

03_MapReduce框架原理_3.5 InputFormat 数据输入类(源码)
点击查看 InputFormat
// 功能
// 1. 将job输入 划分成切片 (输入源不同,生成的切片对象不同)
// 2. 根据 getSplits生成 相对应 读取切片对象的 记录读取器
public abstract class InputFormat<K, V> {
// 将 Job 输入的文件集 切分成 切片对象 的集合
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
// 创建 与切片对象 相对于的 记录读取器
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
点击查看 FileInputFormat
// 功能
// job输入 是文件类型
// 切片规则 : 判断输入文件中是否可切片
// 可切分 : 对每个文件进行切分
// 不可切片 : 将整个文件作为切片
public abstract class FileInputFormat<K, V> extends InputFormat<K, V> {
public static final String INPUT_DIR =
"mapreduce.input.fileinputformat.inputdir";
public static final String SPLIT_MAXSIZE =
"mapreduce.input.fileinputformat.split.maxsize";
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
public static final String PATHFILTER_CLASS =
"mapreduce.input.pathFilter.class";
public static final String NUM_INPUT_FILES =
"mapreduce.input.fileinputformat.numinputfiles";
public static final String INPUT_DIR_RECURSIVE =
"mapreduce.input.fileinputformat.input.dir.recursive";
public static final String INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS =
"mapreduce.input.fileinputformat.input.dir.nonrecursive.ignore.subdirs";
public static final String LIST_STATUS_NUM_THREADS =
"mapreduce.input.fileinputformat.list-status.num-threads";
public static final int DEFAULT_LIST_STATUS_NUM_THREADS = 1;
// 判断指定文件 是否可 切片
protected boolean isSplitable(JobContext context, Path filename) {
return true;
}
// 设置切片最小值
public static void setMinInputSplitSize(Job job,
long size) {
job.getConfiguration().setLong(SPLIT_MINSIZE, size);
}
// 获取切片最小值
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
// 设置切片最大值
public static void setMaxInputSplitSize(Job job,
long size) {
job.getConfiguration().setLong(SPLIT_MAXSIZE, size);
}
// 获取切片最大值
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE);
}
// FileSplit的工程类, 用来创建切片对象
protected FileSplit makeSplit(Path file, long start, long length,
String[] hosts) {
return new FileSplit(file, start, length, hosts);
}
// FileSplit的工程类, 用来创建切片对象
protected FileSplit makeSplit(Path file, long start, long length,
String[] hosts, String[] inMemoryHosts) {
return new FileSplit(file, start, length, hosts, inMemoryHosts);
}
// 将job输入生成一个文件列表
// 并将文件切分成 InputSplit对象,并将 切片对象 存储到list中
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
// 1. 计算 切片最小值
// 有 mapreduce.input.fileinputformat.split.minsize 取设置值,没有取 1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//getFormatMinSplitSize() return 1;
//getMinSplitSize(job) return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
//SPLIT_MINSIZE = mapreduce.input.fileinputformat.split.minsize
// 2. 计算 切片最大值
// 有 mapreduce.input.fileinputformat.split.maxsize 取设置值,没有取 Long.MAX_VALUE
long maxSize = getMaxSplitSize(job);
// getMaxSplitSize return context.getConfiguration().getLong(SPLIT_MAXSIZE, Long.MAX_VALUE);
// SPLIT_MAXSIZE = mapreduce.input.fileinputformat.split.maxsize
// generate splits
// 3. 创建 List<InputSplit>,用来存储 切片结果
List<InputSplit> splits = new ArrayList<InputSplit>();
// 4. List<FileStatus> ,存储 遍历后的文件
List<FileStatus> files = listStatus(job);
// 判断是否是目录
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
// 5. 遍历文件列表,对每个文件进行切片
for (FileStatus file: files) {
// 过滤文件夹
if (ignoreDirs && file.isDirectory()) {
continue;
}
// 1. 获取文件路径
Path path = file.getPath();
// 2. 获取文件长度
long length = file.getLen();
// 文件长度 不为0
if (length != 0) {
// 3. 获取文件 block信息
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 4. 判断文件 是否可以 切片
if (isSplitable(job, path)) {
// 文件支持 切片
// 5. 获取文件块的大小,本地运行环境 32M
long blockSize = file.getBlockSize();
// 6. 获取切片大小
// computeSplitSize = return Math.max(minSize, Math.min(maxSize, blockSize));
// 不设置 mapreduce.input.fileinputformat.split.minsize 、mapreduce.input.fileinputformat.split.maxsize时
// minsize = 1 、maxsize = Long.MAX_VALUE computeSplitSize = blockSize
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 7. 临时变量 存储 文件长度
long bytesRemaining = length;
// 8. 对文件 循环切片
// 切片规则
// 剩余文件长度 是否大于 1.1*切片长度
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//9. 获取切片 起始位置
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//10. 初始化切片对象,添加到 List<InputSplit>
// path : 文件路径
// length-bytesRemaining : 切片在文件中 起始位置
// splitSize : 切片大小
// blkLocations[blkIndex].getHosts() : 文件所属block
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
// 临时变量 - 切片长度
bytesRemaining -= splitSize;
}
//11. 当文件剩余长度 小于切片长度*1.1 时,将文件剩余部分 作为一个切片
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
// 不可切片,将整个文件 作为一个切片进行存储
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
// 当前文件整体 作为一个切片进行存储
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
// 文件长度 为0
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
// 6. 返回 存储切片对象的 集合
return splits;
}
// 计算切片大小
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
// 获取 Bolck大小
protected int getBlockIndex(BlockLocation[] blkLocations,
long offset) {
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block?
if ((blkLocations[i].getOffset() <= offset) &&
(offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){
return i;
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset +
" is outside of file (0.." +
fileLength + ")");
}
// 将给定的路径(多个路径用 ,分割),作为job的输入,并绑定到job上
public static void setInputPaths(Job job,
String commaSeparatedPaths
) throws IOException {
setInputPaths(job, StringUtils.stringToPath(
getPathStrings(commaSeparatedPaths)));
// 将给定的路径(多个路径用 ,分割),作为job的输入,并绑定到job上
public static void setInputPaths(Job job,
Path... inputPaths) throws IOException {
Configuration conf = job.getConfiguration();
Path path = inputPaths[0].getFileSystem(conf).makeQualified(inputPaths[0]);
StringBuffer str = new StringBuffer(StringUtils.escapeString(path.toString()));
for(int i = 1; i < inputPaths.length;i++) {
str.append(StringUtils.COMMA_STR);
path = inputPaths[i].getFileSystem(conf).makeQualified(inputPaths[i]);
str.append(StringUtils.escapeString(path.toString()));
}
conf.set(INPUT_DIR, str.toString());
}
}
点击查看 TextInputFormat
// 用于读取纯文本文件
// 按行读取 (换行和回车都表示 行的结束)
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
// 创建 记录读取器
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes); // 返回行 记录读取器
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
}
点击查看 合并小文件案例(CombineTextInputFormat)
import java.lang
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.{IntWritable, LongWritable, Text}
import org.apache.hadoop.mapreduce.lib.input.{CombineTextInputFormat, FileInputFormat}
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
import org.apache.hadoop.mapreduce.{Job, Mapper, Reducer}
// Mapper 类
// 每个Mapper类实例 处理一个切片文件
class WCMapper extends Mapper[LongWritable, Text, Text, IntWritable] {
var text = new Text
var intWritable = new IntWritable(1)
// 每行记录调用一次map方法
override def map(key: LongWritable, value: Text, context: Mapper[LongWritable, Text, Text, IntWritable]#Context) = {
println("map enter .....")
//1. 获取一行记录
val line = value.toString
//2. 切割
val words = line.split(" ")
//3. 输出到缓冲区
words.foreach(
key1 => {
text.set(key1);
context.write(text, intWritable)
}
)
}
}
// Reducer 类
// 所有Mapper实例 执行完毕后 Reducer才会执行
// Mapper类的输出类型 = Reducer类的输入类型
class WCReducer extends Reducer[Text, IntWritable, Text, IntWritable] {
var sum: Int = 0
private val intWritable = new IntWritable
// 每个key调用一次
// 张飞 <1,1,1,1,1>
override def reduce(key: Text, values: lang.Iterable[IntWritable], context: Reducer[Text, IntWritable, Text, IntWritable]#Context) = {
println("reduce enter .....")
// 1. 对词频数 求sum
values.forEach(sum += _.get)
// 2. 输出结果
intWritable.set(sum)
context.write(key, intWritable)
}
}
// Driver
object Driver {
def main(args: Array[String]): Unit = {
//1. 获取配置信息以及 获取job对象
//读取配置文件 Configuration: core-default.xml, core-site.xml
var configuration = new Configuration
var job: Job = Job.getInstance(configuration)
//2. 注册本Driver程序的jar
job.setJarByClass(this.getClass)
job.setJobName("scala mr")
//3. 注册 Mapper 和 Reducer的jar
job.setMapperClass(classOf[WCMapper])
job.setReducerClass(classOf[WCReducer])
//4. 设置Mapper 类输出key-value 数据类型
job.setMapOutputKeyClass(classOf[Text])
job.setMapOutputValueClass(classOf[IntWritable])
//5. 设置最终输出key-value 数据类型
job.setOutputKeyClass(classOf[Text])
job.setOutputValueClass(classOf[IntWritable])
// 为当前job 设置InputFormat 的实现类
/* 合并小文件,指定使用CombineTextInputFormat,不指定时 默认为TextInputFormat*/
job.setInputFormatClass(classOf[CombineTextInputFormat])
// 优先满足最小切片大小,不超过最大切片大小
FileInputFormat.setMaxInputSplitSize(job,1024*3) //3K
FileInputFormat.setMinInputSplitSize(job,1024) //1K
//6. 设置输入输出路径
FileInputFormat.setInputPaths(job, "src/main/data/input/demo.html")
FileOutputFormat.setOutputPath(job, new Path("src/main/data/output"))
//7. 提交job
val bool: Boolean = job.waitForCompletion(true)
System.exit(bool match {
case true => "0".toInt
case false => "1".toInt
})
}
}
点击查看 CombineTextInputFormat 切片机制
待补充
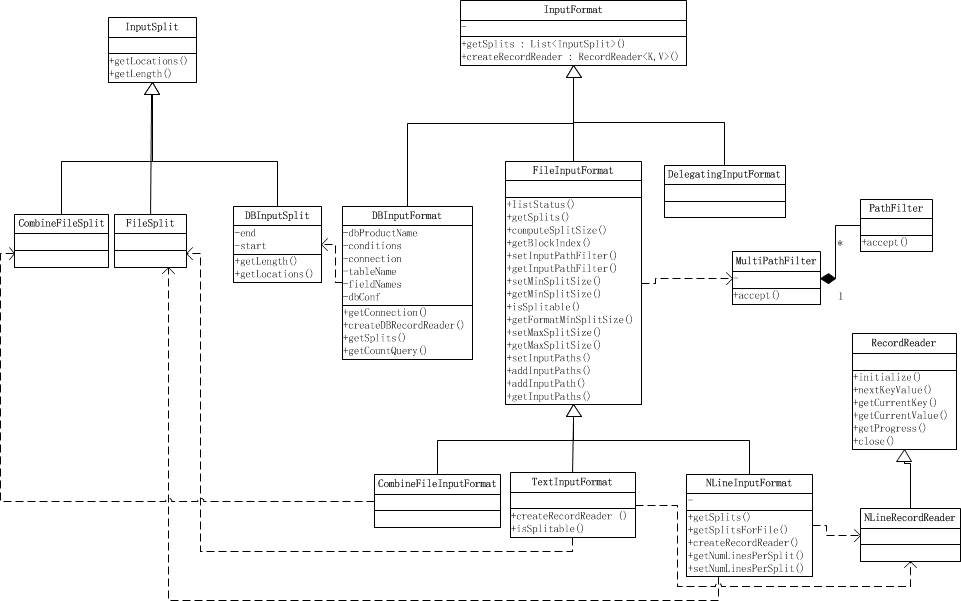
点击查看 InputFormat 继承关系图
分类:
Mapreduce


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界