

02_手把手教你 在IDEA搭建Spark项目开发环境(Mac)
在Mac环境搭建Spark项目
1. scala项目搭建 https://www.cnblogs.com/bajiaotai/p/15381309.html
2. 添加pom依赖
<!--指定当前 scala版本信息-->
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
注意事项 : spark构建版本和scala版本必须一致
3. 创建WordCount案例
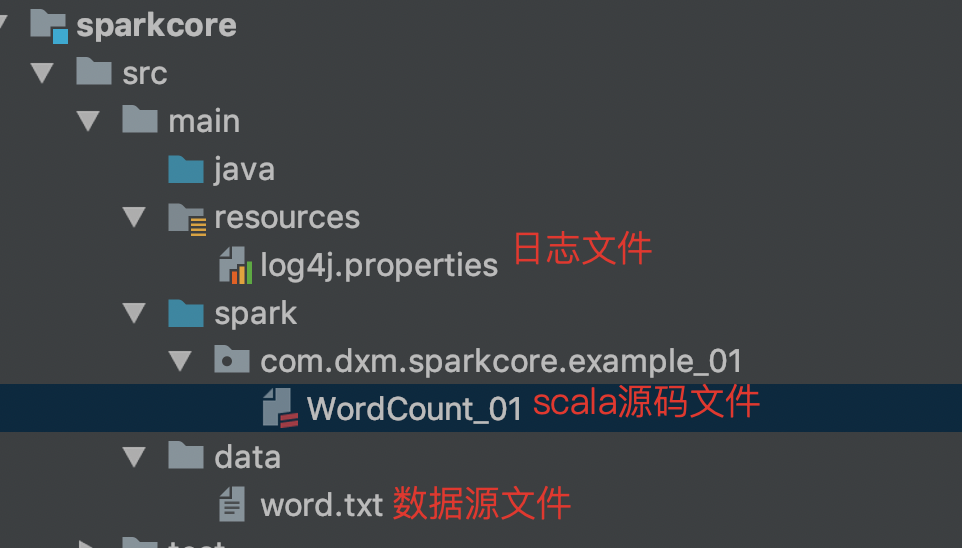
4. 在resources目录添加日志文件 ( log4j.properties )

log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
5. 代码案例
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* * WordCount案例 * 步骤 * 1 添加依赖 (指定当前环境scala版本) * 示例 <groupId>org.apache.spark</groupId> * 2 * 3 * FAQ * Exception in thread "main" java.lang.NoSuchMethodError: scala.util.matching.Regex.<init>(Ljava/lang/String;Lscala/collection/Seq;) * 环境scala版本和spark编译所有scala版本不一致 * 版本适配查询 * http://spark.apache.org/downloads.html * */ object WordCountOne { def main(args: Array[String]): Unit = { // 创建spark运行的配置信息 // setMaster 设置运行集群(local为本地) // setAppName 设置job的name val sparkconf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCountDemo") // 创建和Spark框架的链接 val sc: SparkContext = new SparkContext(sparkconf) println("========原始数据===============") // 读取指定文件数据 val txtFile: RDD[String] = sc.textFile("sparkcore/src/main/data/word.txt") txtFile.foreach(println) println("======切割+扁平化处理==================") // 切割单词,扁平化处理 val words: RDD[String] = txtFile.flatMap( _.split(" ") ) words.foreach(println) println("=======分组===========================") // 分组 val wordGrp: RDD[(String, Iterable[String])] = words.groupBy(word => word) wordGrp.foreach(println) println("=======统计===========================") def sum(pt: (String, Iterable[String])) = { (pt._1, pt._2.size) } //计数 val result: RDD[(String, Int)] = wordGrp.map(sum) result.foreach(println) println("=======根据计数排序===========================") val sort = result.sortBy(pt => pt._2) sort.foreach(println) // 关闭连接 sc.stop() } } // mapreduce 格式 object WordCountTwo { def main(args: Array[String]): Unit = { // 创建spark运行的配置信息 // setMaster 设置运行集群(local为本地) // setAppName 设置job的name val sparkconf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCountDemo") // 创建和Spark框架的链接 val sc: SparkContext = new SparkContext(sparkconf) println("========FileInput读取切片数据===============") // 读取指定文件数据 val txtFile: RDD[String] = sc.textFile("sparkcore/src/main/data/word.txt") txtFile.foreach(println) println("======Mapper类处理切片数据,每行调用一次map方法==================") println("======map方法输出(key,value),到环形缓冲区,按照key排序==================") // 切割单词,扁平化处理 val words: RDD[(String, Int)] = txtFile.flatMap( _.split(" ") ).map((_, 1)).sortBy(_._1) words.foreach(println) println("=====Reducer类拉取map结果文件") println("=====按照相同的key计数") def sum(tp: (String, Iterable[(String, Int)])) = { var cnt = 0 for (e <- tp._2) { cnt += e._2 } (tp._1, cnt) } val wordsGrp: RDD[(String, Int)] = words.groupBy(_._1).map(sum).sortBy(_._2) wordsGrp.foreach(println) // 关闭连接 sc.stop() } } // 使用spark实现的reduceBykey方法 object WordCountThree { def main(args: Array[String]): Unit = { // 创建spark运行的配置信息 // setMaster 设置运行集群(local为本地) // setAppName 设置job的name val sparkconf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCountDemo") // 创建和Spark框架的链接 val sc: SparkContext = new SparkContext(sparkconf) println("========FileInput读取切片数据===============") // 读取指定文件数据 val txtFile: RDD[String] = sc.textFile("sparkcore/src/main/data/word.txt") txtFile.foreach(println) println("======Mapper类处理切片数据,每行调用一次map方法==================") println("======map方法输出(key,value),到环形缓冲区,按照key排序==================") // 切割单词,扁平化处理 val words: RDD[(String, Int)] = txtFile.flatMap( _.split(" ") ).map((_, 1)).sortBy(_._1) words.foreach(println) //reduceByKey /* * reduceByKey 方法 * 说明 * 将集合中按照相同的key,对value聚合,将多个key相同的元素 聚合成一个 * 参数 * 前后两个value聚合的规则(匿名函数/函数指针) * * */ println("========使用reduceByKey方法==========") val result: RDD[(String, Int)] = words.reduceByKey(_ + _).sortBy(_._2) result.foreach(println) // 关闭连接 sc.stop() } } // 一行代码 实现wordcount object WordCountFour { def main(args: Array[String]): Unit = { // 创建spark运行的配置信息 // setMaster 设置运行集群(local为本地) // setAppName 设置job的name val sparkconf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCountDemo") // 创建和Spark框架的链接 val sc: SparkContext = new SparkContext(sparkconf) val result: RDD[(String, Int)] = sc.textFile("sparkcore/src/main/data/word.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortBy(_._2) result.foreach(println) // 关闭连接 sc.stop() } }
6. FAQ
Exception in thread "main" java.lang.NoSuchMethodError: scala.util.matching.Regex.<init>(Ljava/lang/String;Lscala/collection/Seq;)
原因 : 环境scala版本和spark编译所有scala版本不一致
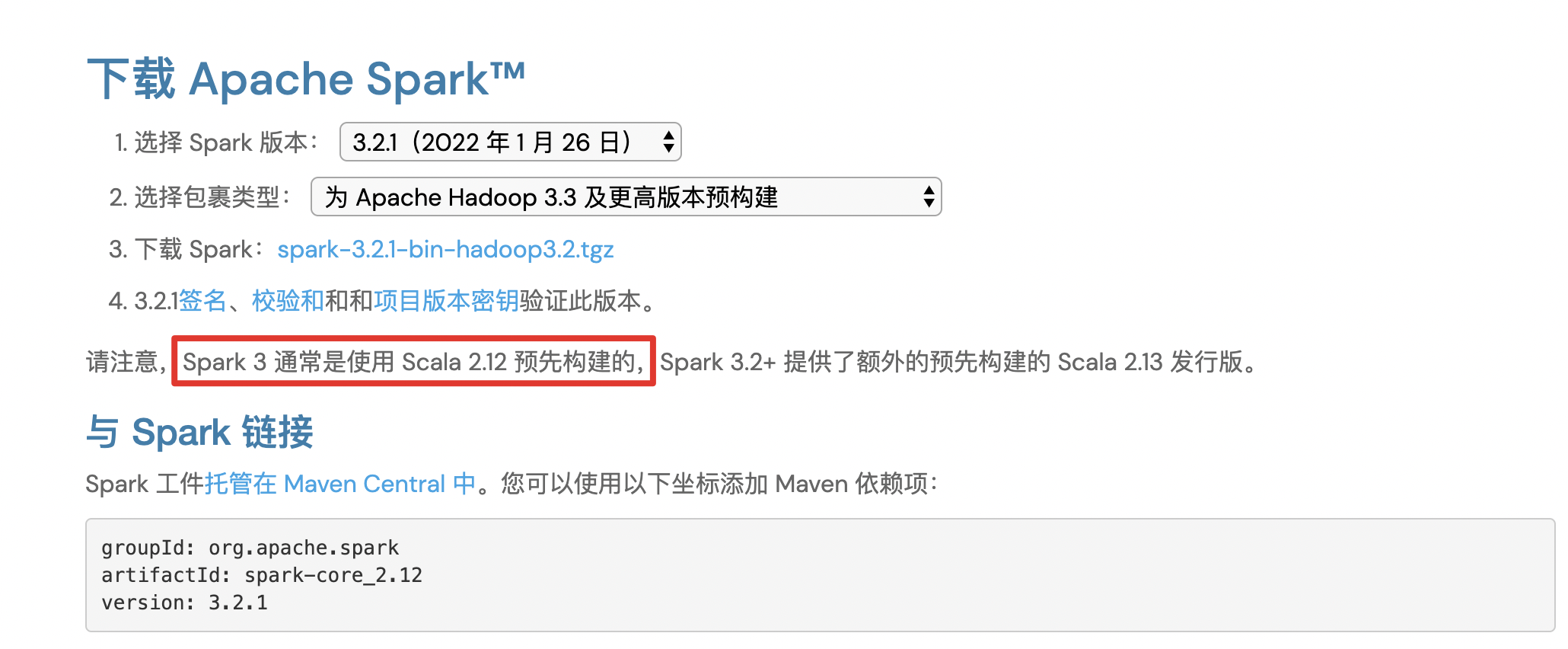
版本适配查询 :http://spark.apache.org/downloads.html
注意 : 如果用的 是Spark 3.X,一般的都是用 Scala 2.12编译的, 所以必须使用Scala 2.12.*的SDK


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界