

基于GCC的openMP学习与测试(2)
一、openMP简单测试
1、简述
-
openMP很多情况下对于利用多核处理器进行加速是很有效果的,然而,也有一些情况是openMP不但没有效果,甚至还有一些反作用。
2、简单测试(1)
-
 View Code
View Code#include<omp.h> #include<time.h> #include<iostream> using namespace std; void openMP() { int i,j; for(i=0; i<200; i++) { for( j = 0; j < 10; j++) j++; } } int main() { time_t start,end1; time( &start ); double omp_start = omp_get_wtime( ); int N = 100000000; int i,j; #pragma omp parallel for(int m = 0; m < N ; m++) { openMP(); } double omp_end = omp_get_wtime( ); time( &end1 ); std::cout<<"used_times "<<end1 - start<<"\n"; std::cout<<"omp_times "<<omp_end - omp_start<<"\n"; return 0; }


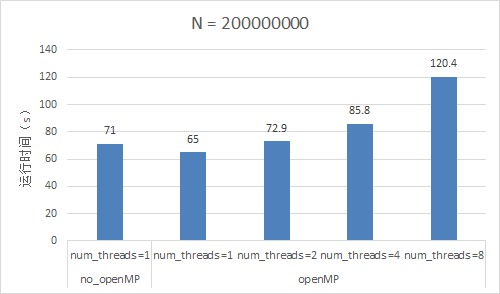
- 从上面可以看出,使用openMP并行化程序并没有比不使用openMP的要快,甚至线程数量越大的情况下,运行时间反而越长。
- 这是因为,数据量巨大,线程数量越多的时候,程序分配并行程序的时间越多,导致程序的运行时间变慢。这种情况下,使用openMP设置的线程数量越多,效果会越差。
3、简单测试(2)
-
View Code
#include<omp.h> #include<time.h> #include<iostream> using namespace std; void openMP() { int i,j; for(i=0; i<200000000; i++) { for( j = 0; j < 100; j++) j++; } } int main() { time_t start,end1; time( &start ); double omp_start = omp_get_wtime( ); int N = 1; int i,j; #pragma omp parallel for for(int m = 0; m < N ; m++) { openMP(); } double omp_end = omp_get_wtime( ); time( &end1 ); std::cout<<"used_times "<<end1 - start<<"\n"; std::cout<<"omp_times "<<omp_end - omp_start<<"\n"; return 0; }

- 从上面的图表可以看出,使用openMP以及扩大线程数量与不使用openMP的程序运行时间相差无几
- 这是因为循环一次的情况下,openMP无论设置了多少个线程,所使用的CPU利用率,系统最大会分配给100%,也就是一个线程的CPU利用率,也就和不使用openMP没有什么差别,这种情况下,openMP是没有什么效果的。
二、openMP学习参考
- 通过 GCC 学习 OpenMP 框架:https://www.ibm.com/developerworks/cn/aix/library/au-aix-openmp-framework/
-
Guide into OpenMP : http://bisqwit.iki.fi/story/howto/openmp/

