

03_MapReduce框架原理_3.8 排序 WritableComparable
1. 说明

2. 排序时机 与 排序算法

流程图
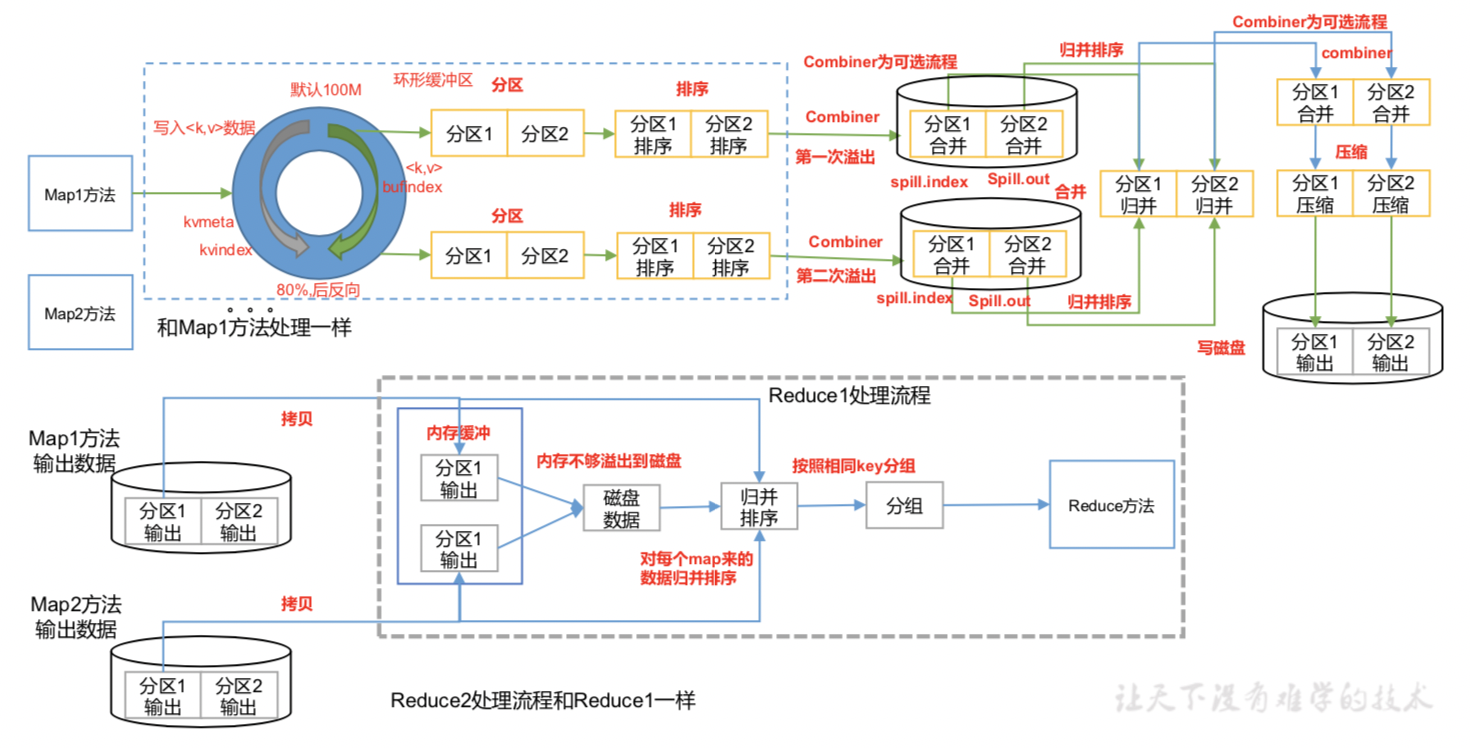
3. 排序分类

4. 实现
1. 说明
自定义类 为key 时,必须 实现 WritableComparable接口,否则无法排序
2. 实现
自定义类 实现 WritableComparable接口, 重写 compareTo 方法
5. 代码案例
1. 全排序



package GroupByPersonOrderbyAgePk { import java.io.{DataInput, DataOutput} import java.lang import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.Path import org.apache.hadoop.io._ import org.apache.hadoop.mapreduce.lib.input.FileInputFormat import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat import org.apache.hadoop.mapreduce.{Job, Mapper, Reducer} /* * 需求 * 根据 person计数,并按 age 排序 * * 输入 * 曹操 20 10 * 曹操 20 10 * 曹操 20 10 * 曹仁 29 9 * 曹仁 29 9 * 曹冲 8 2 * 曹冲 8 2 * 曹冲 8 2 * 曹冲 8 2 * * 输出 * 曹冲 # 8 # 2 4 * 曹操 # 20 # 10 3 * 曹仁 # 29 # 9 2 * * */ // Mapper 类 class PersonCountMapper extends Mapper[LongWritable, Text, Person, IntWritable] { var v = new IntWritable(1) override def map(key: LongWritable, value: Text, context: Mapper[LongWritable, Text, Person, IntWritable]#Context) = { //1. 切割数据 var line: Array[String] = value.toString.split(" +") var name: String = line(0) var age: String = line(1) var income: String = line(2) //2. 创建Person对象 var person = new Person(name, age.toInt, income.toInt) println(person) //3. 写入到环形缓冲区 context.write(person, v) } } // Reducer 类 class PersonCountReducer extends Reducer[Person, IntWritable, Person, IntWritable] { var v = new IntWritable() override def reduce(key: Person, values: lang.Iterable[IntWritable], context: Reducer[Person, IntWritable, Person, IntWritable]#Context) = { var sum = 0 //1. 对每个person 计数 values.forEach(sum += _.get) v.set(sum) //2. 写出数据 context.write(key, v) } } // Driver object PersonCountDriver { def main(args: Array[String]): Unit = { //1. 获取配置信息以及 获取job对象 var configuration = new Configuration var job: Job = Job.getInstance(configuration) //2. 注册本Driver程序的jar job.setJarByClass(this.getClass) job.setJobName("PersonCount mr") //3. 注册 Mapper 和 Reducer的jar job.setMapperClass(classOf[PersonCountMapper]) job.setReducerClass(classOf[PersonCountReducer]) //4. 设置Mapper 类输出key-value 数据类型 job.setMapOutputKeyClass(classOf[Person]) job.setMapOutputValueClass(classOf[IntWritable]) //5. 设置最终输出key-value 数据类型 job.setOutputKeyClass(classOf[Person]) job.setOutputValueClass(classOf[IntWritable]) //6. 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path("src/main/data/input/1.txt")) FileOutputFormat.setOutputPath(job, new Path("src/main/data/output")) //7. 提交job val bool: Boolean = job.waitForCompletion(true) System.exit(bool match { case true => "0".toInt case false => "1".toInt }) } } // public interface WritableComparable<T> extends Writable, Comparable<T> class Person() extends WritableComparable[Person] { var name: String = _ var age: Int = _ var income: Int = _ // 空参构造 def this(name: String, age: Int, income: Int) = { this() // 调用主构造器 this.name = name this.age = age this.income = income } // 序列化方法 override def write(out: DataOutput): Unit = { out.writeUTF(name) out.writeInt(age) out.writeInt(income) } // 反序列化方法 override def readFields(in: DataInput): Unit = { name = in.readUTF age = in.readInt income = in.readInt } override def toString: String = { s"${name} # ${age} # ${income}" } override def compareTo(o: Person): Int = { this.age - o.age } } }
2. 分区+排序+多字段排序
package PartitionByNameGroupByPersonOrderbyAgeIncomePk { import java.io.{DataInput, DataOutput} import java.lang import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.Path import org.apache.hadoop.io.{IntWritable, _} import org.apache.hadoop.mapreduce.lib.input.FileInputFormat import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat import org.apache.hadoop.mapreduce.{Job, Mapper, Partitioner, Reducer} /* * 需求 * 根据 Name 分区, 分区内 对person计数,并按 age、income 排序 * * 输入 * 曹操 20 10 曹操 20 10 曹操 20 10 曹操 20 10 曹操 20 10 曹操 20 10 曹操 20 10 曹仁 29 9 曹仁 29 9 曹冲 8 2 曹冲 8 2 曹冲 8 2 曹冲 8 2 曹植 8 5 曹植 8 5 刘备 30 100 关羽 25 80 张飞 10 2 孙权 20 100 周瑜 45 99 曹洪 29 88 曹洪 29 88 曹洪 29 88 * * 输出 Person(曹冲, 8, 2) 4 Person(曹植, 8, 5) 2 Person(曹操, 20, 10) 7 Person(曹仁, 29, 9) 2 Person(曹洪, 29, 88) 3 Person(张飞, 10, 2) 1 Person(关羽, 25, 80) 1 Person(刘备, 30, 100) 1 Person(孙权, 20, 100) 1 Person(周瑜, 45, 99) 1 * * * * * * * * */ // Mapper 类 class PersonCountMapper extends Mapper[LongWritable, Text, Hero, IntWritable] { var v = new IntWritable(1) var hero = new Hero() override def map(key: LongWritable, value: Text, context: Mapper[LongWritable, Text, Hero, IntWritable]#Context) = { //1. 切割数据 var line: Array[String] = value.toString.split(" ") var name: String = line(0) var age: String = line(1) var income: String = line(2) //2. 创建Person对象 hero.name = name hero.age = age.toInt hero.income = income.toInt //println(person) //3. 写入到环形缓冲区 context.write(hero, v) } } // Reducer 类 class PersonCountReducer extends Reducer[Hero, IntWritable, Hero, IntWritable] { var v = new IntWritable() override def reduce(key: Hero, values: lang.Iterable[IntWritable], context: Reducer[Hero, IntWritable, Hero, IntWritable]#Context) = { println(s"${key} ## ${values.toString}") var sum = 0 //1. 对每个person 计数 values.forEach(sum += _.get) v.set(sum) //2. 写出数据 context.write(key, v) } } // Driver object HeroCountDriver { def main(args: Array[String]): Unit = { //1. 获取配置信息以及 获取job对象 var configuration = new Configuration var job: Job = Job.getInstance(configuration) //2. 注册本Driver程序的jar job.setJarByClass(this.getClass) job.setJobName("PersonCount mr") //3. 注册 Mapper 和 Reducer的jar job.setMapperClass(classOf[PersonCountMapper]) job.setReducerClass(classOf[PersonCountReducer]) //4. 设置Mapper 类输出key-value 数据类型 job.setMapOutputKeyClass(classOf[Hero]) job.setMapOutputValueClass(classOf[IntWritable]) //5. 设置最终输出key-value 数据类型 job.setOutputKeyClass(classOf[Hero]) job.setOutputValueClass(classOf[IntWritable]) //6. 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path("src/main/data/input/1.txt")) FileOutputFormat.setOutputPath(job, new Path("src/main/data/output")) //7. 指定分区个数 与分区器 job.setNumReduceTasks(3) job.setPartitionerClass(classOf[GcPartitioner]) //7. 提交job val bool: Boolean = job.waitForCompletion(true) System.exit(bool match { case true => "0".toInt case false => "1".toInt }) } } //key = Mapoutkey value=Mapoutvalue 根据map输出的key-value 分区 class GcPartitioner extends Partitioner[Hero, IntWritable] { override def getPartition(key: Hero, value: IntWritable, numPartitions: Int): Int = { var one: List[String] = List("曹操", "曹仁", "曹冲", "曹植", "曹洪") var two: List[String] = List("张飞", "刘备", "关羽") var three: List[String] = List("孙权", "张昭", "周瑜") //println(s"${key} ###${one.contains(key.name)}") key.name match { case e: String if one.contains(e) => 0 //case _ => 1 case e1: String if two.contains(e1) => 1 case e2: String if three.contains(e2) => 2 } } } // public interface WritableComparable<T> extends Writable, Comparable<T> class Hero() extends WritableComparable[Hero] { var name: String = _ var age: Int = _ var income: Int = _ // 空参构造 def this(name: String, age: Int, income: Int) = { this() // 调用主构造器 this.name = name this.age = age this.income = income } // 序列化方法 override def write(out: DataOutput): Unit = { out.writeUTF(name) out.writeInt(age) out.writeInt(income) } // 反序列化方法 override def readFields(in: DataInput): Unit = { name = in.readUTF age = in.readInt income = in.readInt } // 对象比较方法 override def compareTo(o: Hero): Int = { if (this.name == o.name && this.age == o.age && this.income == o.income) { 0 } else if (this.age >= o.age && this.income >= o.income){ 1 }else { -1 } } override def toString = s"Person($name, $age, $income)" } }
6. 注意事项(自定义类 继承类检查)
1. 说明
自定义类 作为key 必须实现 WritableComparable的 compareTo 方法
map创建环形缓冲区时 会对key 类型做判断 是否继承了 WritableComparable接口
2. 自定义类 不继承WritableComparable 报错
Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer
3. 源码逻辑
/******************检测MapOutputKeyClass 是否是WritableComparable的子类**************************/ // 对key排序 是Hadoop的默认行为 // 因此 map输出前,会检查 输出key类型 是否继承 WritableComparable // 报错 Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer // Caused by: java.io.IOException: Initialization of all the collectors failed. // Error in last collector was:java.lang.ClassCastException: class GroupByPoneNumPk.Person JobConf类 // 获取map输出key的比较器 public RawComparator getOutputKeyComparator() { Class<? extends RawComparator> theClass = getClass( JobContext.KEY_COMPARATOR, null, RawComparator.class); if (theClass != null) return ReflectionUtils.newInstance(theClass, this); // 检查 job.setMapOutputKeyClass(classOf[Person]) 指定的类 是否是 WritableComparable的子类 return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this); }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界