怎么使用 python 的 jieba 中文分词模块从百万数据中找到用户搜索最多的关键字
最近在看 [生财有术] 亦仁大大分享的一篇文章 [如何在百万级的数据里找到别人正在赚钱的项目] , 作者在里面用到一个分词技术,今天研究了,找数据的这个过程记录一下。
分词环境:
# 安装 表格工具和分词工具
pip3 install xlwt
pip3 install jieba
编辑器: VSCODE
Python 3.9.4
电脑环境: MAC OS 11.2.3
- Python 环境安装
- VSCODE 下运行 .py 文件
关键词获取渠道
摘录自 [如何在百万级的数据里找到别人正在赚钱的项目] 。
以下为原作者君言分享。
2019年,我通过自己寻找项目的方法,找到了一个 月营收可达近5W的小项目,说他是小项目,不是说它赚的少,是因为它很不起眼,你几乎想不到这样的东西也可以赚钱。项目本身不做分享,我自己和朋友就在经营着,我也不做培训,这篇文章的目的主要还是记录和复盘自己的操作思路。虽然不提项目,但是挖掘一个项目的具体步骤我可以提供给大家,如果对你有启发,可以去寻找合适你的项目。
两个词挖掘出海量用户需求这两个神奇的词就是我们经常在使用的:怎么、什么
步骤1:百度搜索:5118,进入5118官网,使用”查询长尾词“工具,搜索:怎么
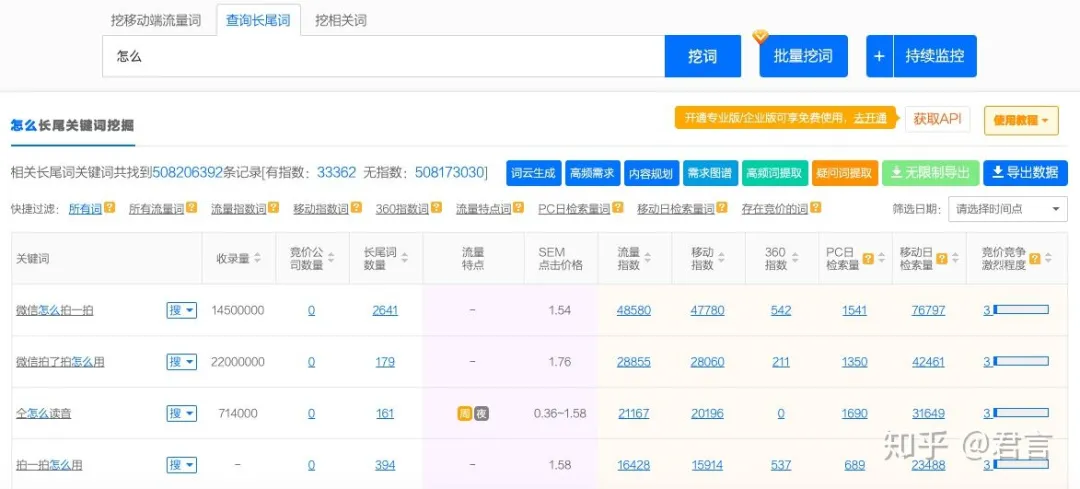
可以看到相关长尾词有5亿多,右上角”导出数据“(年VIP可以导出50W条),这样我们可以拿到跟”怎么“有关的大量长尾词,
接下来简单清洗下数据,包括:去重、去长、去短、去无效词,去非目标词(按顺序操作)我们先把各Excel里的数据,除关键词这一列,其他列都删除,那些搜索数据、长尾数量、竞争程度,不是我们此次的分析目标,没有参考意义,我们只要“关键词”这一列。
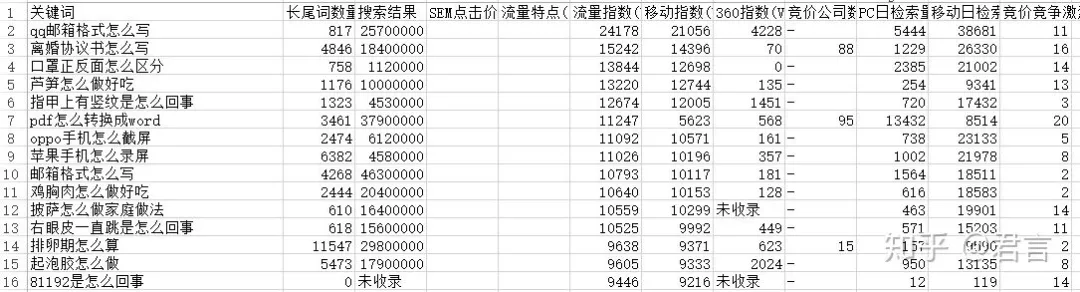
但是词数有5亿多,我们可能只能下载几十万,不一定具有代表性,全部下载及分析既不现实也无意义,所以我们只需要提取有代表性的词即可,具体方法是:刚才导出的50W数据,用Python写个脚本,利用jieba分词模块,把一个个完整长尾词分成词根,比如:QQ邮箱格式怎么写 --> QQ、邮箱、格式、怎么、写边分词的时候边自动记录每个词根的次数,即词频,结果保存到Excel里,然后在Excel里按照词频倒序排序出来。。。
过程就不写了,目的就是找出所有相关关键词的词根,然后使用分词工具,将搜索最多的词以及词频分别记录下来,方便对关键词挖掘。
词频制作并导出为 TXT 文件
因为技术有限,目前只能处理 TXT 文件的词,如果使用 5118 工具导出的为 csv 文件,请使用 csv to txt 工具转换一下文件格式。

txt_query.py 为运行程序,代码为:
import jieba import jieba.analyse import xlwt if __name__=="__main__": wbk = xlwt.Workbook(encoding = 'ascii') #Excel sheet = wbk.add_sheet("wordCount") word_lst = [] key_list=[] #txt doc for line in open('keywords.txt'): #made excel item = line.strip('\n\r').split('\t') # print item #jieba running tags = jieba.analyse.extract_tags(item[0]) for t in tags: word_lst.append(t) word_dict= {} #open file with open("newkeywords.txt",'w') as wf2: for item in word_lst: #count num if item not in word_dict: word_dict[item] = 1 else: word_dict[item] += 1 orderList=list(word_dict.values()) orderList.sort(reverse=True) # print orderList for i in range(len(orderList)): for key in word_dict: if word_dict[key]==orderList[i]: #write txt wf2.write(key+' '+str(word_dict[key])+'\n') key_list.append(key) word_dict[key]=0 for i in range(len(key_list)): sheet.write(i, 1, label = orderList[i]) sheet.write(i, 0, label = key_list[i]) #save wordCount.xls wbk.save('wordCount.xls')
如果在运行过程中,有对应注释行报错,删除注释就可以了。
运行 Python 文件
- 打开终端
- cd 命令进入当前目录 jieba
- 输入命令:python txt_query.py
显示下面提示就说明运行成功了:

生成的文件:
我的例子中搜索的关键词是 “人脸识别”,最后会得出这样的分词结果。
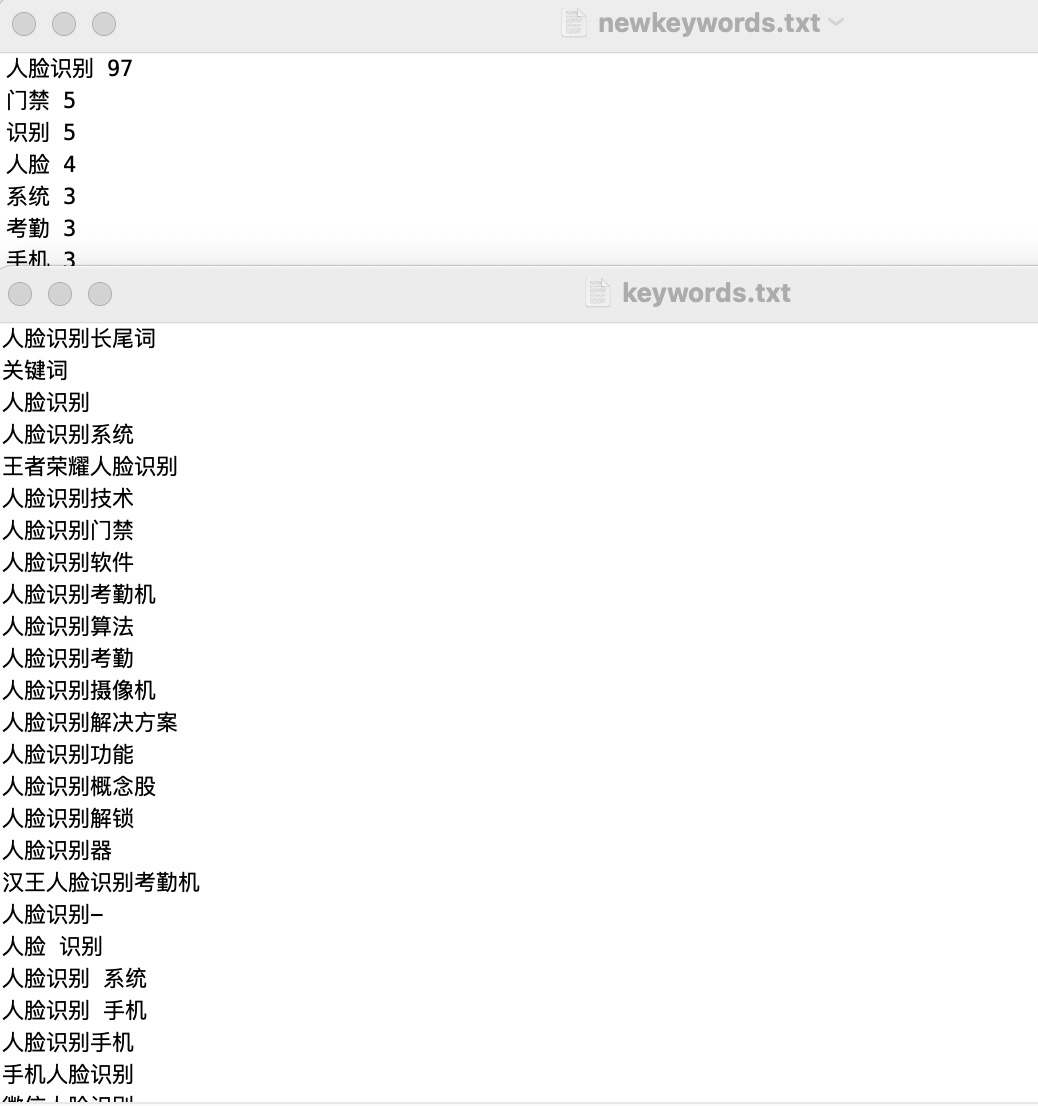
目前流行的是 csv 文件关键词,下面再研究下,这个文件格式的关键词怎么清洗,后续。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号