

MySql- Explain
Explain语句可以查看SQL的执行情况,根据执行情况进行优化。
1. id
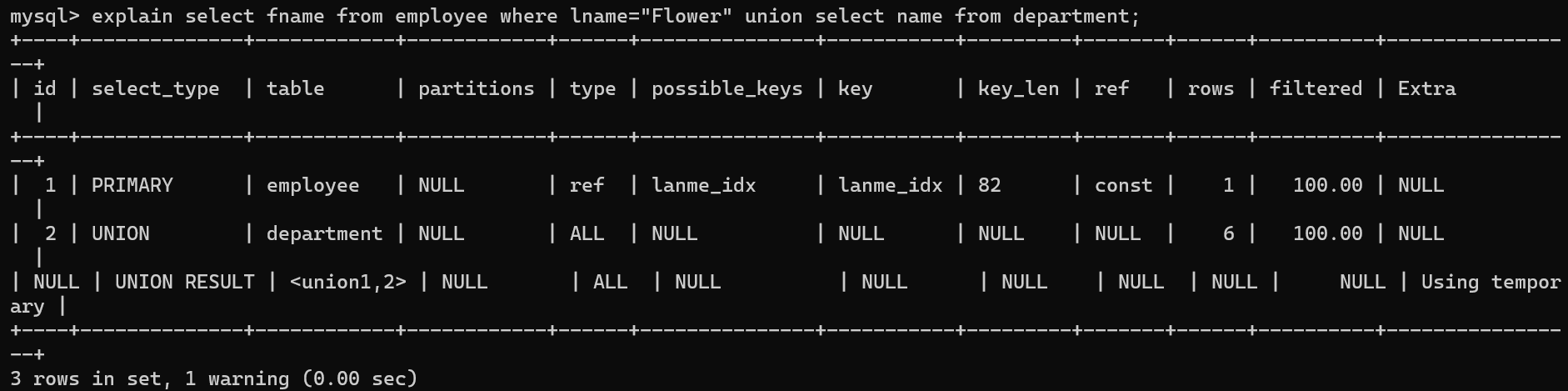
id查询的标识符,几个查询几个id。NULL表示引用其它行的结果。id越大执行优先级越高
2. select_type
- SIMPLE: 简单查询
- PRIMARY: 最外层查询
- UNION: 使用union时第二个查询和之后的查询的select_type会被标记为UNION
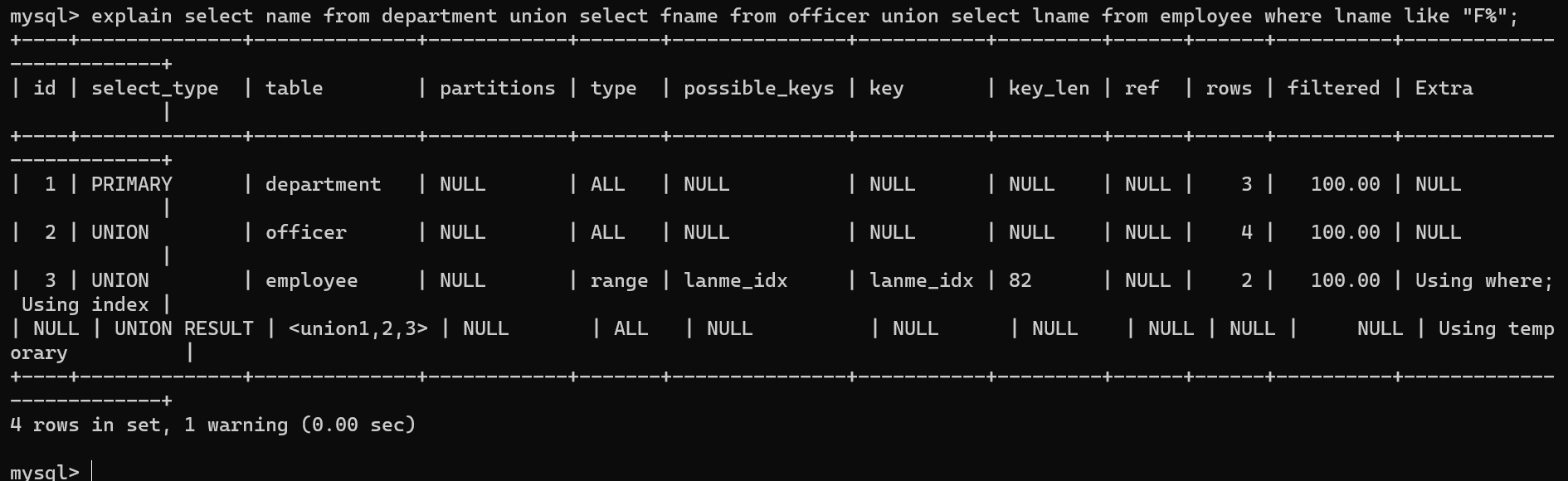
- UNION RESULT
如果是union,最后对结果去除的操作的select_type会被标记为UNION RESULT
如果是union all不存在id为NULL的额外一行,也就不存在select_type为UNION RESULT的行

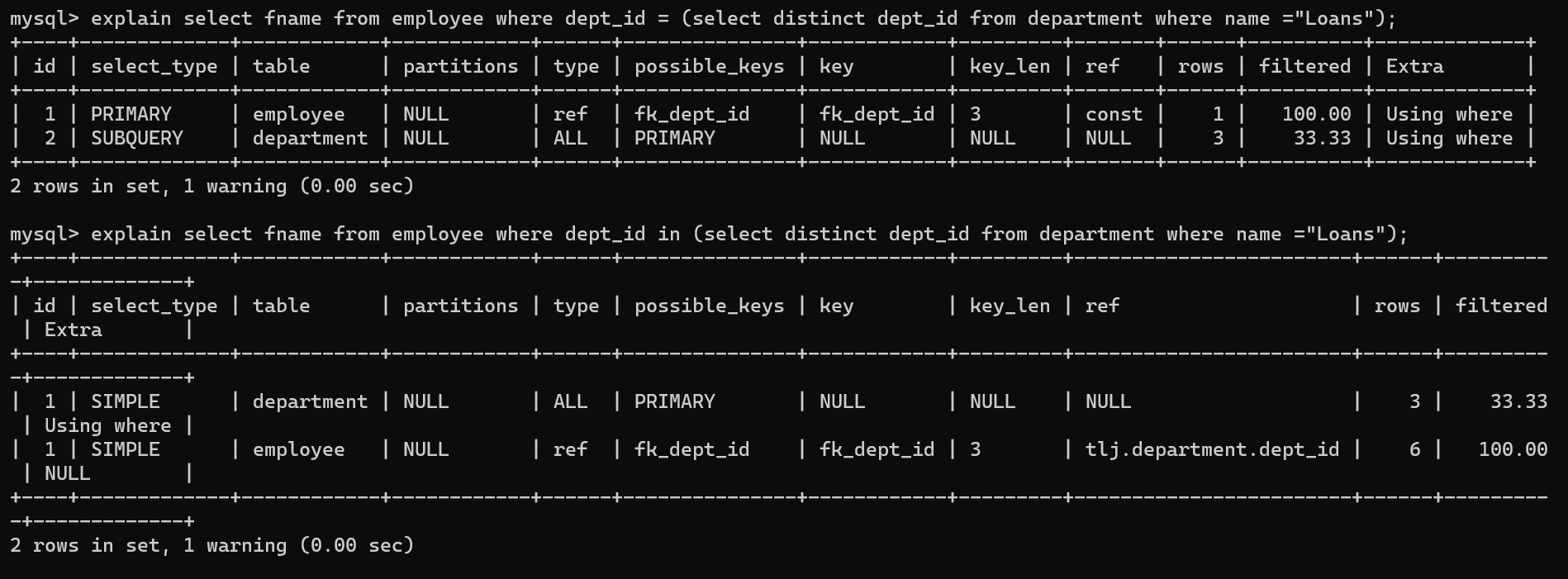
- SUBQUERY
子查询

- DERIVED
派生, from里的select,并不一定有
3. table
访问哪一个表,从哪一个表里进行查询
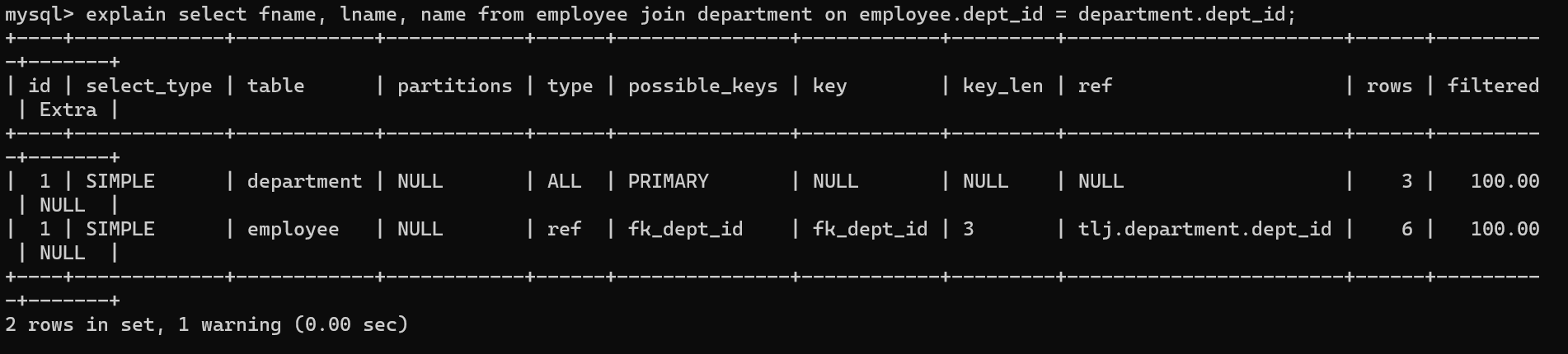
4. partitions
当前查询匹配记录的分区,未分区的表返回null
5. type
连接类型,决定了sql的执行速度
-
system:const的特例,
-
const: 针对主键或唯一索引等值查询扫描,最多返回一行数据,

-
eq_ref:
唯一性索引扫描,对于每个索引键表中只有一条记录与之匹配
当使用了索引的全部组成部分,并且索引是PRIMARY 或 UNIQUE NOT NULL时才会使用
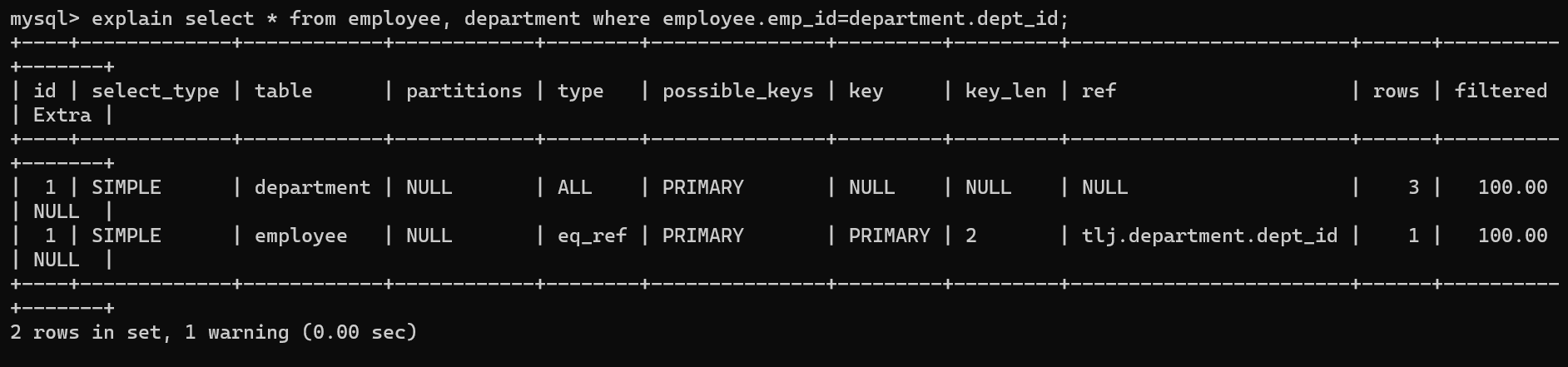
-
ref
非唯一性索引扫描,返回匹配某个值的所有行,
通过索引查找结果,但是有多个匹配行

-
range
范围查找,使用索引
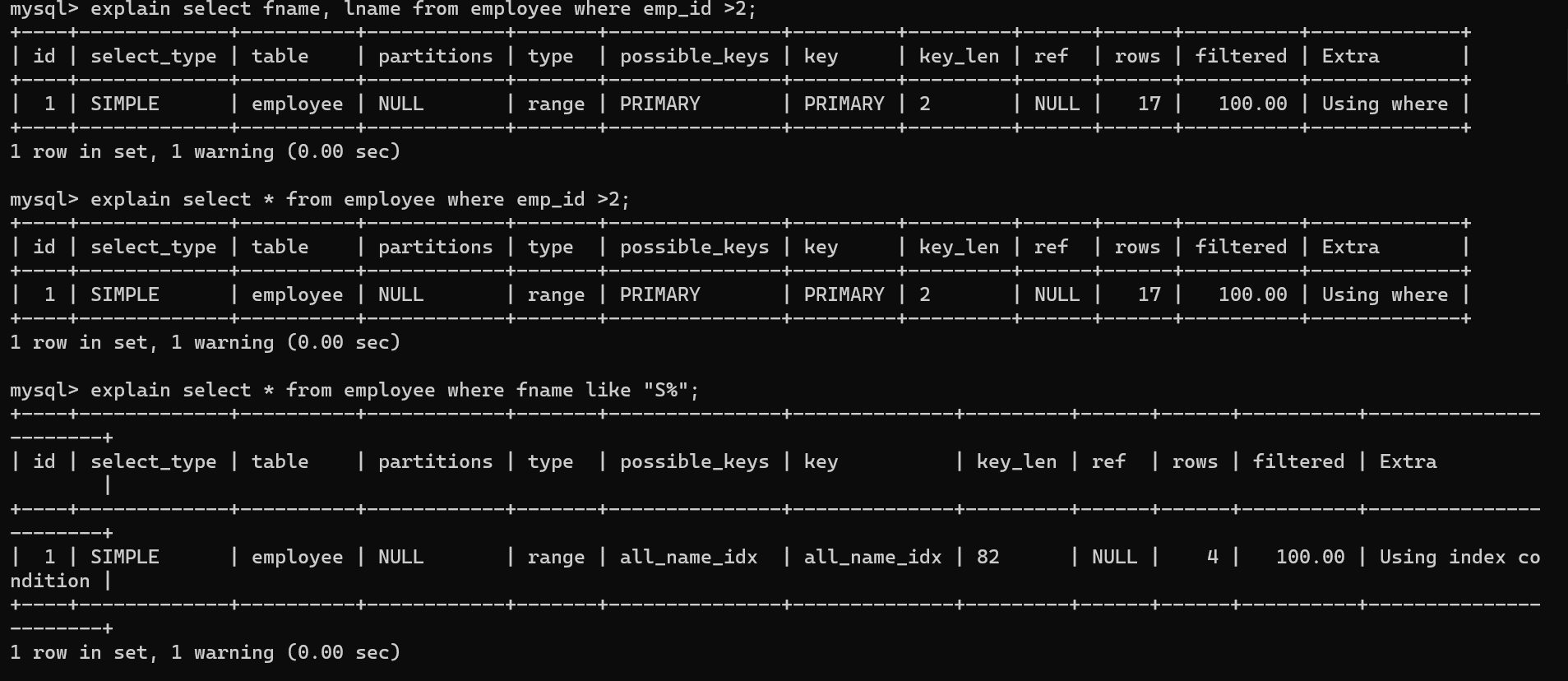
-
index
扫描全部索引和ALL相比只从索引读取

-
ALL全表扫描
遍历全表
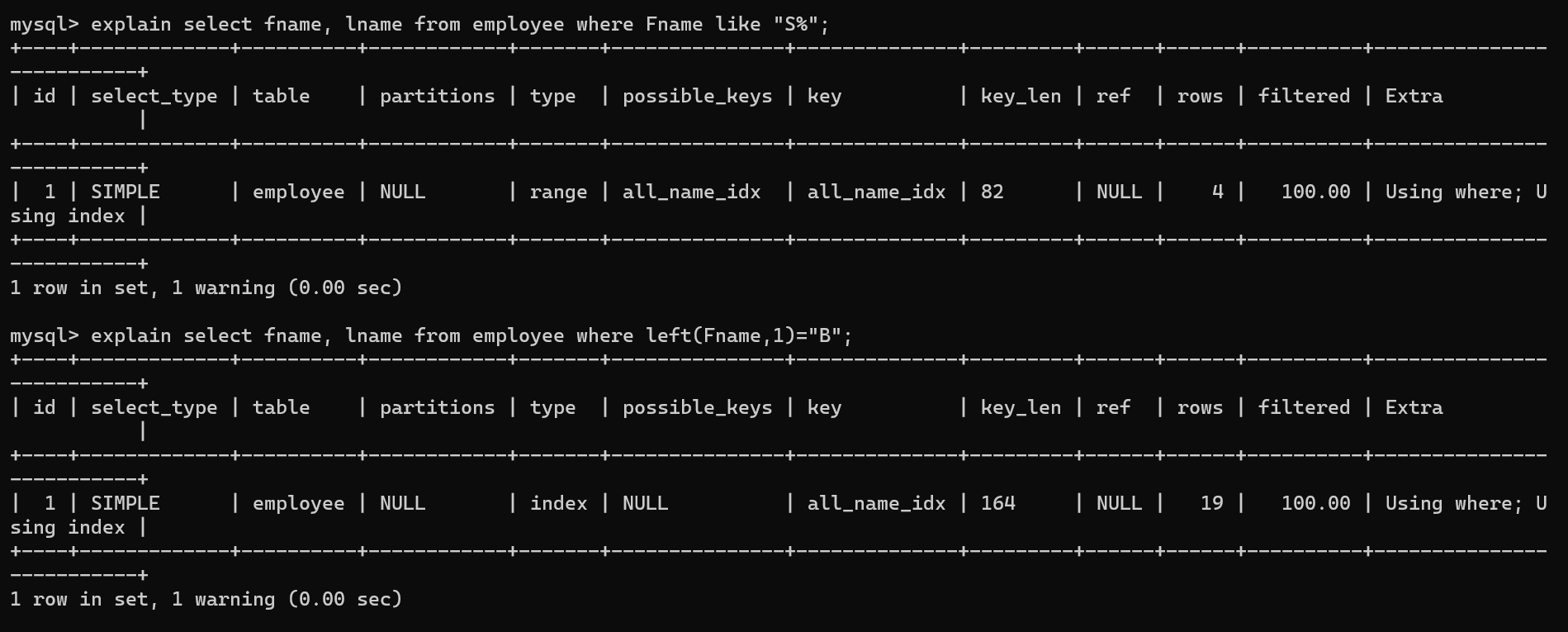
4. possible_keys,Key
possible_keys查询可能用到的索引,但不一定被使用
Key实际使用的索引
如果Key为Null,则没有使用索引
如果是索引覆盖即通过索引就查询到了相应的值,则possibile为Null,使用的索引在key中
5. key_len
索引使用的字节数,查询中使用的索引最大长度,长度越长精度越高效率越低,长度越短效率越高,但精度越低。是一个预估值
6.ref
where或join中与索引比较的参数,常见的有const(常量),func(函数)、字段名


7. rows, filtered
rows预估需要扫描的行数,越小越好
filtered:符合查询条件的数据百分比,最大为100,
8. Extra
额外信息
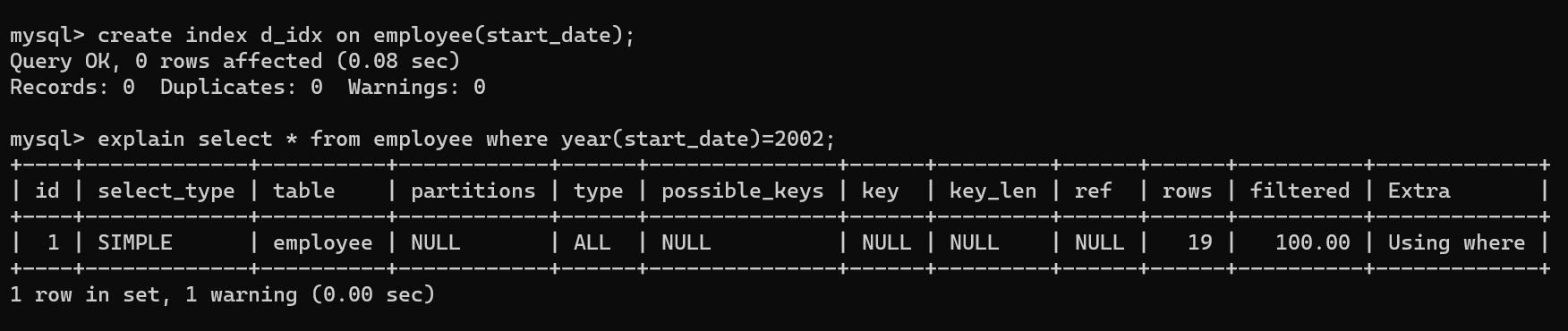
-
using where
使用了where但没使用索引,有时候使用了索引也使用了where也有,比如id的例子中,Primary的那个查询中使用了索引也有where。

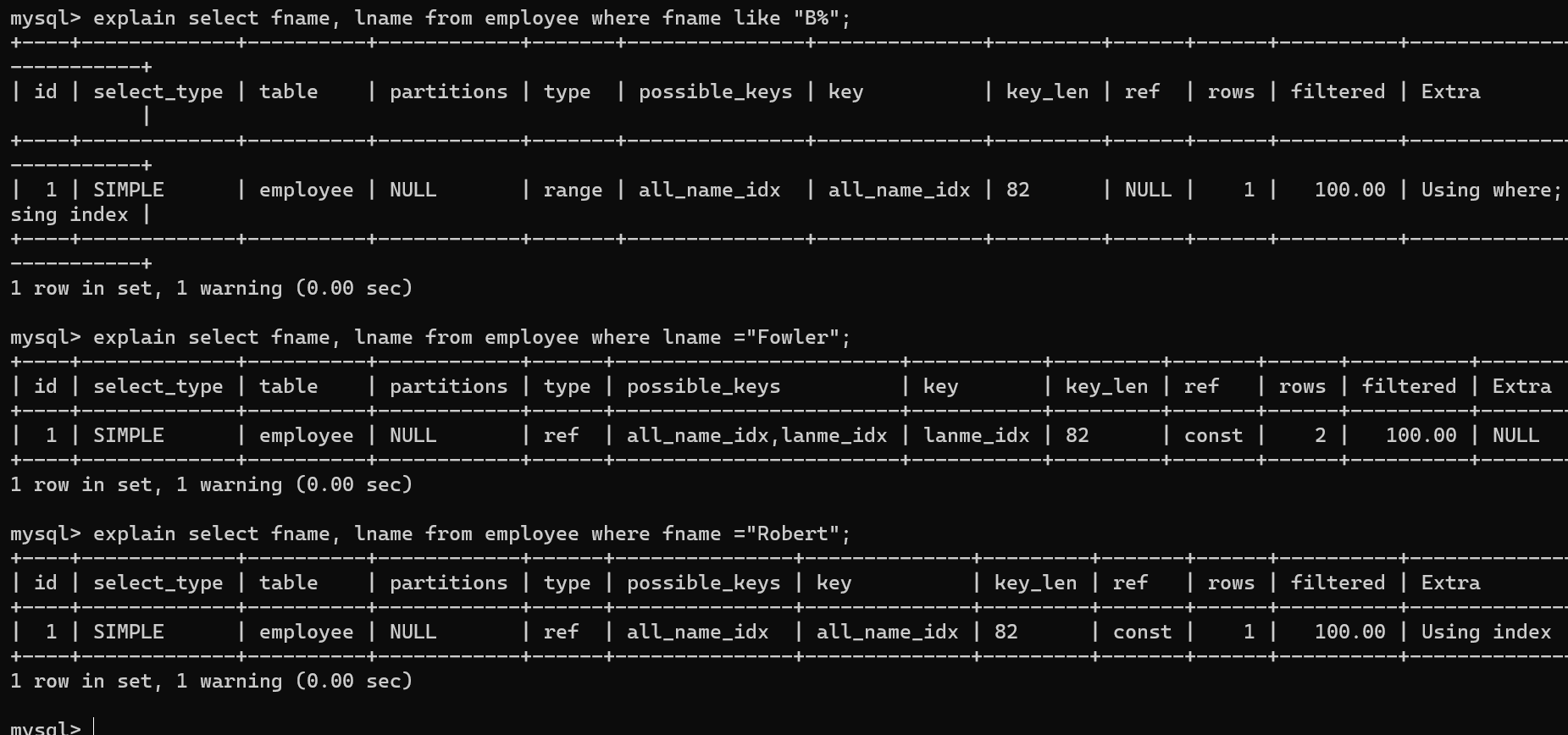
-
Using index索引覆盖
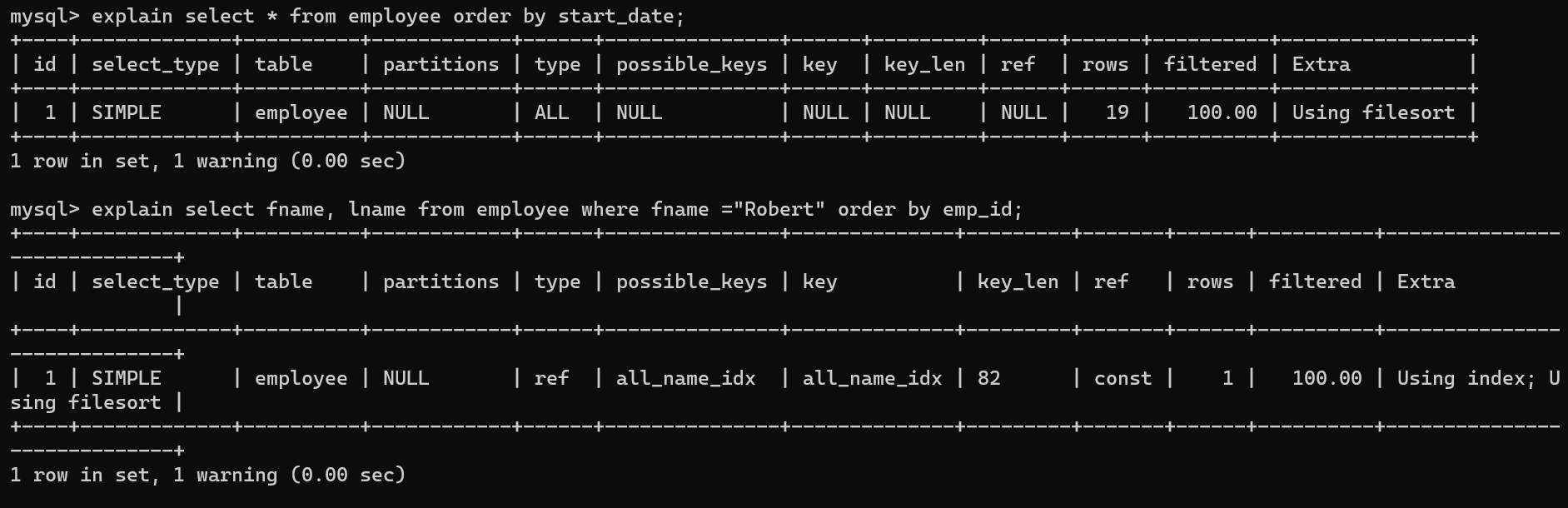
-
Using filesort 使用外部排序,而不是按照表内的索引顺序读取, 可能需要优化
-
using temporary
使用了临时表

-
using join buffer
join时没有用到索引,使用了连接缓存

-
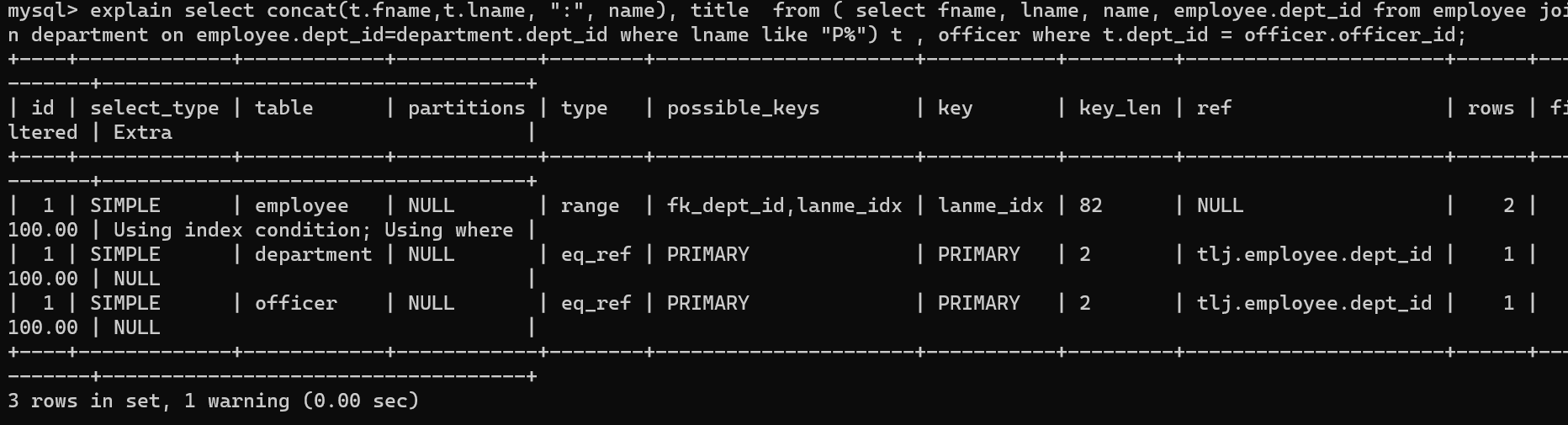
using index condition
使用索引下推,查询的列有非索引列,但先判断索引条件以减少磁盘io。
实际使用的时lnam的索引但是fnam不再lname的索引中。
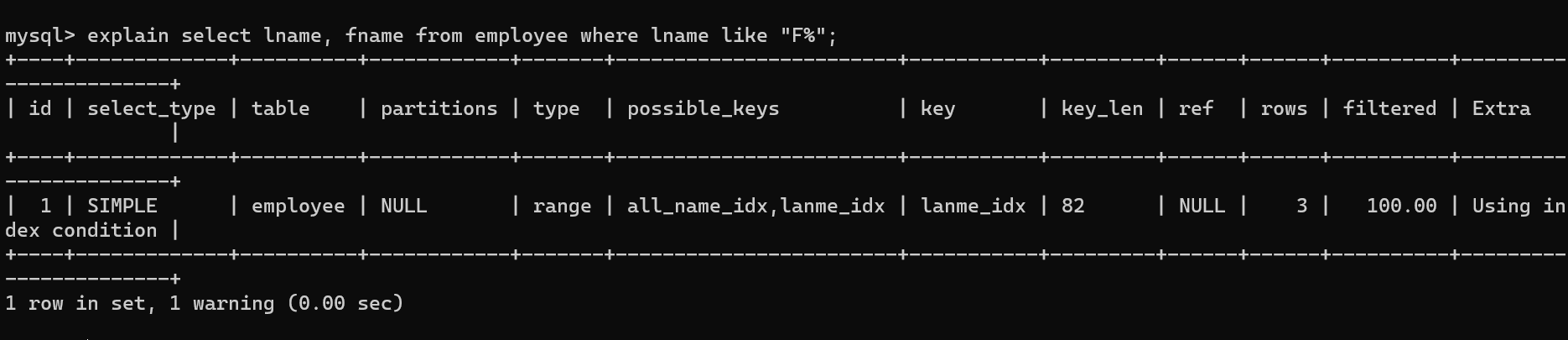
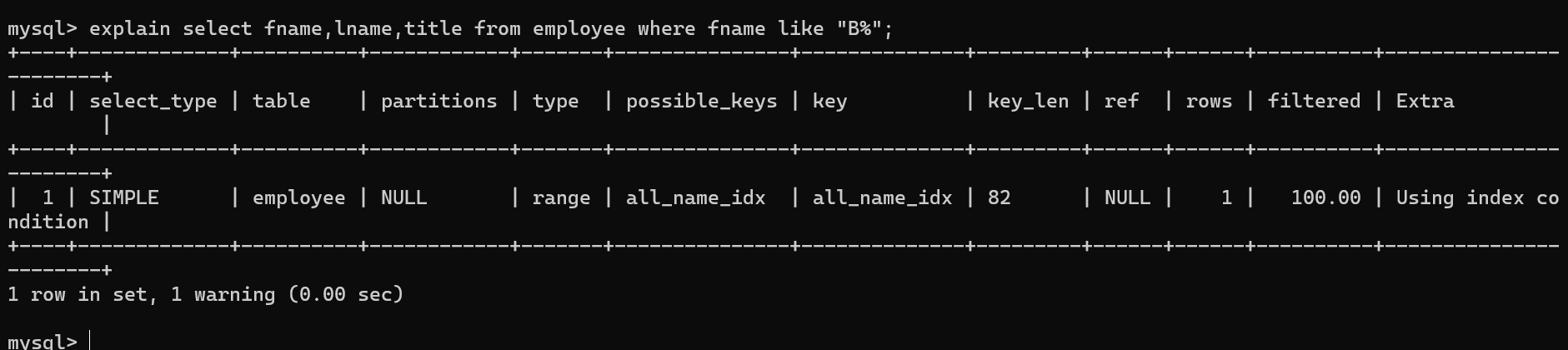
使用all_name索引,但是又查询了title列,title列不在索引里。

