Hadoop完全分布式搭建
目录
Hadoop完全分布式搭建
环境准备
- 准备3台机器
- 配置网络
- 修改主机名
- 配置主机hosts映射
- 关闭防火墙
- 创建用户并使用户具有root权限
- 安装jdk并配置环境变量
- 安装hadoop并配置环境变量
- ssh免密配置
集群规划
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | namenode datanode |
datanode | secondarynamenode datanode |
| YARN | nodemanager | nodemangaer resourcemanger |
nodemanager |
开始配置集群
配置hadoop-env.sh
# 添加java的路径
JAVA_HOME=/opt/module/jdk1.8.0_181
配置workers
为了后面能够群起集群
hadoop1
hadoop2
hadoop3
配置core-site.xml
<!--配置namenode的内部通讯地址-->
<property>
<name>ds.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
<!--指定数据保存的路径,为了路径统一,所以设置一个变量-->
<property>
<name>hadoop.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
配置hdfs-site.xml
<!--设置副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--namenode的数据保存地址-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<!--datanode的数据保存地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<!--secondarynamenode的数据保存地址-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/secondarynamenode</value>
</property>
<!--namenode的web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!--secondarynamenode的web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:9868</value>
</property>
配置mapred-site.xml
<!--指定mapreduce运行到yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml
<!--nodemanager运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value>
</property>
<!--取消yarn虚拟内存的限制-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
初始化namenode
hadoop1
hdfs namenode -format
启动hadoop
hadoop1
hdfs --daemon start namenode
hdfs --daemon start datanode
yarn --daemon start nodemanager
hadoop2
hadfs --daemon start datanode
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
hadoop3
hdfs --daemon start secondarynamenode
hdfs --daemon start datanode
yarn --daemon start nodemanager
测试启动
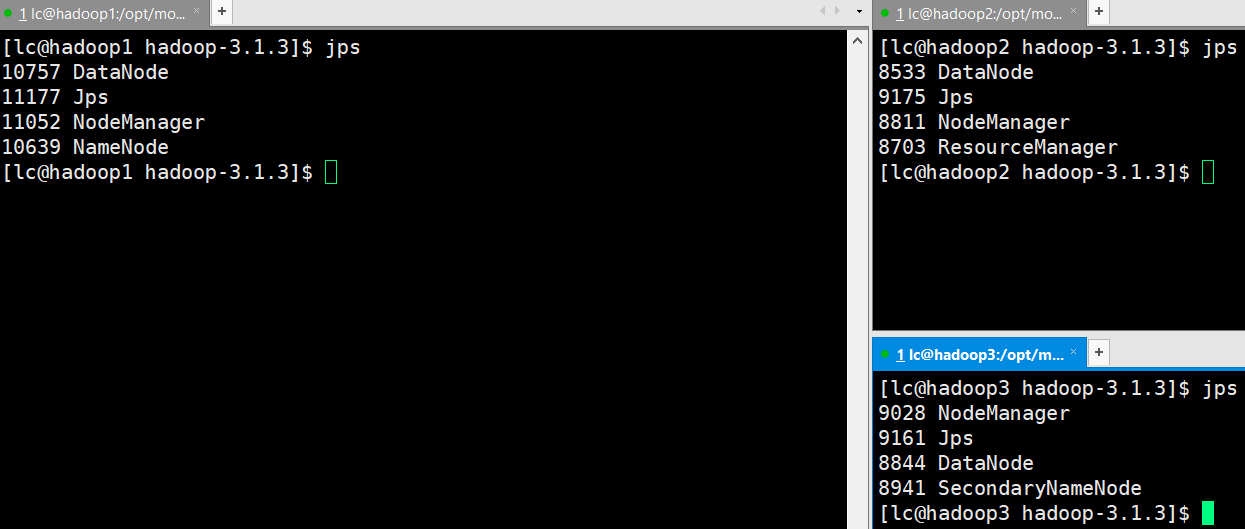
- jps
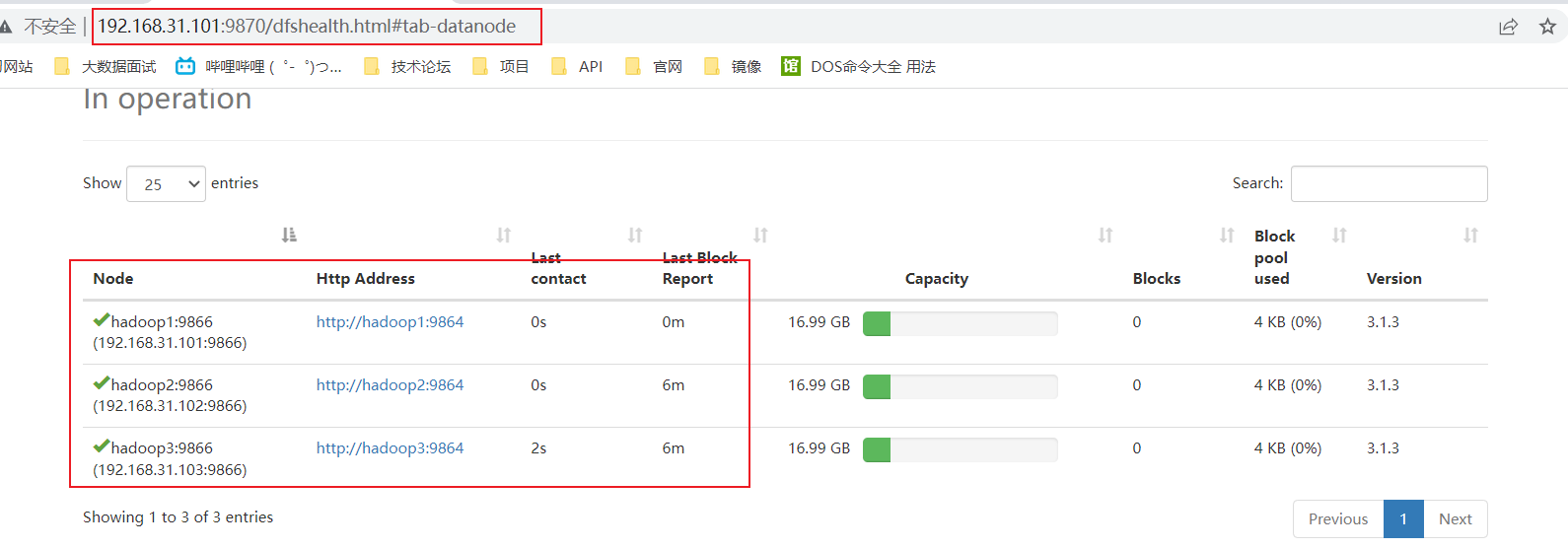
- web测试
脚本编写
群发:rsync,差异性复制
#!/bin/sh
# 判断参数
if [ $# -lt 1 ]
then
echo "input arguments errors!"
exit
fi
# 遍历集群
for hadoop in hadoop1 hadoop2 hadoop3
do
# 遍历文件
for file in $*
do
# 判断文件是否存在
if [ -e $file ]
then
# 获取文件的父目录
pdir=$(cd -P $(dirname $file);pwd)
# 获取文件名字
filename=$(basename $file)
# 差异性复制
rsync -av $pdir/$filename $hadoop:$pdir
else
echo "$file is not exist!"
fi
done
done
hadoop集群,群起脚本
#!/bin/sh
if [ $# -lt 1 ]
then
echo "input arguments error"
exit
fi
# 启动或关闭集群
case $1 in
start)
echo "======HDFS START======"
ssh hadoop1 start-dfs.sh
echo "======YARN START======"
ssh hadoop2 start-yarn.sh
;;
stop)
echo "======HDFS STOP======"
ssh hadoop1 stop-dfs.sh
echo "======YARN STOP======"
ssh hadoop2 stop-yarn.sh
;;
*)
echo "input arguments error"
;;
esac

 浙公网安备 33010602011771号
浙公网安备 33010602011771号