
RPC
一 概述
RPC(Remote Procedure Call):远程过程调用,它是一种通过网络从远程计算机程序上请求服务,这个过程就像调用本地方法一样,而不需要了解底层网络技术的思想。
为什么要 RPC ? 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
RPC 是一种技术思想而非一种规范或协议,常见 RPC 技术和框架有:
- 应用级的服务框架:阿里的Dubbo、Google gRPC、Facebook的Thrift
- 远程通信协议:RMI、Socket、SOAP(HTTP XML)、REST(HTTP JSON)
- 通信框架:MINA 和 Netty
二 RPC结构及流程
2.1 结构
在一个典型 RPC 的使用场景中,包含了服务发现、负载、容错、网络传输、序列化等组件,其中“RPC 协议”就指明了程序如何进行网络传输和序列化。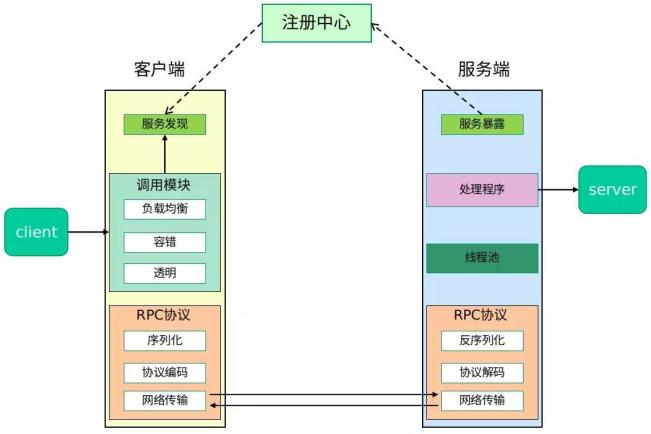
2.2 流程
整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
- 客户端(服务消费端):调用远程方法的一端。
- 客户端 Stub(桩):这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
- 网络传输:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
- 服务端 Stub(桩):这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
- 服务端(服务提供端):提供远程方法的一端。

- 服务消费端(client)以本地调用的方式调用远程服务;
- 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):
RpcRequest; - 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
- 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象:
RpcRequest; - 服务端 Stub(桩)根据
RpcRequest中的类、方法、方法参数等信息调用本地的方法; - 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:
RpcResponse(序列化)发送至消费方; - 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象:
RpcResponse,这样也就得到了最终结果。over!
三 常见的RPC框架
3.1 Dubbo
Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案,涵盖 Java、Golang 等多种语言 SDK 实现。
Dubbo 提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力,支持 Triple 协议(基于 HTTP/2 之上定义的下一代 RPC 通信协议)、应用级服务发现、Dubbo Mesh 等特性。
Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
3.2 gRPC
gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
何谓 ProtoBuf?protobuf是一种更加灵活、高效的数据格式,可用于通讯协议、数据存储等领域,基本支持所有主流编程语言且与平台无关。不过,通过 ProtoBuf 定义接口和数据类型还挺繁琐的,这是一个小问题。
不得不说,gRPC 的通信层的设计还是非常优秀的,Dubbo-go 3.0 的通信层改进主要借鉴了 gRPC。
不过,gRPC 的设计导致其几乎没有服务治理能力。如果你想要解决这个问题的话,就需要依赖其他组件比如腾讯的 PolarisMesh(北极星)了。
3.3 Thrift
Apache Thrift 是 Facebook 开源的跨语言的 RPC 通信框架,目前已经捐献给 Apache 基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于 thrift 研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
Thrift支持多种不同的编程语言,包括C++、Java、Python、PHP、Ruby等(相比于 gRPC 支持的语言更多 )。
3.4 总结
gRPC 和 Thrift 虽然支持跨语言的 RPC 调用,但是它们只提供了最基本的 RPC 框架功能,缺乏一系列配套的服务化组件和服务治理功能的支撑。
Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说都是最优秀的。而且,Dubbo 在国内有很多成功的案例比如当当网、滴滴等等,是一款经得起生产考验的成熟稳定的 RPC 框架。最重要的是你还能找到非常多的 Dubbo 参考资料,学习成本相对也较低
但是,Dubbo主要是给 Java 语言使用。虽然Dubbo目前也能兼容部分语言,但是不太推荐。如果需要跨多种语言调用的话,可以考虑使用 gRPC。
综上,如果是 Java 后端技术栈,并且你在纠结选择哪一种 RPC 框架的话,我推荐你考虑一下 Dubbo。
四 核心技术点
如果想要自己实现一个 RPC,最简单的方式要实现三个技术点,分别是:
- 服务寻址
- 数据流的序列化和反序列化
- 网络传输
4.1 服务寻址
服务寻址可以使用 Call ID 映射。在本地调用中,函数体是直接通过函数指针来指定的,但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。
所以在 RPC 中,所有的函数都必须有自己的一个 ID。这个 ID 在所有进程中都是唯一确定的。
客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个函数和Call ID的对应表。
当客户端需要进行远程调用时,它就查一下这个表,找出相应的 Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
实现方式:服务注册中心。
要调用服务,首先你需要一个服务注册中心去查询对方服务都有哪些实例。Dubbo 的服务注册中心是可以配置的,官方推荐使用 Zookeeper。
实现案例:RMI(Remote Method Invocation,远程方法调用)也就是 RPC 本身的实现方式。
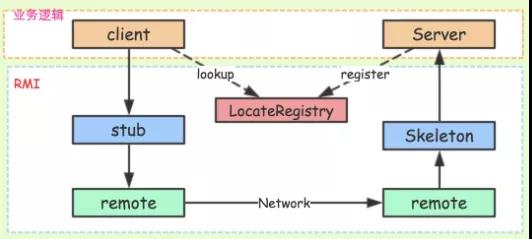
Registry(服务发现):借助 JNDI 发布并调用了 RMI 服务。实际上,JNDI 就是一个注册表,服务端将服务对象放入到注册表中,客户端从注册表中获取服务对象。
RMI 服务在服务端实现之后需要注册到 RMI Server 上,然后客户端从指定的 RMI 地址上 Lookup 服务,调用该服务对应的方法即可完成远程方法调用。
Registry 是个很重要的功能,当服务端开发完服务之后,要对外暴露,如果没有服务注册,则客户端是无从调用的,即使服务端的服务就在那里。
4.2 序列化和反序列化
客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。
但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。
这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。
只有二进制数据才能在网络中传输,序列化和反序列化的定义是:
- 将对象转换成二进制流的过程叫做序列化
- 将二进制流转换成对象的过程叫做反序列化
这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
4.3 网络传输
网络传输:远程调用往往用在网络上,客户端和服务端是通过网络连接的。
所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把 Call ID 和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。
只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。
尽管大部分 RPC 框架都使用 TCP 协议,但其实 UDP 也可以,而 gRPC 干脆就用了 HTTP2。
TCP 的连接是最常见的,简要分析基于 TCP 的连接:通常 TCP 连接可以是按需连接,也可以是长连接,多个远程过程调用共享同一个连接。
所以,要实现一个 RPC 框架,只需要把以下三点实现了就基本完成了:
- Call ID 映射:可以直接使用函数字符串,也可以使用整数 ID。映射表一般就是一个哈希表。
- 序列化反序列化:可以自己写,也可以使用 Protobuf 或者 FlatBuffers 之类的。
- 网络传输库:可以自己写 Socket,或者用 Asio,ZeroMQ,Netty 之类。
在 RPC 中可选的网络传输方式有多种,可以选择 TCP 协议、UDP 协议、HTTP 协议。
每一种协议对整体的性能和效率都有不同的影响,如何选择一个正确的网络传输协议呢?首先要搞明白各种传输协议在 RPC 中的工作方式。
基于 TCP 协议的 RPC 调用
由服务的调用方与服务的提供方建立 Socket 连接,并由服务的调用方通过 Socket 将需要调用的接口名称、方法名称和参数序列化后传递给服务的提供方,服务的提供方反序列化后再利用反射调用相关的方法。
***将结果返回给服务的调用方,整个基于 TCP 协议的 RPC 调用大致如此。
但是在实例应用中则会进行一系列的封装,如 RMI 便是在 TCP 协议上传递可序列化的Java对象。
基于 HTTP 协议的 RPC 调用
该方法更像是访问网页一样,只是它的返回结果更加单一简单。
其大致流程为:由服务的调用者向服务的提供者发送请求,这种请求的方式可能是 GET、POST、PUT、DELETE 等中的一种,服务的提供者可能会根据不同的请求方式做出不同的处理,或者某个方法只允许某种请求方式。
而调用的具体方法则是根据 URL 进行方法调用,而方法所需要的参数可能是对服务调用方传输过去的 XML 数据或者 JSON 数据解析后的结果,***返回 JOSN 或者 XML 的数据结果。
由于目前有很多开源的 Web 服务器,如 Tomcat,所以其实现起来更加容易,就像做 Web 项目一样。
两种方式对比
基于TCP协议实现的RPC调用,由于TCP协议处于协议栈的下层,能够更加灵活地对协议字段进行定制,减少网络开销,提高性能,实现更大的吞吐量和并发数。
但是需要更多关注底层复杂的细节,实现的代价更高。同时对不同平台,如安卓,iOS 等,需要重新开发出不同的工具包来进行请求发送和相应解析,工作量大,难以快速响应和满足用户需求。
基于 HTTP 协议实现的 RPC 则可以使用 JSON 和 XML 格式的请求或响应数据。
而 JSON 和 XML 作为通用的格式标准,开源的解析工具已经相当成熟,在其上进行二次开发会非常便捷和简单。但是由于 HTTP 协议是上层协议,发送包含同等内容的信息,使用 HTTP 协议传输所占用的字节数会比使用 TCP 协议传输所占用的字节数更高。因此在同等网络下,通过 HTTP 协议传输相同内容,效率会比基于 TCP 协议的数据效率要低,信息传输所占用的时间也会更长,当然压缩数据,能够缩小这一差距。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号