
linux 命令汇总
1 grep 命令
1. 搜索空行
grep '^$' 文件名
2. 匹配仅仅只包含 foo 的行
grep '^foo$' 文件名
3. 匹配至少包含一个字母的
grep '[A-Za-z]' 文件名
4. “或”匹配
grep -E 'word1|word2' 文件名
egrep 'word1|word2' 文件名
grep 'word1/|word2' 文件名
5. 既包含 'word1' 又包含 'word2' 的所有行
grep 'word1' 文件名 | grep 'word2'
6. 能匹配到 "col" 和 "cool"
egrep 'co{1,2}l' 文件名
2 regex正则
常见的转义
\ 忽略正则表达式中特殊字符的原有含义 ^ 匹配正则表达式的开始行 $ 匹配正则表达式的结束行 \< 从匹配正则表达式的行开始 \> 到匹配正则表达式的行结束 [ ] 单个字符;如[A] 即A符合要求 [ - ] 范围 [A-Z]即A,B,C一直到Z都符合要求 . 所有的单个字符 * 所有字符,长度可以为0
重复的操作的表示
? 最多匹配一次 * 匹配零次或者任意多次 + 匹配一次以上 {n} 匹配n次 {n,} 最少匹配n次 {,m} 最多匹配m次 {n,m} 匹配n到m次
3 source sh ./ 的问题
1 先说sh test.sh 和 ./test.sh的区别:
(1) 如果脚本所在目录路径不在path 里面, 要执行当前目录下的可执行文件,使用全路径 ./executable-file
(2) 如果要执行一个sh脚本,不管有没可执行的权限(chmod),都可以使用 sh file,如果file不在当前目录,也要传入全路径
2 再说下source
(1) source命令也称为点命令,也就是一个点符号(.),是bash的内部命令,功能是使shell读入指定的shell程序文件并依次执行文件中的所有语句
(2) source命令通常用于重新执行刚修改的初始化文件,使之立刻生效,而不必注销并重新登录.
(3) 用法 source filename 或 . filename
3 source 和 sh or ./的区别
(1) sh file 和 ./ file 重新建立一个子shell,在子shell中执行脚本里面的语句,该子shell继承父shell的环境变量,但子shell新建的、改变的变量不会被带回父shell,除非使用export。
(2) source file 这个命令其实只是简单地读取脚本里面的语句依次在当前shell里面执行,没有建立新的子shell。那么脚本里面所有新建、改变变量的语句都会保存在当前shell里面
实例:
1.新建一个test.sh脚本,内容为:A=1 2.然后使其可执行chmod +x test.sh 3.运行sh test.sh后,echo $A,显示为空,因为A=1并未传回给当前shell 4.运行./test.sh后,也是一样的效果 5.运行source test.sh 或者 . test.sh,然后echo $A,则会显示1,说明A=1的变量在当前shell中
4 vim
操作类:
x 删除光标所在位置字符 i 光标前插入文本 A 行后添加文本 dw 删除一个单词(光标放在起始出) d2w 删除两个单词 d$ 从光标处删至当前行尾部 dd 删除该行(接着光标移动到另一行输入p将之前的一行粘贴置入到此行上方) 2dd 删除两行 r+char 替换光标所在位置的字符
移动类:
光标在屏幕文本中的移动可以用箭头键,也可以使用 h j k l 字母键 k (上行)j(下行) h(左移) l(右移) w 跳到下一个单词的开始 e 跳到单词的结束 输入0(数字零)移动光标到行首 gg 跳到文件的开始 G 跳到文件的结束 10gg 或10G 跳到第10行
撤销类:
输入u来撤消最后执行的命令
输入U来撤消对整行的修改
Ctril + R 重做被撤消的命令,也就是撤消掉撤消命令
查找类:
正常模式下输入 /(或者:) 字符输入要查找的字符串 回车
n 查找所搜索的字符串
N 逆向查找所搜索的字符串
5 sed
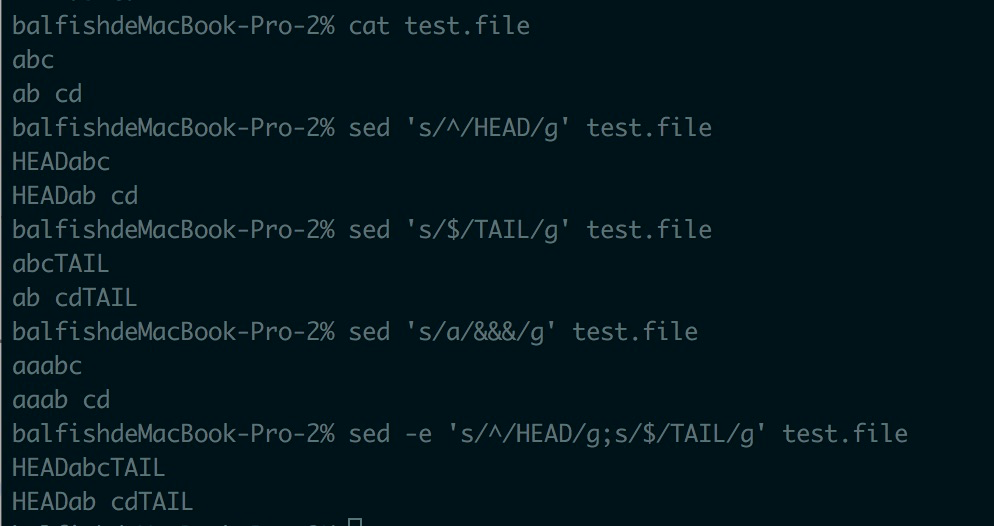
(1) 每行的行头添加字符"HEAD", 命令如下
sed 's/^/HEAD/g' test.file
(2) 每行的行尾添加字符"TAIL", 命令如下
sed 's/$/TAIL/g' test.file
(3) 每行匹配的字符重复打印三次, 命令如下
sed 's/a/&&&/g' test.file
(4) 每行的行头添加字符"HEAD",每行的行尾添加字符"TAIL",命令如下
sed -e 's/^/HEAD/g;s/$/TAIL/g' test.file
(4) window文件unix上打开
"\n\r" -> "\n" 去掉"\r" ,用命令sed -i 's/\r//' test.file
简介:
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等
sed使用参数
[root@www ~]# sed [-nefr] [动作]
选项与参数:
-n :使用安静模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但加上-n参数后,则只有经过sed 特殊处理的那一行才会被列出来
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
要删除第 3 到最后一行
nl /etc/passwd | sed '3,$d'
在第二行后(亦即是加在第三行)加上『drink tea』字样!
nl /etc/passwd | sed '2a drink tea'那如果是要在第二行前
nl /etc/passwd | sed '2i drink tea'
如果是要增加两行以上,在第二行后面加入两行字,例如『Drink tea or .....』与『drink beer?』
nl /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?'
将第2-5行的内容取代成为『No 2-5 number』呢?
nl /etc/passwd | sed '2,5c No 2-5 number'
仅列出 /etc/passwd 文件内的第 5-7 行
nl /etc/passwd | sed -n '5,7p'
搜索 /etc/passwd有root关键字的行
nl /etc/passwd | sed '/root/p'
使用-n的时候将只打印包含模板的行
nl /etc/passwd | sed -n '/root/p'
删除/etc/passwd所有包含root的行,其他行输出nl /etc/passwd | sed '/root/d'
搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行:
nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p}'如果只替换/etc/passwd的第一个bash关键字为blueshell,就退出
nl /etc/passwd | sed -n '/bash/{s/bash/blueshell/;p;q}'
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代
先观察原始信息,利用 /sbin/ifconfig 查询 IP
[root@www ~]# /sbin/ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
.....(以下省略).....
处理得到本机ip
(1)将 IP 前面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g'
192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
(2)将 IP 后面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*$//g'
192.168.1.100
多点编辑
nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试!利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
[root@www ~]# sed -i 's/\.$/\!/g' regular_express.txt
利用 sed 直接在 regular_express.txt 最后一行加入『# This is a test』
[root@www ~]# sed -i '$a # This is a test' regular_express.txt由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增『# This is a test』!
6 cat命令
-b 对非空白行进行编号,行号从1开始
-n 和nl命令差不多,对所有行(包括空白行)进行编号输出显示
-E 在每行的结尾处附加$符号
cat对于内容极大的文件来说,可以用管道 | 传送到more工具,然后一页一页地查看
如[root@localhost ~]# cat /etc/fstab /etc/profile | more
cat 有创建文件的功能,创建文件后,要以EOF结束;(> 改为 >> 则为追加)
如[root@localhost ~]# cat > test << EOF 创建test文件,以EOF作为文件输入的结尾
>test1 这是输入内容
>test2 这是输入内容
>EOF 退出编辑状态
7 more
more 是我们最常用的工具之一,最常用的就是显示输出的内容,然后根据窗口的大小进行分页显示,然后还能提示文件的百分比
more [参数选项] [文件]
+num 从第num行开始显示;
-num 定义屏幕大小,为num行;
+/pattern 从pattern 前两行开始显示;
more 的动作指令:
我们查看一个内容较大的文件时,要用到more的动作指令,比如ctrl+f(或空格键) 是向下显示一屏,ctrl+b是返回上一屏; Enter键可以向下滚动显示n行,要通过定,默认为1行;
Enter 向下n行,需要定义,默认为1行;
Ctrl+f 向下滚动一屏;
空格键 向下滚动一屏;
Ctrl+b 返回上一屏;
= 输出当前行的行号;
:f 输出文件名和当前行的行号;
v 调用vi编辑器;
!命令 调用Shell,并执行命令;
q 退出
8 less
enter <-> y 向下/上滚动一行 space <-> b 向下/上滚动一屏 d <-> u 向下/上滚动半屏 h less的帮助 g 跳到第一行 G 跳到最后一行 /pattern 搜索pattern ,比如 /MAIL表示在文件中搜索MAIL单词 q 退出less
9 sort命令
sort的-t和-k用法示例
如果有一个文件的内容是这样:
[rocrocket@rocrocket programming]$ cat facebook.txt
banana:30:5.5
apple:10:2.5
pear:90:2.3
orange:20:3.4
这 个文件有三列,列与列之间用冒号隔开了,第一列表示水果类型,第二列表示水果数量,第三列表示水果价格。那么我想以水果数量来排序,也就是以第二列来排 序,如何利用sort实现?幸好,sort提供了-t选项,后面可以设定间隔符。指定了间隔符之后,就可以用-k来指定列数了。
[rocrocket@rocrocket programming]$ sort -n -k 2 -t ':' facebook.txt
apple:10:2.5
orange:20:3.4
banana:30:5.5
pear:90:2.3
10 awk命令
awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
入门实例
显示/etc/passwd的账户
#cat /etc/passwd |awk -F ':' '{print $1}'
root
daemon
bin
sys
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
#cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
....
blue,/bin/nosh
awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
搜索/etc/passwd有root关键字的所有行
#awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
# awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
awk内置变量
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。
ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容:
#awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/bin/sh
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
看这样一个例子,文件的路径为/usr/share/man/man5/locale.alias.5.gz 问如何使用命令得到所在的文件夹,也即/usr/share/man/man5/

11 ps
-e 显示所有进程。
-f 全格式。
-h 不显示标题。
-l 长格式。
-w 宽输出。
a 显示终端上的所有进程,包括其他用户的进程。
r 只显示正在运行的进程。
u 以用户为主的格式来显示程序状况。
x 显示所有程序,不以终端机来区分
1 ps -ef
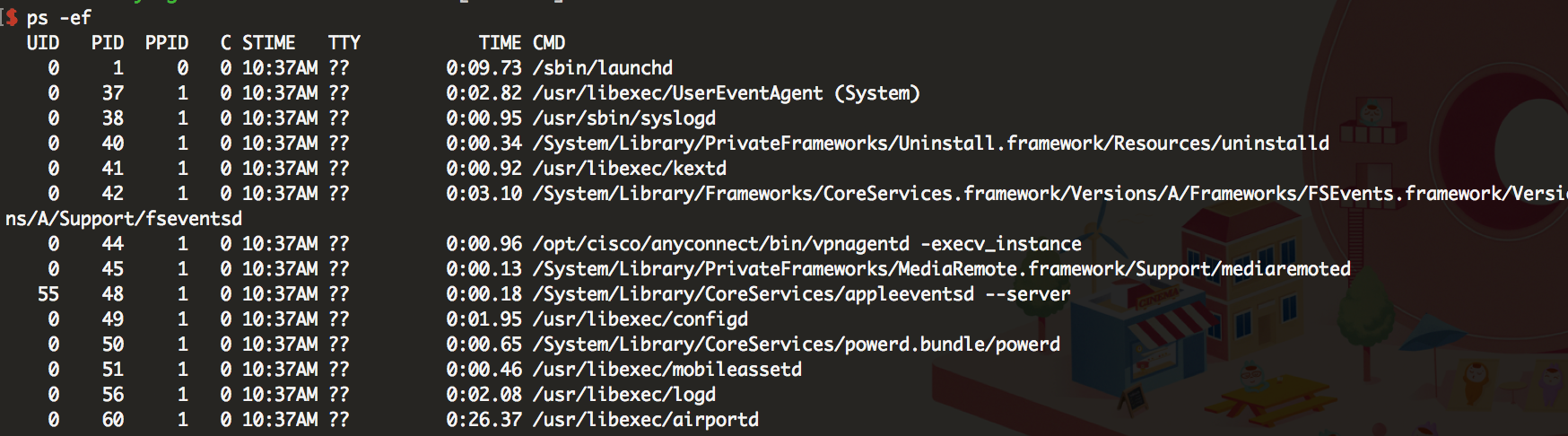
1. UID 用户ID
2. PID 进程ID
3. PPID 父进程ID
4. C CPU占用率
5. STIME 开始时间
6. TTY 开始此进程的TTY----终端设备
7. TIME 此进程运行的总时间
8. CMD 命令名
2 ps aux
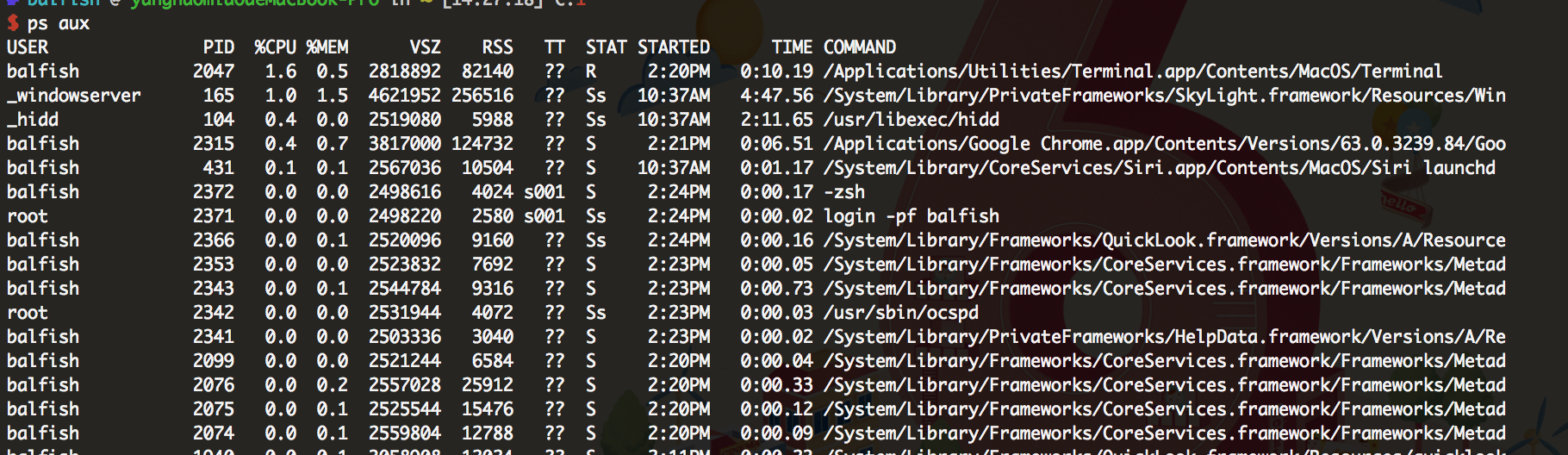
1. USER 进程的属主
2. PID 进程的id
3. PPID 父进程id
4. %CPU 占用的CPU百分比
5. %MEM 占用内存的百分比
6. VSZ 该进程使用的虚拟内存量(kb)
7. RSS 该進程占用的固定內存量(kb) (驻留中页的数量)
8. TTY 该进程在哪个终端上运行。若与终端无关,则显示(?)。若为pts/0,则表示由网络连接主机进程
9. TIME 该进程实际使用CPU运行的时间
10. COMMAND 命令的名称和参数
100 其他汇总
| top | Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器 |
| uname -a | 查看内核,处理器,操作系统等信息 |
| ctrl + a | 移动光标到命令行首 |
| ctrl + e | 移动光标到命令行尾 |
| ctrl + u | 清除当前行所有字符 |
| df | 显示档案系统的状况 |
| du | 显示目录或文件的大小 |
| ps -A | 查看所有运行进程 |
| tar -zcvf | 压缩tar文件 |
| tar -zxvf | 解压缩tar文件 |
| bc | 任意精度计算器语言, 做数字运算 |
| tr | 转换文件中的字符. 例如. cat testfile | tr a-z A-Z |
其他命令
1 得到git最近一次tag
git describe --tags `git rev-list --tags --max-count=1`
2 sublime text列选
如果每行的字符串长度不同,而你需要删除每行的最后7个字符,该怎么办呢?
1. Command+A 全选
2. Command+Shift+L 进入列选模式
3. 使用方向键左右移动所有列的光标,并配合使用Shift键来多选每行的字符

 浙公网安备 33010602011771号
浙公网安备 33010602011771号