
数据结构——递归与非递归
目录
我们先来看一下官方对递归的定义,编程语言中,函数 F(type a, type b, ……)直接或间接地调用函数本身,则称该函数为递归函数。 初学者对这个概念可能不是很理解,我们可以通过一些简单的例子来理解一下递归的概念。先看一张图,

从这张图中,我们可以看到,当一个人手中拿着一面镜子同时照镜子的时候,就会呈现出上面的情形,似乎进入了一种死循环——镜子照镜子照镜子照镜子……相信大家也一定听过一个故事,从前有一座山,山上有一座庙,庙里有一个老和尚再给小和尚讲故事,从前有一座山……这其实也是一种递归。
1.1.1 递归函数调用
为了能够更好地理解递归地定义,我们假设有如下递归函数:
1 void func(int a, int b) 2 { 3 a++; 4 b++; 5 func(a, b); 6 a++; 7 b++; 8 }
我们看到第五行就是函数调用自己本身,这便是一个递归函数。
当我们遇到一些问题想要使用递归进行解决时,我们会发现很困难,理解看懂递归很容易,可是使用递归却非常地困难。然而递归有着一般的解题思路,我将其称为递归三部曲。
1.2.1 第一部、确定函数的功能
我们已经知道了递归就是函数直接或间接地调用本身,那么我们首先需要的就是一个函数,确定函数的功能,就是要知道这个函数要完成一件什么样的事,而这件事,是由编写函数的人自己确定的。换句话说,就是我们不需要给出这个函数内部的具体定义,只要先明白函数是用来干嘛的就可以了。
比如,我们现在需要计算一个数n的阶乘。
1 // function: 2 // 计算n的阶乘(函数功能) 3 // params: 4 // n为需要计算阶乘的数值 5 int f(int n) 6 { 7 // TODO 具体定义 8 }
这里函数的功能就是计算n的阶乘。
1.2.2 第二部、确定递归终止条件
在1.1什么是递归中我们举了两个例子,照镜子和山上有座庙故事的例子,我们发现这两个例子都是死循环,会无休止地递归下去,这样地函数是我们需要避免写出来地,因为计算机的资源是有限的,如果递归的层次过深,就会造成"爆栈"的风险,如果不能理解什么是"爆栈",没有关系,你可以先认为递归层次过深,内存会发生溢出。而照镜子的例子是一个无限递归,他需要的内存资源是无限的,所以这样就会发生内存溢出的风险。所以我们需要给递归确定终止条件,这样才能防止内存溢出。
我们继续看计算一个数n的阶乘的例子。我们知道当n=1时,n! = 1;所以,我们就找到了递归函数的终止条件,将上面的代码完善如下:
1 // function: 2 // 计算n的阶乘(函数功能) 3 // params: 4 // n为需要计算阶乘的数值 5 int f(int n) 6 { 7 if (1 == n) 8 return n; 9 10 }
这样,我们就找到了递归终止条件,完成了二部曲。
1.2.3 第三部、确定递推关系式
这一部往往是写递归函数的难点,因为他需要你具有递归逻辑思维才能写出来,在这里由于本人水平有限,不能找到一般递推关系式的推演方法。如果大家有兴趣可以参考相应书籍并进行相应习题练习。
不过在计算一个数n的阶乘的例子中,递推关系式很容易就可以找到: f(n) = n * f(n-1),我们可以继续完善上述代码:
1 // function: 2 // 计算n的阶乘(函数功能) 3 // params: 4 // n为需要计算阶乘的数值 5 int f(int n) 6 { 7 if (1 == n) // 终止条件 8 return n; 9 else 10 return n * f(n - 1); // 递推关系式 11 12 }
到这里,我们就已经初步学习了递归函数如何撰写的一般步骤了。
我们已经知道了什么是递归函数,就是函数调用自己本身的函数。那么什么是尾递归呢?
尾递归就是函数调用本身的位置处于函数最后一行的位置,这就是尾递归。
1 void func(int a, int b) 2 { 3 a++; 4 b++; 5 func(a, b); 6 }
这个递归函数在末尾调用了自身,所以这是一个尾递归。
那么,我们再来看上面的n的阶乘的例子:
1 // function: 2 // 计算n的阶乘(函数功能) 3 // params: 4 // n为需要计算阶乘的数值 5 int f(int n) 6 { 7 if (1 == n) // 终止条件 8 return n; 9 else 10 return n * f(n - 1); // 递推关系式 11 12 }
这里return n*f(n-1);是不是尾递归呢?答案不是的。尽管这条语句处于函数的末尾,但是f(n)函数进行了运算,所以他并不是尾递归。
我们需要注意,只有当函数本身没有参与操作,并处于末尾的时候,才是尾递归!
那么尾递归有什么用呢?尾递归其实是为了解决上面说到的"爆栈"问题而存在的,现在大多数的编程语言编译的时候都进行了尾递归优化。详细的内容可以看1.5函数栈部分。
1.4.1 阶乘问题
题目:求数n的阶乘,这个问题我们已经讲过了,代码如下所示:
1 // function: 2 // 计算n的阶乘(函数功能) 3 // params: 4 // n为需要计算阶乘的数值 5 int f(int n) 6 { 7 if (1 == n) // 终止条件 8 return n; 9 else 10 return n * f(n - 1); // 递推关系式 11 12 }
1.4.2 斐波那契数列
题目:斐波那契数列的是这样一个数列:1、1、2、3、5、8、13、21、34....,即第一项 f(1) = 1,第二项 f(2) = 1.....,第 n 项目为 f(n) = f(n-1) + f(n-2)。求第 n 项的值是多少。
根据递归三部曲,我们依次给出解题步骤:
(1)确定函数功能
我们假设 fabonic(n) 的功能是求第 n 项的值,代码如下:
1 // function: 2 // 求第n项的值 3 // params: 4 // n 第n项 5 // return: 6 // 第n项的值 7 int fabonic(int n) 8 { 9 // TODO 具体定义 10 }
(2)确定终止条件
我们可以知道当n=1时,fabonic(1)=1;当n=1时,fabonic(1)=2;所以代码如下所示:
1 // function: 2 // 求第n项的值 3 // params: 4 // n 第n项 5 // return: 6 // 第n项的值 7 int fabonic(int n) 8 { 9 if (n <= 2) // 终止条件 10 { 11 return 1; 12 } 13 }
(3)确定递推关系式
题目中已经给出了递推关系式,所以代码如下:
1 // function: 2 // 求第n项的值 3 // params: 4 // n 第n项 5 // return: 6 // 第n项的值 7 int fabonic(int n) 8 { 9 if (n <= 2) // 终止条件 10 { 11 return 1; 12 } 13 else 14 { 15 return f(n - 1) + f(n - 2); // 递推关系式 16 } 17 }
1.4.3 汉诺塔问题
问题:相传在古印度圣庙中,有一种被称为汉诺塔(Hanoi)的游戏。该游戏是在一块铜板装置上,有三根柱子(编号A、B、C),在A柱自下而上、由大到小按顺序放置n个盘子(如下图)。
游戏的目标:把A柱上的盘子全部移到C柱上,并仍保持原有顺序叠好。操作规则:每次只能移动一个盘子,并且在移动过程中三根柱上都始终保持大盘在下,小盘在上,操作过程中盘子可以置于A、B、C任一柱上。
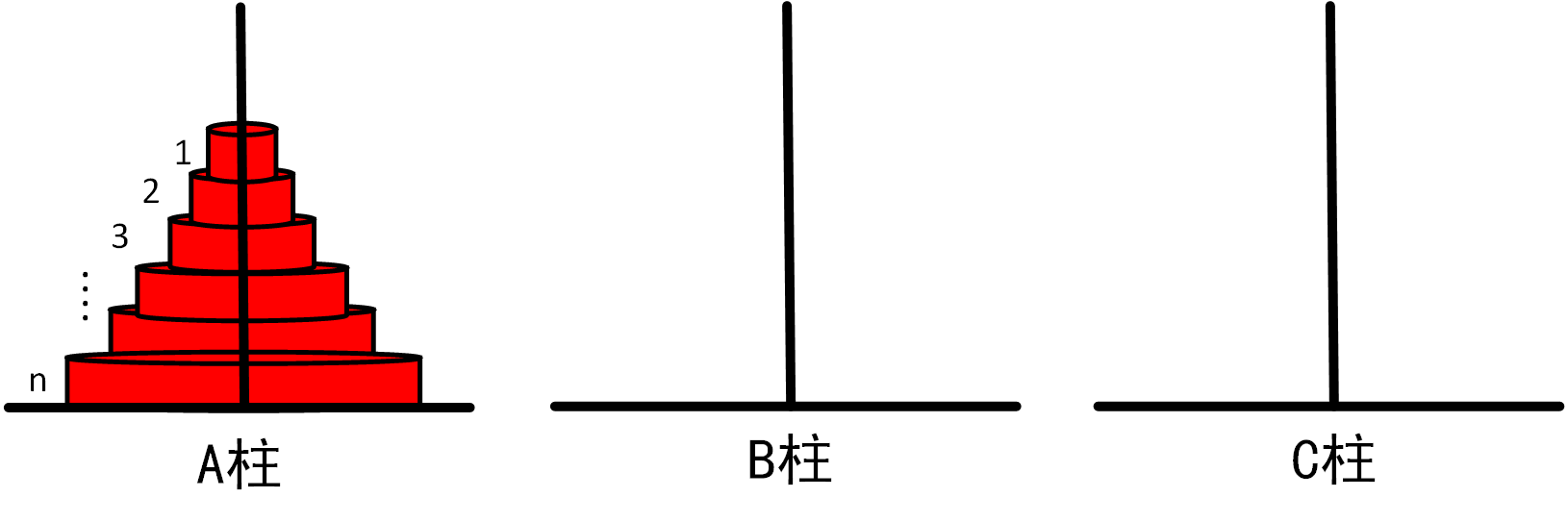
图1.3.1_0
为了能够更好地解决这道题目,我们先通过画图来理解一下这道题目。
(1)当n=1时,情况如下图所示:
=>将1盘从A柱移动到C柱
总移动次数=1
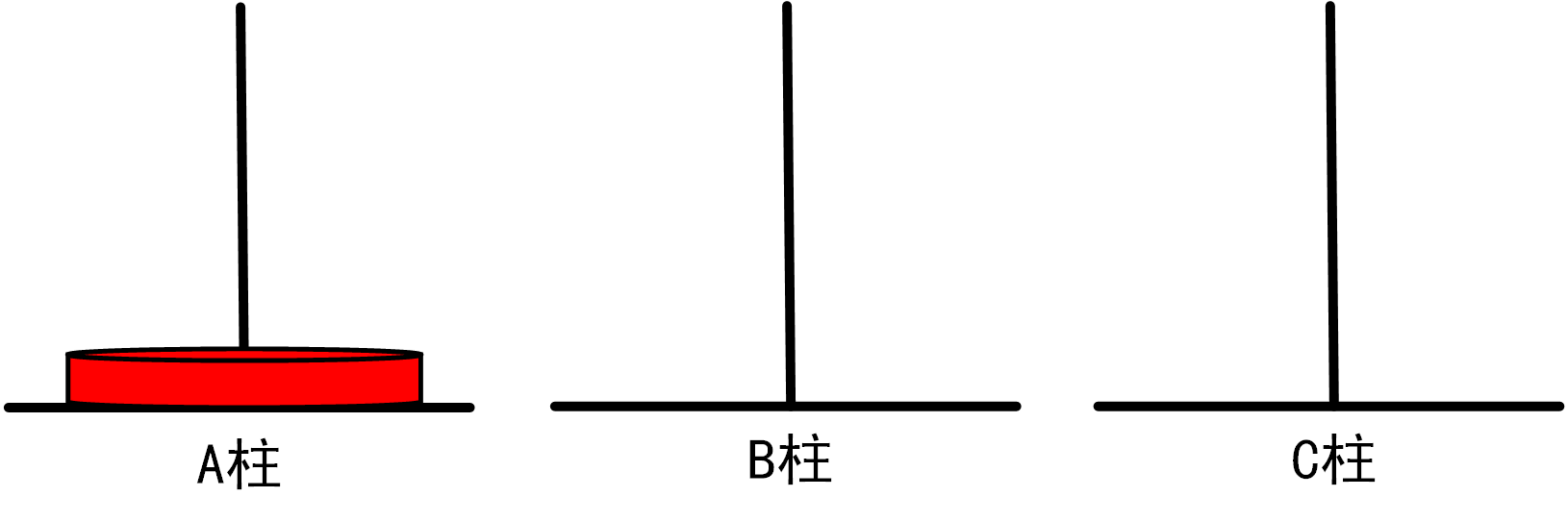
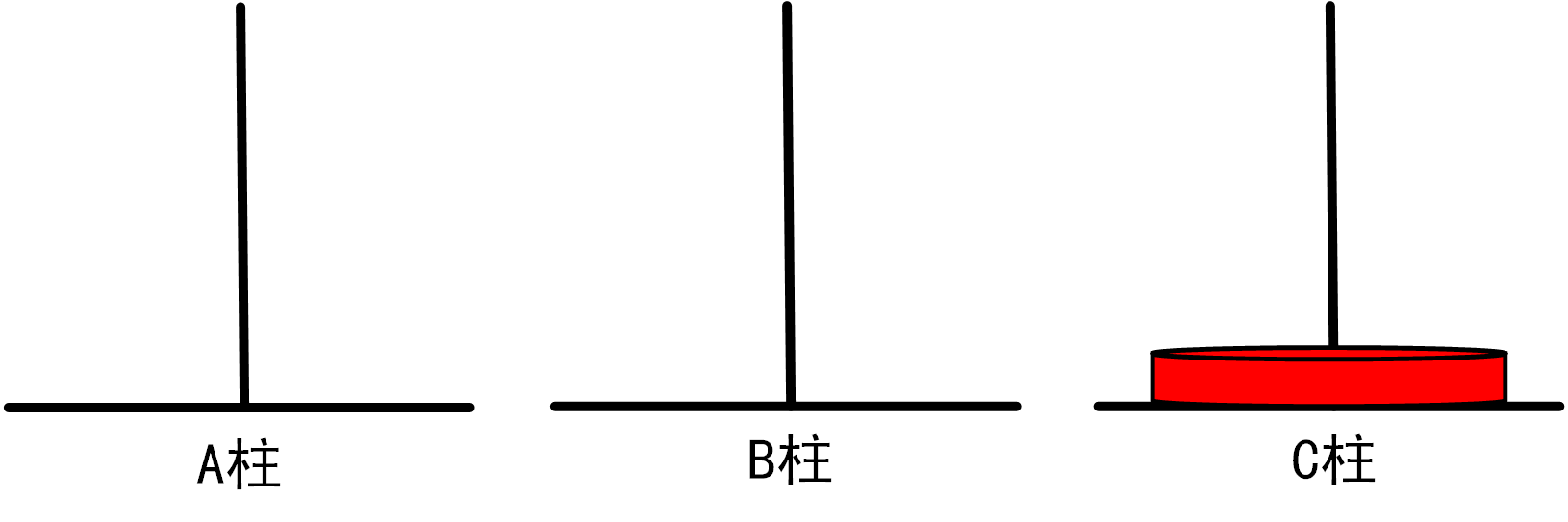
图1.3.1_1
(2)当n=2时,我们需要进行如下移动步骤:
将1号盘从A柱移动到B柱
=>将2号盘从A柱移动到C柱
将1号盘从B柱移动到C柱
总移动次数=3
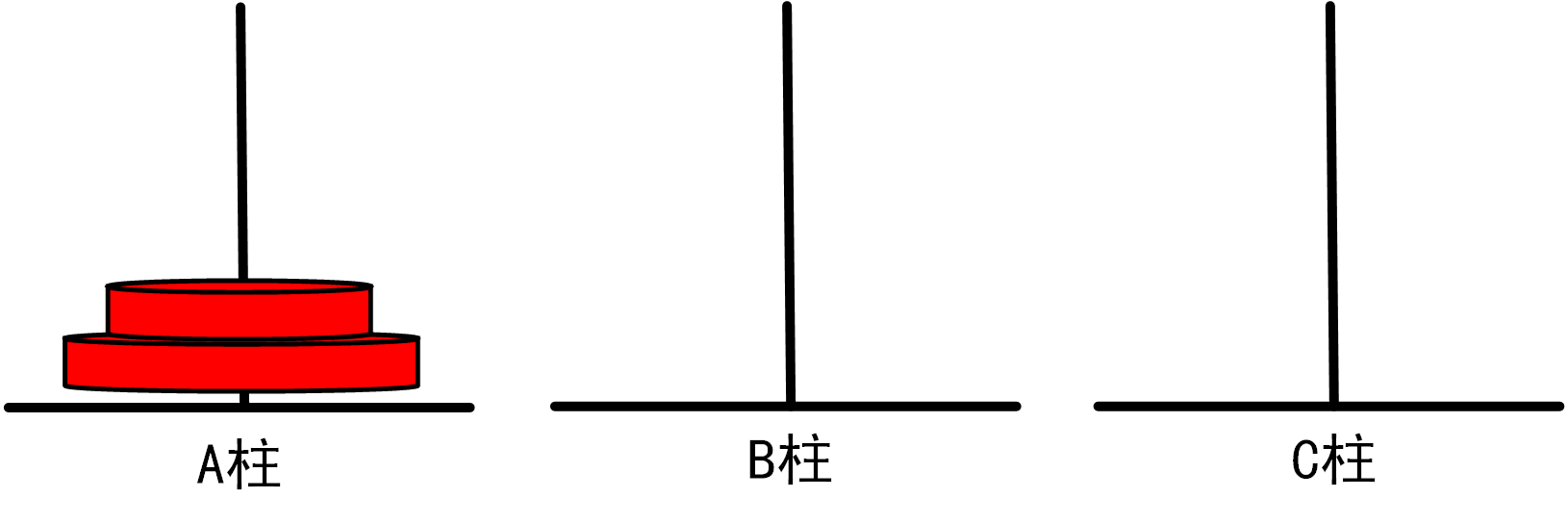
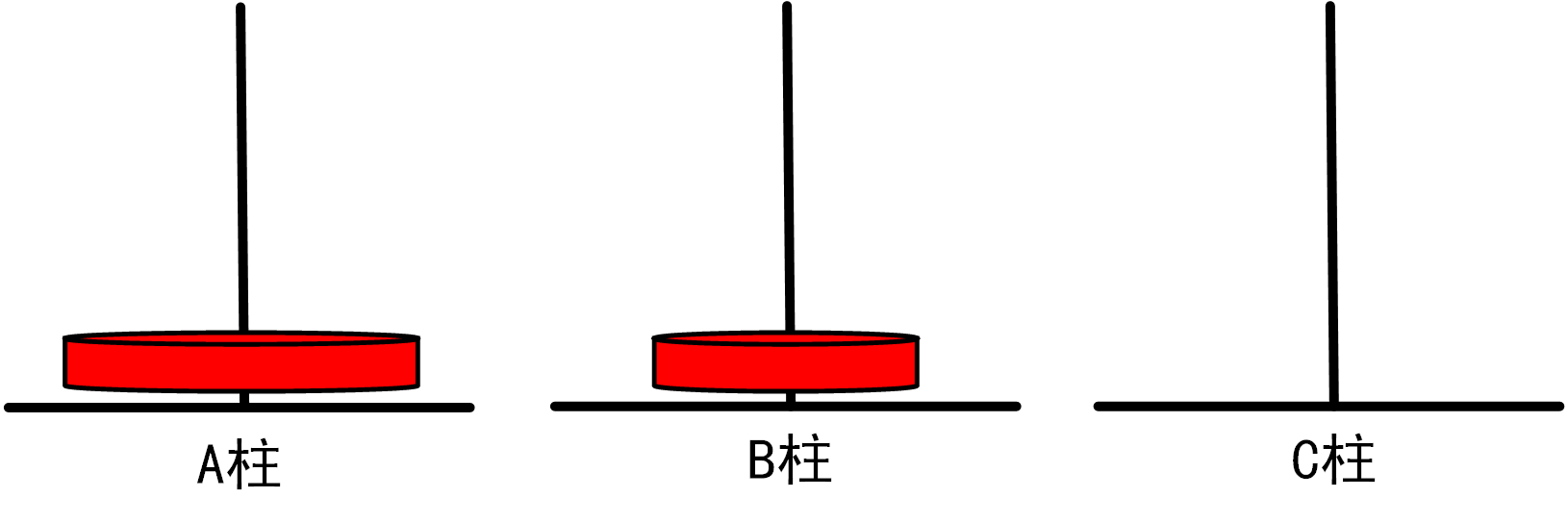

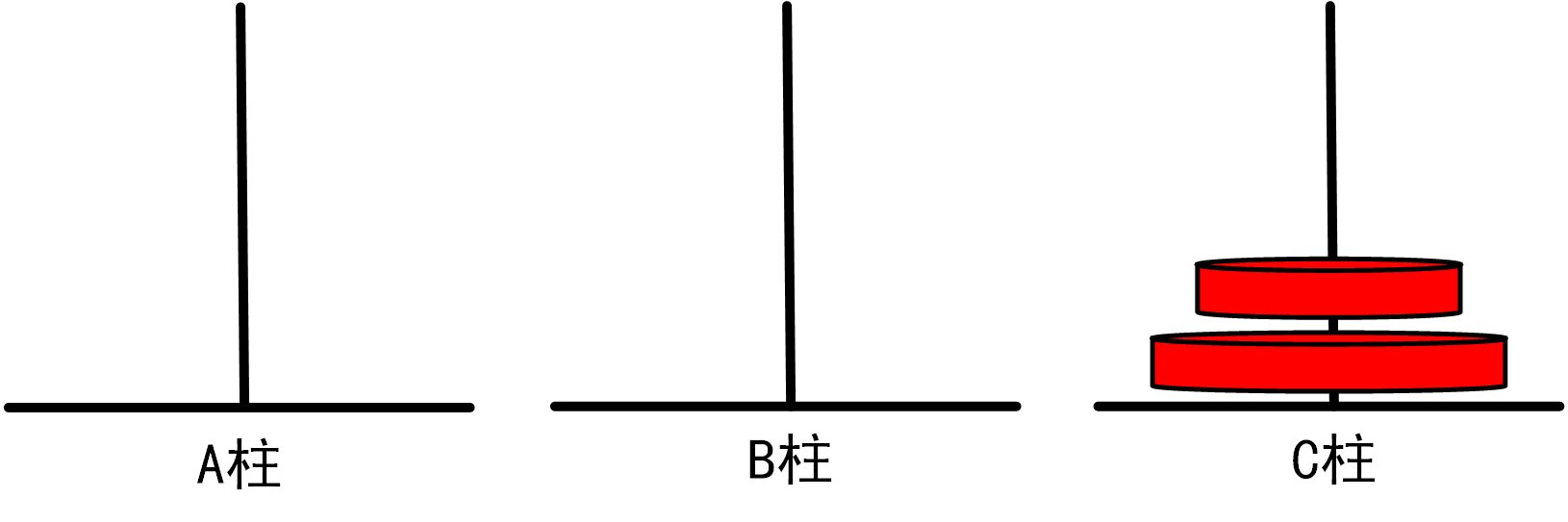
图1.3.1_2
(3)当n=3时,我们需要进行如下移动步骤:
将1号盘从A柱移动到C柱
将2号盘从A柱移动到B柱
将1号盘从C柱移动到B柱
=>将3号盘从A柱移动到C柱
将1号盘从B柱移动到A柱
将2号盘从B柱移动到C柱
将1号盘从A柱移动到C柱
总移动次数=7
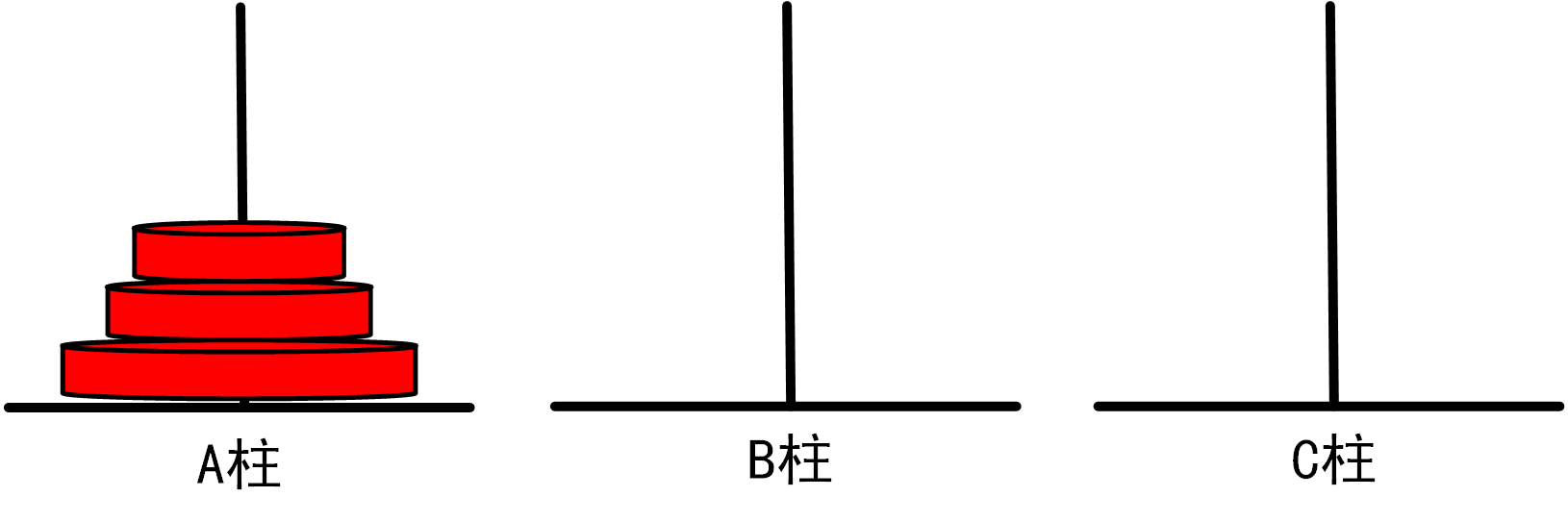
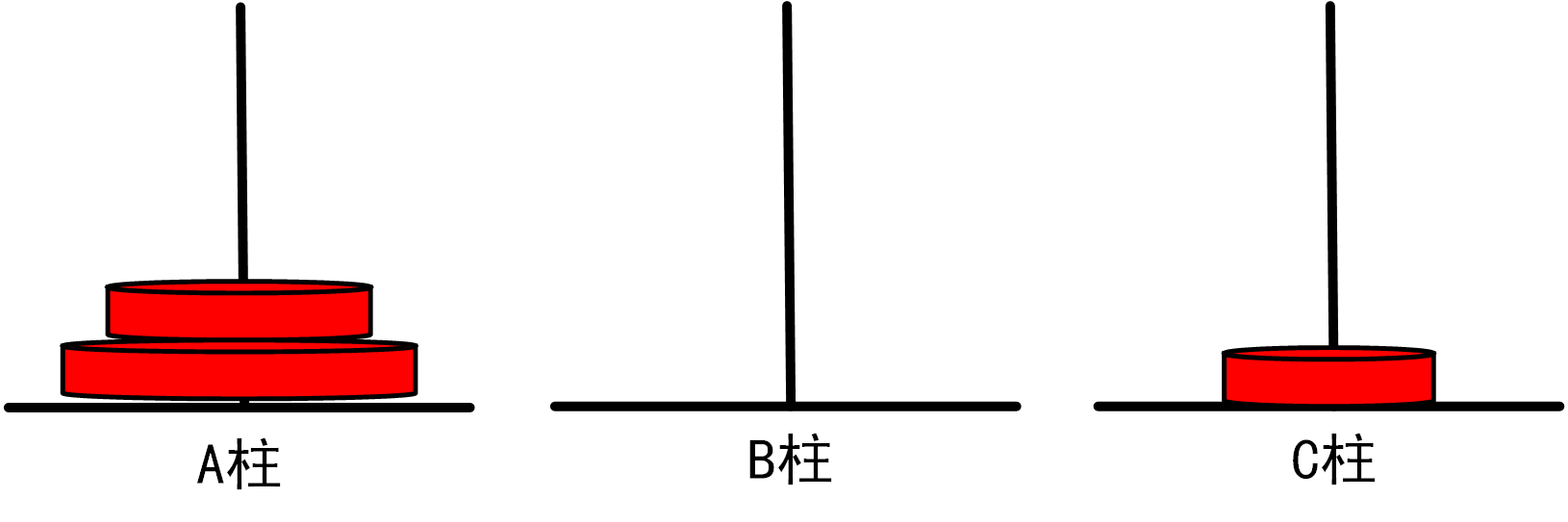
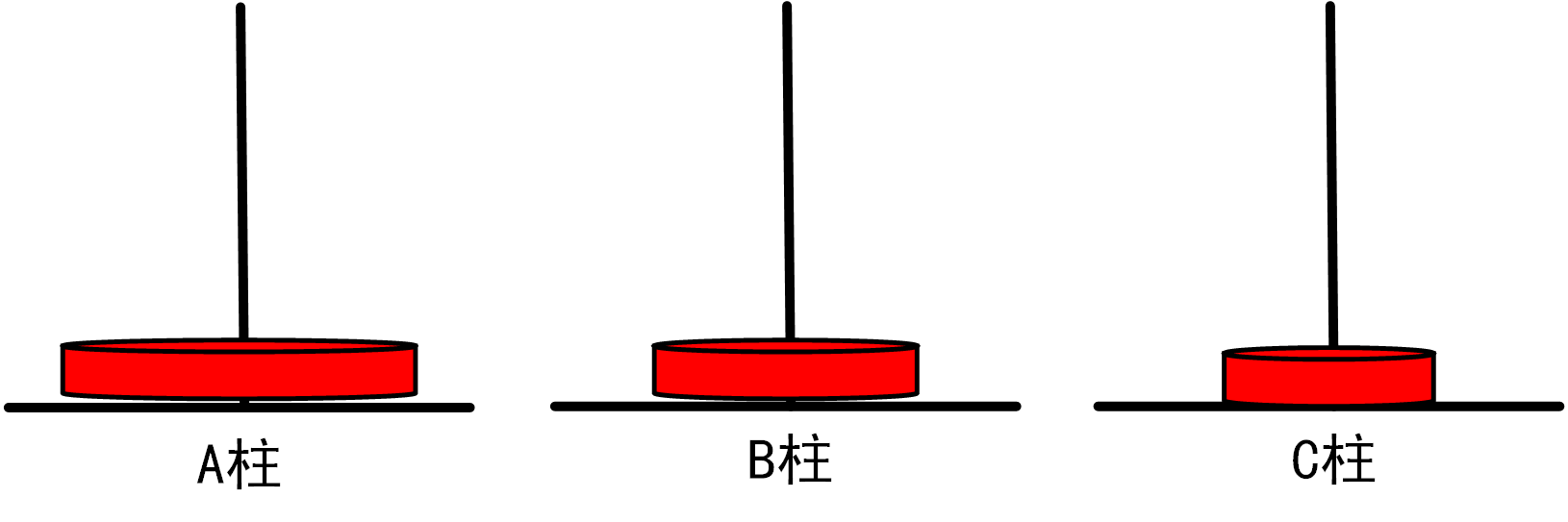
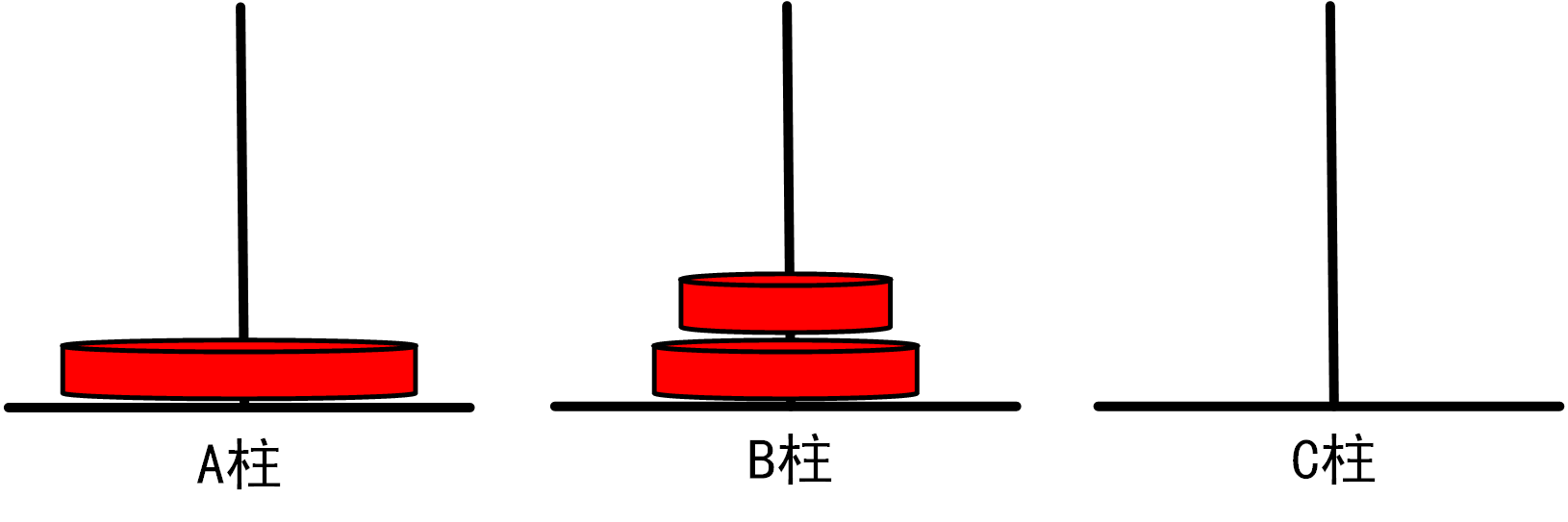
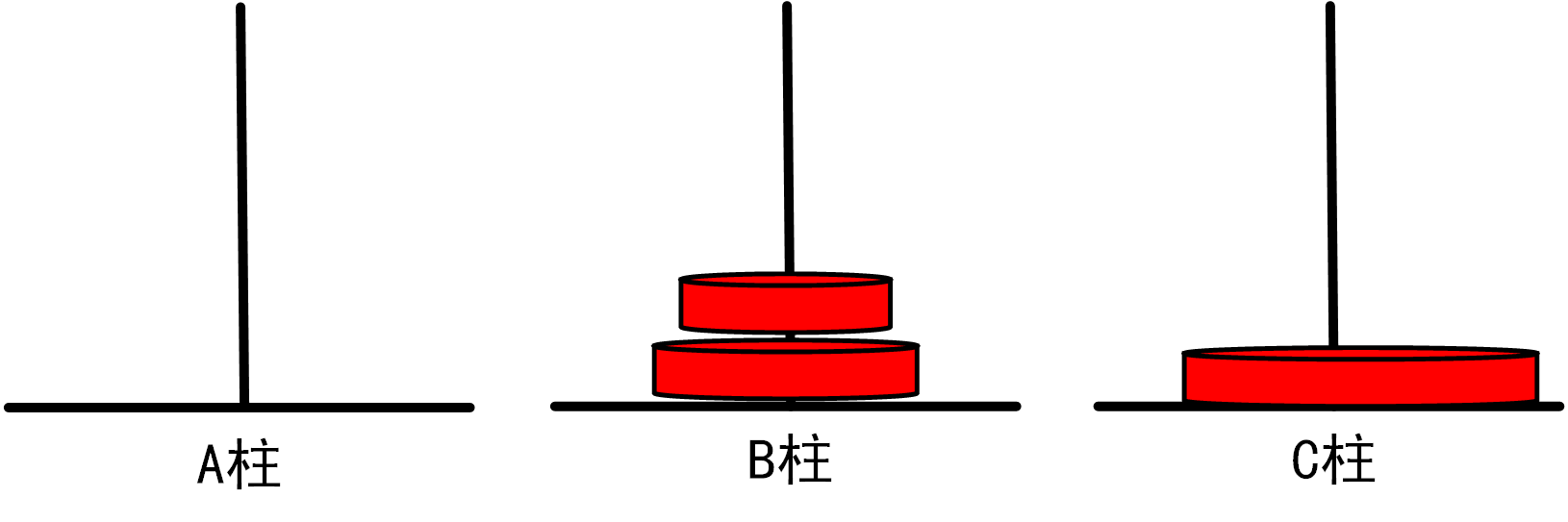
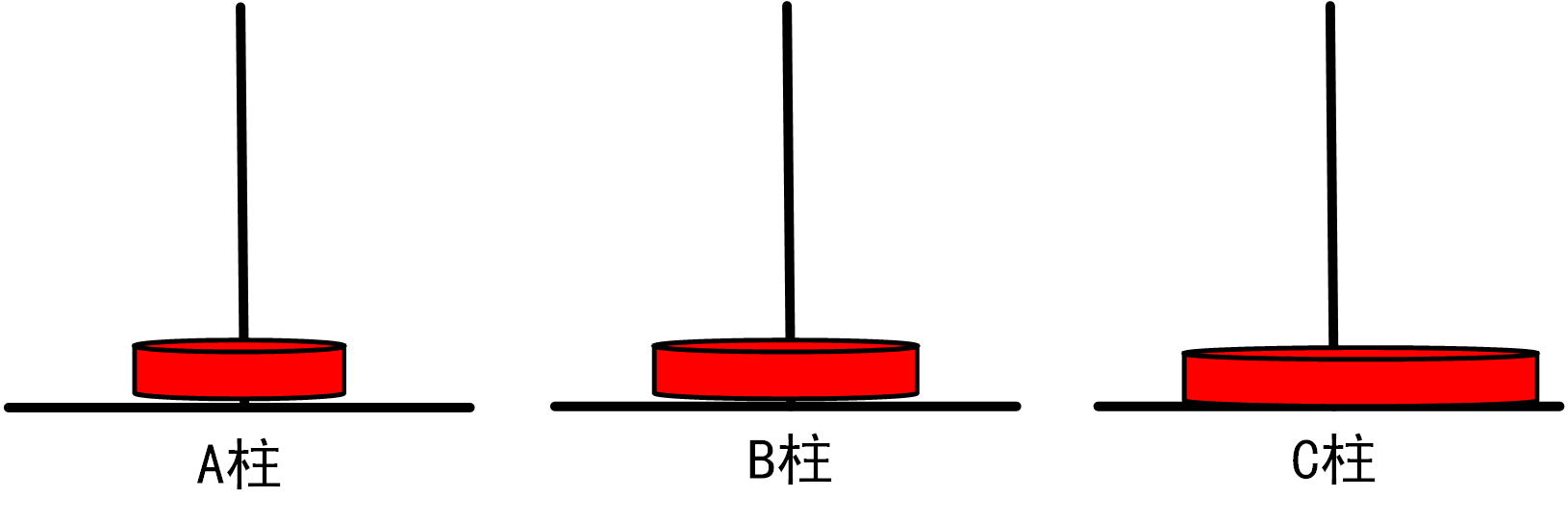
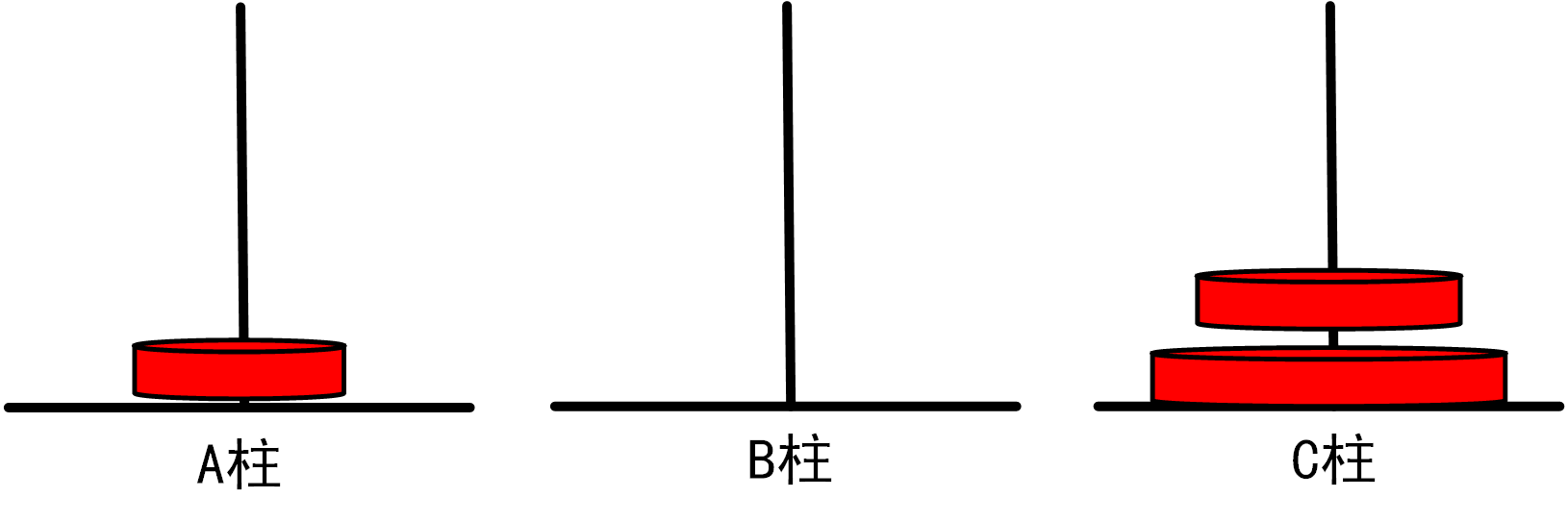
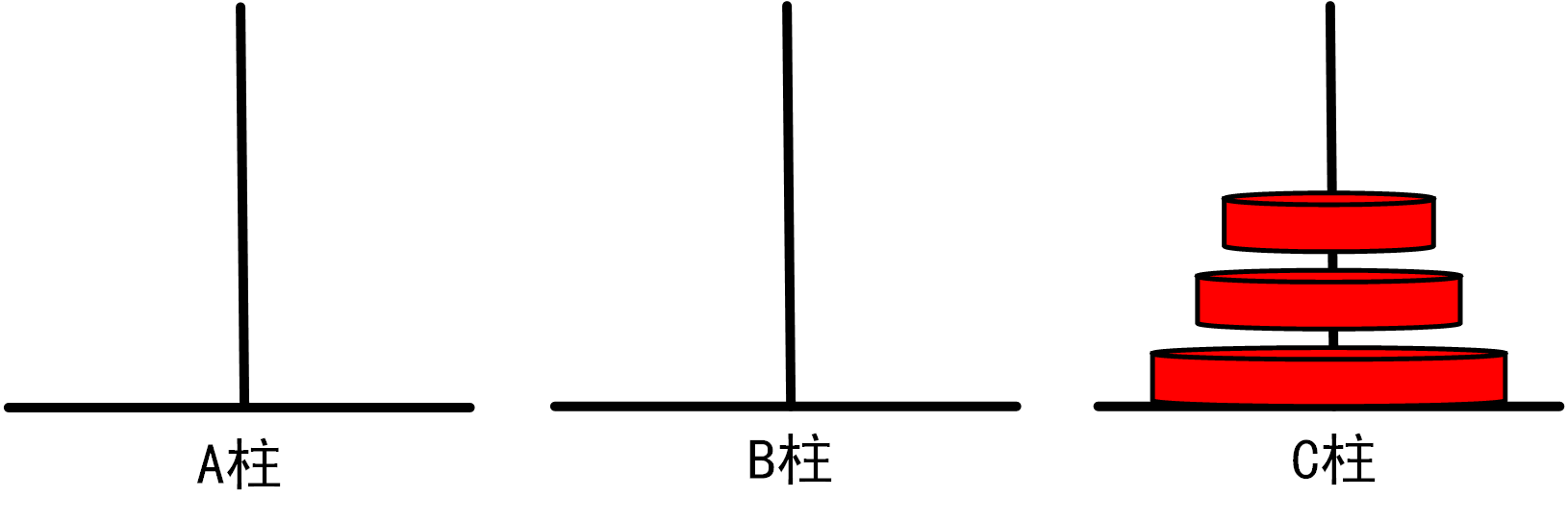
图1.3.1_3
通过上图,我们先来推出递归解法。根据递归三部曲,
第一步,先确定函数功能,把A柱上编号1~n的圆盘移到C柱上,以B为辅助柱,函数形式为f(n,A,B,C );
第二步,找到函数终止条件,此处为,当n=1时,将1号盘从A柱移动到C柱;
第三步,找到递推公式,我们经过分析,发现需要先将1号盘至n-1号盘移动到B柱上,其中C柱作为辅助柱,然后将最大的盘--A柱n号盘,从A柱移动到C柱上,最后将B柱上的1号盘至n-1号盘移动至C柱上;
综上,我们可以得到如下函数公式:
1 // 汉诺塔问题 2 // parameters: 3 // n 圆盘数目 4 // A A柱,初始塔(柱) 5 // B B柱,辅助塔(柱) 6 // C C柱,目标塔(柱) 7 void hanoi(int n, char A, char B, char C) 8 { 9 if (1 == n) 10 { 11 move(A, 1, C); // 将编号为1 的圆盘从A 移到 C 12 } 13 else 14 { 15 hanoi(n - 1, A, C, B); // 递归,把A塔上编号1~n-1的圆盘移到B上,以C为辅助塔 16 move(A, n, C); // 将编号为n 的圆盘从A 移到 C 17 hanoi(n - 1, B, A, C); // 递归,把B塔上编号1~n-1的圆盘移到C上,以A为辅助塔 18 } 19 }
至此,汉诺塔问题解决。
我们知道函数的递归调用,编程实现的本质其实就是借助函数栈来实现的。我们来看一个递归函数n的阶乘的例子。

函数其实是在一个函数栈中实现运行的,栈的特点是后进先出。当我们运行f(3)这个函数时,函数运行到return n * f(n-1)这条语句时,会产生函数调用,而进行函数调用之前,需要先将函数的局部变量(如上图蓝色框内所示)保存起来,也就是所谓地先将现场保存起来,然后进行参数地更新和函数调用。当函数调用完成返回时,需要将栈中的信息弹出,恢复现场,继续执行。

上图其实就是函数栈。
所以当我们的递归层次越深时,函数栈需要的空间便越大(因为需要栈空间来保存局部变量等信息),所以"爆栈"的风险便越大,那么有没有办法能解决上述问题呢?
显然是有的。还记得我们之前说的尾递归吗,因为尾递归处于函数的最末端,尾递归结束后,函数也相应地结束了,后续并没有操作了,这就意味着没有保存当前函数局部变量地必要了,我们可以把当前局部变量地栈空间用来存储尾递归地局部变量,这样尾递归所需要地空间就是O(1)了,而且也没有恢复现场地必要了,程序运行地时间也会变少。
我们知道了当递归函数地层次过深时,有可能会发生"爆栈"地风险,所以有时候我们需要将递归进行非递归话,也叫迭代化。
我们已经知道了函数栈,那么函数递归的本质其实可以归结为如下几点:
(1)在函数递归调用之前将局部变量保存到栈中
(2)修改参数列表
(3)进行函数递归调用
(4)获得栈顶元素(恢复现场)
(5)弹出栈顶元素(释放内存空间)
我们通过将几道经典地例题递归解法转化为迭代解法来初步探究一下。
2.2.1 n的阶乘问题
递归解法:
// function: // 计算n的阶乘(函数功能) // params: // n为需要计算阶乘的数值 int f(int n) { if (1 == n) // 终止条件 return n; else return n * f(n - 1); // 递推关系式 }
函数栈图解:
迭代解法:
1 struct Params 2 { 3 int n; 4 int result; 5 }; 6 7 8 int f(int n) 9 { 10 // 初始化栈 11 Params stack[10]; 12 int top = -1; 13 // n 和 result 是局部变量 14 int result = 0; 15 16 // 正向递归 17 while (1 != n) 18 { 19 // 保存局部变量 20 stack[++top].n = n; 21 stack[top].result = result; 22 23 // 对递归参数进行修改 24 n = n - 1; 25 } 26 27 // 终止条件 28 result = 1; 29 30 // 反向传参 31 while (-1 != top) 32 { 33 n = stack[top--].n; 34 result = result * n; 35 } 36 37 return result; 38 }
2.2.2 二叉树的中序遍历
递归解法:
/* 二叉树结点 */ template <typename DataType> struct BiNode { DataType data; BiNode<DataType>* lChild; BiNode<DataType>* rChild; }; /* 中序遍历 */ // bt 二叉树根节点 template <typename DataType> void inOrder(BiNode<DataType>* bt) { if (nullptr == bt) { return; } else { inOrder(bt->lChild); std::cout << bt->data; inOrder(bt->rChild); } }
函数栈图解:
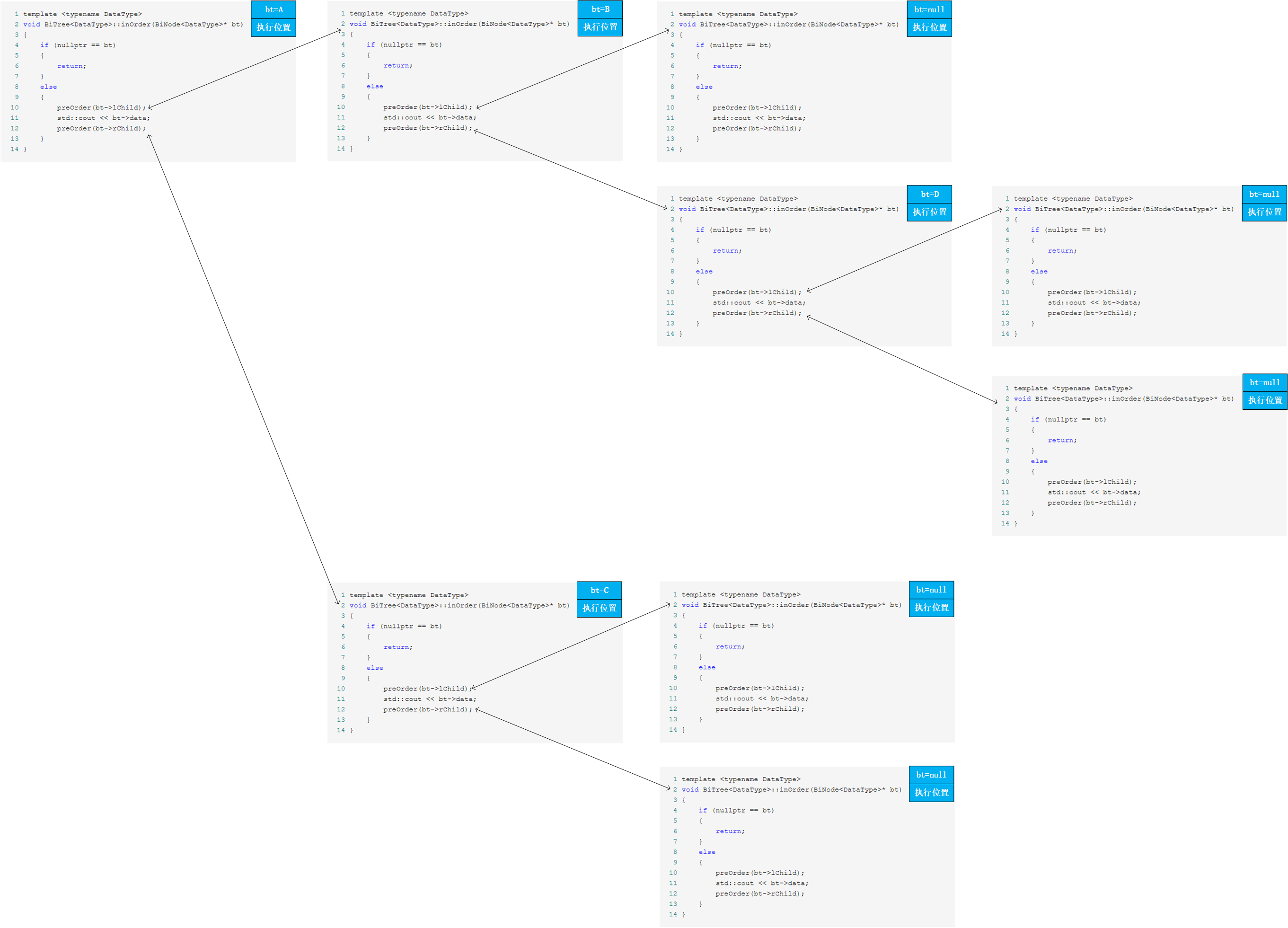
迭代解法:
1 template <typename DataType> 2 void inOrderIter() 3 { 4 BiNode<DataType>* stack[20]; 5 int top = -1; 6 BiNode<DataType>* bt = root; 7 8 while (nullptr != bt || -1 != top) 9 { 10 while (nullptr != bt) 11 { 12 stack[++top] = bt; 13 bt = bt->lChild; 14 } 15 16 if (-1 != top) 17 { 18 bt = stack[top--]; 19 std::cout << bt->data; 20 bt = bt->rChild; 21 } 22 } 23 }
2.2.3 汉诺塔问题
递归解法:


1 #include <iostream> 2 3 struct HanioNode 4 { 5 int n; // 盘数量 6 char A; // 初始塔 7 char B; // 辅助塔 8 char C; // 目标塔 9 }; 10 11 12 class Hanio 13 { 14 public: 15 Hanio(); 16 // Hanio(int n, char A = 'A', char B = 'B', char C = 'C'); 17 void play(HanioNode hanio); 18 void play(); 19 void move(char A, int n, char C); 20 HanioNode hanioNode; 21 }; 22 23 24 Hanio::Hanio() 25 { 26 hanioNode.n = 10; 27 hanioNode.A = 'A'; 28 hanioNode.B = 'B'; 29 hanioNode.C = 'C'; 30 } 31 32 33 void Hanio::move(char A, int n, char C) 34 { 35 std::cout << n << "从" << A << "移动到了" << C << std::endl; 36 } 37 38 39 void Hanio::play(HanioNode hanio) 40 { 41 if (1 == hanio.n) 42 { 43 move(hanio.A, 1, hanio.C); 44 } 45 else 46 { 47 HanioNode temp = hanio; 48 temp.n = hanio.n - 1; 49 temp.A = hanio.A; 50 temp.B = hanio.C; 51 temp.C = hanio.B; 52 play(temp); 53 54 move(hanio.A, hanio.n, hanio.C); 55 56 temp.n = hanio.n - 1; 57 temp.A = hanio.B; 58 temp.B = hanio.A; 59 temp.C = hanio.C; 60 play(temp); 61 } 62 }
函数栈图解:
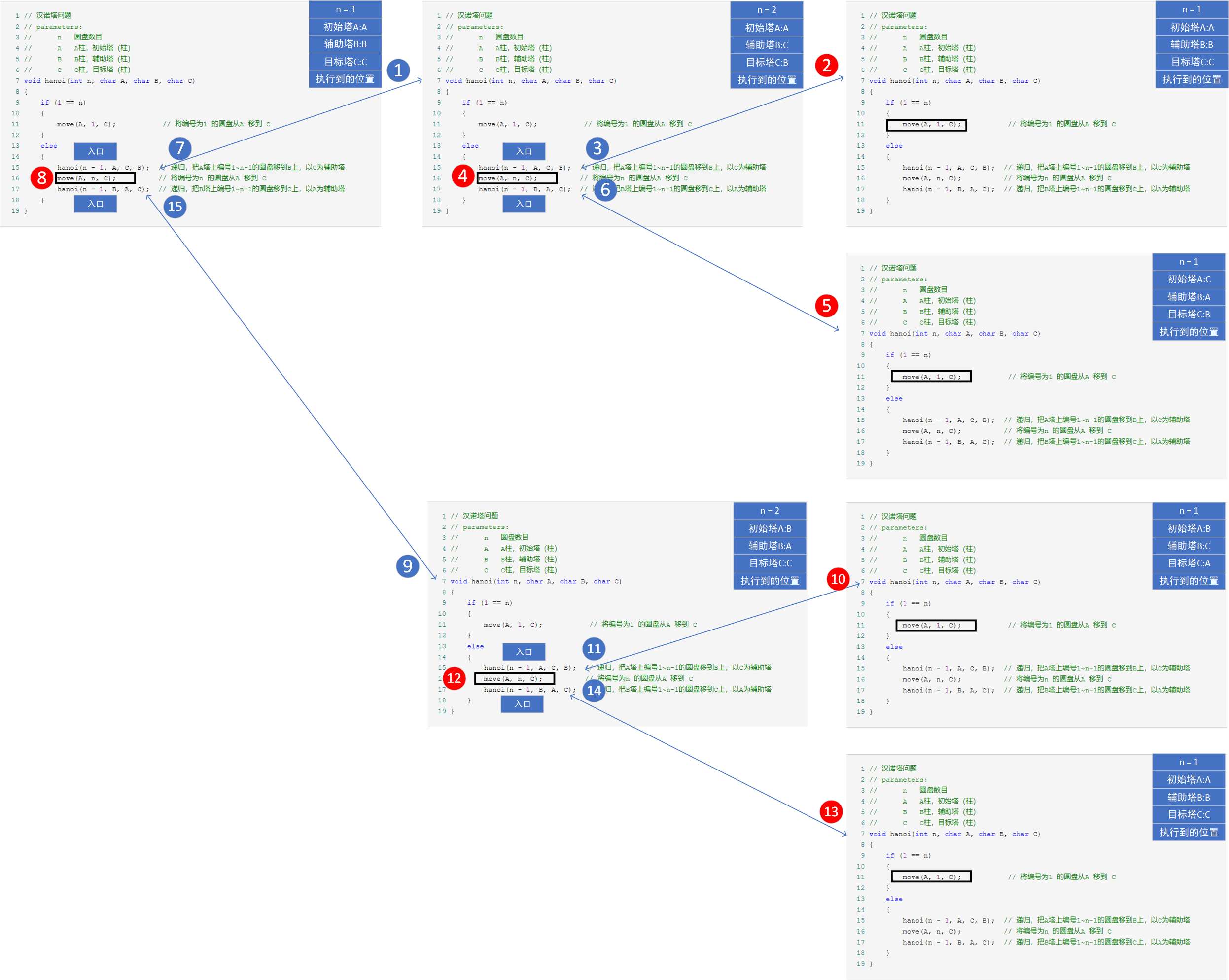
迭代解法:
1 void Hanio::play() 2 { 3 HanioNode hanio = hanioNode; 4 HanioNode stack[10]; 5 int top = -1; 6 int count = 0; 7 8 while (1 != hanio.n || -1 != top) 9 { 10 while (1 != hanio.n) 11 { 12 stack[++top] = hanio; 13 14 HanioNode temp = hanio; 15 hanio.n = temp.n - 1; 16 hanio.A = temp.A; 17 hanio.B = temp.C; 18 hanio.C = temp.B; 19 } 20 21 move(hanio.A, 1, hanio.C); 22 count++; 23 24 if (-1 != top) 25 { 26 hanio = stack[top--]; 27 move(hanio.A, hanio.n, hanio.C); 28 count++; 29 30 HanioNode temp = hanio; 31 hanio.n = temp.n - 1; 32 hanio.A = temp.B; 33 hanio.B = temp.A; 34 hanio.C = temp.C; 35 } 36 } 37 38 move(hanio.A, 1, hanio.C); 39 count++; 40 std::cout << "count:" << count << std::endl; 41 }
递归迭代化的本质就是掌握函数栈,
(1)在函数递归调用之前将局部变量保存到栈中
(2)修改参数列表
(3)进行函数递归调用
(4)获得栈顶元素(恢复现场)
(5)弹出栈顶元素(释放内存空间)
因为编者水平有限,很难总结出普适的一般规律,抱歉。
当递归层次不是很深时(小于1000),我们其实没有必要将其进行迭代化,迭代后的代码会比较难理解。
1、 [汉诺塔图解递归算法](https://www.cnblogs.com/dmego/p/5965835.html)
2、 [递归转化为非递归的一般方法](https://blog.csdn.net/biran007/article/details/4156351)
3、 [尾递归为啥能优化](https://zhuanlan.zhihu.com/p/36587160)
4、 [汉诺塔的非递归算法](https://www.cnblogs.com/blogzcan/p/7485372.html)
5、 [尾调用优化](http://www.ruanyifeng.com/blog/2015/04/tail-call.html)
6 、[尾递归是个什么鬼](https://www.cnblogs.com/zhanggui/p/7722541.html)
7 、[一种将递归过程转化为非递归过程的方法研究]
8、 [递归算法非递归化的一般规律]
9、 [对于递归有没有什么好的理解方法? - 帅地的回答 - 知乎 ](https://www.zhihu.com/question/31412436/answer/683820765)
10、[什么是递归?先了解什么是递归](https://www.cnblogs.com/Pushy/p/8455862.html)
11、[递归的核心,生活中的递归例子](https://www.cnblogs.com/max-hou/p/8946310.html)
感谢上面的作者提供的知识!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号