
数据结构3 - 「哈希」
一 哈希表
哈希即散列技术,就是数据保存的存储位置和关键字之间存在一个映射关系,使得关键字可以和存储位置直接对应起来。
记录的存储位置 p 和关键字 key 之间确定一个对应关系 H,使得 p = H(key),则称关系 H 为散列函数,p 为散列地址。
通过散列技术将数据存储起来的所建成的存储结构称之为哈希表(Hash table)。
二 散列函数构造法
1.除留余数法
2.直接定址法
3.数字分析法
4.平方取中法
5.折叠法
6.随机数法
三 冲突处理
1.开放地址法 - 线性探测法/二次探测法/伪随机探测法
2.链地址法
3.公共溢出区法
4.再散列函数法
5.折叠法
6.随机数法
四 hash表的时间复杂度为什么是O(1)
我们先从数组说起,创建数组必须要内存中一块连续的空间,并且数组中必须存放相同的数据类型。比如我们创建一个长度为10,数据类型为整型的数组,在内存中的地址是从1000开始,那么内存中的存储格式如下
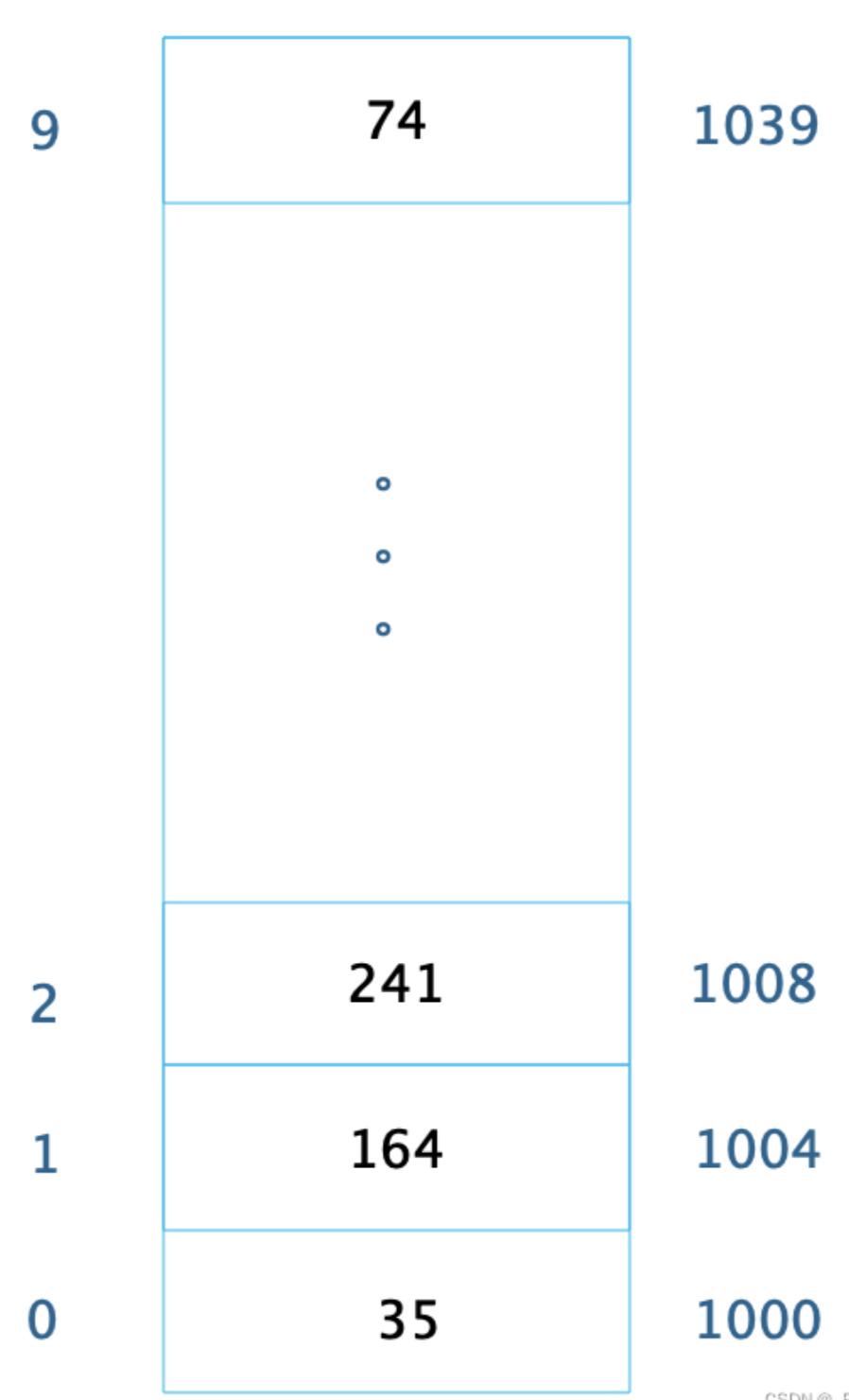
由于每个整型数据占据4个字节的内存空间,因此整个数组的内存空间地址是 1000~1039。根据这个我们可以轻易算出数组中每个数据的内存下标地址。比如下标 2可以计算得到这个数据在内存中的位置1008,从而对这个位置的数据 241进行快速读写访问,时间复杂度为O(1)
Hash 表的物理存储其实是一个数组,如果我们能够根据 Key 计算出数组下标,那么就可以快速在数组中查找到需要的 Key 和 Value。许多编程语言支持获得任意对象的 HashCode,比如Java中HashCode方法返回值是一个Int。可以利用这个Int类型的HashCode计算数组下标。最简单的方法就是除留余数法。
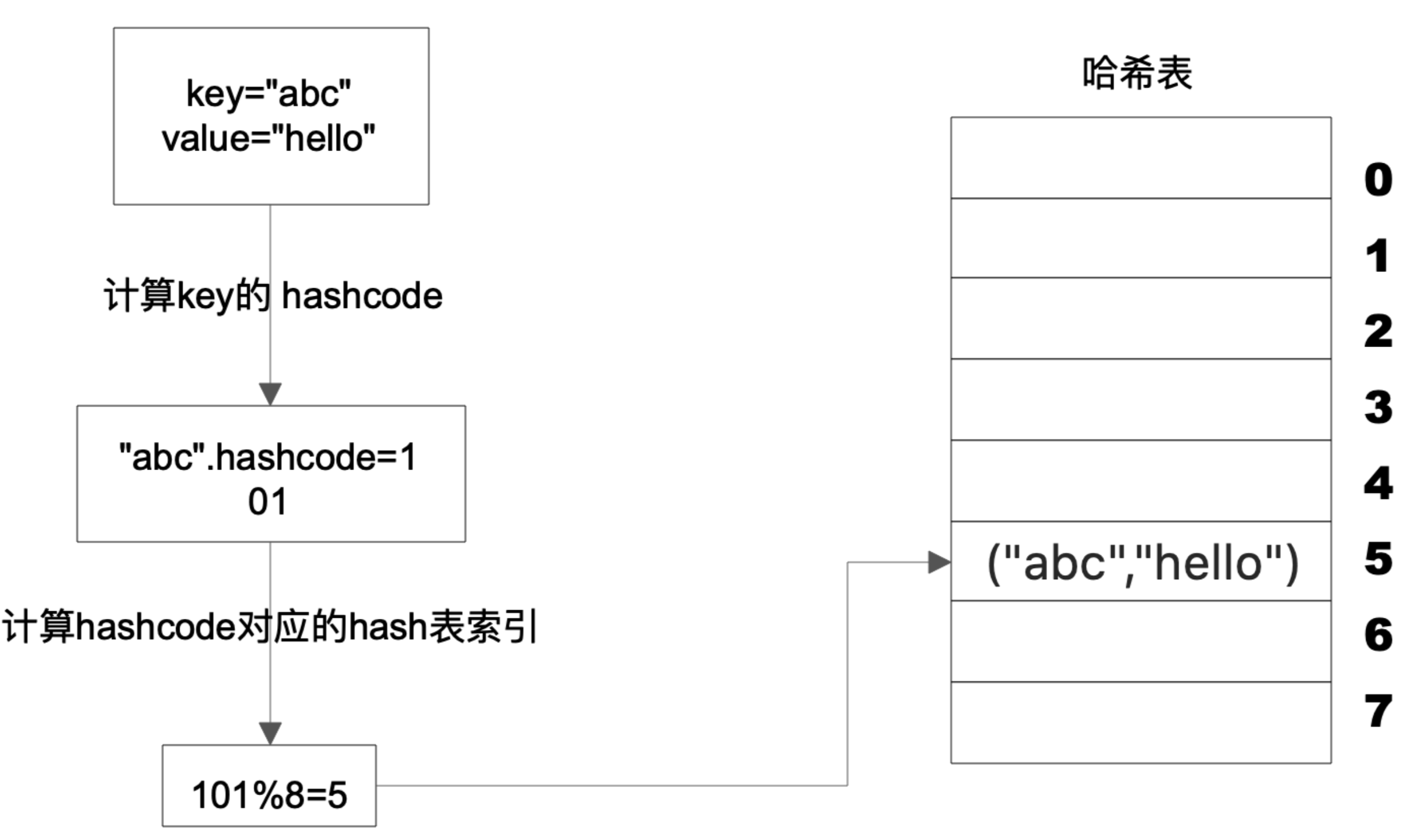
上图这个例子中,Key是字符串abc,Value是字符串hello。我们先计算Key的哈希值,得到101这样一个整型值。然后对8取模余5就是数组的下标,这样就可以把 ("abc", "hello") 这样一个 Key、Value 值存储在下标为5的数组中
但是如果不同的 Key 计算出来的数组下标相同怎么办?这就是所谓的 Hash 冲突,解决 Hash 冲突常用的方法是链表法
事实上, ("abc", "hello") 这样的 Key、Value 数据并不会直接存储在Hash表的数组中,因为数组要求存储固定数据类型,主要目的是每个数组元素中要存放固定长度的数据。所以,数组中存储的是 Key、Value 数据元素的地址指针。一旦发生 Hash 冲突,只需要将相同下标,不同Key的数据元素添加到这个链表就可以了。查找的时候再遍历这个链表,匹配正确的Key。
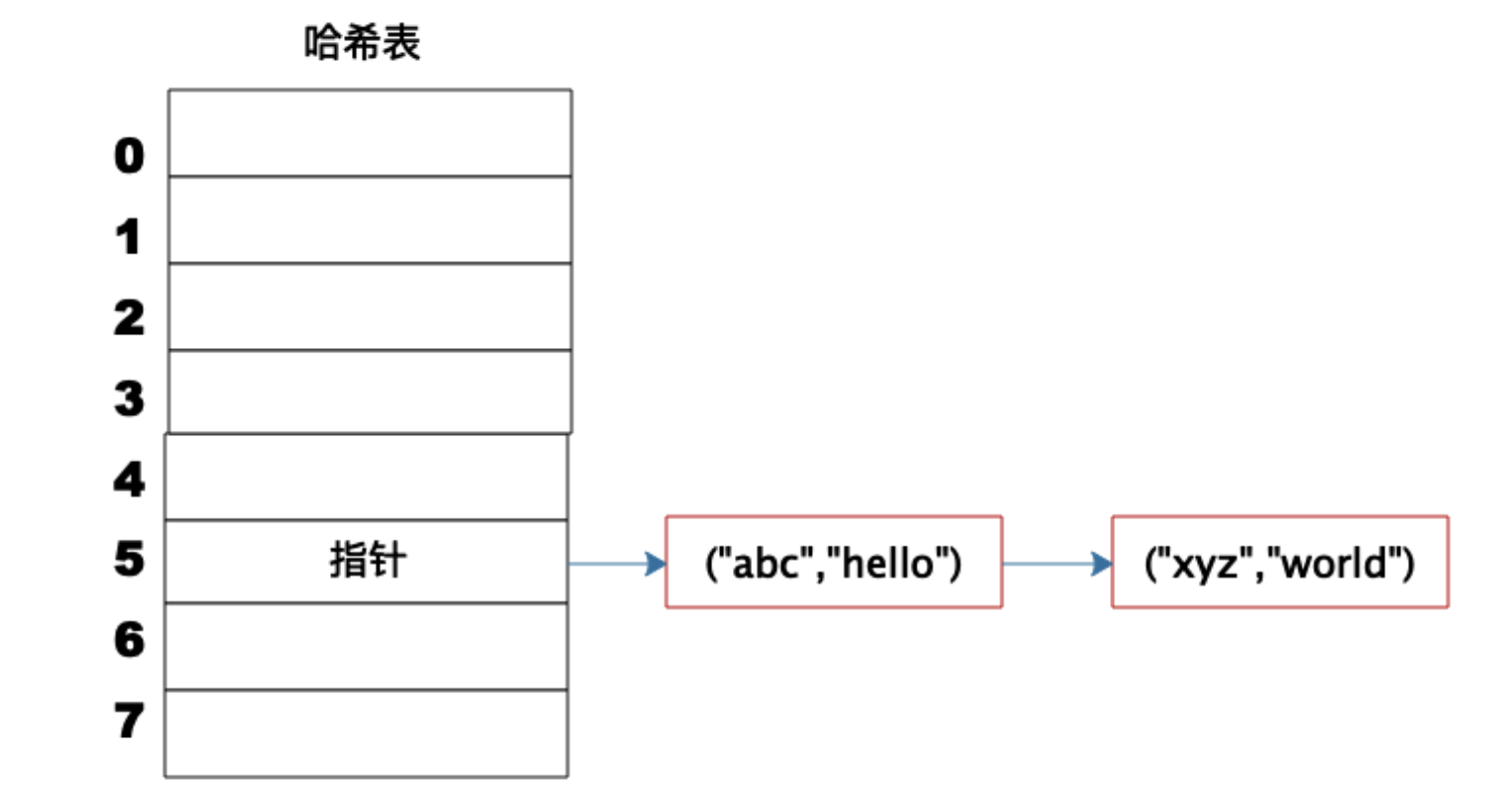
因为有 Hash 冲突的存在,所以"Hash 表的时间复杂度为什么是 O(1)?"这句话并不严谨,极端情况下,如果所有 Key 的数组下标都冲突,那么 Hash 表就退化为一条链表,查询的时间复杂度是 O(N)。但是作为一个面试题,“Hash 表的时间复杂度为什么是 O(1)”是没有问题的。
五 为什么重写equals方法也一定要重写hash方法
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {//注:这里的hash其实也是由key计算得到的。详见上面的put方法传参 Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);//(1) else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null);//(2) if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key//(3) V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
1. 只重写了equals没重写hashCode或hashCode和equals方法都没有重写
则new出来的两个key对应的类的对象即便属性完全相同,也会被HashMap的put方法判定为两个不同的元素(不同索引位置上的两个不同的元素),从而走到//(1),被作为新元素,都添加到HashMap中,而非更新key对应的value值。
2. 只重写了hashCode没重写equals
则new出来的两个key对应的类的对象即便属性完全相同,也会被HashMap的put方法判定为两个不同的元素(同一个索引位置上的链表上的两个不同的元素),从而走到//(2),被作为新元素,都添加到HashMap中,而非更新key对应的value值。
3. 重写了hashCode和equals
则new出来的两个key对应的类的对象如何属性完全相同,则会被HashMap的put方法判定为一个相同的元素,会走到//(3),更新key对应的value值。
(延伸:总之就是都要重写,否则put时候认为是不同元素,预期更新,实际新增了~)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号