
读写分离 & 分库分表 & 深度分页
什么是读写分离?
读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
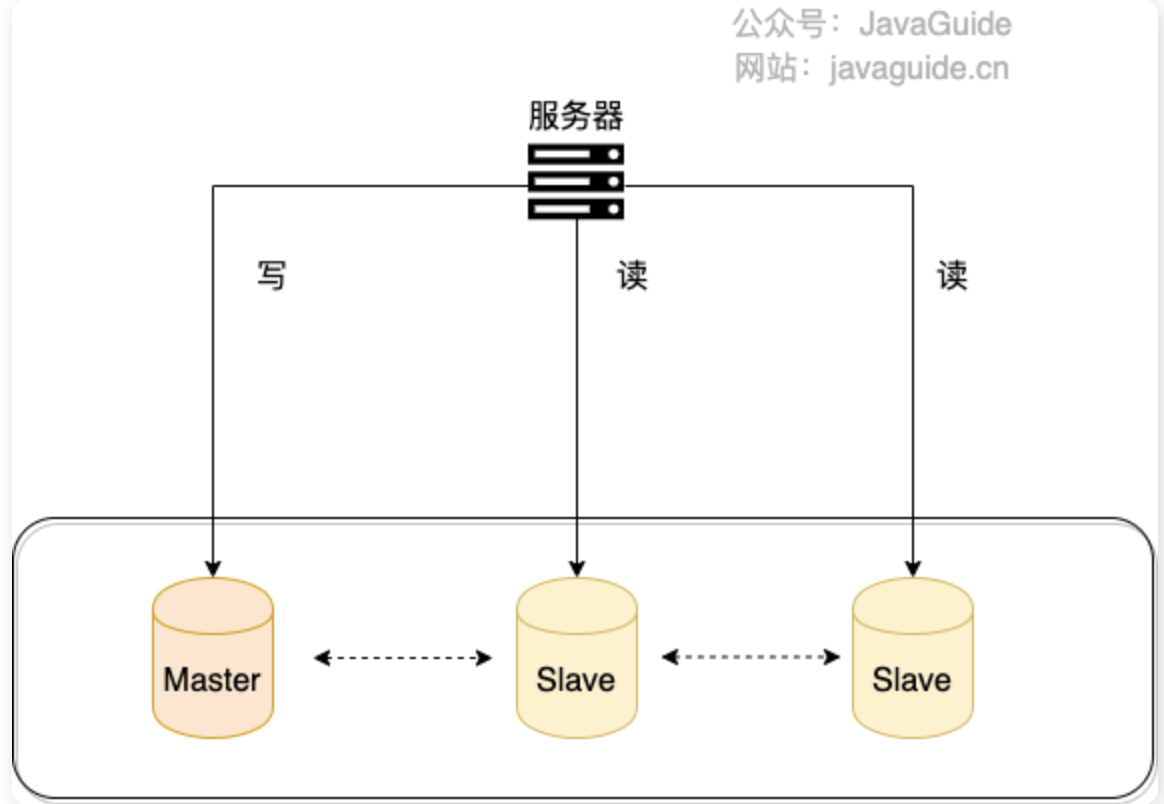
一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。
如何实现读写分离?
不论是使用哪一种读写分离具体的实现方案,想要实现读写分离一般包含如下几步:
- 部署多台数据库,选择其中的一台作为主数据库,其他的一台或者多台作为从数据库。
- 保证主数据库和从数据库之间的数据是实时同步的,这个过程也就是我们常说的主从复制。
- 系统将写请求交给主数据库处理,读请求交给从数据库处理。
落实到项目本身的话,常用的方式有两种:
1. 代理方式

我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
提供类似功能的中间件有 MySQL Router(官方, MySQL Proxy 的替代方案)、Atlas(基于 MySQL Proxy)、MaxScale、MyCat。
关于 MySQL Router 多提一点:在 MySQL 8.2 的版本中,MySQL Router 能自动分辨对数据库读写/操作并把这些操作路由到正确的实例上。这是一项有价值的功能,可以优化数据库性能和可扩展性,而无需在应用程序中进行任何更改
2. 组件方式
在这种方式中可以通过引入第三方组件来帮助我们读写请求。
这也是我比较推荐的一种方式。这种方式目前在各种互联网公司中用的最多的,相关的实际的案例也非常多。如果你要采用这种方式的话,推荐使用 sharding-jdbc,直接引入 jar 包即可使用,同时也节省了很多运维的成本。
主从复制原理是什么?
MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和 DML 语句)。因此,我们根据主库的 binlog 日志就能够将主库的数据同步到从库中。
- 主库将数据库中数据的变化写入到 binlog
- 从库连接主库
- 从库会创建一个 I/O 线程向主库请求更新的 binlog
- 主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
- 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
- 从库的 SQL 线程读取 relay log 同步数据本地(也就是再执行一遍 SQL )。
你一般看到 binlog 就要想到主从复制。当然除了主从复制之外,binlog 还能帮助我们实现数据恢复。
如何避免主从延迟?
读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 主从同步延迟 。
如果我们的业务场景无法容忍主从同步延迟的话,应该如何避免呢(注意:我这里说的是避免而不是减少延迟)? 这里提供两种方案
强制将读请求路由到主库处理
既然你从库的数据过期了,那我就直接从主库读取嘛!这种方案虽然会增加主库的压力,但是,实现起来比较简单,也是我了解到的使用最多的一种方式。
比如 Sharding-JDBC 就是采用的这种方案。通过使用 Sharding-JDBC 的 HintManager 分片键值管理器,我们可以强制使用主库。
HintManager hintManager = HintManager.getInstance(); hintManager.setMasterRouteOnly(); // 继续JDBC操作
对于这种方案,你可以将那些必须获取最新数据的读请求都交给主库处理。
延迟读取
还有一些朋友肯定会想既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
总结
关于如何避免主从延迟,我们这里介绍了两种方案。实际上,延迟读取这种方案没办法完全避免主从延迟,只能说可以减少出现延迟的概率而已,实际项目中一般不会使用。
总的来说,要想不出现延迟问题,一般还是要强制将那些必须获取最新数据的读请求都交给主库处理。如果你的项目的大部分业务场景对数据准确性要求不是那么高的话,这种方案还是可以选择的。
如何减少主从延迟?
我们在上面的内容中也提到了主从延迟以及避免主从延迟的方法,这里我们再来详细分析一下主从延迟出现的原因以及应该如何尽量减少主从延迟。
要搞懂什么情况下会出现主从延迟,我们需要先搞懂什么是主从延迟。
MySQL 主从同步延时是指从库的数据落后于主库的数据,这种情况可能由以下两个原因造成:
- 从库 I/O 线程接收 binlog 的速度跟不上主库写入 binlog 的速度,导致从库 relay log 的数据滞后于主库 binlog 的数据;
- 从库 SQL 线程执行 relay log 的速度跟不上从库 I/O 线程接收 binlog 的速度,导致从库的数据滞后于从库 relay log 的数据。
与主从同步有关的时间点主要有 3 个:
- 主库执行完一个事务,写入 binlog,将这个时刻记为 T1;
- 从库 I/O 线程接收到 binlog 并写入 relay log 的时刻记为 T2;
- 从库 SQL 线程读取 relay log 同步数据本地的时刻记为 T3。
结合我们上面讲到的主从复制原理,可以得出:
- T2 和 T1 的差值反映了从库 I/O 线程的性能和网络传输的效率,这个差值越小说明从库 I/O 线程的性能和网络传输效率越高。
- T3 和 T2 的差值反映了从库 SQL 线程执行的速度,这个差值越小,说明从库 SQL 线程执行速度越快。
那什么情况下会出现出从延迟呢?这里列举几种常见的情况:
- 从库机器性能比主库差:从库接收 binlog 并写入 relay log 以及执行 SQL 语句的速度会比较慢(也就是 T2-T1 和 T3-T2 的值会较大),进而导致延迟。解决方法是选择与主库一样规格或更高规格的机器作为从库,或者对从库进行性能优化,比如调整参数、增加缓存、使用 SSD 等。
- 从库处理的读请求过多:从库需要执行主库的所有写操作,同时还要响应读请求,如果读请求过多,会占用从库的 CPU、内存、网络等资源,影响从库的复制效率(也就是 T2-T1 和 T3-T2 的值会较大,和前一种情况类似)。解决方法是引入缓存(推荐)、使用一主多从的架构,将读请求分散到不同的从库,或者使用其他系统来提供查询的能力,比如将 binlog 接入到 Hadoop、Elasticsearch 等系统中。
- 大事务:运行时间比较长,长时间未提交的事务就可以称为大事务。由于大事务执行时间长,并且从库上的大事务会比主库上的大事务花费更多的时间和资源,因此非常容易造成主从延迟。解决办法是避免大批量修改数据,尽量分批进行。类似的情况还有执行时间较长的慢 SQL ,实际项目遇到慢 SQL 应该进行优化。
- 从库太多:主库需要将 binlog 同步到所有的从库,如果从库数量太多,会增加同步的时间和开销(也就是 T2-T1 的值会比较大,但这里是因为主库同步压力大导致的)。解决方案是减少从库的数量,或者将从库分为不同的层级,让上层的从库再同步给下层的从库,减少主库的压力。
- 网络延迟:如果主从之间的网络传输速度慢,或者出现丢包、抖动等问题,那么就会影响 binlog 的传输效率,导致从库延迟。解决方法是优化网络环境,比如提升带宽、降低延迟、增加稳定性等。
- 单线程复制:MySQL5.5 及之前,只支持单线程复制。为了优化复制性能,MySQL 5.6 引入了 多线程复制,MySQL 5.7 还进一步完善了多线程复制。
分库分表
分库 就是将数据库中的数据分散到不同的数据库上,可以垂直分库,也可以水平分库。
垂直分库 就是把单一数据库按照业务进行划分,不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。
常见的分片算法有哪些?
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
- 哈希分片:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
- 范围分片:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将
id为1~299999的记录分到第一个库,300000~599999的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。 - 地理位置分片:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
- 融合算法:灵活组合多种分片算法,比如将哈希分片和范围分片组合
深度分页介绍
查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录 SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
范围查询
当可以保证 ID 的连续性时,根据 ID 范围进行分页是比较好的解决方案:
# 查询指定 ID 范围的数据 SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id # 也可以通过记录上次查询结果的最后一条记录的ID进行下一页的查询: SELECT * FROM t_order WHERE id > 100000 LIMIT 10
这种优化方式限制比较大,且一般项目的 ID 也没办法保证完全连续。
子查询
我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。
# 通过子查询来获取 id 的起始值,把 limit 1000000 的条件转移到子查询 SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order limit 1000000, 1) LIMIT 10;
不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。
当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
延迟关联
延迟关联的优化思路,跟子查询的优化思路其实是一样的:都是把条件转移到主键索引树,减少回表的次数。不同点是,延迟关联使用了 INNER JOIN(内连接) 包含子查询。
SELECT t1.* FROM t_order t1 INNER JOIN (SELECT id FROM t_order limit 1000000, 10) t2 ON t1.id = t2.id LIMIT 10;
覆盖索引
索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
覆盖索引的好处:
- 避免 InnoDB 表进行索引的二次查询,也就是回表操作: InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
- 可以把随机 IO 变成顺序 IO 加快查询效率: 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
# 如果只需要查询 id, code, type 这三列,可建立 code 和 type 的覆盖索引 SELECT id, code, type FROM t_order ORDER BY code LIMIT 1000000, 10;
不过,当查询的结果集占表的总行数的很大一部分时,可能就不会走索引了,自动转换为全表扫描。当然了,也可以通过 FORCE INDEX 来强制查询优化器走索引,但这种提升效果一般不明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号