

BLEURT: Learning Robust Metrics for Text Generation 论文翻译与笔记
笔记:
ROUGE and BLEU:最早出现的句子相似度度量方法,基于N-gram重叠。这些度量标准只对词汇变化敏感,不能识别句子语义或语法的变化。因此,它们被反复证明与人工评估差距较大。
BEER, RUSE, and ESIM:需要进行端到端训练,通常依赖经人工标注或经过学习的嵌入。在给定人类评估数据训练集的情况下,能够拟合人类评估的分布,效果较好。可经微调用于度量特定的属性,如流畅性、原文忠实度、语法正确性或语言风格。
YiSi and BERTscore:使用句子上下文表示和人工设计的计算逻辑对句子相似度进行计算。鲁棒性较好,在缺乏训练数据的情况下也具有较好表现。
作者认为,可以通过预训练结合人工评估数据的微调来同时满足度量方法的鲁棒性和表达度。基于该思路,提出了BLEURT,一种基于BERT的文本生成任务度量方法,通过对维基百科句子的随机扰动,辅以一组词汇级和语义级的监督信号来进行预训练。
预训练过程
其预训练过程是在普通bert预训练之后的一个补充,在正常的bert预训练完成之后,在微调前对bert进行再预训练 预热
数据集,文章里从维基百科获取句子集 ,并进行随机扰乱获取扰乱句子集。
1.生成句子对
从维基百科获取句子集 ,并进行随机扰乱获取扰乱句子集
扰乱方法包括:
遮盖(BERT,spanBERT)
回译(en->fr->en)
删除(30%)
2.预训练监督信息

如图所示,监督信息包括
1)其他自动指标计算方法的结果(BLEU,ROUGE,BERTscore)
2)回译似然度
令 为英译法模型,同理
为法译英模型
则该分数可定义为 ,
其中
通过调换 和
的顺序,以及添加英德和德英翻译模型,共获得四个似然分数
3)三分类标签,判断原句和扰动句的文本关系,主要包括蕴含、矛盾、中立
4)回译标志,标注扰动句是否通过原句由回译过程生成
3.建模
上述任务的预测值均通过[CLS]后接一线性层获得
对于回归任务,用均方误差作为损失;对于多分类任务,用交叉熵作为损失
最终将各个任务的损失函数进行聚合
,其中K为任务个数,M为数据个数
对预训练的模型进行少样本微调
通过连接参考句和预测句,送入BERT预训练模型可获得上下文向量序列
取特殊标志[CLS]位置的向量作为句子表示,馈入一线性层,获得相似度分数
使用少量训练数据进行微调,选用线性回归损失函数
实验
WMT指标共享任务
数据集:WMT Metrics Shared Task(2017-2019)
指标: (Kendall's Tau),以及当年的官方度量指标。WMT官方指标为
(Pearson's correlation)或
(Kendall's Tau)的变体DARR。
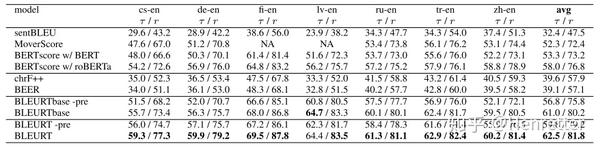
模型:BLEURT(BERT-large), BLEURTbase(BERT-base), BLEURT-pre(BERT-large,无预训练),BLEURTbase-pre(BERT-base,无预训练)
实验结果:预训练过程对结果有提升,尤其对于BERT-base。BLEURT为各个年份的WMT指标共享任务提供了sota。
对质量漂移的鲁棒性实验
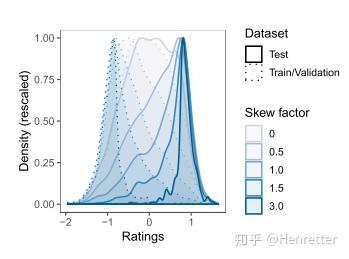
数据集:WMT Metrics Shared Task(2017)
方法:在文本翻译任务上进行实验,采样低分数的句子对作为训练数据,高分数的句子对作为测试数据,不断增大分布的斜率,观察模型的评价性能。
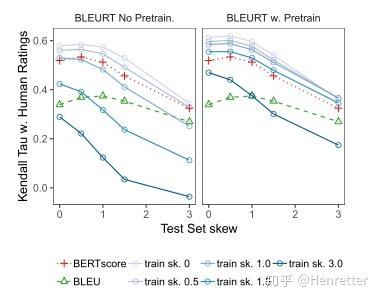
模型:BLEURT(BERT-large),BLEURT-pre(BERT-large,无预训练)
实验结果:预训练过程使模型对质量漂移的鲁棒性显著提升
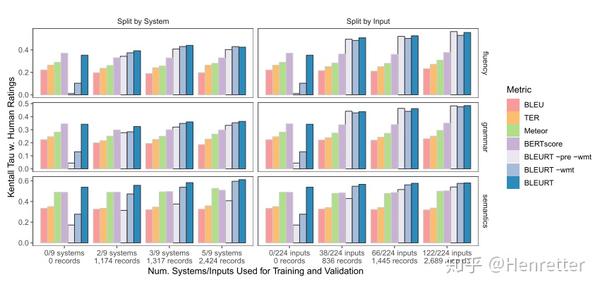
数据到文本生成实验
数据集:WebNLG Challenge 2017
评价标准:语义,语法,流畅度
模型:BLEURT-pre-wmt(BERT-large,无预训练),BLEURT-wmt(维基百科预训练+微调),BLEURT(维基百科预训练+WMT(16-18)+微调)
实验结果:得益于预培训过程,BLEURT能够快速地适应新的任务。进行了两次预训练(第一次使用维基百科合成数据,第二次使用WMT数据)的BLEURT,能够在缺乏训练数据的各类任务上提供可接受的结果。
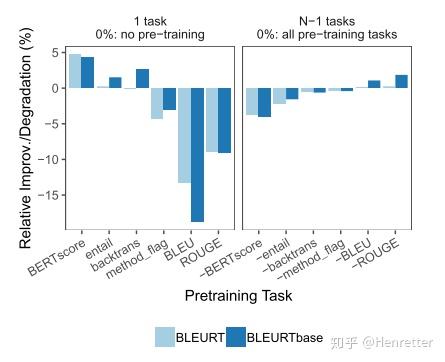
消融实验
实验结果:在高质量的指标上进行预训练有助于模型,在与人类判断相差较大的指标上进行预训练则会损害模型。
总结
文章提出了BLEURT,一种文本生成任务的评价方法。该指标需要端到端的训练,因此能够以更高的精度拟合人类评估方式。此外,预训练使得该方法对领域漂移和质量漂移有一定鲁棒性。未来的方向包括多语言NLG评估,以及探索人类评估与分类器相结合的方法。
BLEURT: Learning Robust Metrics for Text Generation
Abstract
在过去的几年中,文本生成取得了长足的进步。 但是,由于大多数热门的选择(例如BLEU和ROUGE)可能与人类判断的关联性较差,因此评估方法一直落后。 我们提出BLEURT,这是一种基于BERT的学习评估方法,可以通过数千个可能的训练实例来模拟人类的判断。 我们方法的一个关键方面是一种新颖的预训练方案,该方案使用了数百万个合成示例来帮助模型推广。 BLEURT提供了有关WMT Metrics共享任务和WebNLG Competition数据集最近三年的最新结果。 与基于vanillaBERT的方法相比,即使在训练数据稀少且分布不均的情况下,它也能提供出色的结果。
1 Introduction
在过去的几年中,自然文本生成(NLG)的研究取得了重大进展,这主要是由神经编码器/解码器范例(Sutskever等,2014; Bahdanau等,2015)推动的,它可以解决各种各样的问题。 任务包括翻译(Koehn,2009),摘要(Mani,1999; Chopra等,2016),结构化数据到文本生成(McKeown,1992; Kukich,1983; Wiseman等,2017)对话 (Smith and Hipp,1994; Vinyals and Le,2015)和图像字幕(Fang et al。,2015)。 但是,现有指标的缺点越来越阻碍了进步(Wiseman等人,2017; Ma等人,2019; Tian等人,2019)。人工评估通常是系统质量的最佳指标。 然而,设计众包实验是一个昂贵且高延迟的过程,它不容易适应日常的模型开发流程。 因此,NLG研究人员通常使用自动评估指标,这些指标可以提供可接受的质量指标,并且计算成本非常低廉。本文研究了句子级别的基于参考的度量标准,这些度量描述了候选句子与参考句子相似的程度。相似性的确切定义范围可以从字符串重叠到逻辑含义。
第一代度量标准依赖于手工制作的规则,用于测量句子之间的表面相似度。 为了说明这一点,两个流行的指标BLEU(Pa pineni等,2002)和ROUGE(Lin,2004)依赖于N-gram重叠。 因为这些度量标准仅对词汇变化敏感,所以它们不能适当地奖励给定参考的语义或句法变化。因此,它们被反复证明与人类判断的关联性很差,特别是当所有要比较的系统具有相似的准确性水平时(Liu等人,2016; Novikova等人,2017; Chaganty等人, 2018)。
NLG研究人员越来越多地通过将学习到的组件注入其度量标准来解决这些问题。 为了说明这一点,请考虑“ WMT指标共享任务”,这是一个年度基准,在该基准中,比较了翻译指标模仿人类评估的能力。 比赛的最后两年主要由基于神经网络的方法RUSE,YiSi和ESIM主导(Ma et al。,2018,2019)。 当前的方法主要分为两类。 诸如BEER,RUSE和ESIM之类的完全了解的标准都是经过端到端培训的,它们通常依赖于手工制作的功能和/或学习的嵌入。 相反,诸如YiSi和BERTscore之类的混合度量将训练后的元素(例如上下文嵌入)与手写逻辑(例如作为token对齐规则)结合在一起。 第一类通常具有出色的表达能力:如果有一组人类评级数据的训练集可用,则指标可能会充分利用它并紧密拟合评级分布。此外,可以调整学习的指标以测量特定于任务的属性,例如流利性,忠诚度,语法或风格。 另一方面,混合指标提供了鲁棒性。 当训练数据很少或没有训练数据时,它们可能会提供更好的结果,并且它们不依赖于训练数据和测试数据均分布的假设。
实际上,由于域漂移(这是度量标准文献的主要目标)以及质量漂移,因此IID假设在NLG评估中尤其成问题,还因为质量漂移:NLG系统往往会随着时间的流逝而变得更好,因此需要对模型进行训练 2015年的收视率数据可能无法区分2019年表现最佳的系统,尤其是对于较新的研究任务而言。 理想的学习指标既可以充分利用可用的评分数据进行训练,又可以对分布漂移具有鲁棒性,即应该能够推断出来。
我们的见解是,可以通过在大量人工数据上预先训练一个完全学习的指标,然后再根据人类评级对其进行微调,来将表达力和鲁棒性相结合。 为此,我们引入了BLEURT,这是一种基于BERT的文本生成指标(Devlin等,2019)。 BLEURT的一项关键指标是一种新颖的预训练方案,该方案使用维基百科句子的随机扰动,并辅以多种词汇和语义级别的监督信号。
为了证明我们的方法,我们训练了英语的BLEURT并在不同的生成方式下对其进行了评估。 我们首先验证它是否在WMT Metrics Shared Task的所有最新年份(2017年至2019年,英语对英语)中提供了最新的结果。 然后,我们使用基于WMT 2017的综合基准压力测试其应对质量漂移的能力。最后,我们证明了它可以轻松地通过数据到文本数据集中的三项任务来适应不同的工作领域, WebNLG 2017(Gardent等人,2017)。 消融表明,我们的综合预训练方案可提高IID设置的性能,并且在训练数据稀少,偏斜或超出范围时,对于确保鲁棒性至关重要。
代码和预先训练的模型可以在线获得。
2 Preliminaries
将x =(x1,..,xr)定义为长度r的参考句子,其中每个xi是一个记号,并让x〜=(〜x1,..,x〜p)是长度p的预测语句 。 令{{xi,x〜i,yi}} Nn = 1是大小为N的训练数据集,其中yi∈R是表示x〜i对xi有多好的人类评价。 给定训练数据,我们的目标是学习预测人类等级的函数f:(x,x〜)→y。
3 Fine-Tuning BERT for Quality Evaluation
考虑到可用的少量评估数据,很自然地利用无监督表示来完成此任务。 在我们的模型中,我们使用BERT(来自变压器的双向编码器表示)(Devlin等人,2019),这是一种无监督的技术,可学习文本序列的上下文表示。 给定x和x〜,BERT是一个Transformer(Vaswani et al。,2017),它返回上下文化向量的序列


其中W和b分别是权重矩阵和偏差向量。 上面的线性层以及BERT参数都经过训练(即 微调)(通常是几千个示例中的数字)。
我们使用回归损失![]()
尽管这种方法非常简单,但是我们将在第5节中展示它在WMT度量标准共享任务17-19中提供了最新的结果,这使其成为高性能的评估方法。 但是,对BERT进行微调需要大量IID数据,这对于应归纳到各种任务和模型漂移的度量标准而言并不理想。
4 Pre-Training on Synthetic Data
我们方法的关键方面是一种预训练技术,在对评级数据进行微调之前,我们使用该技术来“预热” BERT。数量的合成参考候选对(z,z〜),并且我们在具有多个任务损失的几个词法和语义级别的监督信号上训练BERT。 正如我们的实验将显示的那样,BLEURT在此阶段之后的泛化效果要好得多,尤其是在训练数据不完整的情况下。
任何预训练方法都需要数据集和一组预训练任务。 理想情况下,设置应类似于最终的NLG评估任务,即句子对应类似分配,并且训练前的信号应与人类评级相符。 不幸的是,我们无法访问将来将要评估的NLG模型。 因此,我们针对通用性优化了我们的方案,并提出了三个要求。
(1)参考句子的集合应大而多样,以使BLEURT能够应对各种NLG领域和任务。
(2)句子对应包含各种各样的词汇,句法和语义上的差异。 此处的目的是预期NLG系统可能产生的所有变化,例如,短语替换,复述,噪声或遗漏。
(3)训练前的目标应有效地捕捉到这些现象,以便BLEURT能够学会识别它们。 以下各节介绍了我们的方法。
4.1 Generating Sentence Pairs
使BLEURT暴露于多种句子差异的一种方法是使用现有的句子对数据集(Bowman等人,2015; Williams等人,2018; Wang等人,2019)。 这些集合是相关句子的丰富来源,但它们可能无法捕获NLG系统产生的错误和变更(例如,遗漏,重复,无意义的替换)。 相反,我们选择了一种自动方法,该方法可以任意扩展并且成本低廉:我们通过随机干扰Wikipedia的180万个细分z来生成合成句子对(z,z〜)。 我们使用三种技术:使用BERT填充掩码,反向翻译和随机删除单词。 我们获得大约650万个扰动z〜。 让我们描述这些技术。
4.2 Pre-Training Signals
下一步是使用一组预训练信号{τk}来增强每个句子对(z,z〜),其中τk是预训练任务k的目标向量。良好的预训练信号应捕获各种各样的词汇和语义差异。 它们也应该便宜获得,以便应用程序可以扩展到大量合成数据。 下一节介绍了我们的9个培训前任务,总结在表1中。其他实现细节在附录中。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践