
数据结构2 - 「布隆过滤器」
1 概述
布隆过滤器实际上是一个很长的二进制数组 + 一系列随机hash映射函数,主要用于判断一个元素是否在集合中。
链表、树、散列表等等数据结构也都可以进行判断, 但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,检索速度也越来越慢,最终达到瓶颈。
上述三种结构的检索时间复杂度分别为O(n), O(logn), O(1)。这个时候,布隆过滤器就应运而生
2 布隆过滤器特点
1、高效地插入和查询,占用空间少,返回的结果是不确定性的。
2、一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在(在不一定在,不在一定不在)
3、布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加
4、误判只会发生在过滤器没有添加过的元素
5、对于添加过的元素不会发生误判
3 布隆过滤器的原理
布隆过滤器的数据结构实质就是一个大型初值都为零的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在。
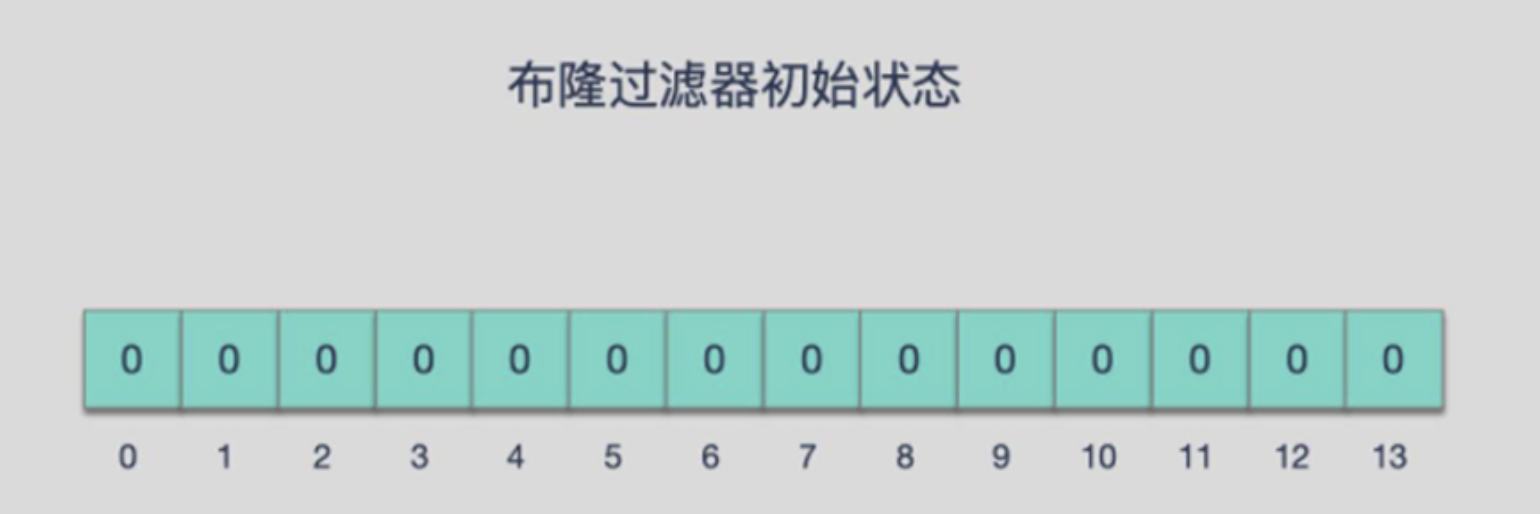
添加key时: 使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时: 只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过3个映射函数)。
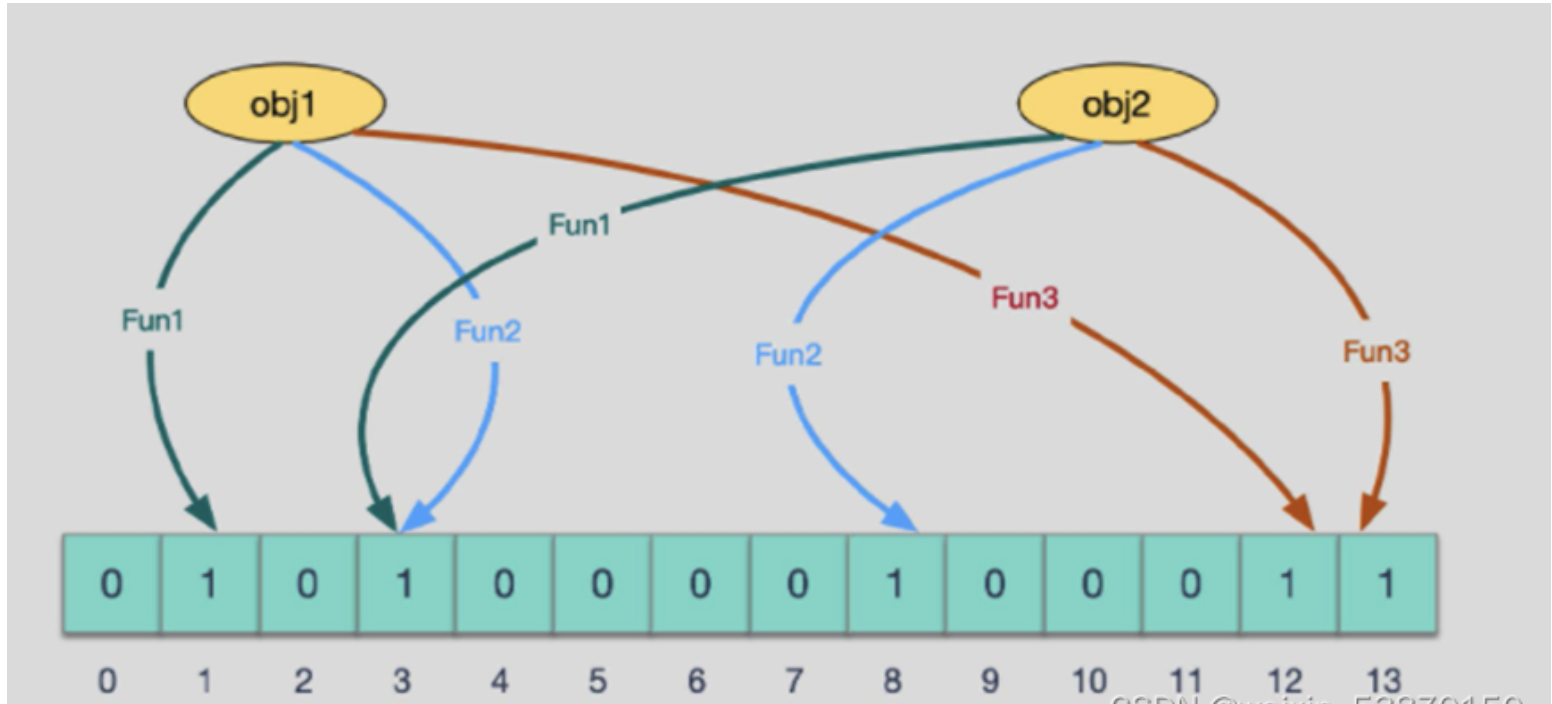
查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了
如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在,为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。
4 布隆过滤器使用场景
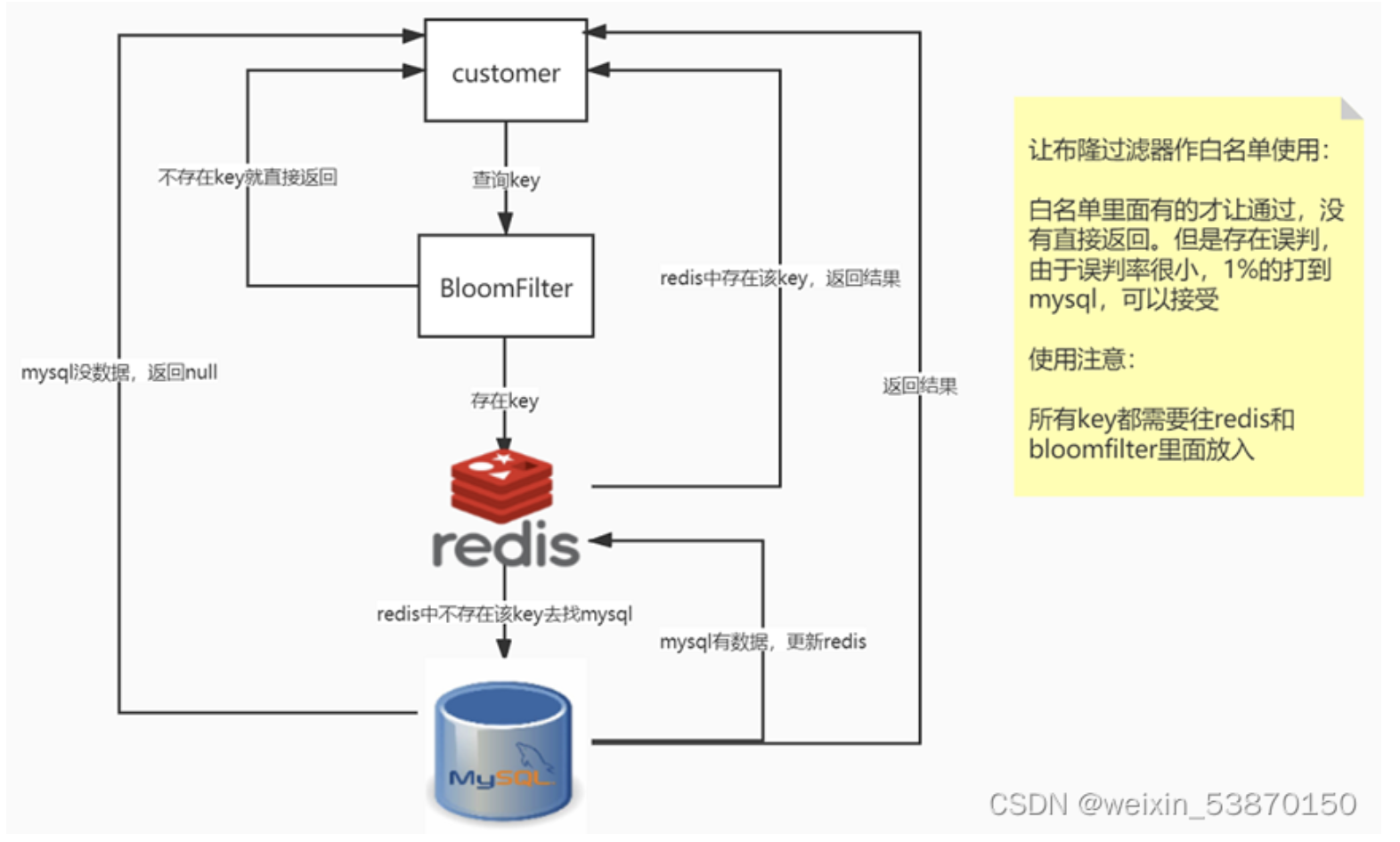
a 解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则穿透到Mysql数据库
b 白名单处理
在白名单中的,就执行特定操作。比如:识别重要邮件,只要是邮箱在白名单中的邮件,就识别为重要邮件。
假设白名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。
把所有白名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号