MongoDB
关系型数据库
关系型数据库遵循如下四个特性
- A (Atomicity) 原子性
- C (Consistency) 一致性
- I (Isolation) 独立性
- D (Durability) 持久性
什么是NoSql
NoSql 是指非关系型的数据库,有时也称 Not Only Sql,是对不同于传统数据库管理系统的统称,NoSql 用于超大规模数据的存储,关系型数据库不适应这些大量数据,而NoSql 数据库能很好的处理这些数据。
两种数据库的差异
关系型数据库
- 高度组织结构化数据
- 结构化查询语言
- 数据和关系都存储在单独的表中
- 数据操作语言,数据定义语言
- 严格的一致性
- 基础事务
NoSql
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,文档存储,图形数据库
- 最终一致性,而非ACID
- 非结构化和不可预知的数据
- CAP 定义
科普CAP 原则
CAP 原则又称 CAP 定理/布鲁尔定理,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partitiontolerance(分区容错性),三者不可兼得
CAP 原则要么 AP、CP、AC ,但是不存在CAP, 所以在进行分布式架构时,必须做出取舍
NoSql 数据库分类
列存储
- Hbase
- Hypertable
文档存储
- Mongodb
- ClouchDB
key-value 存储
- Redis
- MemcacheDB
- Berkeley DB
图存储
- Neo4J
- FlockDB
对象存储
- db4o
- versant
XML 数据库
- Berkeley DB XML
- BaseX
MongoBD
mongodb 是由c++ 编写,基于分布式文件存储的开源数据库系统,将数据存储为一个文档,数据结构由键值对组成,文档类似于JSON 对象
MongoDB 与 普通数据库结构比对
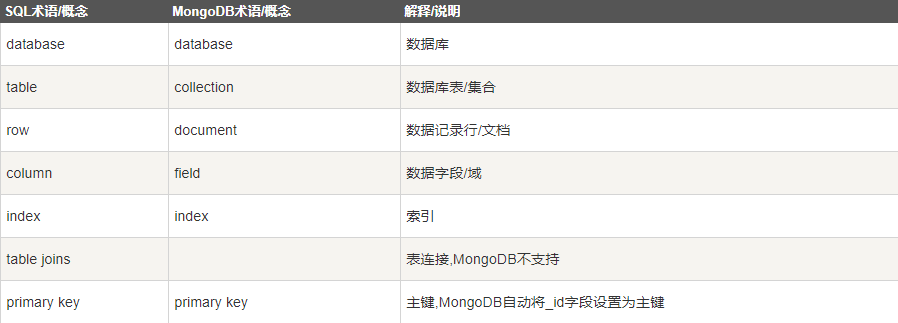
数据库-集合-文档
一、Window 下安装mongoDB
官网:https://www.mongodb.com/download-center/community
安装好后,在C盘建立data 目录
data 目录下建立 db、log 目录
在bin目录下执行
mongod --dbpath c:\data\db
链接mongodb
mongo.exe
创建配置文件 c:\data\config.cfg
systemLog:
destination: file
path: c:\data\log\mongod.log
storage:
dbPath: c:\data\db
安装服务
mongod.exe --config "c:\mongodb\config.cfg" --install
启动mongodb 服务
net start MongoDB
关闭服务
net stop MongoDB
二、使用数据库
show dbs 显示所有的数据库
use 数据库名 选择某个数据库
db 显示当前数据库
db.集合名.insert({"name":"李四"}) 插入数据
db.dropDatabase() 删除数据库
db.createCollection("集合名") 创建集合
show collections 显示DB下所有的集合
db.集合名.drop() 删除集合
db.集合名.find() 查询集合的数据
db.集合名.update({"主键":"旧值"},$set:({"主键":"新值"})) 更新文档的值
db.集合名.remove({"键":"值"}) 删除文档
文档查询操作
#版本3.2 以后
db.集合.insertOne()
db.集合.insertMany()
文档查询
db.集合.find() 查询所有的文档
db.集合.find({_id:123}) 查询 _id =123 的文档
db.集合.findOne() 返回一个对象
db.集合.find()[0] 找第一个
db.集合.find().count() 统计集合的个数
文档更新
db.集合.update({name:"zhangsan"},{name:"lisi"}) 后一个字段会覆盖掉前面的其他字段
#db.集合.updateOne() 修改一个符合条件的文档
db.集合.update({name:"zhangsan"},{$set:{"name":"liis",ip:"127.0.1"}}) 修改字段,如果不存在即新增
db.集合.drop() 删除集合 db.集合.remove({_id:123}) 删除符合条件的文档 ,默认删除多个 ,删除一个需要加参数 true
db.集合.remove({}) 清空集合
db.dropDatabase() 删除当前数据库
三、MongoDB 高可用集群
01.Master-Slave 主从结构
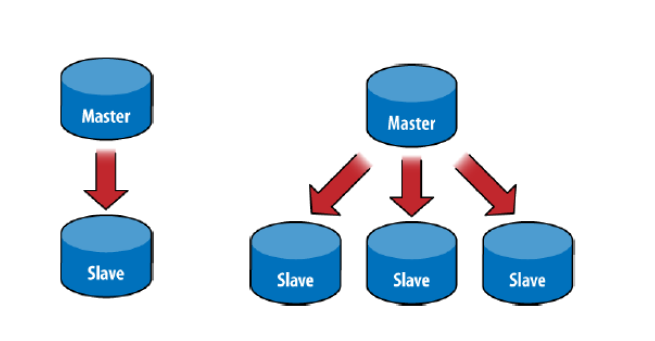
主从架构一般用于备分或者读写分离。一般有一主一从设计和一主多从设计。
Master(主): 可读可写,当数据有修改时,会将 oplog 同步到所有连接的 slave 上
Slave(从):只读不可写,自动从 Master 同步数据
注意: 对于 Mongodb 来说,并不推介使用 Master -Slave 架构,因为 Master-Slave 其中 Master 宕机后不能自动恢复,推介使用 Replica Set 。除非 Replica 节点数超过 50,才需要使用 Master -Slave 架构。正常清空不会那么多节点。
此外,Master-Slave 不支持链式架构,Slave 只能直接连接 Master.Redis 的 Master-Slave 支持链式结构。Slave 可以连接Slave.
02.Relica-Set 副本集方式
Mongodb 的Replica Set 即副本集方式主要有两个目的,一个是数据冗余做故障恢复使用,当发生硬件故障或者其他原因造成的宕机时,可以使用副本进行恢复。
另一个是做读写分离,读的请求分流到副本上,减轻主的读压力。
Primary - Seconary 搭建的 Replica Set
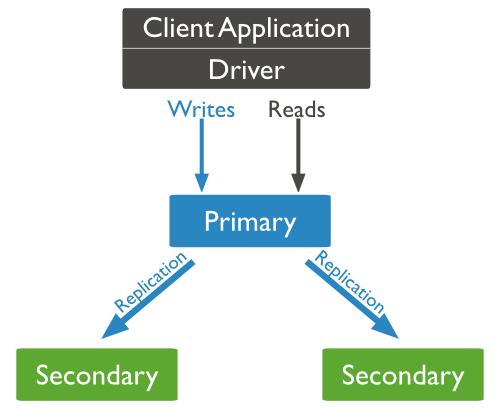
Replica Set 是 mongo 的实例集合,他们有着相同的数据内容
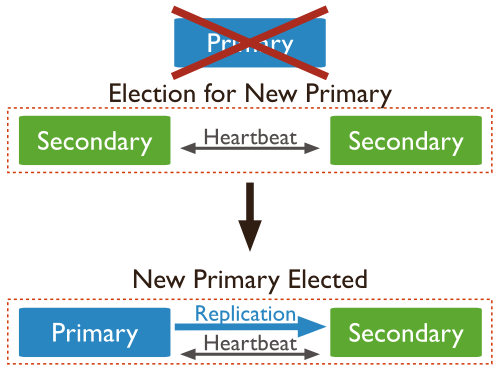
Primary(主节点):
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。
默认读请求也是发到Primary节点处理的,需要转发到Secondary需要客户端修改一下连接配置。
Secondary(副本节点):
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
Arbiter(仲裁者):
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter跑起来几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选主投票的时候要有一个大多数才能进行选主决策。
使用Arbiter搭建Replica Set
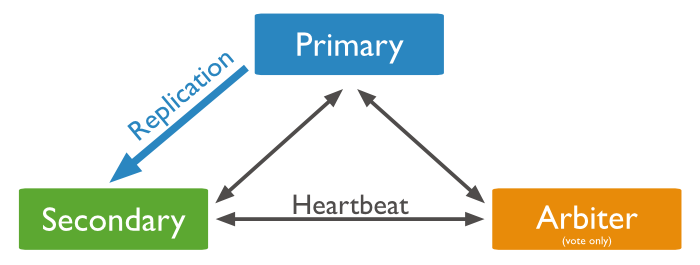
选主过程: 若 Secodary 宕机,不受影响,但是 Primary 宕机,会重新选取主节点。
03.Sharding 分片技术
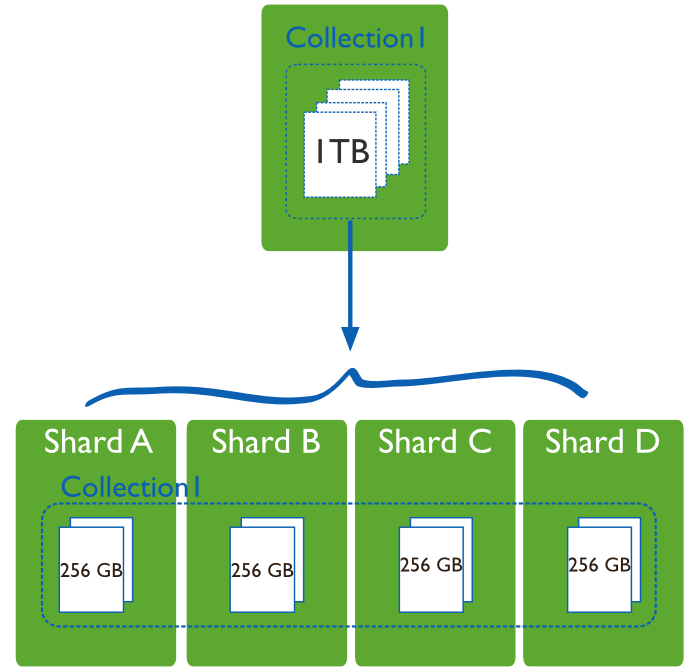
当数据两比较大时候,我们需要把数据分片运行在不同的机器,降低 cpu、内存和 IO 的压力, Sharding 就是数据库分片技术。
MongoDB 分片技术类似 Mysql 的水平切分和垂直切分,数据库主要由两种方式做Sharding :垂直扩展和横向切分
垂直扩展的方式就是进行集群扩展,添加更多的 cup,内存,磁盘空间等
横向切分则是通过数据分片的方式,通过集群统一提供服务
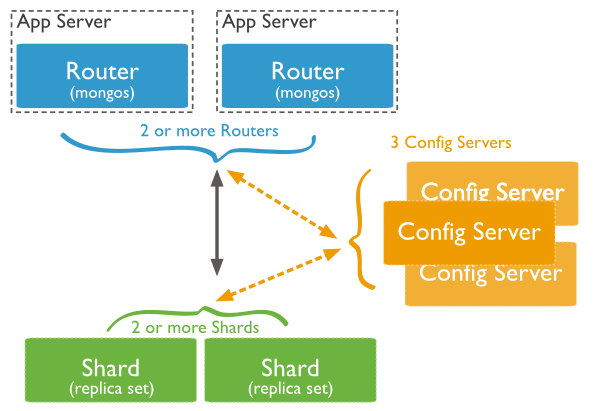
(1)MongoDB的Sharding架构
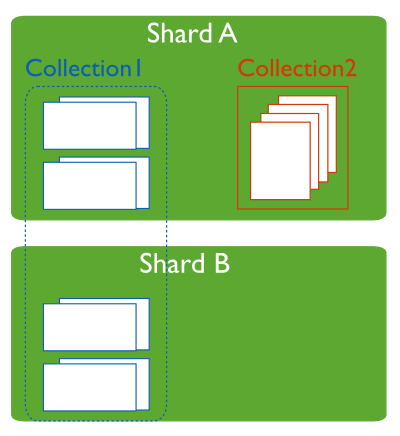
(2)MongoDB分片架构中的角色
数据片头(Shards)
用来保存数据,保证数据的高可用性和一致性,可以是单独的 mongo 实例,也可以是一个副本集。
在生产环境下 Shard 一般是一个 Replica Set ,以防止改数据片的单点故障。所有Shard 种有一个 PrimaryShard,里面包含未进行画分的数据集合
查询路由:(Query Routers)
路由就是 mongos 的实例,客户端直接连接 mongos ,由 mongos 把读写请求路由到指定的 Shard 上去
一个 Sharding 集群,可以有一个 mongos,也可以有多个 mongos 以减轻客户端的压力。
配置服务器:(Config Servers)
保存集群的元数据(metadata),包含各个 Shard 的路由规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号