

怎样才能看懂 spark 中RDD 间的血缘关系
1. RDD 血缘关系

/*RDD 血缘关系*/ /* * 1. 什么是Rdd的血缘关系? * 1.RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。 * 2.将创建 RDD 的一系列 Lineage (血统)记录下来,以便恢复丢失的分区。 * 3.RDD的 Lineage 会记录RDD的 元数据信息和转换行为 * 当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区 * * 2. 怎样查看 Rdd的血缘关系? * rdd.toDebugString * */
2. RDD 依赖关系
/*RDD 依赖关系*/ /* * 1. 什么是Rdd的依赖关系? * 当前Rdd和父Rdd的依赖关系 * 2. 怎样查看 Rdd的依赖关系? * rdd.dependencies * */
3. RDD 窄依赖&宽依赖
/*RDD 窄依赖&宽依赖*/ /* * 1.什么是窄依赖? * 当前Rdd的1个分区 最多依赖父Rdd的一个分区 * 没有Shuffle过程,例如map、flatmap * * 2.什么是宽依赖? * 当前Rdd的1个分区 依赖父Rdd的多个分区数据 * 有SHuffle过程,例如groupBy * */
4. 示例
//查看 Rdd的血缘关系 object FindLineAge extends App { val sparkconf: SparkConf = new SparkConf().setMaster("local").setAppName("distinctTest") val sc: SparkContext = new SparkContext(sparkconf) private val rdd: RDD[String] = sc.textFile("Spark_319/src/data/*.txt") private val rdd1: RDD[String] = rdd.flatMap(_.split(" ")) private val rdd2: RDD[(String, Iterable[String])] = rdd1.groupBy(e => e) private val rdd3: RDD[(String, Int)] = rdd2.map(tp => (tp._1, tp._2.size)) println("****rdd*********************") println(rdd.toDebugString) println("****rdd1*********************") println(rdd1.toDebugString) println("*****rdd2********************") println(rdd2.toDebugString) println("*****rdd3********************") println(rdd3.toDebugString) rdd3.collect().foreach(println(_)) sc.stop() } //查看 Rdd的依赖关系 object Finddepend extends App { val sparkconf: SparkConf = new SparkConf().setMaster("local").setAppName("distinctTest") val sc: SparkContext = new SparkContext(sparkconf) private val rdd: RDD[String] = sc.textFile("Spark_319/src/data/*.txt") private val rdd1: RDD[String] = rdd.flatMap(_.split(" ")) private val rdd2: RDD[(String, Iterable[String])] = rdd1.groupBy(e => e) private val rdd3: RDD[(String, Int)] = rdd2.map(tp => (tp._1, tp._2.size)) println("****rdd*********************") println(rdd.dependencies) println("****rdd1*********************") println(rdd1.dependencies) println("*****rdd2********************") println(rdd2.dependencies) println("*****rdd3********************") println(rdd3.dependencies) rdd3.collect().foreach(println(_)) sc.stop() }
****rdd********************* (2) Spark_319/src/data/*.txt MapPartitionsRDD[1] at textFile at 血缘关系.scala:54 [] | Spark_319/src/data/*.txt HadoopRDD[0] at textFile at 血缘关系.scala:54 [] ****rdd1********************* (2) MapPartitionsRDD[2] at flatMap at 血缘关系.scala:57 [] | Spark_319/src/data/*.txt MapPartitionsRDD[1] at textFile at 血缘关系.scala:54 [] | Spark_319/src/data/*.txt HadoopRDD[0] at textFile at 血缘关系.scala:54 [] *****rdd2******************** (2) ShuffledRDD[4] at groupBy at 血缘关系.scala:60 [] +-(2) MapPartitionsRDD[3] at groupBy at 血缘关系.scala:60 [] | MapPartitionsRDD[2] at flatMap at 血缘关系.scala:57 [] | Spark_319/src/data/*.txt MapPartitionsRDD[1] at textFile at 血缘关系.scala:54 [] | Spark_319/src/data/*.txt HadoopRDD[0] at textFile at 血缘关系.scala:54 [] *****rdd3******************** (2) MapPartitionsRDD[5] at map at 血缘关系.scala:62 [] | ShuffledRDD[4] at groupBy at 血缘关系.scala:60 [] +-(2) MapPartitionsRDD[3] at groupBy at 血缘关系.scala:60 [] | MapPartitionsRDD[2] at flatMap at 血缘关系.scala:57 [] | Spark_319/src/data/*.txt MapPartitionsRDD[1] at textFile at 血缘关系.scala:54 [] | Spark_319/src/data/*.txt HadoopRDD[0] at textFile at 血缘关系.scala:54 [] ****rdd********************* List(org.apache.spark.OneToOneDependency@512575e9) ****rdd1********************* List(org.apache.spark.OneToOneDependency@617389a) *****rdd2******************** List(org.apache.spark.ShuffleDependency@348ad293) *****rdd3******************** List(org.apache.spark.OneToOneDependency@30f74e79)
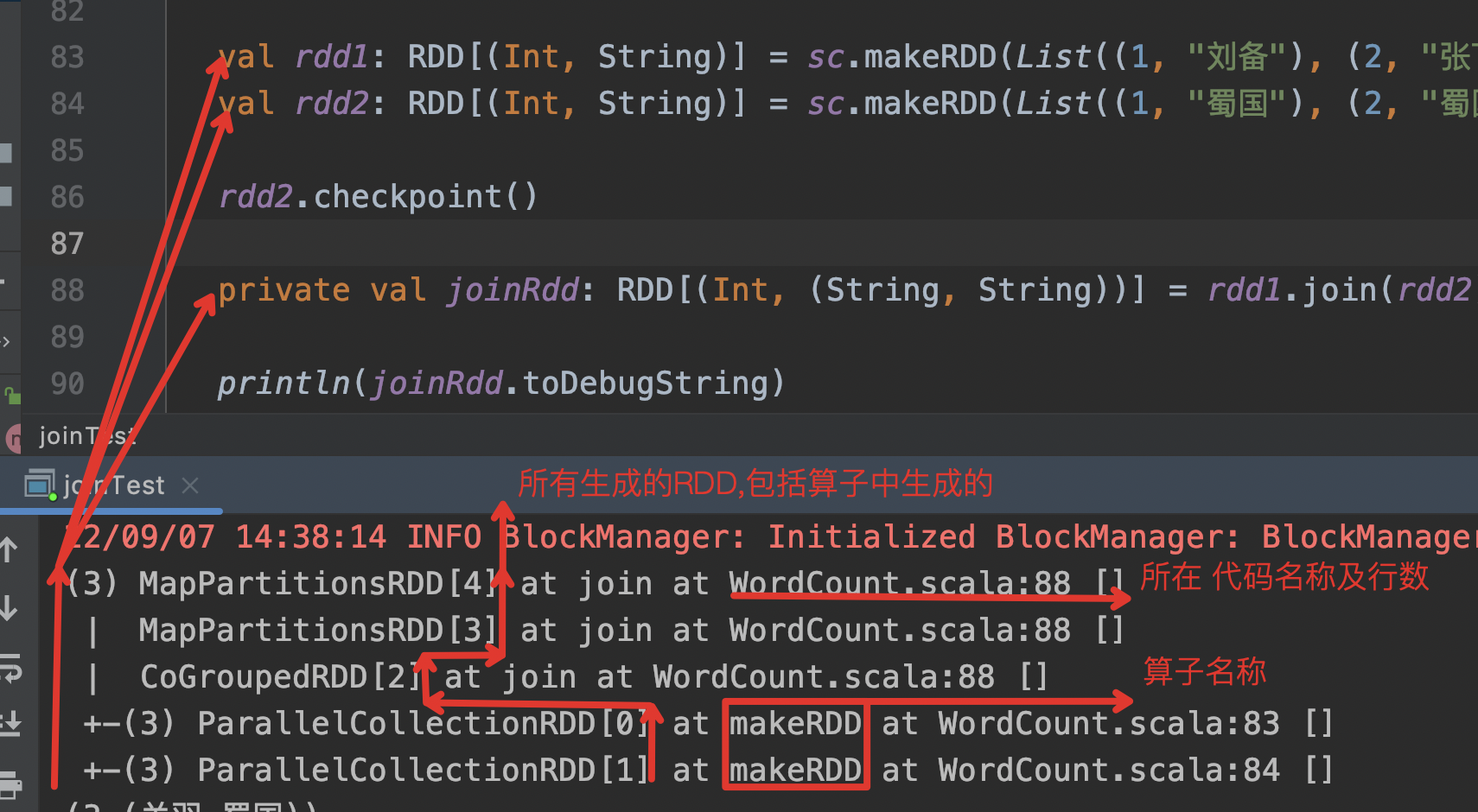
5. 能从 血缘关系中获取那些信息?
1.查询RDD 之前有多少个RDD 2.源代码 中 有多少个 RDD对象 3.RDD 的算子 4.所在RDD 在源代码中行数及脚本名称
分类:
SparkCore


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界