结对第二次—文献摘要热词统计及进阶需求
作业格式
- 课程名称:软件工程1916|W(福州大学)
- 作业要求:结对第二次—文献摘要热词统计及进阶需求
- 结对学号:221600235许林瑜 221600236杨吉
- 作业目标:
本次作业分为两部分:
一、基本需求:实现一个能够对文本文件中的单词的词频进行统计的控制台程序。
二、进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器。
Github项目地址
##具体分工 许林瑜:代码的基础功能编写(我一开始没认真看用DEVC++写的。。。和VS环境差的有点多) ,博客码字 杨吉:负责代码优化,在VS2017上分装接口(填我的坑) together:找逻辑错误,做单元测试
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| •EStimate | • 估计这个任务需要多少时间 | 60 | 80 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 60 |
| • Design Spec | • 生成设计文档 | 60 | 40 |
| • Design Review | • 设计复审 | 120 | 110 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 50 |
| • Design | • 具体设计 | 120 | 120 |
| • Coding | • 具体编码 | 120 | 150 |
| • Code Review | • 代码复审 | 60 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 40 | 50 |
| • Size Measurement | • 计算工作量 | 30 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 50 |
| 合计 | 790 | 850 |
##解题思路描述: - 基本需求 :在拿到题目之后最先考虑的就是如何进行数据存储,再者才是去考虑如何去实现逻辑功能。在考虑用Java还是C++中选着了一下 ,最后还是用C++的STL来存储数据结构,相对而言可以自己定义构造和排序,可以使代码的逻辑更为简洁。找资料的第一时间想的就是去CSDN上找是不是有类似的问题,再反复看了很多类似的问题代码后有了初步的构思想法。接着就是在网站上找了关于STL容器的资料,了解容器是怎么存储数据结构的,并且了解了STl容器的基础函数。找到操作可能需要的几个函数先记下来,这样子在后续的过程中,有现成的函数也不用再花大量的时间去完成已经有的功能了(不要造重复的轮子)。 - 进阶需求,首先就是网上了解了现在常用的爬虫软件,然后就选择相对成熟的爬虫软件通过博客,视频等手段去了解如何使用,因为很好功能比较强大的爬虫软件都是外国软件,么得中文版本,所以自己直接下载使用的话还是有一点难度的。 - 当然做作业之前还要认真的阅读《构建之法》的相关内容,以及助教们提供的相关博客链接。
设计实现过程
- 首先思考如何存储数据结构,然后再考虑怎么去实现逻辑功能。
- 最后采用了采用了C++中STL容器来存储结构数组,所以并没有自己定义新的类来存储。所以么得类图(当然可能我不知道怎么画)结构体定义如下:
typedef struct word //定义结构体用于存储单词结构
{
char w[Word_Max]; //单词
int count; //个数
};
单词采用字符数组记录,Word_Max为预定义的单词数最大长度,单词出现频率用整型count存储。
- 接着就是考虑到如何实现词频统计的基础功能和如何将不同的功能分装太不同的函数之中。通过对网络上已有的一些源码的参考,初步来将功能分成几个不同的函数比如添加词频记录,将统计结果写入文件中,I判断是否为合法单词等。参考了网上的一些代码然后根据自己的实际需求完成了基础需求的代码部分。
![]()
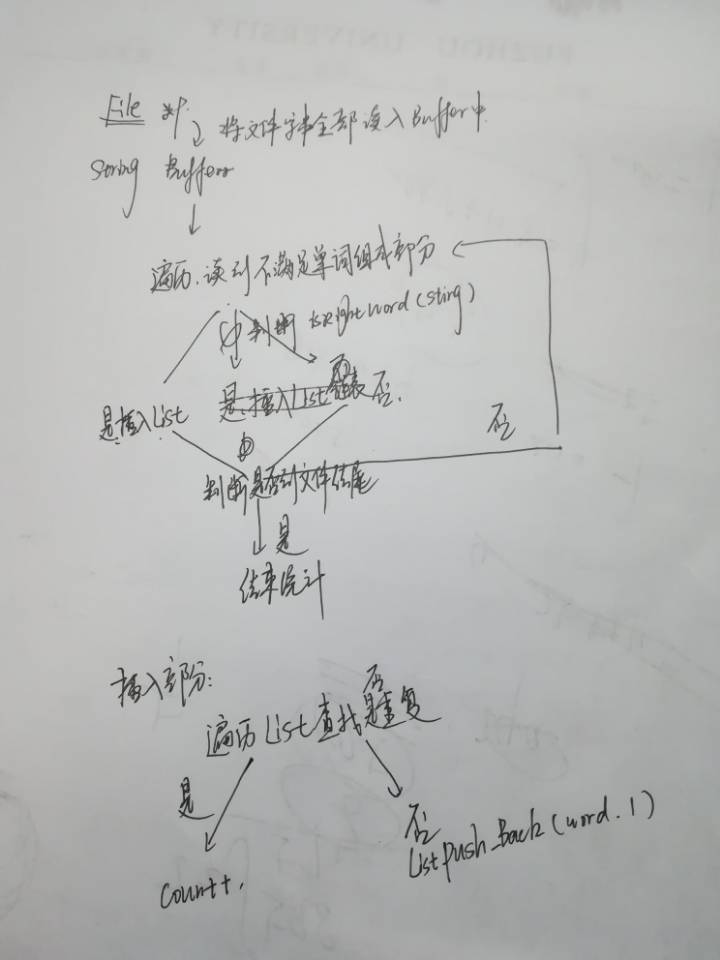
改进思路
性能分析
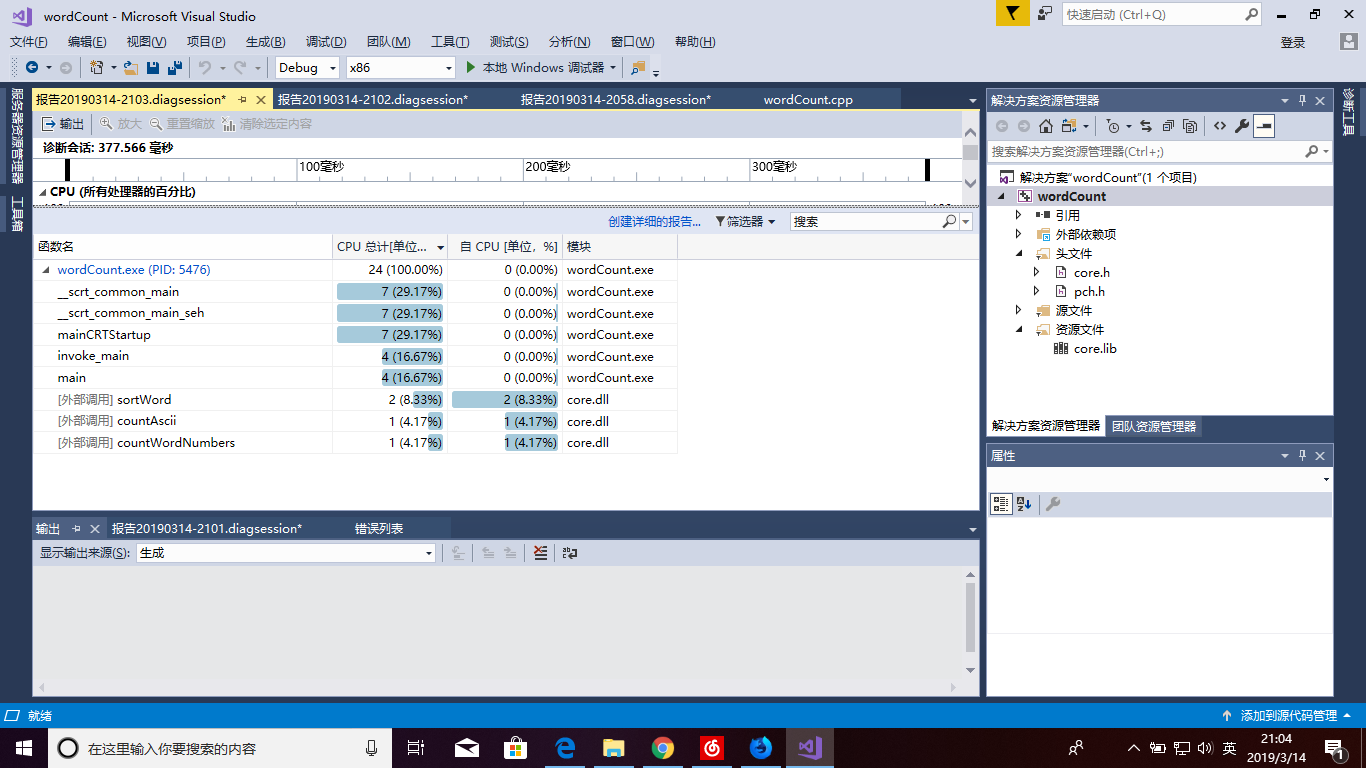
- 通过CPU的占用率看,在外部调用的自己编写的几个函数中sortWord()的CPU占用率最高
可能和用List容器的使用有关,改进思路应该就是更改数据结构,使用更加方便访问和查询的数据结构来存储。这样子就可以减少遍历循环的次数,减少CPU的占用。
还有就是这次由于太迟才开始完成作业,爬虫部分没有来的做,自己测试的数据也未必能够测出性格的优劣,所以自己有空的时候还会把这个当成一个小目标来完成一下。
代码说明
对list链表排序
void sortWord(list<words> &a) {//对单词出现次数排序
a.sort([](words x, words y) { 重写list中的sort()函数
if (x.times != y.times)
return x.times > y.times;
else {
if (x.s[0] > 90 && y.s[0] < 91)
return (x.s[0] - 32) < y.s[0];
else if (x.s[0] < 91 && y.s[0] > 91)
return x.s[0] < (y.s[0] - 32);
else
return x.s[0] < y.s[0];
}
});
}
判断单词是否合法
int isRightWord(string s)//判断是否是符合定义的单词
{
if (s.size() < 4)
return 0; //单词长度不满足return
int i; int x = 0;
for (i = 0; i < 4; i++)
{
if (s[i] <= 'z' && s[i] >= 'a')
x++;
else if (s[i] <= 'Z' && s[i] >= 'A')
x++;
}
if (x != 4 ) //用x统计单词是否以四个字母开头
return 0;
else
return 1;
}
判断字符的ASCII码是否符合
int isLlegal(char a) { //判断字符的ASCII码是否符合
if (a <= 'z' && a >= 'a')
{
return 1;
}
else if (a <= 'Z' && a >= 'A')
{
return 1;
}
else if ('0' <= a && a <= '9') {
return 1;
}
else
return 0;
}
链表中插入单词并计数
void addToList(list<words> &a, string s)
{
int i = 1;
for (auto &x : a) {
if (s == x.s)
{
x.times++;
i = 0;
break;
}
}
if (i == 1) {
a.push_back(words(s, 1));// 遍历一遍,如果没有出现重复单词就在链表尾部插入
}
}
分割单词(设置全局变量,每分割一次就COUNT++)
void IsWord(string s, list<words>&a) //统计单词
{
int i = 0, j = 0;
string word;
for (int k = 0; k < s.size(); k++)
{
if (!isLlegal(s[k])) //如果不满足单词组成则分割单词,判断是否为合法单词是否要插入
{
if (isRightWord(word))
{
addToList(a, word);
}
word = "";
}
else
{
word.push_back(s[k]); 未完成分割单词则把字符读入字符串最尾
}
}
}
统计函数(主要是添加全局变量,在读取文本是每getline()一次就COUNT++)
int countLines(string s) {
ifstream pFile;
string buffer;
pFile.open(s); // 打开文件
int count = 0;
for (string temp; getline(pFile, temp);) //将论文读入字符串
{
if (temp != "")
{
buffer += temp;
count++;
}
}
cout << "lines:" << count << endl;
pFile.close();
return count;
}
单元测试
单元测试用的是Visual Studio 2017上自带的C++单元测试功能
在原有的项目下新建UnitTest1项目,并将引用指向原来的项目
在unittest1.cpp中使用宏"TEST_METHOD"包裹方法将不同的函数分成独立的测试单元
#include "stdafx.h"
#include "CppUnitTest.h"
#include "../core/core.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace UnitTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
std::string textString = "asd31111";
Assert::AreEqual(isRightWord(textString), 0);
}
TEST_METHOD(TestMethod2) {
std::string textText = "a.txt";
Assert::AreEqual(countLines(textText), 3)
}
};
}
使用了Assert中的Assert::AreEqual();来对输入与输出是否相等进行判断。测试了ASCII和单词判断的函数。但是因为还是第一次使用单元测试这种做法所以只是初步的测试了一下,更多的测试还是用比较老土的那种方法。
测试的数据主要就是针对不同的函数进行测试,由局部基础的逻辑函数进行测试,一步步测试到整个项目;
- 测试判断ASCII码的函数就是用不同的输入 比如:A a @ # 空字符等去判断返回值是否正确
- 判断是否是合法的单词事用不同的字符串进行测试 比如:12asjda , ada , hhhh(asdsad) ,asdajsdja2019 ,adadad;等对常见的字符输入进行测试,观测返回值是否正确。
- 判断排序,字符串分割等函数是否正确,主要是去网上找了英文论文作为输入,然后观测输出数据与人为数的数据是否有偏差,比如排序。是否按要求输出,替换文中的单词如win(10)次
adsada(10)次是否会正确排序。还测试了空文件,以及较大的文件。
Github的代码签入记录
遇到的困难及解决办法
-
遇到的困难
- 刚开始鬼使神差的用结构链表来存储词频统计结果,觉得遍历一遍只是简简单单的事情,然后一开始也写的很正常。然后然后就是......不会排序,好吧我承认我指针学的不是很好。然后就要面临怎么排序的问题了。
- 还有就是result的异常啊这些,比如词频统计的数量出错,字符串访问出错,单词漏读等等
- 最困难的就是老师要求的那些自己也没有见过的东西,刚开始用起来真的是很头疼。
-
解决方法
- 去学了一下List容器采用List链表来存储(之前那个坑是我挖的。。)然后队友就负责把原来的储存结构修改了一下,然后重写了List的排序函数就OK了
- 第二个关于result 的问题无非就是函数逻辑上的问题,调试了一下就解决了呀。
- 通过老师给的博客链接,和自己上网找资料,也是在慢慢摸索中学会了很多以前不会的技能和工具吧。
队友评价
- 本次作业开始分工明确,队友负责写需求的初步代码,我开始着手学习dll的封装,然后我对代码进行完善封装测试,队友写博客。在写代码过程中遇到很多问题,比如说链表的排序过程中出了问题,还有字符串数组的大小维护等问题,但都在和队友的商量下,一一解决了。队友在本次作业中,积极主动,才思敏捷,遇到问题时,积极主动查资料,能提出很好的建议,本次合作非常愉快。
#[博客pdf版下载](https://files.cnblogs.com/files/fishkk/%E7%BB%93%E5%AF%B9%E7%AC%AC%E4%B8%80%E6%AC%A1%E2%80%94%E5%8E%9F%E5%9E%8B%E8%AE%BE%E8%AE%A1.zip)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号