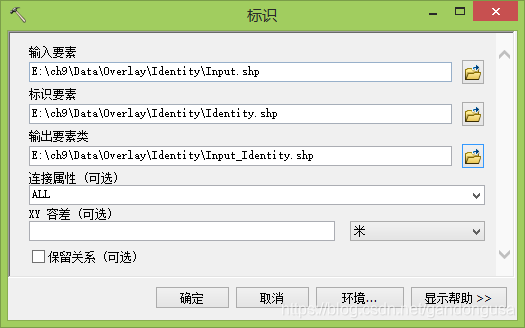
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【标识】工具,打开【标识】对话窗口。
(2)在打开的【标识】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Overlay\ Identity” 目录下
输入要素:Input.shp
标识要素:Identity.shp
输出要素:Input_Identity.shp
(3)【连接属性】选项。
ALL:输入要素的所有属性都将传递到输出要素类。这是默认设置。
NO_FID:除 FID 外,输入要素的其余属性都将传递到输出要素类。
ONLY_FID:只有输入要素的 FID 字段将传递到输出要素类。
【连接属性】保持默认不变。
(4)【XY容差】保持默认设置。
(5)【保留关系】可选项,选择之后会将输入要素和标识要素之间的附加关系写入到输出要素中,此选项仅在输入要素为线要素而标识要素为面要素时才适用。
(6)标识结果如图XX所示。
|
图XX标识结果 图XX擦除结果 |
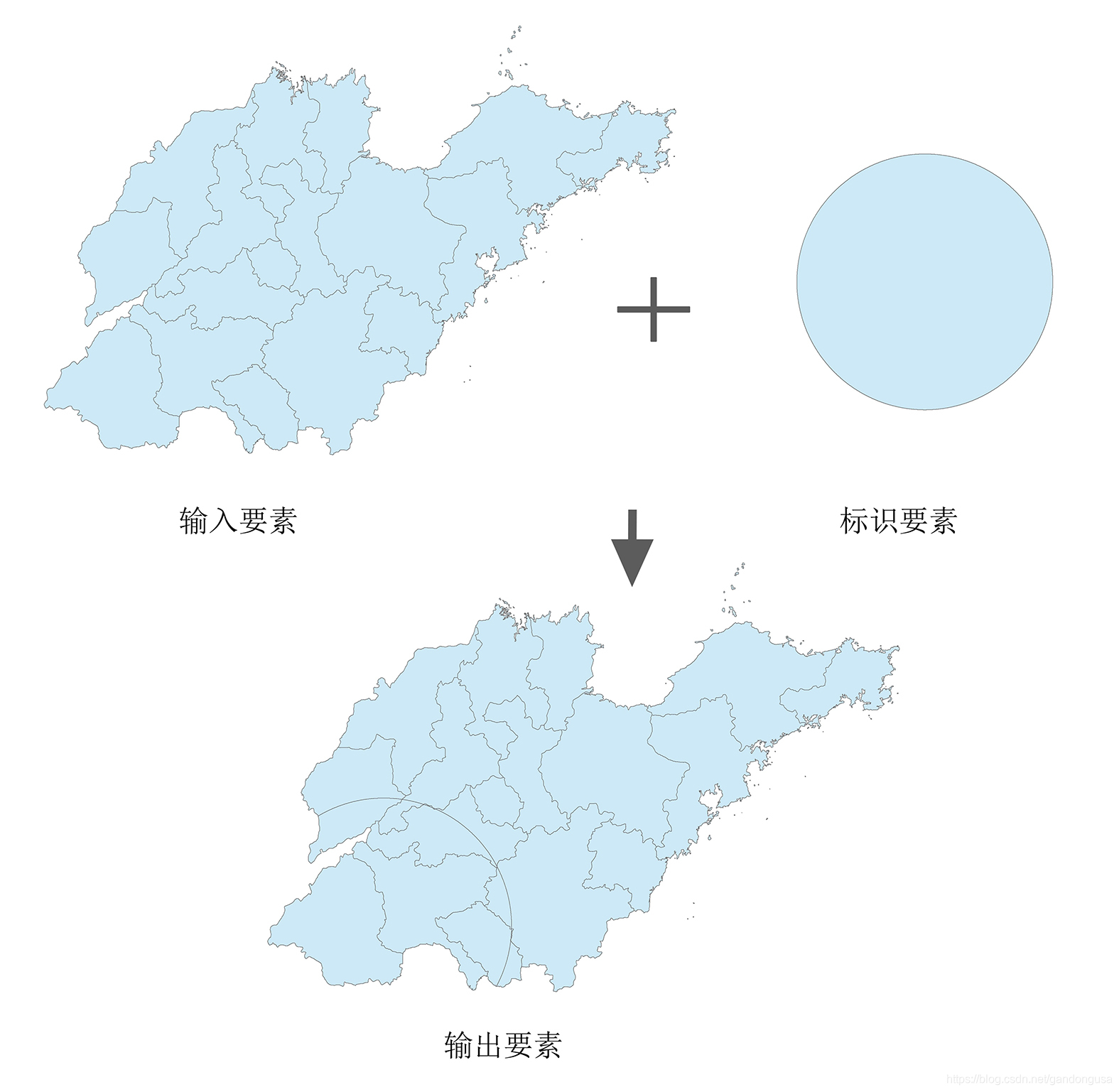
标识操作之后的结果会包含输入要素与标识要素的全部属性。
标识操作把山东省区域范围分为突发事件影响区域和非影响区域。
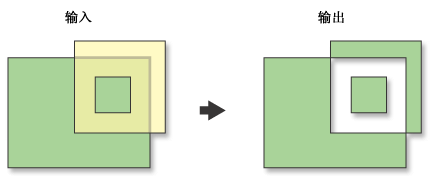
9.2.2 擦除
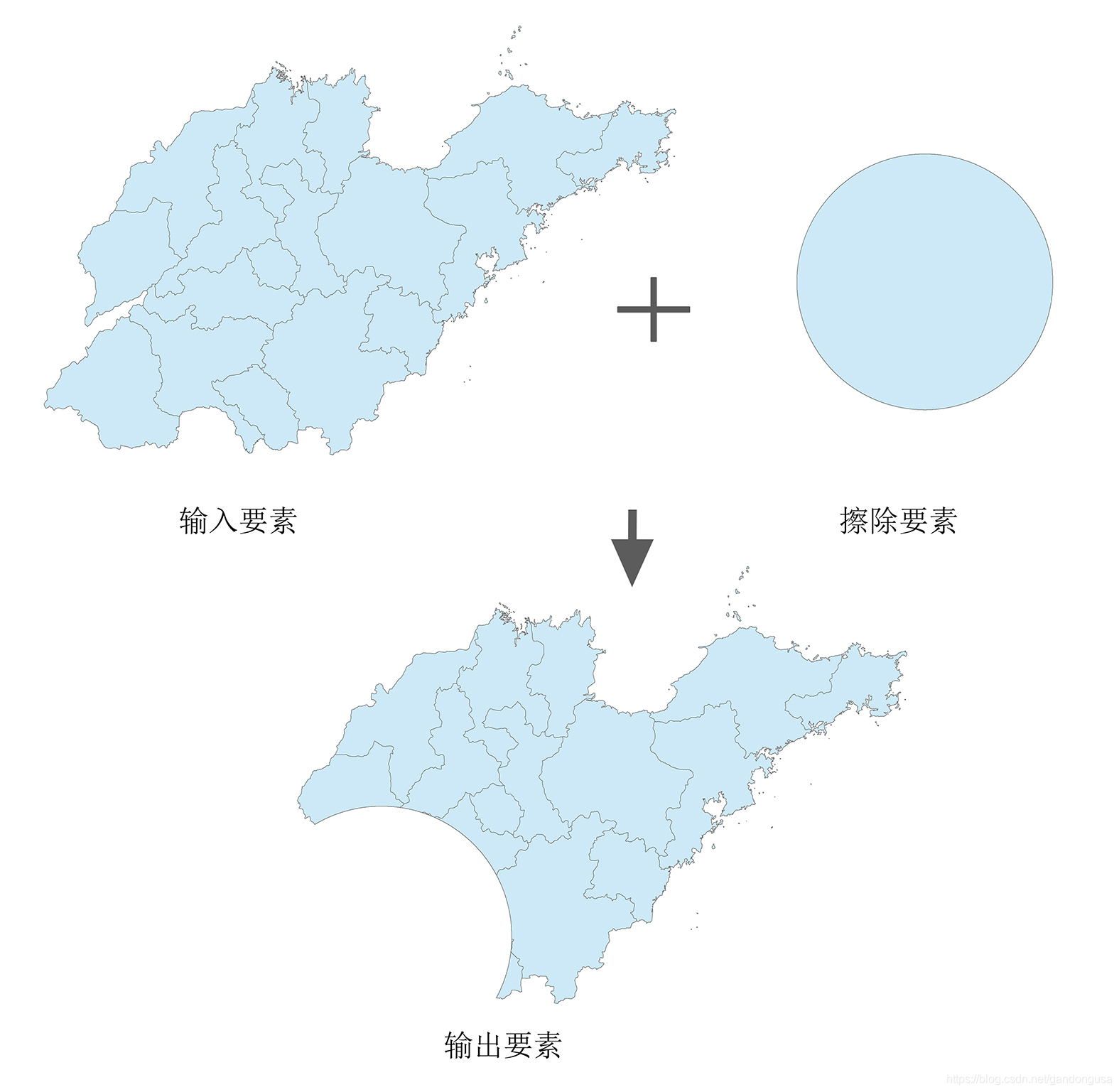
擦除 (Erase)操作将通过将输入要素与擦除要素的多边形相叠加来创建要素类。只将输入要素处于擦除要素外部边界之外的部分复制到输出要素类(图XX)。
擦除要素可以为点、线或面。面擦除要素可用于擦除输入要素中的面、线或点;线擦除要素可用于擦除输入要素中的线或点;点擦除要素仅用于擦除输入要素中的点。
输入要素类的属性值将被复制到输出要素类。
|
图XX 擦除操作 图XX 擦除对话窗口 |


具体操作过程为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【擦除】工具,打开【擦除】对话窗口。
(2)在打开的【擦除】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Overlay\Erase” 目录下
输入要素:Input.shp
擦除要素:Erase.shp
输出要素:Input_Erase.shp
(3)【XY容差】保持默认设置。
(4)擦除结果如图XX所示。
擦除操作把受突发事件影响的区域擦除,只保留未受影响的区域。
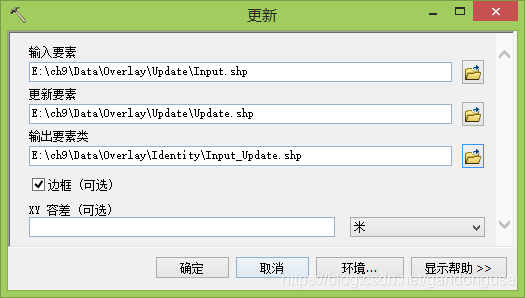
9.2.3 更新
更新(Update)操作计算输入要素和更新要素的几何交集。输入要素的属性和几何根据输出要素类中的更新要素来进行更新(图XX)。
输入要素必须是面要素,更新要素必须是面要素。
此工具将不修改输入要素类,工具的执行结果将写入到新要素类。
输入要素类与更新要素类的字段名称必须保持一致。如果更新要素类缺少输入要素类中的一个(或多个)字段,则将从输出要素类中移除缺失字段的输入要素类字段值。
|
图XX 更新操作 图XX更新对话窗口 |

具体操作过程为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【更新】工具,打开【更新】对话窗口。
(2)在打开的【更新】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Overlay\Update” 目录下
输入要素:Input.shp
更新要素:Update.shp
输出要素:Input_Update.shp
(3)【边框】选项。如果在对话框中未选中边框参数,则沿着更新要素外边缘的面边界将被删除。即使删除某些更新面的外边界,与输入要素重叠的更新要素的属性也被会指定给输出要素类中的面。
【边框】选项保持默认勾选状态。
(4)【XY容差】保持默认设置。
(5)更新结果如图XX所示。
更新操作把山东省内受突发事件影响的区域合并并与突发事件整体区域一起显示。
|
图XX 更新结果 图XX 交集取反结果 |
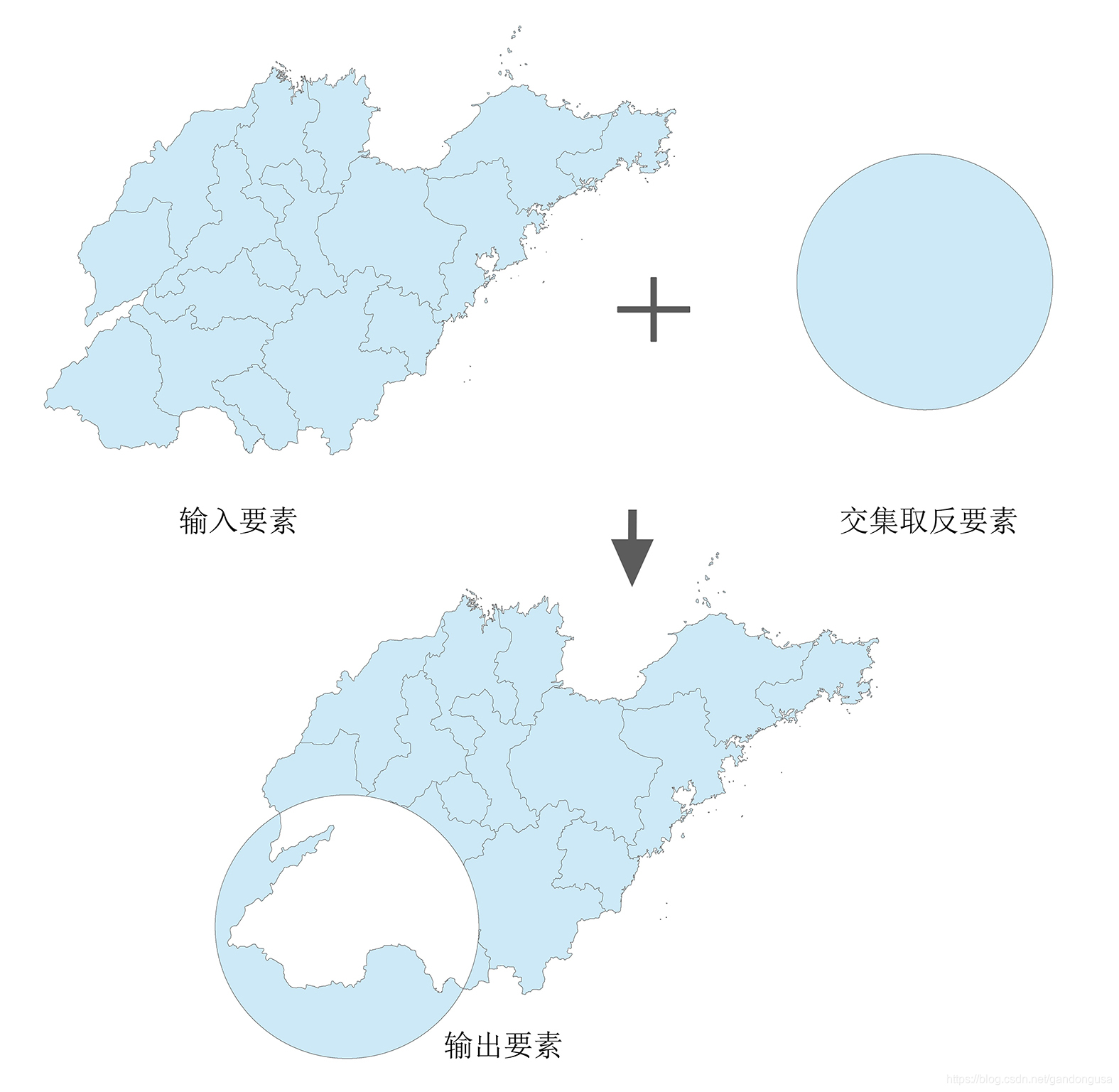
9.2.4 交集取反
交集取反(SymDiff)操作输入要素和更新要素中不叠置的要素或要素的各部分将被写入到输出要素类(图XX)。
输入和更新要素类或要素图层必须具有相同的几何类型。
输入要素类的属性值将被复制到输出要素类。
|
图XX 交集取反操作 图XX交集取反对话窗口 |
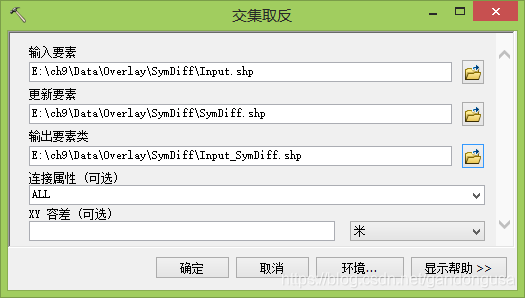
具体操作过程为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【交集取反】工具,打开【交集取反】对话窗口。
(2)在打开的【标识】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Overlay\ SymDiff” 目录下
输入要素:Input.shp
交集取反要素:Identity.shp
输出要素:Input_ SymDiff.shp
(3)【连接属性】选项。
ALL:输入要素的所有属性都将传递到输出要素类。这是默认设置。
NO_FID:除 FID 外,输入要素的其余属性都将传递到输出要素类。
ONLY_FID:只有输入要素的 FID 字段将传递到输出要素类。
【连接属性】保持默认不变。
(4)【XY容差】保持默认设置。
(5)交集取反结果如图XX所示。
交集取反操作把山东省内受突发事件影响的区域排除在外。
9.2.5 空间连接
空间连接(SpatialJoin)操作根据空间关系将一个要素类的属性连接到另一个要素类的属性。目标要素和连接要素的被连接属性写入到输出要素类。
空间连接是指根据要素的相对空间位置将连接要素中的行匹配到目标要素中的行。
默认情况下,连接要素的所有属性会被追加到目标要素的属性中并复制到输出要素类。
该操作始终会向输出要素类添加两个新字段:Join_Count 和 TARGET_FID。Join_Count 指示与每个目标要素 (TARGET_FID) 匹配的连接要素数量。
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【空间连接】工具,打开【空间连接】对话窗口。
(2)在打开的【空间连接】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Overlay\ SpatialJoin” 目录下
输入要素:Input.shp
空间连接要素:Join.shp
输出要素:Input_SpatialJoin.shp
(3)【连接操作】有两个选项,“JOIN_ONE_TO_ONE”和“JOIN_ONE_TO_MANY”。
JOIN_ONE_TO_ONE—如果找到与同一目标要素存在相同空间关系的多个连接要素,将使用字段映射合并规则对多个连接要素中的属性进行聚合。例如,如果在两个独立的面连接要素中找到了同一个点目标要素,将对这两个面的属性进行聚合,然后将其传递到输出点要素类。如果一个面要素的属性值为 3,另一个面要素的属性值为 7,且指定了“总和”合并规则,则输出要素类中的聚合值将为 10。默认选项为 JOIN_ONE_TO_ONE。
JOIN_ONE_TO_MANY—如果找到多个与同一目标要素存在相同空间关系的连接要素,输出要素类将包含目标要素的多个副本(记录)。例如,如果在两个独立的面连接要素中找到了同一个点目标要素,则输出要素类将包含目标要素的两个副本,分别包含两个面的属性。
保持默认选项:“JOIN_ONE_TO_ONE”,同时勾选“保留所有目标要素”,其它默认。
(4)空间连接结果如图XX所示。
|
图XX 空间连接操作 图XX 空间连接结果 |

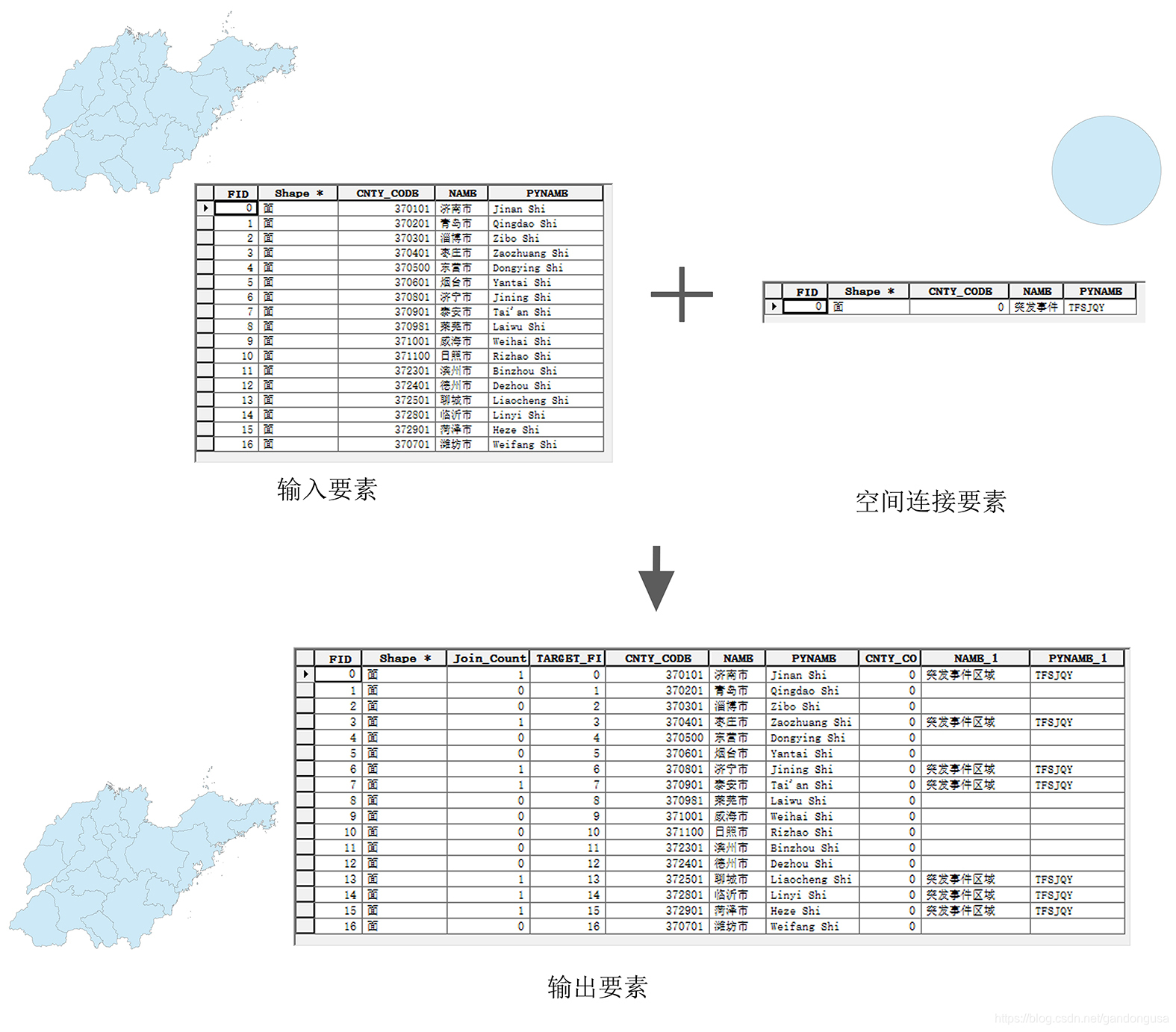
空间连接操作可以从属性表中看出哪些地市受到突发事件影响。
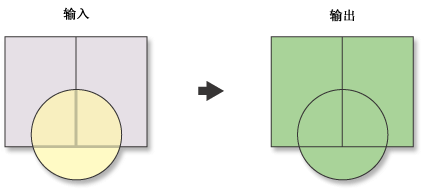
9.2.6 联合
联合(Union)操作计算输入要素的几何并集。将所有要素及其属性都写入输出要素类(图XX)。
所有输入要素类和要素图层都必须有面几何。
允许间距参数可用于连接属性参数的 ALL 或 ONLY_FID 的设置。可以识别出被生成面完全包围的生成区域。这些GAP 要素的 FID 属性将为 -1。
输出要素类将包含各个输入要素类的 FID_<name> 属性。
|
图XX 联合操作 图XX 联合对话窗口 |
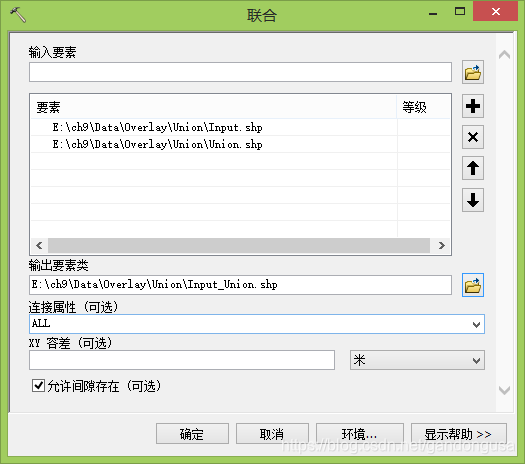
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【联合】工具,打开【联合】对话窗口。
(2)在打开的【联合】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\叠加分析\联合” 目录下
输入要素:Input.shp,Union.shp
输出要素:Input_Union.shp
(3)【连接属性】选项。
ALL:输入要素的所有属性都将传递到输出要素类。这是默认设置。
NO_FID:除 FID 外,输入要素的其余属性都将传递到输出要素类。
ONLY_FID:只有输入要素的 FID 字段将传递到输出要素类。
【连接属性】保持默认不变。
(4)【XY容差】保持默认设置。
(5)【允许间隙存在】选项。
选中状态则不为被面完全包围的输出区域创建要素。这是默认设置。 要选择此类要素,可通过判定输入要素的所有 FID 值是否均等于 -1 来查询输出要素类。
不选中状态则被面完全包围的输出区域创建要素。该要素将有空属性。
【允许间隙存在】选项保持默认勾选。
(6)联合操作结果如图XX所示。
联合操作把突发事件影响区域和山东省政区合并为一个整体。通过属性表也可以判断出受影响地市的具体范围。
|
图XX 联合结果 |
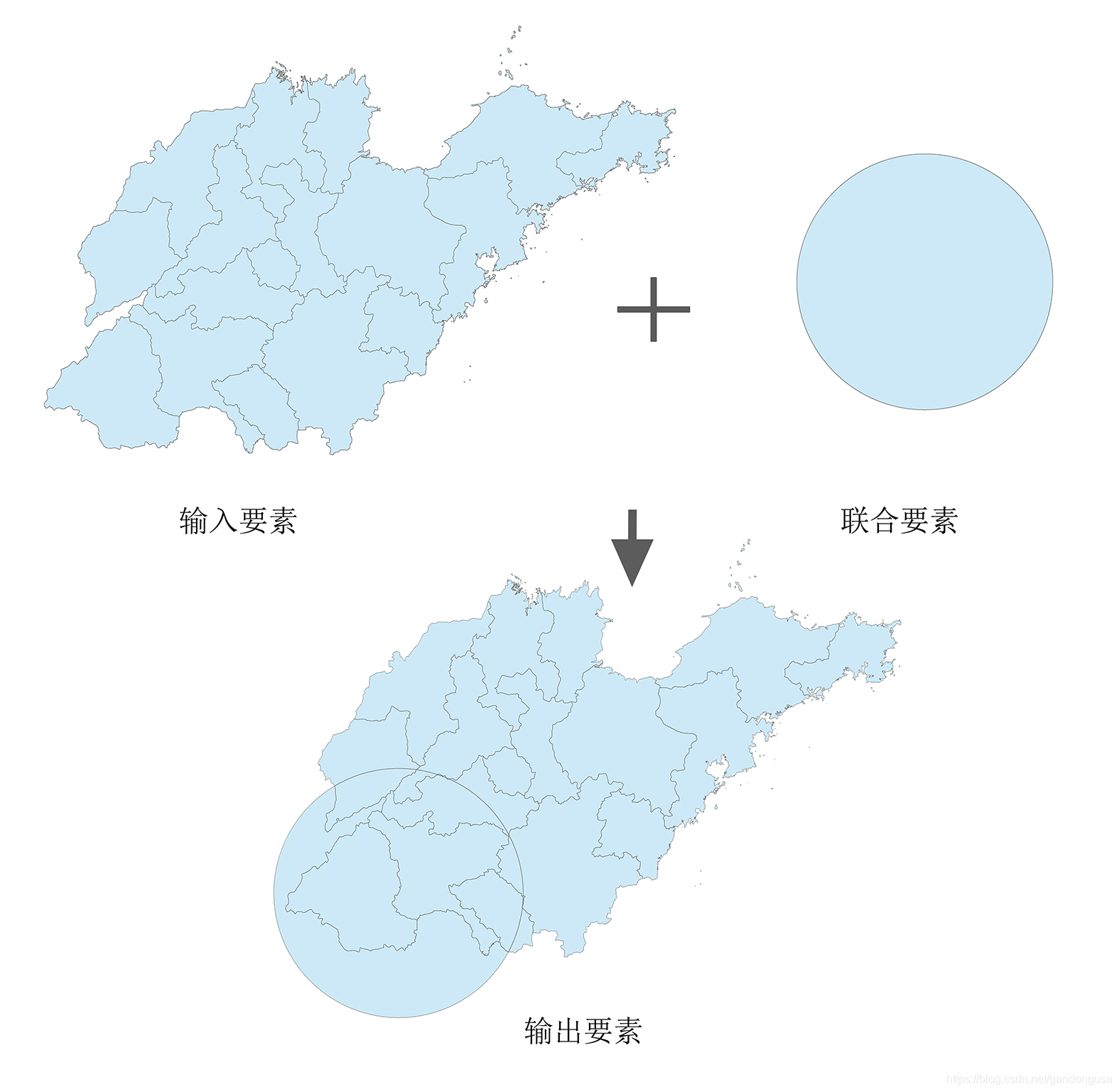
9.2.7 相交
相交(Intersect)操作计算输入要素的几何交集。所有图层和/或要素类中相叠置的要素或要素的各部分将被写入到输出要素类(图XX)。
输入要素必须是简单要素:点、多点、线或面。输入要素不能是复杂要素,比如注记要素、尺寸要素或网络要素。
如果输入具有不同几何类型(面上的线、线上的点等),则输出要素类几何类型默认与具有最低维度几何的输入要素相同。如果一个或多个输入的类型为点,则默认输出为点;如果一个或多个输入为线,则默认输出为线;如果所有输入都为面,则默认输出为面。
输出类型可以是具有最低维度几何或较低维度几何的输入要素类型。例如,如果所有输入都是面,则输出可以是面、线或点。如果某个输入类型为线但不包含点,则输出可以是线或点。如果任何一个输入是点,则输出类型只能是点。
|
图XX 相交操作 图XX 相交操作对话窗口 |

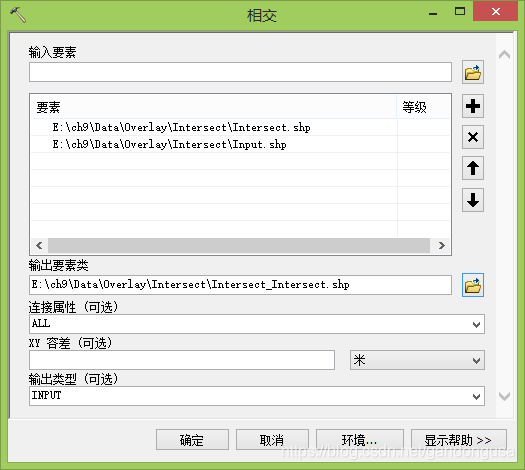
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【叠加分析】,双击【相交】工具,打开【相交】对话窗口。
(2)在打开的【相交】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Overlay\ Intersect” 目录下
输入要素:Input.shp,Intersect.shp
输出要素:Input_Intersect.shp
(3)【连接属性】选项。
ALL:输入要素的所有属性都将传递到输出要素类。这是默认设置。
NO_FID:除 FID 外,输入要素的其余属性都将传递到输出要素类。
ONLY_FID:只有输入要素的 FID 字段将传递到输出要素类。
【连接属性】保持默认不变。
(4)【XY容差】保持默认设置。
(5)【输出类型】为可选项。
INPUT:所返回相交的几何类型与具有最低维度几何的输入要素的几何类型相同。如果所有输入都是面,则输出要素类将包含面。如果一个或多个输入是线但不包含点,则输出是线。如果一个或多个输入是点,则输出要素类将包含点。这是默认设置。
LINE:将返回线相交。仅当输入中不包含点时,此选项才有效。
POINT:将返回点相交。如果输入是线或面,则输出将是多点要素类。
【输出类型】保持默认设置不变。
(6)相交操作结果如图XX所示。
|
图XX 相交结果 |
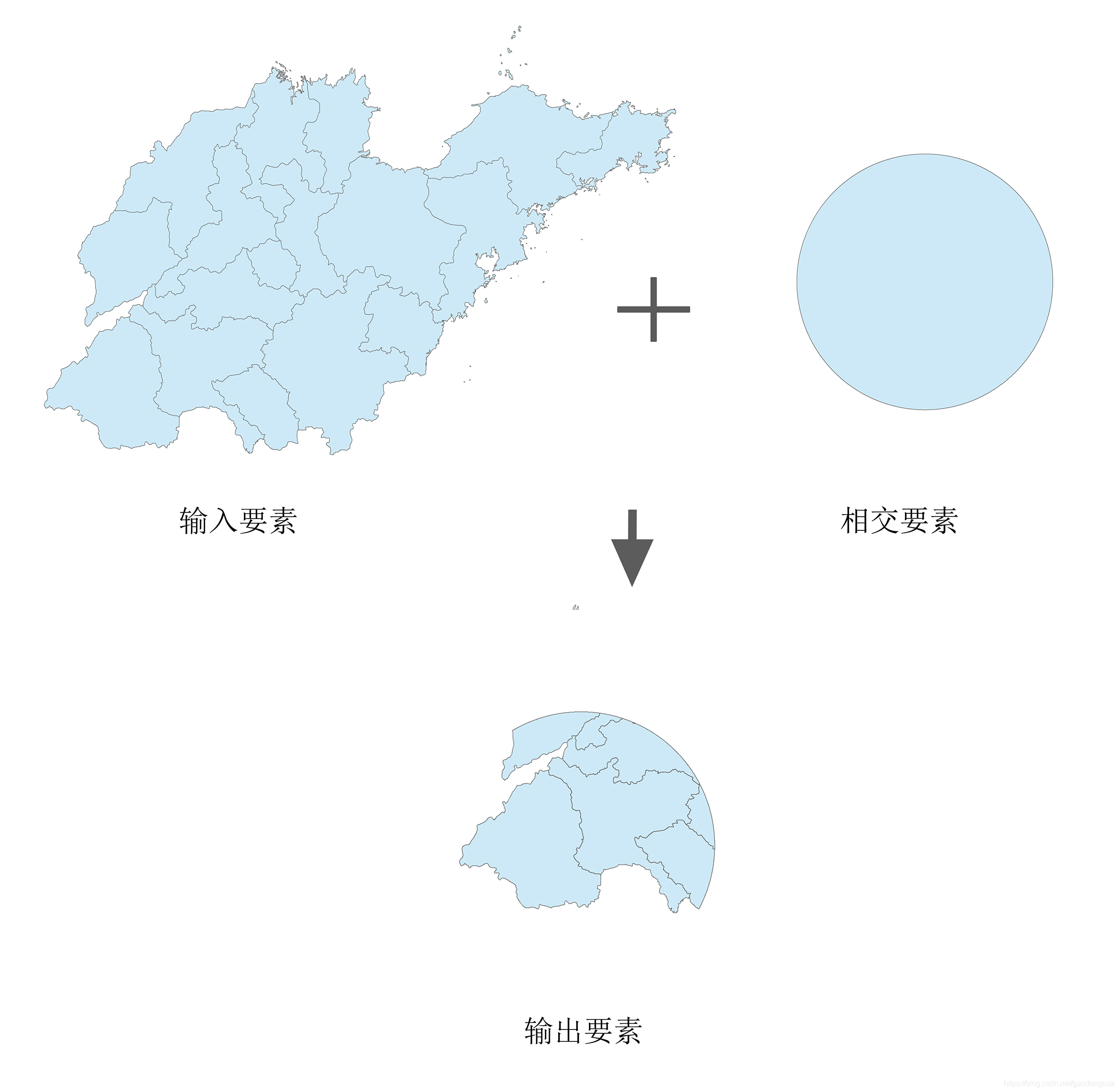
相交操作只保留受突发事件影响的山东省政区部分。
9.3 邻域分析
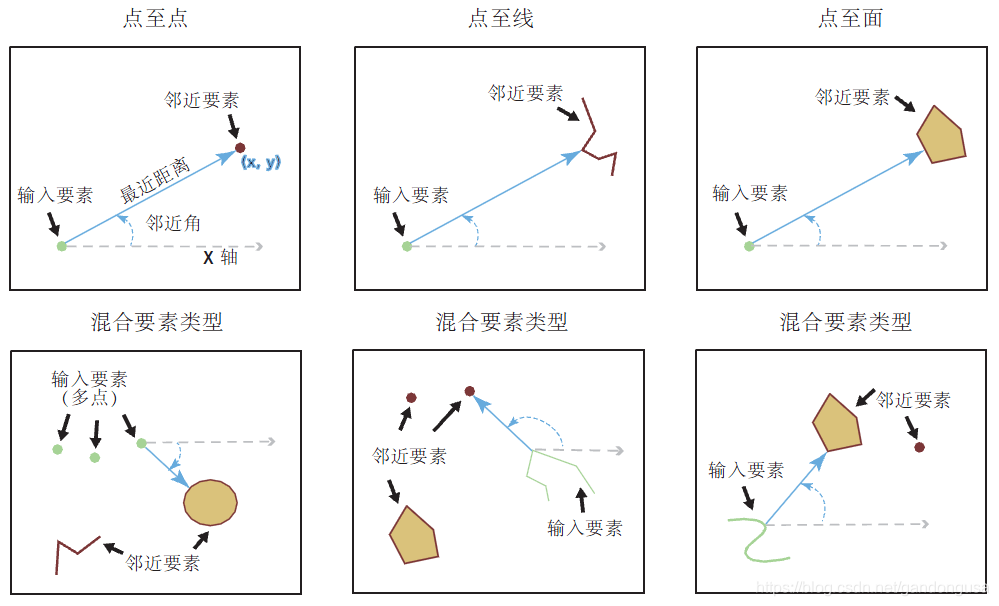
邻域分析(Proximity)是通过空间点周围的相邻点,或者特定方向范围及特定位置的相邻点,对其进行距离分析的一种方法,此方法经常用于解决“什么在什么附近”的问题。
根据分析工具所支持的输入数据类型,可以把邻域分析工具分为两大类:基于要素的邻域分析工具和基于栅格的邻域分析工具。本节只讨论基于要素的邻域分析工具,基于栅格的邻域分析工具将在《栅格数据空间分析》讲解。基于要素的邻域分析通常包括以下常用工具。
9.3.1 邻域分析计算原理
邻域分析主要分析的两个要素之间的最短距离,即两个要素彼此之间最接近的距离。ArcGIS中计算距离基于以下的规则:
Rule1: 两点间的距离是连接两点的直线距离(图XX)
|
图xx 两点间距离计算 |
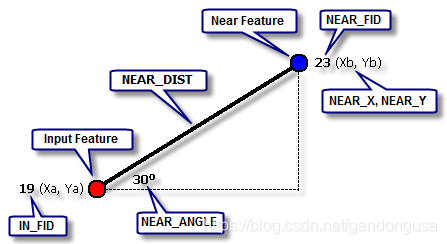
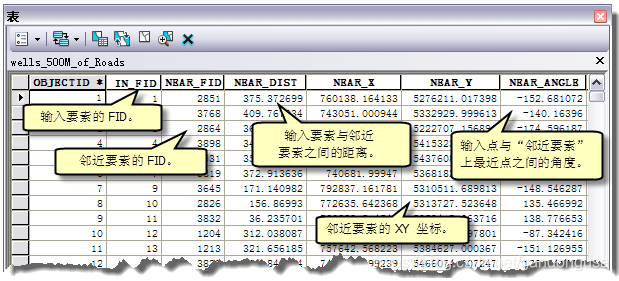
图XX中显示的关键字IN_FID、NEAR_DIST、NEAR_FID、NEAR_X、NEAR_Y 和 NEAR_ANGLE是计算距离时ArcGIS使用的默认关键字,在邻域分析工具中这些关键字添加到输入要素中。
其中:InputFeature为输入要素,IN_FID为输入要素编码;
NearFeature为邻近要素,NEAR_FID为邻近要素编码,NEAR_X、NEAR_Y为邻近要素X、Y坐标;
NEAR_ANGLE为邻近角,是指输入要素与邻近要素之间连线与水平轴之间的夹角,逆时针测量角,介于 0 与 180 度之间,顺时针测量角,介于 0 与 -180 度之间;
NEAR_DIST为输入要素与临近要素之间的距离,通过输入要素与邻近要素的坐标值计算。
当计算多点间距离时,可使用Rule1 计算输入多点要素中的每一点到邻近多点要素中的每一点的距离,这些距离中的最短距离是两个多点要素间的距离。
如果多点要素中的某一点在另一个多点要素中的某一点之上,则两个多点要素间的距离为零,这适用于所有多部分要素。
Rule2: 点到折线间的距离是点到折线的垂线或最近的折点的距离(图XX)
|
图XX 点到线段的距离 图XX 折线到折线的距离 |
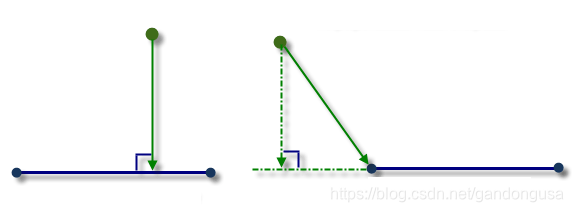
点和线段间的最短距离是点到线段的垂线。如果无法在线段的端点之间画出垂线,那么点到最近端点的距离为最短距离。
在 ArcGIS 中,线要素称为折线。线和折线这两个术语可互换。折线是点的有序集合,这些点称为折点。"vertex" 是 "vertice" 的单数形式。一条折线可以拥有任意多的折点。由两个折点定义的线叫做线段。定义一条线段的两个折点称为端点。同理,面是由一条或多条折线定义的封闭区域。
如果折线只有一条线段,可使用Rule 2 得出该距离。当折线有多条线段时,先确定与点距离最近的线段,之后使用Rule2 得出该距离。
面是由有序线段集合围成的封闭区域,因此计算点到面的距离首先要确定与点距离最近的线段,之后使Rule2 得出该距离。仅当点位于面外时距离为正值;否则,距离为零。
Rule3: 折线间的距离取决于线段折点间的距离
对于线段要素计算两条线段的最近距离可以通过以下方法计算:
(1)使用规则 2 计算输入线段的每个端点到邻近线段的距离。
(2)计算出邻近线段的每个端点到输入线段的距离。
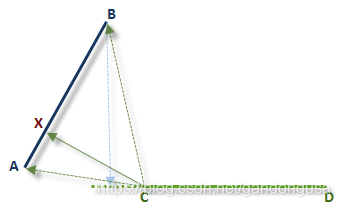
折线到折线距离:假设每个折线要素都有一条线段。图XX显示从折点 C 到由折点 AB 定义的线段的垂线 CX。也可以计算从折点 D 到线段的垂线,但是该距离长于 CX。因此,CX 是从线段 CD 到线段 AB 的最短距离。
因为无法画出从折点 A 或 B 到线段 CD 的垂线,因此要从折点 A 或 B 到折点 C 计算最短距离。结果是 AC 为线段 AB 到线段 CD 的最短距离。
在两个计算出的距离(AC 和 CX)中,因为 CX 在所有折点到线段的距离中最短,因此它是两条线段间的最短距离。
折线到面的距离:当计算折线和面之间的距离时,要确定最近的两条线段:一条来自折线,另外一条来自组成面边界的一系列线段。按照Rule3计算两条线段间的距离。
表XX显示如何计算不同要素类型间的距离以及如何按照上述内容确定最近位置。
| 输入要素 | 邻近要素 | ||||
|
| 点 | 多点 | 线 | 面 | |
| 点 |
|
|
|
| |
| 多点 |
|
|
|
| |
| 线 |
|
|
|
| |
| 面 |
|
|
|
| |










9.3.2 点距离
点距离指在某一指定搜索半径范围内,确定输入点要素与邻近要素中所有点之间的距离(图XX)。
|
图XX 点距离示意 图XX 点距离对话窗口 |

如果使用默认搜索半径计算所有输入点与所有邻近点之间的距离,则此工具将创建两组点之间的距离表,若点数量非常多则输出表可能非常大。
结果将记录在输出表中,其中包含以下信息:
INPUT_FID:输入要素的要素 ID ;NEAR_FID:邻近要素的要素 ID ;DISTANCE:输入要素与邻近要素之间的距离。
输入要素和邻近要素可以是相同的数据集。在此情况下,如果输入要素和邻近要素是相同的记录,将忽略这一结果,这样就不会报告与一个要素的距离是 0 个单位的要素本身。
具体操作过程为:
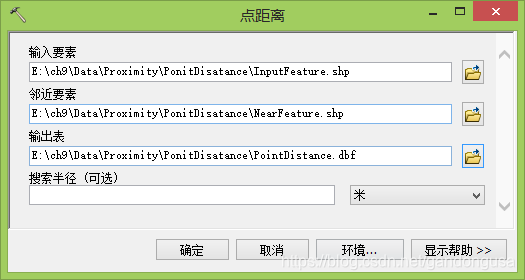
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【点距离】工具,打开【点距离】对话窗口。
(2)在打开的【点距离】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\ Proximity \PointDistance” 目录下
输入要素:InputFeature.shp
邻近要素:NearFeature.shp
输出表: PointDistance.dbf
搜索半径:保持默认。保持默认不填写即为搜索全部要素。
(3)生成的距离表如图XX所示。
|
图XX 距离表 |
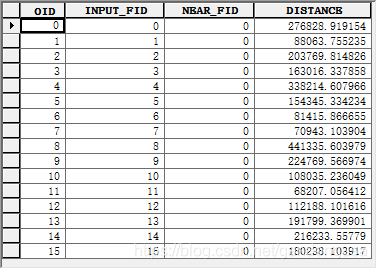
此表中输入要素为除济南市之外的其它16个地市,邻近要素为济南市,输出表中距离为16个地市距离济南市的距离,单位为m。
9.3.3 近邻分析
近邻分析是指在搜索半径范围内,确定输入要素中的每个要素与邻近要素中的最近要素之间的距离(图XX)。
NEAR_FID和NEAR_DIST两个字段将被添加到输入要素的属性表中。如果字段已存在,将更新字段值。
NEAR_FID存储最近要素的要素 ID;NEAR_DIST存储输入要素与最近要素之间的距离。如果在搜索半径内未找到任何要素,则 NEAR_FID 和 NEAR_DIST 的值都将为 -1。
也可将 NEAR_X、NEAR_Y、NEAR_ANGLE 和 NEAR_FC 字段添加到输入要素的属性表中。如果字段已存在,将更新字段值。如果在搜索半径内未找到任何要素,则字段 NEAR_X 和 NEAR_Y 的值为 -1,字段 NEAR_ANGLE 的值为 0,字段 NEAR_FC 的值为空。
输入要素和邻近要素均可为点、多点、线或面。
邻近要素可包括一个要素类或不同 shape 类型的多个要素类。
同一数据集既可用作输入要素,又可用作邻近要素。当输入要素的最近要素是其本身(NEAR_DIST 为 0)时,此要素将在计算中被忽略,并将搜索除此要素之外的最近要素。
当多个邻近要素与输入要素之间的最短距离相同时,随机选择其中一个邻近要素来作为最邻近要素。
|
图XX近邻分析示意 |
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【近邻分析】工具,打开【近邻分析】对话窗口。
(2)在打开的【近邻】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Proximity\ NearAnalysis” 目录下
输入要素:InputFeature.shp,本操作不会生成新的要素图层,会在输入要素中直接更新生成新的属性;
邻近要素:NearFeature.shp
搜索半径:保持默认。保持默认不填写即为搜索全部要素。
|
图XX 近邻分析对话窗口 |
(3)【位置】选项。
未选中: 指定不写入最近位置的x和y坐标。这是默认设置。
选中:指定将最近位置的x坐标和y坐标写入 NEAR_X 和 NEAR_Y 字段。
勾选【位置】选项前的对勾。
(4)【角度】选项。
未选中:指定将不写入邻近角值。这是默认设置。
选中:指定将邻近角值写入 NEAR_ANGLE 字段。
勾选【角度】选项前的对勾。
(5)生成的近邻分析图层属性表如图XX所示。
|
图XX 近邻分析属性表结果 |
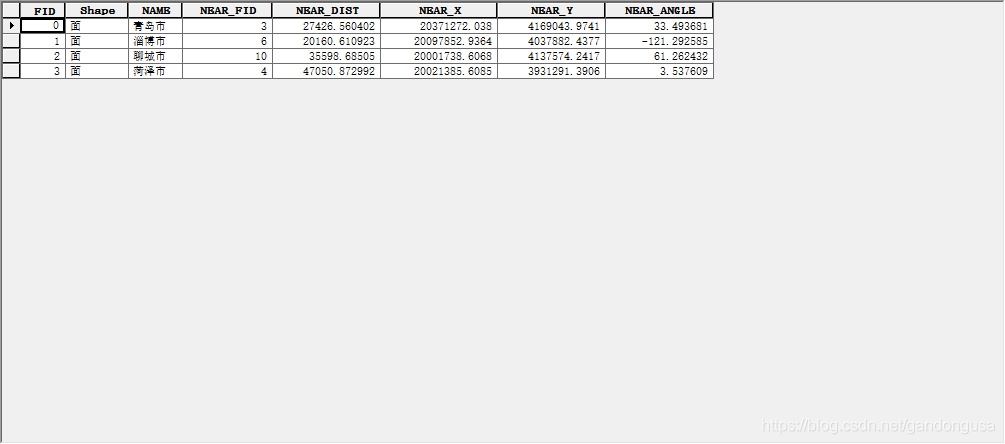
输入要素为山东省4个地市的面图层,临近要素为除此之外的13个地市点要素,生成的近邻分析属性表中显示的是与4个地市距离最近的点要素及其相关属性。
近邻分析和点距离均会将距离信息返回为数值属性,不同的是,对于近邻分析,将返回到输入点要素属性表中,而对于点距离,则返回到包含“输入要素”及“邻近要素”要素 ID 的独立表中。
9.3.4 生成近邻表
生成近邻表操作在搜索半径范围内,确定输入要素中的每个要素与邻近要素中的一个或多个附近要素之间的距离。结果将记录在输出表中(图XX)。
|
图XX 生成近邻表示意 |
此工具和近邻分析工具类似。但该工具不更新输入要素,而是创建一个新的输出表。而且,该工具能够发现和最接近匹配项的最大数量参数指定的数量一样多的邻近要素。
默认情况下,输出表包含三个字段:IN_FID、NEAR_FID 和 NEAR_DIST。其他字段则根据所选的可选参数(在参数条目中说明)添加到输出。
IN_FID:存储输入要素的要素ID;NEAR_FID:存储最近要素的要素ID;NEAR_DIST:存储输入要素与最近要素之间的距离。
可以使用 IN_FID 或 NEAR_FID 字段将输出表连接回输入要素类或邻近要素类中。
输入要素和邻近要素均可为点、多点、线或面。
该工具的默认选项是要找到从每个输入要素到最近的邻近要素的距离。选择 ALL 选项,即取消取中仅查找最近的要素参数来创建包含所有输入和所有邻近要素之间的距离的表。
如果在搜索半径内未找到任何要素,则 NEAR_FID 和 NEAR_DIST 的值都将为 -1。
输入要素和邻近要素可以是相同的数据集。在此情况下,如果输入要素和邻近要素是相同的记录,将忽略这一结果,这样就不会报告与一个要素的距离是 0 个单位的要素本身。
输入要素可以是您已执行要素选择的图层。使用工具执行操作时将使用并更新所选要素。其余要素将新建字段(例如 NEAR_FID 和 NEAR_DIST)的值设置为 -1。
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【生成近邻表】工具,打开【生成近邻表】对话窗口。
(2)在打开的【生成近邻表】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Proximity\ GenerateNearTable” 目录下
输入要素:InputFeature.shp,
邻近要素:NearFeature.shp
输出要表:GenerateNearTab.dbf
搜索半径:保持默认。保持默认不填写即为搜索全部要素。
|
图XX 生成近邻表对话窗口 |

(3)【位置】选项。
未选中: 指定不写入最近位置的x和y坐标。这是默认设置。
选中:指定将最近位置的x坐标和y坐标写入 NEAR_X 和 NEAR_Y 字段。
勾选【位置】选项前的对勾。
(4)【角度】选项。
未选中:指定将不写入邻近角值。这是默认设置。
选中:指定将邻近角值写入 NEAR_ANGLE 字段。
勾选【角度】选项前的对勾。
(5)生成的近邻表如图XX所示。
|
图XX 生成近邻表结果 |
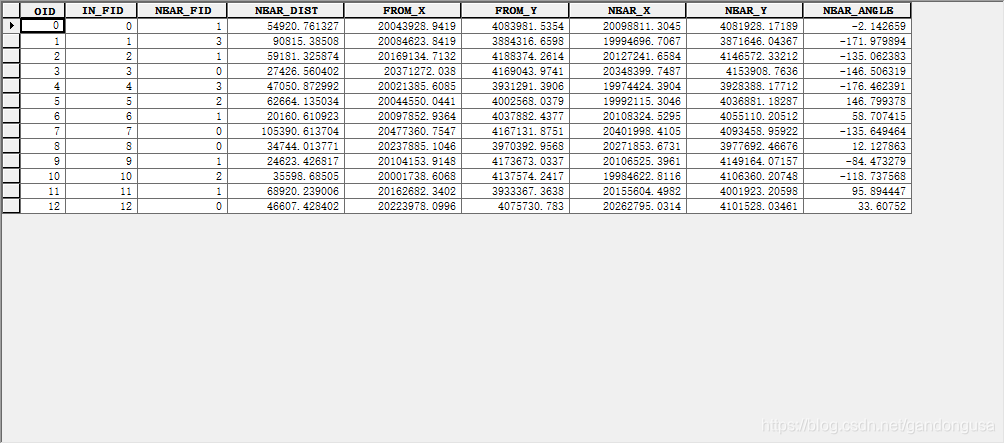
输入要素为山东省13个地市的点图层,临近要素为除此之外的4个地市面要素,生成的近邻分析表中显示的是与13个地市距离最近的面要素及其相关属性。
9.3.5 面邻域
面邻域操作根据面邻接关系(重叠、重合边或结点)创建统计数据表(图XX)。
|
图XX 面邻域示意 图XX 面邻域对话窗口 |
此工具用于分析面邻接,汇总源面和邻域面之间的重叠面积(重叠邻域(可选))、重合边的长度(边邻域)、边界在某一点处交叉或接触的次数(结点邻域)。
并将汇总信息写入输出表。源面可能具有一个或多个邻域面;邻域面是以至少一种上述方式与源面相关联的空间。
输出表包含下列字段:
src_fiel:前缀 src 表示源;该字段是按字段报告参数所使用的一个字段,例如 src_MYID。您可以获得在按字段报告参数中指定的多个此类字段。
nbr_field:前缀 nbr 表示邻域;该字段是按字段报告参数所使用的一个字段,例如 nbr_MYID。与 src 字段类似,您可以获得在按字段报告参数中指定的多个此类字段。
AREA:此字段用于存储源面和邻域面(重叠邻域)的总重叠面积。只有选中了包括区域重叠参数 (area_overlap = "AREA_OVERLAP"),输出表中才包括此字段。
LENGTH:此字段用于存储源面和邻域面之间重合边的总长度。
NODE_COUNT:此字段用于存储源面和邻域面在某一点处交叉或接触的次数。
具体操作步骤为:
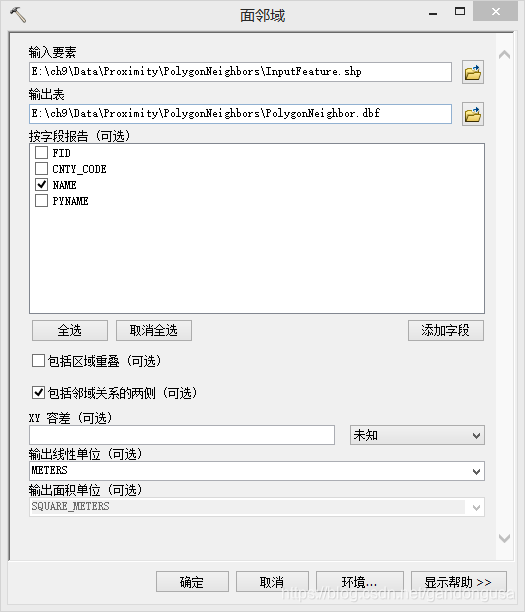
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【面邻域】工具,打开【面邻域】对话窗口。
(2)在打开的【面邻域】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Proximity\ PolygonNeighbors” 目录下
输入要素:InputFeature.shp,
输出要素:PolygonNeighbor.dbf
(3)按字段报告选项中,选择NAME字段。
(4)【包括区域重叠】选项
未选中:不会在输出中分析和包括重叠关系。这是默认设置。
选中:会在输出中分析和包括重叠关系。
【包括区域重叠】选项保持默认设置。
(5)【包括邻域关系的两侧】选项。
选中:对于邻域面对,同时报告两种邻域信息:一个面是源且另一个面是邻域以及一个面是邻域且另一个面是源。这是默认设置。
未选中:对于邻域面对,仅报告一个面是源且另一个面是邻域的邻域信息。不包括相互关系。
【包括邻域关系的两侧】选项保持默认设置。
(6)【XY容差】保持默认设置。
(7)【输出线性单位】和【输出面积单位】保持默认。
(8)面邻域输出结果如图XX所示。
|
图XX 面邻域结果 |
面邻域分析可以得到与山东省每个地市相邻的地市有哪些并同时获得其它相关信息。
9.3.6.3 缓冲区分析
ArcGIS生成缓冲区有两种主要的方法:利用缓冲区工具或者利用缓冲区向导。
9.3.6.3.1 缓冲区工具
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【缓冲区】工具,打开【缓冲区】对话窗口。
或者在ArcMap中单击【地理处理】菜单,选择其下的【缓冲区】,打开【缓冲区】对话窗口。
(2)在打开的【缓冲区】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Proximity\Buffer” 目录下
输入要素:Input.shp
输出要素类:Buffer_Tools.shp
距离项选择【字段】:Distance
|
图XX 缓冲区对话窗口 图XX 缓冲区结果 |

(3)【侧类型】选项。
FULL:对于线输入要素,将在线两侧生成缓冲区。对于面输入要素,将在面周围生成缓冲区,并且这些缓冲区将包含并叠加输入要素的区域。对于点输入要素,将在点周围生成缓冲区。这是默认设置。
LEFT:对于线输入要素,将在线的拓扑左侧生成缓冲区。此选项对于面输入要素无效。
RIGHT:对于线输入要素,将在线的拓扑右侧生成缓冲区。此选项对于面输入要素无效。
OUTSIDE_ONLY:对于面输入要素,仅在输入面的外部生成缓冲区(输入面内部的区域将在输出缓冲区中被擦除)。此选项对于线输入要素无效。
【侧类型】选项保持默认不变。
(4)【末端类型】选项。
线输入要素末端的缓冲区形状。此参数对于面输入要素无效。
ROUND:缓冲区的末端为圆形,即半圆形。这是默认设置。
FLAT:缓冲区的末端很平整或者为方形,并且在输入线要素的端点处终止。
本例中输入要素为面要素,故本选项为灰色不可选。
(5)【融合类型】选项。
NONE:无论如何重叠,均保持每个要素的独立缓冲区。这是默认设置。
ALL:将所有缓冲区融合为单个要素,从而移除所有重叠。
LIST:融合共享所列字段(传递自输入要素)属性值的所有缓冲区。
【融合类型】选项保持默认不变。
(6)【融合字段】选项。
融合输出缓冲区所依据的输入要素的字段列表进行缓冲区生成。当【融合类型】为LIST时本选项可用。
(7)缓冲区生成结果如图XX所示。
9.3.6.3.2 缓冲区向导
缓冲区向导工具提供向导式操作过程,建立缓冲区只需按照向导提示设置相应的参数即可。【缓冲向导】工具默认不包含在相应的工具条中,需要添加才能使用。
(1)在ArcMap中工具条空白处右键单击,选择【自定义】,打开【自定义】对话窗口。选择【命令】选项卡,在【类别】下选项中,定位到【工具】,并从右侧的命令找到【缓冲向导】(图XX)。拖动【缓冲向导】命令到已有的工具条上添加该命令。
|
图XX 缓冲向导工具 图XX 缓冲区向导一 |

(2)双击工具条上添加的【![]() 缓冲向导】工具,打开【缓冲向导】对话窗口。
缓冲向导】工具,打开【缓冲向导】对话窗口。
(3)在打开的缓冲向导窗口中,图层中的要素选择:Input.shp。
选择之后会列出要素数目为3。如果要进行缓冲分析的图层没有出现,需要利用ArcMap中的【![]() 添加数据】添加数据到ArcMap中才能进行缓冲区操作(图XX)。
添加数据】添加数据到ArcMap中才能进行缓冲区操作(图XX)。
选择完成后单击【下一步】。
(4)在缓冲距离选择窗口中,选择:以制定的距离,5000米,修改下方的缓冲距离单位:米。(图XX)
选择完成之后单击【下一步】。
|
图XX缓冲区向导二 图XX缓冲区向导三 |


(5)在出现的缓冲区类型、缓冲区范围和缓冲区保存位置中设置相应的选项即可。
缓冲区输出类型包含两种选项:融合和不融合。
创建缓冲区的位置根据缓冲的要素是点要素、线要素还是面要素,有不同的选择类型。当是点要素和线要素时,该选项为灰色不可选状态,当是面要素时为可选项。可以定义面要素生成的缓冲区的位置是面内部、外部、内外皆有等。通过选取相应的选项,右侧会显示该选项的示意图,方便选择(图XX)。
设置完成后,单击【完成】,完成向导。
|
图XX 缓冲结果示意 |
(6)生成的结果如图XX所示。
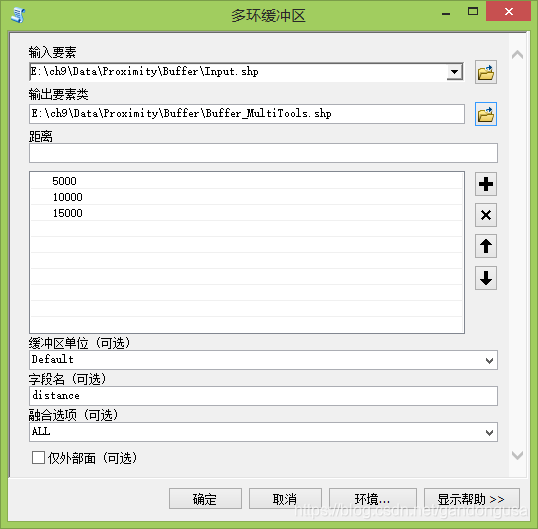
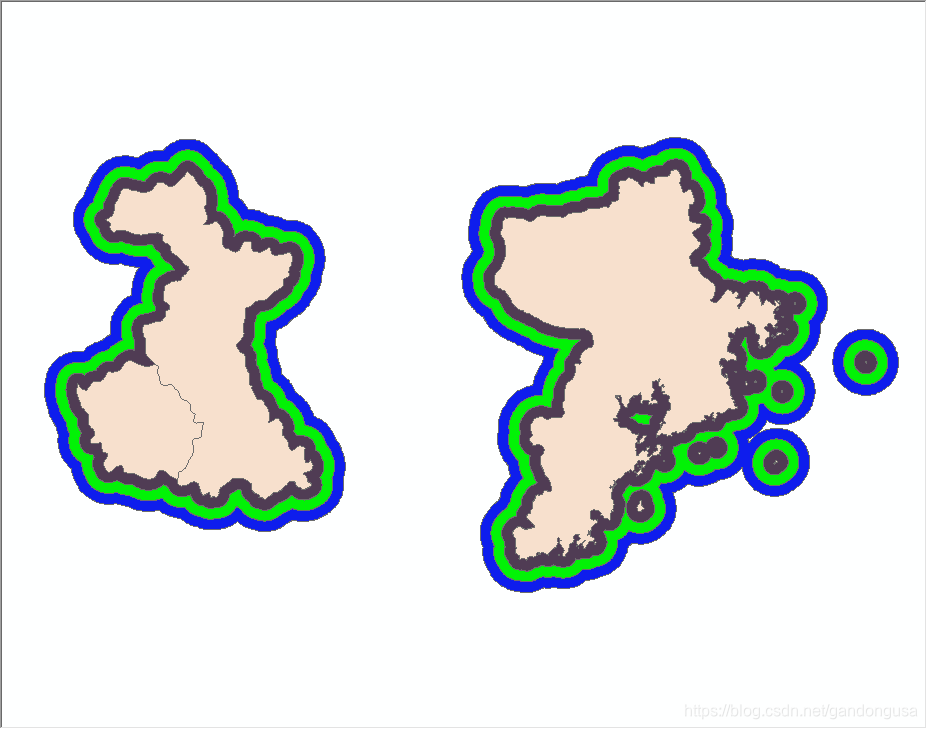
9.3.6.3.3 多环缓冲区
在输入要素周围的指定距离内创建多个缓冲区(图XX)。使用缓冲距离值可随意合并和融合这些缓冲区,以便创建非重叠缓冲区。
|
图XX 多环缓冲区 图XX 多环缓冲区对话窗口 |

具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【多环缓冲区】工具,打开【多环缓冲区】对话窗口。
(2)在打开的【多环缓冲区】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Proximity\Buffer” 目录下
输入要素:Input.shp
输出要素类:Buffer_MultiTools.shp
距离项输入5000后点击右侧“+”添加至列表中,再次按照相同的方式添加数值:10000,15000。
(3)【缓冲区单位】选项。
与“距离”值一起使用的线性单位。如果未指定单位,或者输入了“默认”,则将使用输入要素空间参考的线性单位。如果将“缓冲区单位”指定为“默认”并设置了“输出坐标系”地理处理环境,则将使用其线性单位。
国内地形图测量基本单位为米,【缓冲区单位】保持默认即可。
(4)【字段名】选项。
输出要素类中的字段名称,其中存储用于创建每个缓冲区要素的缓冲距离。如果未指定名称,则默认字段名称为“distance”。此字段类型为“双精度”。
【字段名】选项保持默认。
(5)【融合选项】选项
确定是否要像围绕输入要素的环一样融合缓冲区。
ALL:缓冲区将是输入要素周围不重叠的圆环(将其视为输入要素周围的圆环)。最小缓冲区将覆盖其输入要素加上缓冲距离的区域,后续缓冲区将是围绕最小缓冲区的环形,该最小缓冲区不覆盖输入要素或较小缓冲区的区域。相同距离的所有缓冲区都将融合到单个要素中。这是默认设置。
NONE:不论是否重叠,都会保存所有缓冲区域。每个缓冲区均会覆盖其输入要素加上任何较小缓冲区的区域。
【融合选项】选项保持默认。
(6)【仅外部面】选项
确定缓冲区是否覆盖输入要素。仅对面输入要素有效。
未选中: 缓冲区会叠加或覆盖输入要素。这是默认设置。
选中:缓冲区将是围绕输入要素的环,并且不会叠加或覆盖输入要素(输入面内部的区域将从缓冲区中擦除)。
【仅外部面】选项保持默认为选中。
(7)生成的多环缓冲区结果如图XX所示。
|
图XX 多环缓冲区示意 |
9.3.7泰森多边形
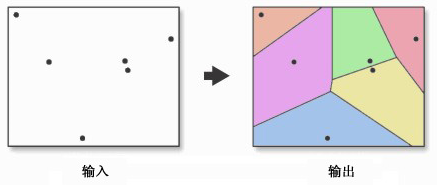
荷兰气候学家A·H·Thiessen提出了一种根据离散分布的气象站的降雨量来计算平均降雨量的方法,即将所有相邻气象站连成三角形,作这些三角形各边的垂直平分线,于是每个气象站周围的若干垂直平分线便围成一个多边形。用这个多边形内所包含的一个唯一气象站的降雨强度来表示这个多边形区域内的降雨强度,并称这个多边形为泰森多边形(ThiessenPolygons)。泰森多边形每个顶点是每个三角形的外接圆圆心。泰森多边形也称为Voronoi图,或dirichlet图。
泰森多边形的特性是(图XX):
(1)每个泰森多边形内仅含有一个点输入要素;
(2)泰森多边形内的点到相应离散点的距离最近;
(3)位于泰森多边形边上的点到其两边的离散点的距离相等。
泰森多边形可用于定性分析、统计分析、邻近分析等。例如,可以用离散点的性质来描述泰森多边形区域的性质;可用离散点的数据来计算泰森多边形区域的数据;判断一个离散点与其它哪些离散点相邻时,可根据泰森多边形直接得出,且若泰森多边形是n边形,则就与n个离散点相邻;当某一数据点落入某一泰森多边形中时,它与相应的离散点最邻近,无需计算距离。
|
图XX 泰森多边形 图XX 泰森多边形构建方法 |

创建泰森多边形的理论背景为:
(1)S 是坐标或欧氏空间 (x,y) 中点的集合,对于该空间中的任意点 p,S 中有一个与 p 相距最近的点,除非点 p 与 S 中的两个或多个点的距离相等。
(2)由到 S 中的单个点的距离最近的所有点 p 定义单个邻近多边形(Voronoi 像元),即所有点 p 到 S 中的给定点的距离比到 S 中的任何其他点的距离都近的全部区域。
构造泰森多边形步骤为:
(1)在所有点中划分出符合 Delaunay 准则的不规则三角网 (TIN)。
(2)三角形各边的垂直平分线即可形成泰森多边形的边。各平分线的交点决定泰森多边形折点的位置。
具体操作步骤为:
(1)在ArcMap【目录列表】窗口中定位到【系统工具箱】--【Analysis Tools】--【邻域分析】,双击【创建泰森多边形】工具,打开【创建泰森多边形】对话窗口。
(2)在打开的【创建泰森多边形】对话窗口中设置如下(图XX):
数据位置:“\ch9\Data\Proximity\ Thiessen” 目录下
输入要素:Input.shp
输出要素类:Thiessen.shp
(3)【输出字段】选项。
确定点输入要素的哪些属性将传递到输出要素类。
ONLY_FID:仅输入要素的 FID 字段将传递到输出要素类。这是默认设置。
ALL:输入要素的所有属性都将传递到输出要素类。
【输出字段】选项选择“ALL”。
(4)泰森多边形结果如图XX所示。
|
图XX 泰森多边形对话窗口 图XX 泰森多边形结果 |


9.4 统计分析
统计分析工具不仅包含对属性数据执行标准统计分析(例如平均值、最小值、最大值和标准差)的工具,也包含对重叠和相邻要素计算面积、长度和计数统计的工具。
9.4.1 汇总统计数据
汇总统计数据操作计算表中字段的汇总统计数据。通过【汇总统计数据】可以统计的类型有:
SUM:添加指定字段的合计值。
MEAN:计算指定字段的平均值。
MIN:查找指定字段所有记录的最小值。
MAX:查找指定字段所有记录的最大值。
RANGE:查找指定字段的值范围 (MAX - MIN)。
STD:查找指定字段中值的标准差。
COUNT:查找统计计算中包括的值的数目。计数范围包括除空值外的每个值。要确定字段中的空值数,请在相应字段上使用 COUNT 统计,然后在另一个不包含空值的字段上使用 COUNT 统计(例如 OID,如果存在的话),然后将这两个值相减。
FIRST:查找“输入表”中的第一条记录,并使用该记录的指定字段值。
LAST:查找“输入表”中最后一条记录,并使用该记录的指定字段值。
9.4.2 交集制表
交集制表操作计算两个要素类之间的交集并对相交要素的面积、长度或数量进行交叉制表(图XX)。
|
图XX 交集制表 |
9.4.3 频数
频数操作读取表和一组字段,并创建一个包含唯一字段值以及各唯一字段值所出现次数的新表。
9.5 矢量分析综合实例
实例为ATM取款机选址分析,综合利用矢量分析中的缓冲区分析和叠加分析确定新设ATM取款机的区域。
9.5.1 背景与需求分析
ATM取款机作为人们生活中不可或缺一部分,正发挥着越来越重要的作用。ATM取款机的合理布设能够方便人们的生活,得到较高的生活品质。利用ArcGIS的空间分析功能对新建ATM取款机的位置进行分析,合理的布设ATM取款机。
ATM取款机选址空间分析用到的数据包括:
本例用到的数据位于:“\ch9\Data\Example”目录下
(1)原有ATM取款机分布图:ATM.shp
(2)居民点分布图:Residential.shp
(3)商场超市分布图:Market.shp
(4)道路交通图:Road.shp
9.5.2 选址条件分析
ATM取款机选址空间分析要满足的条件为:
(1)距离原有的ATM取款机200m以外,避免重复建设,减少浪费;
(2)要在距离居民点500m范围之内,减少居民出行距离;
(3)距离商场超市距离小于300m,方便取款;
(4)距离道路距离小于80m,保证取款的交通顺畅和快捷。
9.5.3 操作步骤
定位到“\ch9\Data\Example”目录下,打开“Ex01.mxd”文档,里面加载四个图层。
9.5.3.1 原有ATM取款机影响范围
ArcMap中单击【地理处理】下拉菜单,选择【缓冲区】命令,打开【缓冲区】窗口。
在打开的【缓冲区】对话窗口中设置如下(图XX):
输入要素:ATM
输出要素类:\ch9\Data\Example\ATM_Buffer.shp
距离:线性单位,200m
其它默认.
原有ATM取款机影响范围缓冲区结果如图XX所示。
|
图XX ATM缓冲区对话窗口 图XX ATM影响范围 |

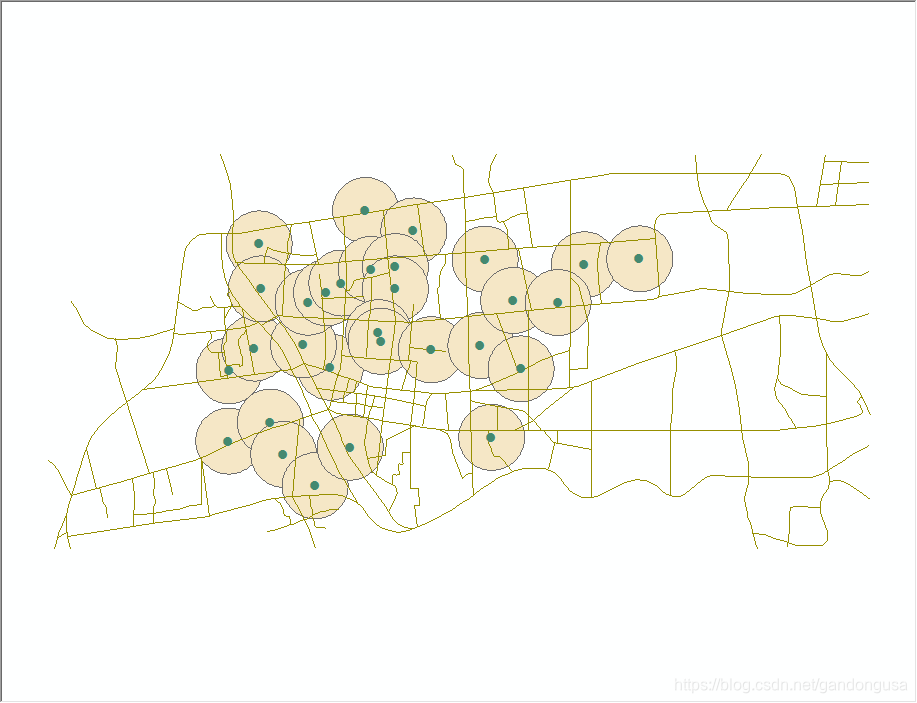
9.5.3.2 居民点影响范围
ArcMap中单击【地理处理】下拉菜单,选择【缓冲区】命令,打开【缓冲区】窗口。
在打开的【缓冲区】对话窗口中设置如下(图XX):
输入要素:Residential
输出要素类:\ch9\Data\Example\Residential_Buffer.shp
距离:线性单位,500m
其它默认.
居民点影响范围缓冲区结果如图XX所示。
|
图XX 居民点缓冲区对话窗口 图XX 居民点影响范围 |

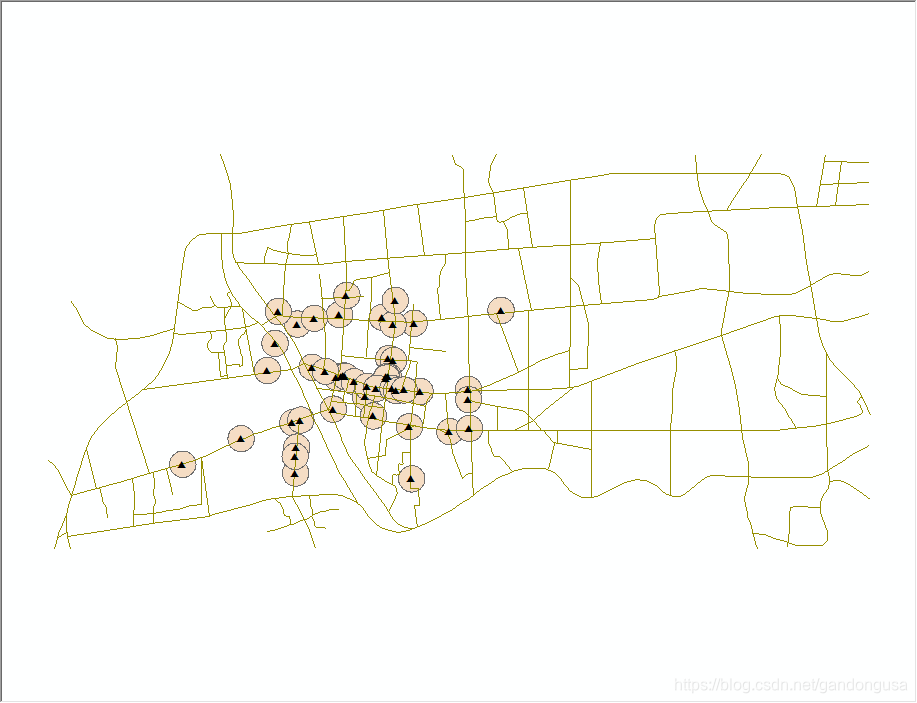
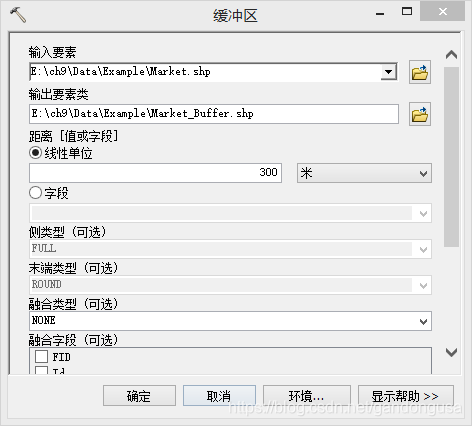
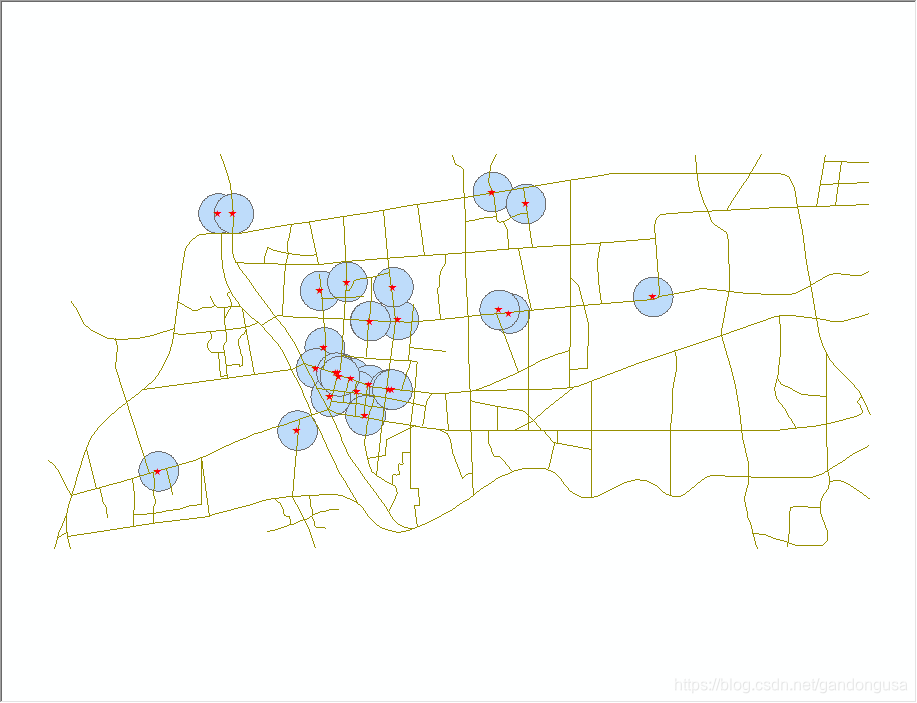
9.5.3.3 商场超市影响范围
ArcMap中单击【地理处理】下拉菜单,选择【缓冲区】命令,打开【缓冲区】窗口。
在打开的【缓冲区】对话窗口中设置如下(图XX):
输入要素:Market
输出要素类:\ch9\Data\Example\Market_Buffer.shp
距离:线性单位,300m
其它默认.
超市商场影响范围缓冲区结果如图XX所示。
|
图XX 商场超市缓冲区对话窗口 图XX 商场超市影响范围 |
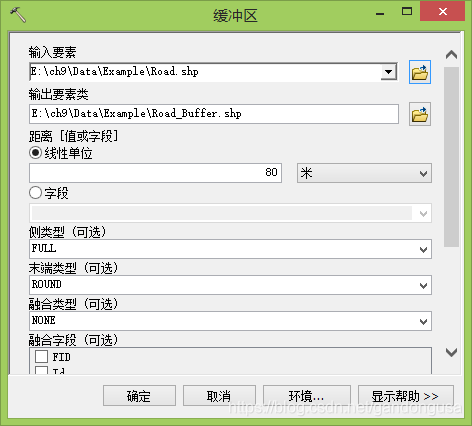
9.5.3.4 道路影响范围
ArcMap中单击【地理处理】下拉菜单,选择【缓冲区】命令,打开【缓冲区】窗口。
在打开的【缓冲区】对话窗口中设置如下(图XX):
输入要素:Road
输出要素类:\ch9\Data\Example\Road_Buffer.shp
距离:线性单位,80m
其它默认.
道路影响范围缓冲区结果如图XX所示。
|
图XX 道路缓冲区对话窗口 图XX 道路影响范围 |
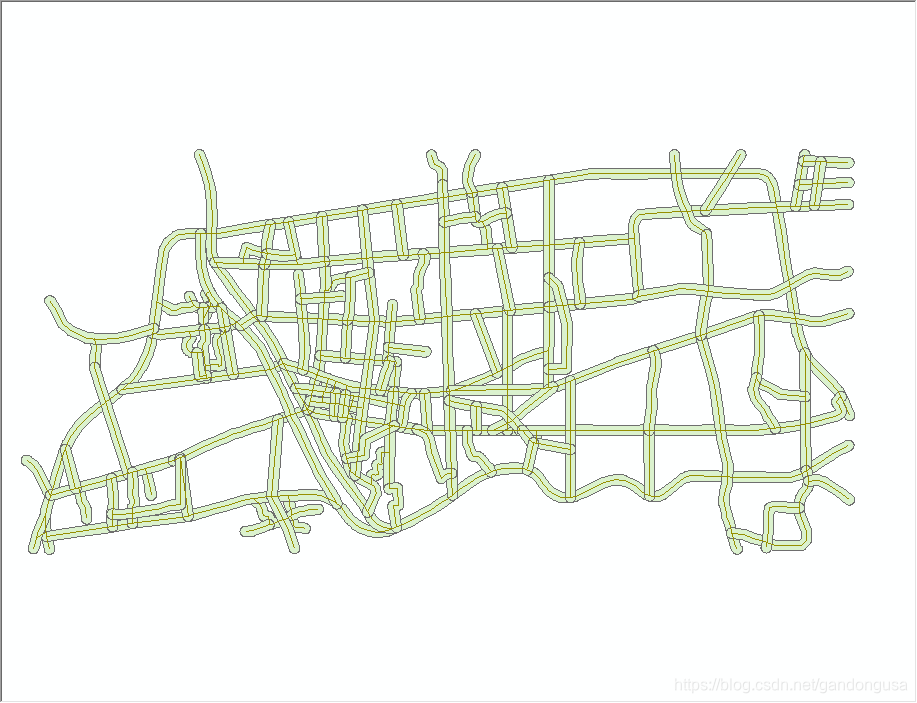
9.5.3.5 选址区域确定
ATM取款机选址的求解分为两个步骤,首先需要求解出满足居民点、商场超市和道路距离缓冲范围的区域,然后根据求解出的满足上面三个条件的区域减去原有ATM缓冲区的区域,即可得到新的ATM取款机布设的新区域。
(1)计算Residential_Buffer、Market_Buffer和Road_Buffer三个图层的交集区域,具体操作步骤为:
ArcMap中【目录列表】定位到【工具箱】--【系统工具箱】--【Analyst Tools】--【叠加分析】--【相交】,打开【相交】对话窗口。
在打开的【相交】对话窗口中设置如下(图XX):
输入要素:Residential_Buffer、Market_Buffer和Road_Buffer
输出要素类:\ch9\Data\Example\Buffer_Intersect.shp
连接属性:All
输出属性:Input
相交结果如图XX所示。
|
图XX 相交对话窗口 图XX 相交结果 |

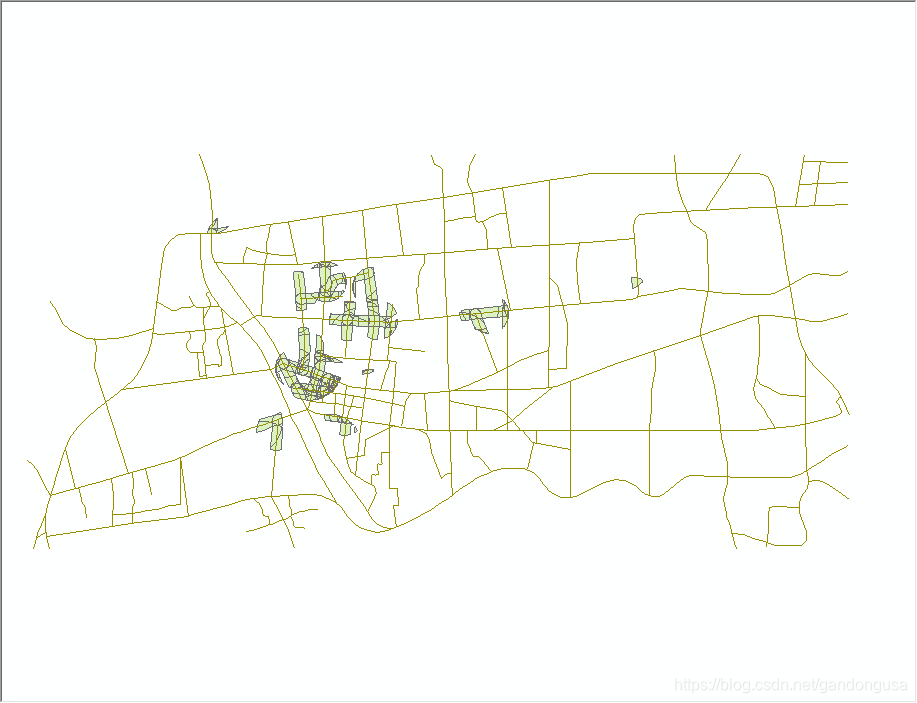
(2)计算满足四个条件的区域,具体过程如下
ArcMap中【目录列表】定位到【工具箱】--【系统工具箱】--【Analyst Tools】--【叠加分析】--【擦除】,打开【擦除】对话窗口。
在打开的【擦除】对话窗口中设置如下(图XX):
输入要素:Buffer_Intersect
擦除要素:ATM_Buffer
输出要素类:\ch9\Data\Example\Buffer_Erase.shp
XY容差:默认
擦除结果如图XX所示。
|
图XX 擦除对话窗口 图XX 擦除结果 |

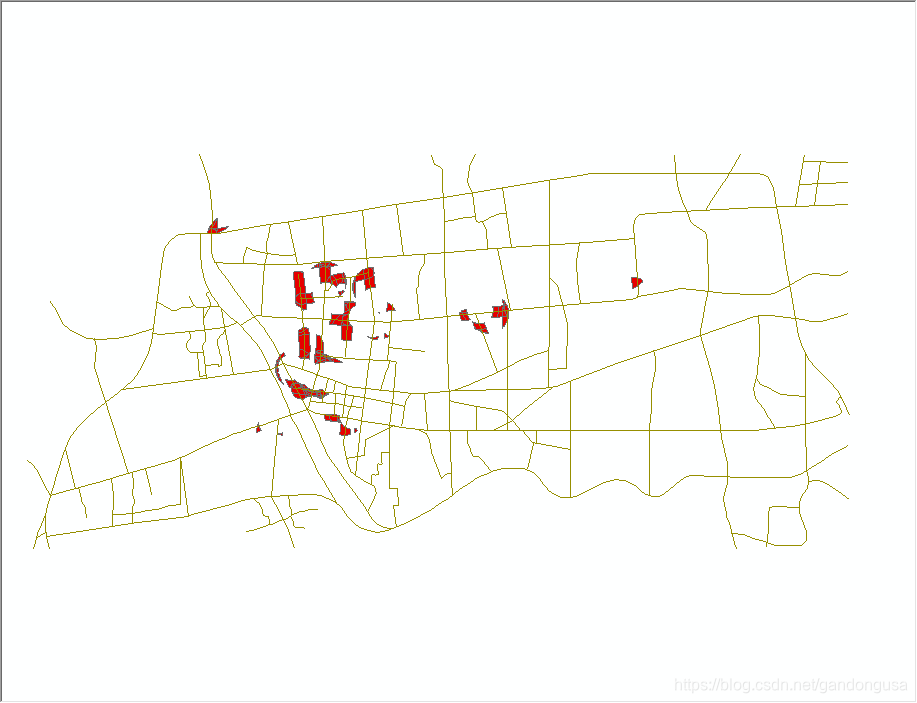
通过上述两个步骤,就可以确定出新的ATM布设的区域。
9.5.3.6 区位评价
上节中得到4个条件全部满足的选址区域。为了了解ATM选址的实际情况,可以把满足条件的情况进行分级:满足全部4个条件均的为第一级,满足其中3个条件的为第二级,满足其中2个条件的为第三级,只满足其中1个条件的为第四级,全部条件都不满足的为第五等级。
具体操作步骤为:
(1)区域属性赋值
分别打开ATM_Buffer、Residential_Buffer、Market_Buffer和Road_Buffer属性表,添加短整型字段并赋值(表XX);
| 图层 | 添加字段 | 字段类型 | 赋值 |
| ATM_Buffer | ATM | 短整型 | -1 |
| Residential_Buffer | Resident | 短整型 | 1 |
| Market_Buffer | Market | 短整型 | 1 |
| Road_Buffer | Road | 短整型 | 1 |
ATM_Buffer赋值为-1,说明ATM_Buffer之外的区域才能满足要求;另外3个缓冲图层赋值为1,说明3个缓冲图层本身符合要求。
(2)区域叠加处理
ArcMap中【目录列表】定位到【工具箱】--【系统工具箱】--【Analyst Tools】--【叠加分析】--【联合】,打开【联合】对话窗口。
在打开的【联合】对话窗口中设置如下(图XX):
输入要素:ATM_Buffer、Residential_Buffer、Market_Buffer和Road_Buffer
输出要素类:\ch9\Data\Example\Buffer_Union.shp
连接属性:ALL
XY容差:默认
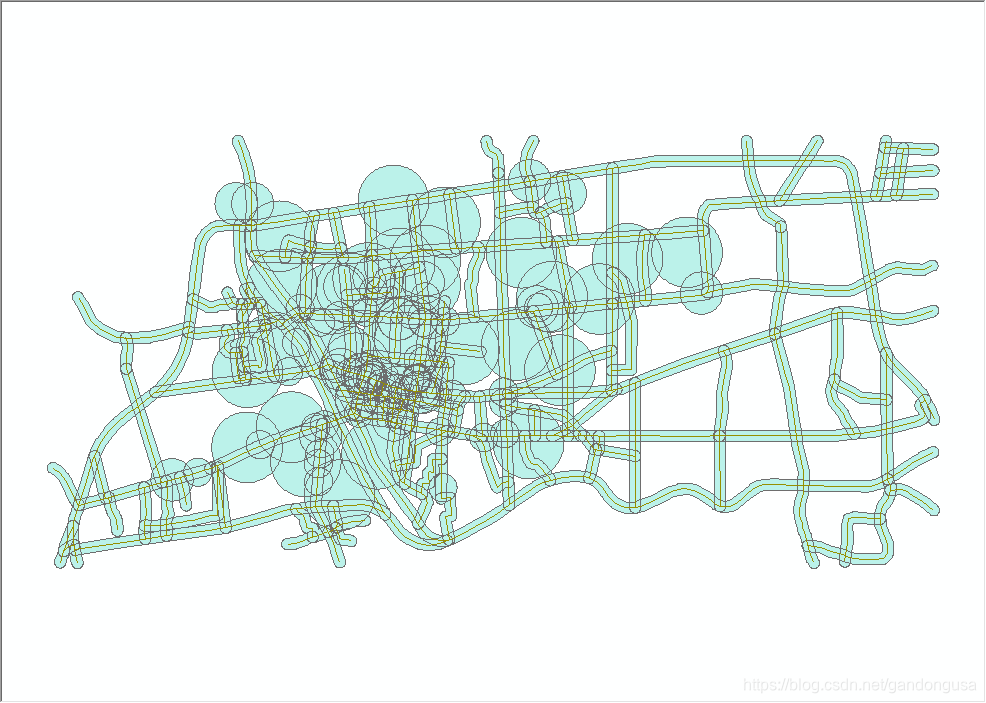
联合结果如图XX所示。
|
图XX 联合对话窗口 图XX 联合结果 |

(3)区域分级
打开生成的Buffer_Union图层属性表,添加短整型字段“CLASS”;
在“CLASS”上右键单击选择【![]() 字段计算器】,打开【字段计算器】对话窗口;
字段计算器】,打开【字段计算器】对话窗口;
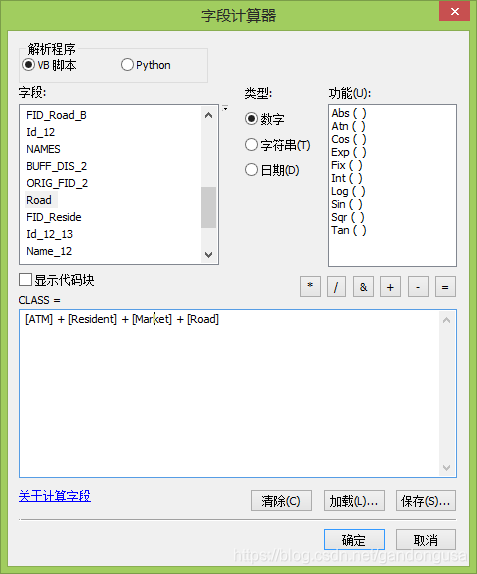
在打开的【字段计算器】窗口中设置如下(图XX):
在下方“CLASS=”空白处填入:“[ATM] + [Resident] + [Market] + [Road]”
|
图XX 字段计算器窗口 |
(4)区域分级显示
计算完成后对Buffer_Union图层利用CLASS字段分级显示。
第一等级:CLASS值为3;
第二等级:CLASS值为2;
第三等级:CLASS值为1;
第四等级:CLASS值为0;
第五等级:CLASS值为-1。
|
图XX ATM选址分析结果 |
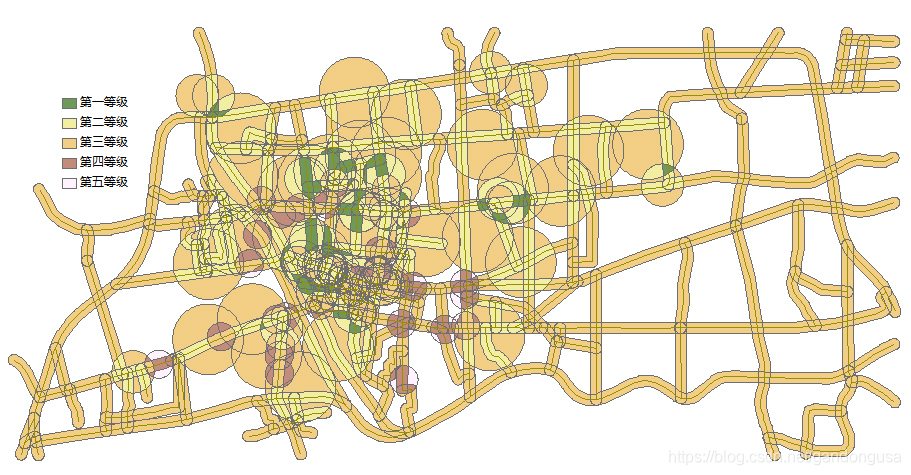
分级后的图即为ATM取款机选址结果图。按照等级由低到高,适宜程度由适宜变为不适宜(图XX)。在实际的项目应用过程中,可以根据实际情况确定影响的因素和缓冲的范围,找到合适的阈值和条件,寻找到适合的区域。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号