


数据结构1 - 「跳表」
一 概述
对于一个单链表,即使链表是有序的,如果我们想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低,跳表就不一样了。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。在高并发的情况下,平衡树会需要一个全局锁来保证线程安全。而跳表只需要部分锁即可,因此在高并发环境下拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是 O(logn)
二 原理
跳表的本质是同时维护了多个链表,并且链表是分层的,最低层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。
如下图所示,查找18的时候原来需要遍历18次,现在只需要7次即可。针对链表长度比较大的时候,构建索引查找效率的提升就会非常明显。
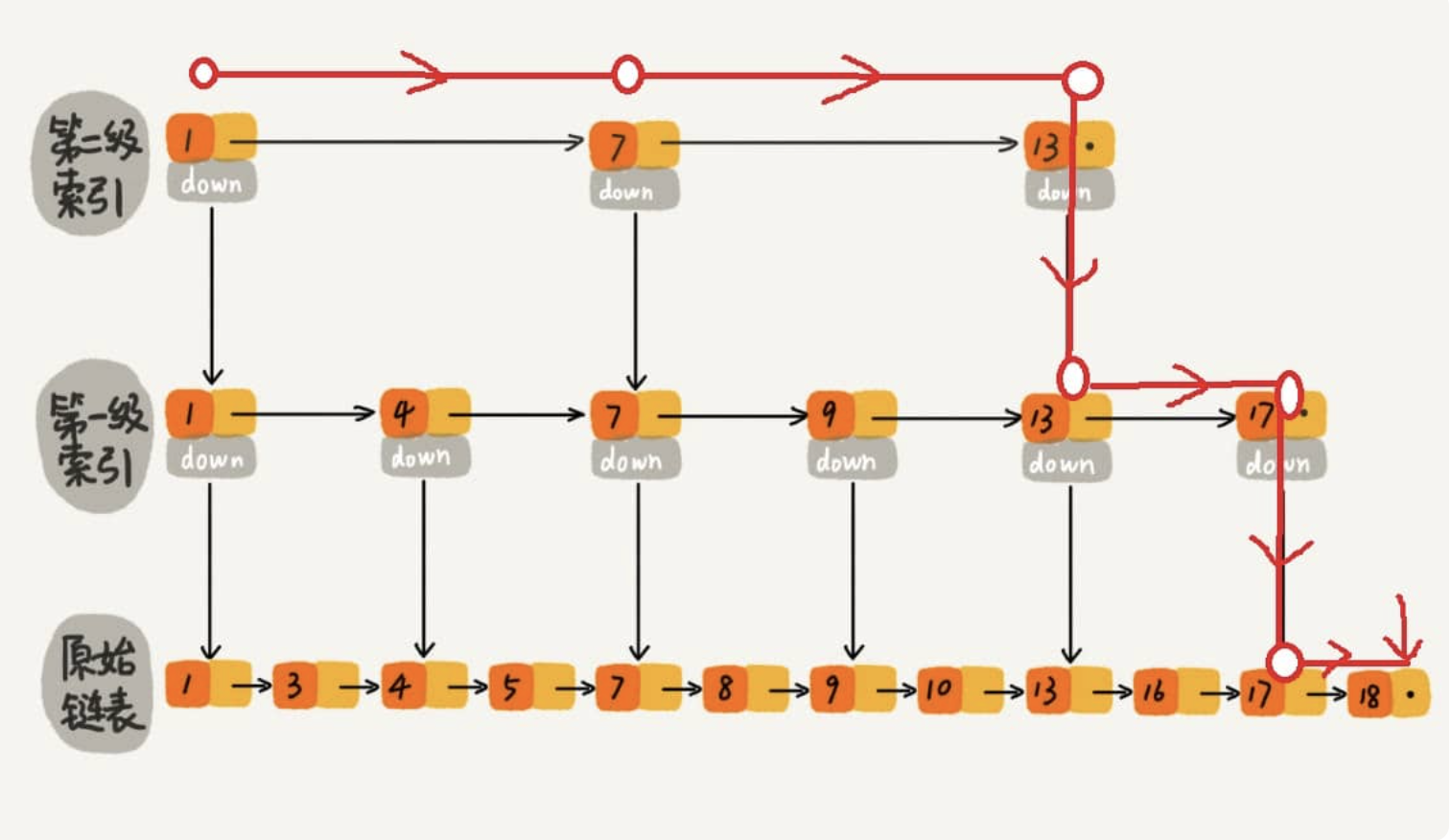
从上面很容易看出,跳表是一种利用空间换时间的算法。
使用跳表实现 Map 和使用哈希算法实现 Map 的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。JDK 中实现这一数据结构的类是 ConcurrentSkipListMap
分类:
数据结构


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2018-03-03 mysql锁分析