
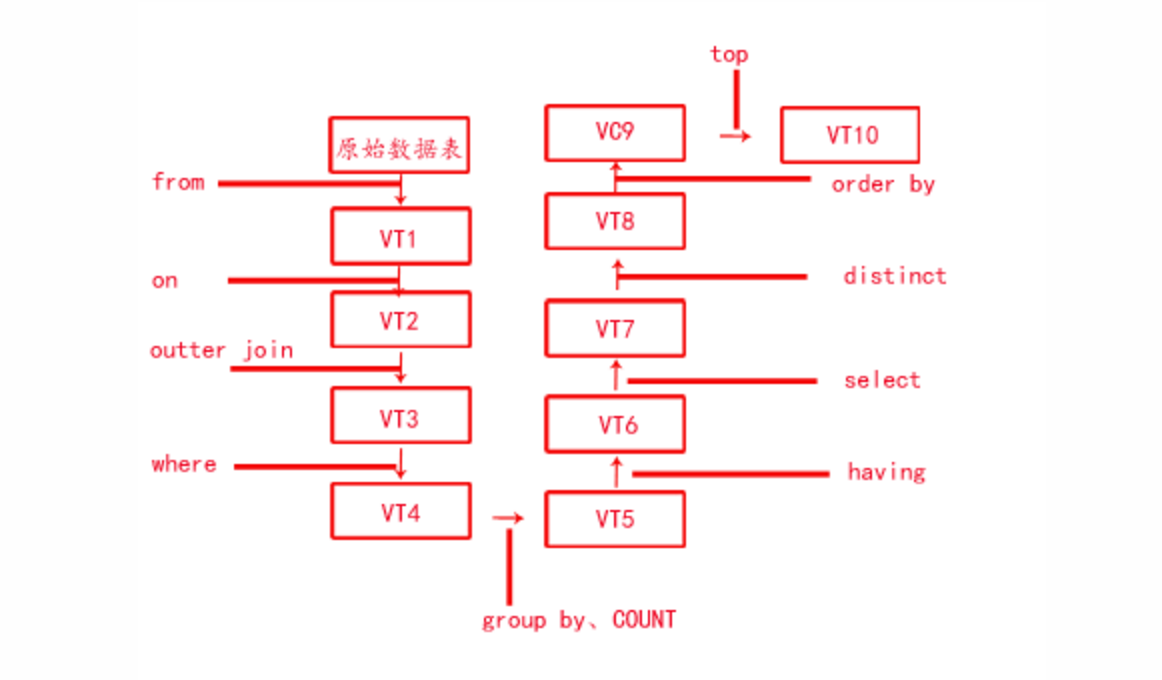
sql语句的执行顺序
今天思考on,where,having的执行顺序,联想到了整个sql语句的执行顺序。
sql语句的执行顺序为
(1) from
(2) on
(3) join
(4) where
(5) group by, count, sum, avg
(6) having
(7) select
(8) distinct
(9) order by
(10)limit
从这个顺序中我们可以看出所有的查询语句都是从from开始执行的,在执行过程中,每个步骤都会生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入表。
1. from后如果存在多张表,那么先取出前两张表,以行数较小的表为基础表,两张表执行笛卡尔积,生成结果表vtb1
2. 将on中的逻辑表达式将应用到vtb1上,以筛选出满足逻辑表达式的行,生成结果表vtb2
一般的sql编辑器都要求join和on搭配使用,因为如果没有on,将生成笛卡尔积。如果你就是想要笛卡尔积作为结果的话,那么on后的表达式可以写1=1这种恒等式,来绕过join,on必须搭配的限制
3. 如果使用的是outer join,那么就需要添加外部行,left outer jion将左表在第二步中过滤的行添加进来,反之将右表在第二步中过滤的行添加进来,生成虚拟表vtb3。
如果from后的表的数量大于2,那么将vtb3作为第一张表,继续重复执行前三步,得到最终的vtb3。
4. 将where中的逻辑表达式将应用到vtb3上,以筛选出满足逻辑表达式的行,生成结果表vtb4
5. 将group by后字段中的唯一的值组合成为一组,得到虚拟表vtb5。之后的count,sum,avg等聚合操作都是针对组的
6. 将having中的逻辑表达式将应用到vtb5上,以筛选出满足逻辑表达式的行,生成vtb6。(having筛选器是唯一应用到已分组数据的筛选器)
7. 将select的列从vtb6中筛选出来。生成vtb7
8. 依据distinct语句,将vtb7中相同的行移除,生成vtb8。如果使用了group by那么就无需使用distinct,因为group by的结果中所有的行都不相同
9. 按照order_by指定的列排序vtb8,生成vtb9。排序是很消耗资源的,除非对结果有顺序要求,否则建议不使用order by
10.根据top的列数返回给用户
在网上看到一张图片,可以直观的展示sql语句执行顺序,希望对大家有所帮助

 浙公网安备 33010602011771号
浙公网安备 33010602011771号