

03_MapReduce框架原理_3.6 Shuffle机制(源码)
点击查看 Shuffle 流程图
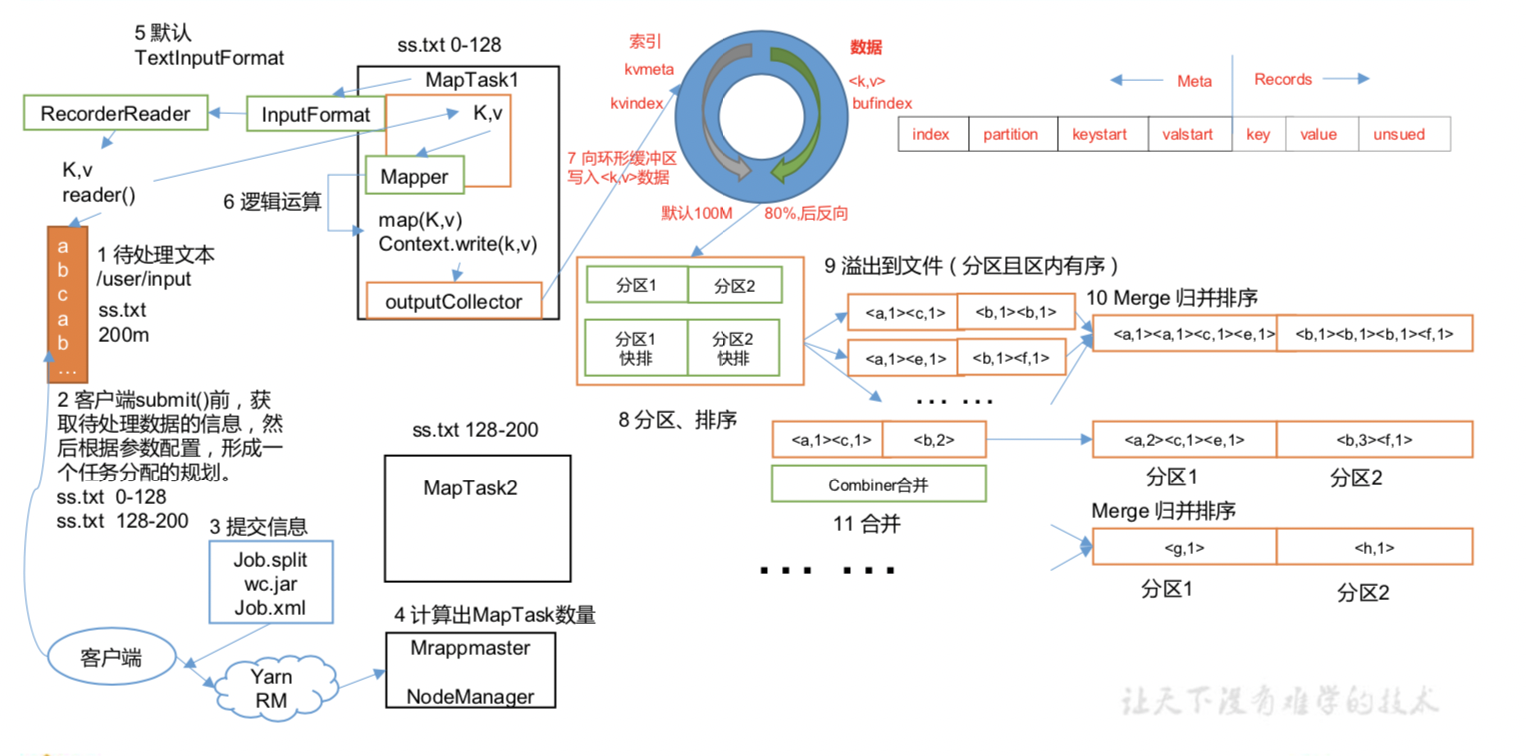
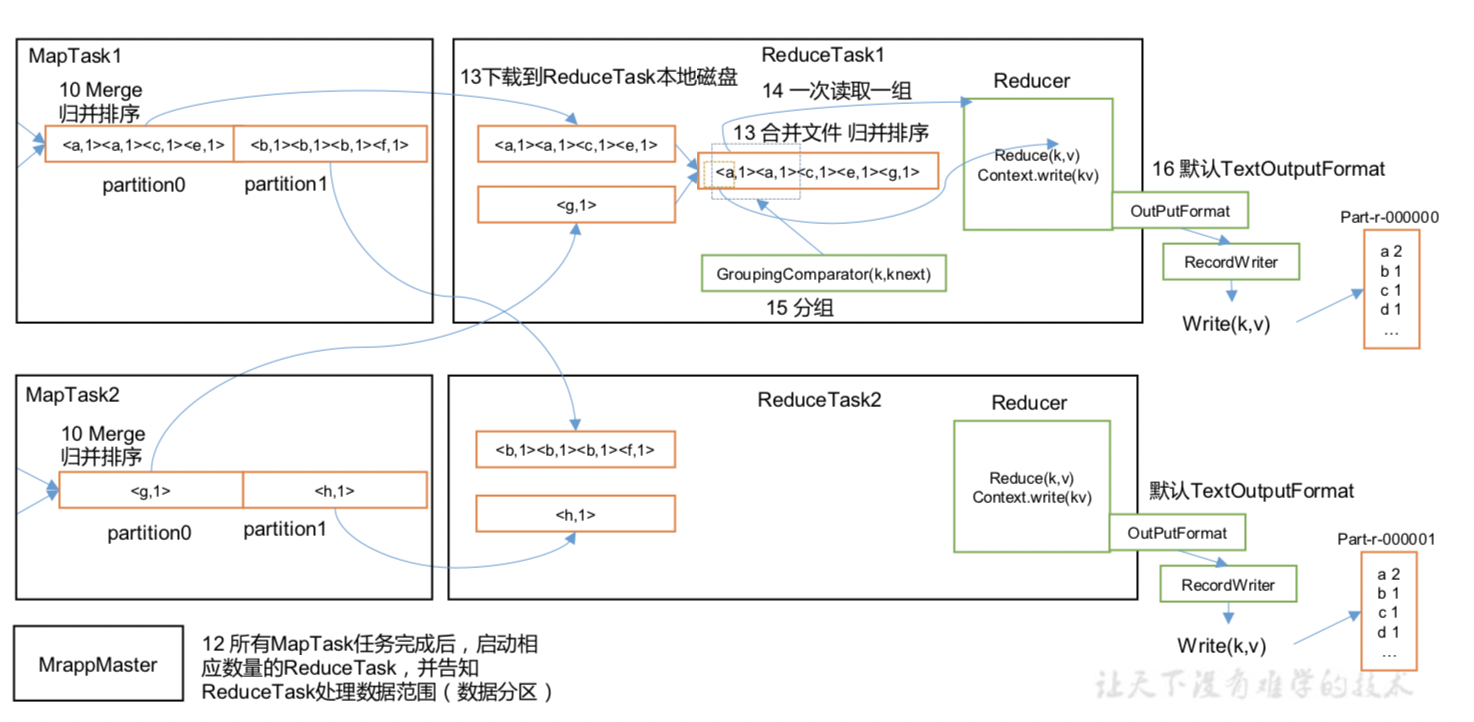
点击查看 Shuffle 机制 说明
点击查看 Shuffle 源码
Shuffle 机制过程
// 发生时间 : map方法之后,reduce方法之前 (为了解决 MapTask输出如何高效输出到ReduceTask)
/***********************MapTask****************************************************************************************/
//1. map方法处理一行数据,经处理结果 输出到 内存缓冲区(key,value)
context.write(key, value)
//2. 写入到 环形缓冲区
// 1. MapTask 类 write 方法
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
// 根据key,value计算当前key 所属的分区编号
partitioner.getPartition(key, value, partitions));
}
//思考: 往 环形缓冲区中写入了内容呢
// 1. 元数据信息 partition、keystart(标记key在内存中的开始位置)、valstart(标记value在内存中的开始位置)、VALLEN(结束位置)
// 2. 数据信息 key, value, partition
// 功能 : 将 key,value 序列化到 内存缓冲区中
public synchronized void collect(K key, V value, final int partition) throws IOException {
// bufferRemaining 为缓冲区大小 默认为 100m
// 通过 mapreduce.task.io.sort.mb 设置缓冲区大小
// METASIZE 为存储元数据
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// write accounting info
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}
//3. 溢写过程
//1. 当 bufferRemaining(缓冲区容量) 使用大于大于80%后,会将内存中 数据写入到 本地磁盘的临时文件中(溢写文件)
// 溢写前 会将 数据分区、且分区内排序(快排)
// group by partition(分区编号) order by key
//4. Merge 溢写文件 (生成一个输出文件 group by partition 且 分区内有序),等待reduceTask 的拉取
//1. 将步骤3 中生成的多个溢写文件 Merge成一个文件 且数据分区、且分区内排序(归并排序)
// group by partition(分区编号) order by key
//2. Combiner合并 (被动触发,必须指定合并器才能执行) job.setCombinerClass(WordCountCombiner.class)
// 聚合规则(value) group by key
/***********************ReduceTask****************************************************************************************/
//1. 拉取 MapTask结果数据(按分区拉取),并对数据归并排序
// 1. 每个reduceTask 只处理一个分区的数据
// 2. 拉取策略(动态归并)
// 示例 10个MapTask ,会将先完成的MapTask的数据拉取合并,再与后完成的MapTask合并
//2. 生成 同一分区且有序的数据,供ReduceTask 处理


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界