

label smoothed cross entropy 标签平滑交叉熵
在将深度学习模型用于分类任务时,我们通常会遇到以下问题:过度拟合和过度自信。对过度拟合的研究非常深入,可以通过早期停止, 辍学,体重调整等方法解决。另一方面,我们缺乏解决过度自信的工具。标签平滑 是解决这两个问题的正则化技术。通过对 label 进行 weighted sum,能够取得比 one hot label 更好的效果。
label smoothing 将 label 由 转化为
,公式为:
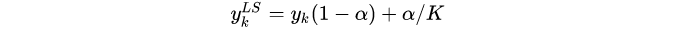
过度自信和校准
如果分类模型的预测结果概率反映了其准确性,则对它进行校准。例如,考虑我们数据集中的100个示例,每个示例的模型预测概率为0.9。如果我们的模型经过校准,则应正确分类90个示例。类似地,在另外100个预测概率为0.6的示例中,我们期望只有60个示例被正确分类。
模型校准对于
- 模型的可解释性和可靠性
- 确定下游应用程序的决策阈值
- 将我们的模型集成到集成或机器学习管道中
过度自信的模型未经过校准,其预测概率始终高于准确性。例如,对于精度仅为0.6的输入,它可以预测0.9。请注意,测试误差较小的模型仍然可能过于自信,因此可以从标签平滑中受益。
标签平滑公式
标签平滑用y_hot和均匀分布的混合替换一键编码的标签矢量y_hot:
y_ls =(1- α)* y_hot + α / K
其中K是标签类别的数量,而α是确定平滑量的超参数。如果α = 0,我们获得原始的一热编码y_hot。如果α = 1,我们得到均匀分布。
标签平滑的动机
当损失函数是交叉熵时,使用标签平滑,模型将softmax函数应用于倒数第二层的对数向量z,以计算其输出概率p。在这种设置下,交叉熵损失函数相对于对数的梯度很简单
∇CE= p - y = softmax(z)-y
其中y是标签分布。特别是,我们可以看到
- 梯度下降将尝试使p尽可能接近y。
- 渐变范围介于-1和1。
一键编码的标签鼓励将最大的logit间隙输入到softmax函数中。直观地,大的logit间隙与有限梯度相结合将使模型的适应性降低,并且对其预测过于自信。
相反,如下面的示例所示,平滑标签鼓励较小的logit间隙。在[3]中表明,这将导致更好的模型校准并防止过度自信的预测。
一个具体的例子
假设我们有K = 3类,并且我们的标签属于第一类。令[ a,b,c ]为我们的logit向量。
如果我们不使用标签平滑,则标签矢量是单热编码矢量[1、0、0]。我们的模型将一个 » b和一个 » Ç。例如,将softmax应用于logit向量[10,0,0]会得出[0.9999,0,0]舍入到小数点后4位。
如果我们使用α = 0.1的标签平滑,则平滑的标签向量≈[0.9333,0.0333,0.0333]。logit向量[3.3322,0,0]在softmax之后将平滑的标签向量近似为小数点后4位,并且间隙较小。这就是为什么我们称标签平滑为一种正则化技术,因为它可以抑制最大的logit变得比其余的更大。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践