Python scrapy 爬虫 模拟登录
模拟登录,可以解决某些网站,必须要登录才能抓取的问题。
模拟登录就是要拿到网站的 cookie。
当爬虫程序进入网站开始抓取时数据时,爬虫的入口并不是 scrapy 给定的 pass ,而是 scrapy 封装好的 start_requests ,这个方法就是对 start_urls 执行 for 循环,然后把它 yield Request 出去。
对我们模拟登录来讲,只需要修改它的这个 for 循环,直接把这个 start_requests 方法覆盖掉就可以了。
模拟登录,需要使用 Selenium 类库 , Selenium 是个浏览器自动化项目,它的核心是 WebDriver ,可以控制浏览器进行点击,移动,输入等。
目前 Selenium 有个缺陷,在控制浏览器时,会被一些知名网站识别出来,比如知乎、拉勾等,也就是被 反爬 了。
selenium 文档
undetected-chromedriver 这个开源项目可以防止被这个大厂的网站识别出来,它可以让 Selenium 变的更加简单,且不容易被发现。需要将这两个项目安装在当前爬虫也在的虚拟环境中:
安装浏览器自动化类库
1. 进入到当前爬虫的虚拟环境
workon py3scrapy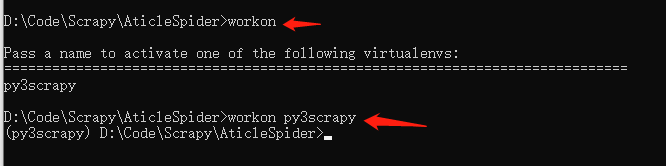
2. 安装类库,使用 douban 源,速度非常快
pip install selenium -i https://pypi.douban.com/simple
pip install undetected-chromedriver -i https://pypi.douban.com/simple
报下面这个错的原因,是因为我开的代理了,把代理关了就可以了。
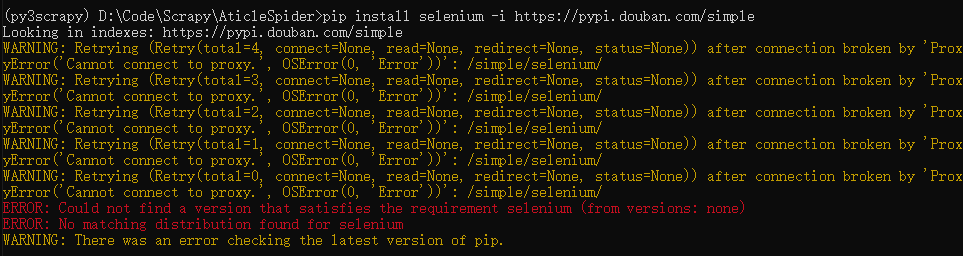
正在安装:


3. 使用类库,在当前文件中导入这两个类库
undetected-chromedriver 的高级用法:
# 把这个复制过来就可以实例化一个浏览器了
import undetected_chromedriver.v2 as uc
browser = uc.Chrome()如果有找不到安装的类库时,须再去项目的 python 解释器中找到类库安装的虚拟环境的位置,重新进行配置。
未完待续...
越努力,越幸运,坚持每天学习一小时,坚持每天吸收一个知识点。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
2017-09-04 锚点定位跳转的各种实现方法