

信息论-Turbo码学习
1.Turbo码:
信道编码的初期:分组码实现编码,缺点有二:只有当码字全部接收才可以开始译码,需要精确的帧同步时延大,增益损失多
解决方案:卷积码:充分利用前一时刻和后一时刻的码组,延时小,缺点:计算复杂度高
Turbo码,依靠迭代译码解决计算复杂性问题,通过在编译码器中交织器和解交织器的使用,有效地实现随机性编译码的思想,通过短码的有效结合实现长码,达到了接近Shannon理论极限的性能(在两个分量译码器之间迭代译码)
缺点:时延问题。
百科结论:Turbo码采用反馈卷积码是为了获得更大的交织增益;Turbo码的性能主要取决于它的有效自由距离;Turbo码在低信噪比下具有近Shannon界纠错能力的原因;自由距离较低引起Turbo码在中信噪比下出现纠错平台现象等等。
在信噪比较低的高噪声环境下性能优越(信道条件差的移动通信系统中有很大的应用潜力),而且具有很强的抗衰落、抗干扰能力
Turbo码引起超乎寻常的优异译码性能,可以纠正高速率数据传输时发生的误码。在直扩(CDMA) 系统中采用Turbo 码技术可以进一步提高系统的容量。
在短帧情况下的仿真结果表明短交织Turbo码在AWGN信道和Rayleigh衰落下仍然具有接近信道容量的纠错能力
提出背景:在加性白高斯噪声的环境下, 采用编码效率R=1/2、交织长度为 65536的Turbo码,经过18次迭代译码后,在 Eb/N0=0.7dB时, 其误码率到达10-5,与香农极限只相差0.5dB。
2.Turbo码理解:
将两个简单分量码通过伪随机交织器并行级联来构造具有伪随机特性的长码,并通过在两个软入/软出(SISO)译码器之间进行多次迭代实现了伪随机译码。
交织:在实际应用中,比特差错经常成串发生,这是由于持续时间较长的衰落谷点会影响到几个连续的比特,而信道编码仅在检测和校正单个差错和不太长的差错串时才最有效(如RS只能纠正8个字节的错误)。
为了纠正这些成串发生的比特差错及一些突发错误,可以运用交织技术来分散这些误差,使长串的比特差错变成短串差错,从而可以用前向码对其纠错。
伪随机特性:频谱会因数据出现连“1”和连“0”而包含大的低频成分,不适应信道的传输特性,也不利于从中提取出时钟信息。解决办法之一是采用扰码技术,使信号受到随机化处理,变为伪随机序列
扰码不但能改善位定时的恢复质量,还可以使信号频谱平滑,使帧同步和自适应同步和自适应时域均衡等系统的性能得到改善。
3.Turbo码的编码结构:
三种:并行级联卷积码PCCC,串行级联卷积码SCCC,混合级联卷积码结构HCCC。
3.1并行级联卷积码结构:
是由两个反馈的系统卷积编码器通过一个交织器并行连接而成,编码后的校验位经过删余阵,从而产生不同的码率的码字。
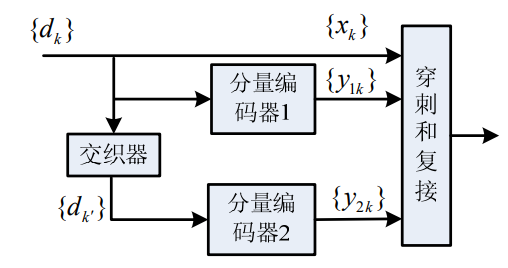
分量编码器:分量码的最佳选择是递归系统卷积码:
Turbo码编码器一般包括两个结构相同的递归系统卷积编码器和一个随机交织器。长度为N的信息序列u一方面直接进入第1个分量编码器RSC1,另一方面经过随机交织器处理后送入第2个分量编码器RSC2。随机交织器的处理是输入序号至输出序号的一映射,它的输出为长度相同,但比特位置经随机排列的交织序列。两个分量编码器RSC1和RSC2分别产生两个不同的校验比特序列x和x。为了提高Turbo码的码率,除可以选用高码率的分量码外,还可以采用打孔(Puncturing)技术从这两个校验序列中删除一些校验位,然后再与信息序列x复用在一起输出。
递归系统卷积码:BER性能在高信噪比好,高码率(R≥2/3)的情况下,对任何信噪比,它的性能均比等效的高码率(R≥2/3)的情况下,对任何信噪比它的性能均比等效的非系统卷积码NSC要好,
递归系统卷积码(RSC)不同于一般的卷积码器在于其结构中不仅有向前结构,还有向后反馈结构:
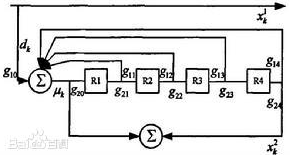
RSC 编码器一般有2-5 级移位寄存器,
Turbo 码在高信噪比下的性能主要由它的自由距离所决定。因为Turbo码的自由距离主要由重量为2的输入信息序列所产生的码字间的最小距离所决定,用本原多项式作为反馈连接多项式的分量编码器所产生的码字的最小重量为最大,因此当Turbo码交织器的大小给定后,如果分量码的反馈连接多项式采用本原多项式,则Turbo码的自由距离会增加,从而Turbo码在高斯信噪比情况下的“错误平层(errorfloor)”会降低。错误平层效应指的是在中高信噪比情况下,误码曲线变平。
3.2交织器的设计
作用:可以使得Turbo码的距离谱细化,即码重分布更为集中。
交织器实际上是一个一一映射函数,作用是将输入信息序列中的比特位置进行重置,以减小分量编码器输出校验序列的相关性和提高码重。通常在输入信息序列较长时可以采用近似随机的映射方式,相应的交织器称为伪随机交织器。
交织:交织是对信息序列加以重新排列的一个过程。如果定义一个集合A , A={1,2,…,N}。则交织器可以定义为一个一一对应的映射函数π(A-->A):J=π(i),(i,j属于A) 这里的i ,j 分别是未交织序列C 和交织序列C' 中的元素标号。映射函数可以表示为πN = (π⑴,π⑵,π⑶,…,π(N))。
有三原则:
最大程度的置乱原来的数据排列顺序,避免置换前相距较近的数据在置换后仍然相距较近,特别是要避免相邻的数据在置换后仍然相邻
尽量提高最小码重码字的重量和减小低码重码字的数量;尽可能避免与同一信息位直接相关的两个分量编码器中的校验位均被删除
对于不归零的编码器,交织器设计时要避兔出现"尾效应" 图案。
交织器和分量码的结合可以确保Turbo码编码输出码字都具有较高的汉明重量。在Turbo编码器中交织器的作用是将信息序列中的比特顺序重置。当信息序列经过第一个分量编码器后输出的码字重量较低时,交织器可以使交织后的信息序列经过第二个分量编码器编码后以很大的概率输出较高重码字,从而提高码字的汉明重量:同时好的交织器还可以奇效地降低校验序列间的相关性
内置交织器:
Turbo码内置的交织器是在第2个分量编码器RSC2编码处理之前将信息序列的N个比特的位置进行随机排列,它起着关键的作用,很大程度上影响着Turbo码的性能。通过随机交织,使得编码由简单的短码得到了近似长码。当交织器充分大时,Turbo码就具有近似于随机长码的特性。
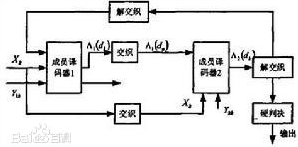
4.迭代译码
Turbo码译码器采用迭代译码方法,其中使用两个分量译码器,并在第一分量译码器与第二分量译码器之间传递软译码信息,如图3-35所示。无冲突交织器支持并行译码的主要原理是:在进行迭代译码时,第一分量译码器将信息序列进行分段,每个分段使用单独的一个专用的译码处理单元独立地进行译码,各分段译码过程可以并行进行,提高译码速度。但是第二分量译码器也需要采用相同的、并行的分段译码方法,这就要求第二分量译码器的每个独立专用的译码处理单元同一时刻访问不同的分段,这样才能避免信息序列分段地访问冲突,从而实现第二分量译码器的并行分段译码,提高整个迭代译码的速度。
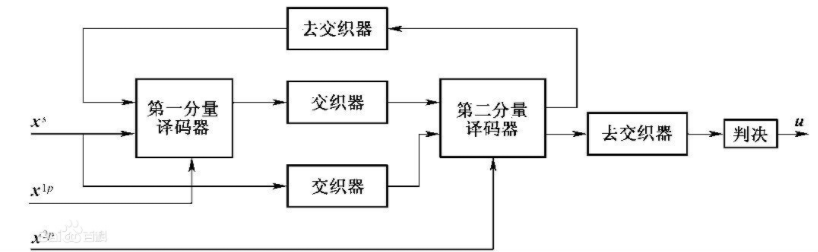
图3-36所示为无冲突交织器的示意图,4个窗口(Windows)A、B、C、D分别代表独立的分段译码,它们需要通过交织器获取各自的原始数据,此时4个窗口A、B、C、D在读取原始数据时,不会出现在同一时刻访问同一分段,不会发生资源访问冲突的问题,这样保证了4个窗口A、B、C、D可以并行地分段译码。

5.译码原理
Turbo码的译码算法采用了最大后验概率算法:译码时首先对接收信息进行处理,两个成员译码器之间外部信息的传递就形成了一个循环迭代的结构。由于外部信息的作用,一定信噪比下的误比特率将随着循环次数的增加而降低。但同时外部信息与接受序列间的相关性也随着译码次数的增加而逐渐增加,外部信息所提供的纠错能力也随之减弱,在一定的循环次数之后,译码性能将不再提高。
在译码的结构上又做了改进,再次引入反馈的概念,取得了性能和复杂度之间的折衷。
译码算法:MAP-Log-MAP算法、Max-Log-MAP以及软输入软输出(SOVA)算法。
5.1译码算法
软输入软输出的译码算法。软输出译码器的输出不仅应包含硬判决值
标准MAP算法
Log-MAP算法
Max-Log-MAP算法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具