
taptap关于王者荣耀评论的爬虫与数据可视化
背景
玩家评论可以为游戏的版本迭代提供重要参考,假如可以快速定位玩家的负面评价,则能够节约收集意见的时间成本。本项目通过文本挖掘方法,展示从数据采集到情感模型评价的全过程。
一、爬虫
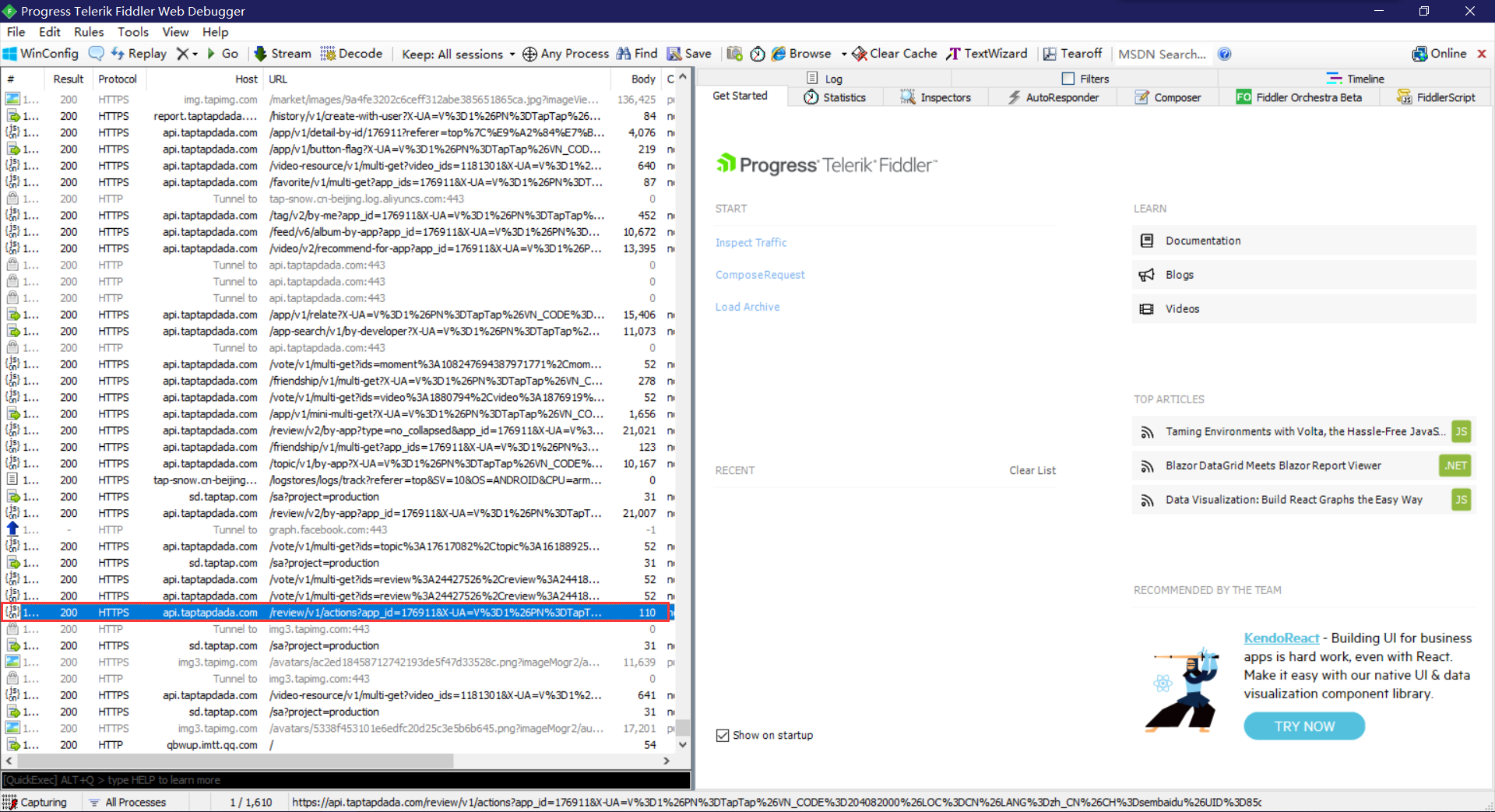
TAPTAP评论数据通过JSON返回,使用python中的Requests库非常容易就可以提取里面的内容。下面这幅图是Fiddler抓包时看到的数据:
运行环境
请在python环境下运行,本次程序的开发环境为python 3.8.1
基本功能
这个程序根据你提供的游戏id,按评论最近更新时间,自动抓取每条完整的游戏评论和它的关联信息,存放到csv文件中。
- 前置准备: 如果你将csv文件的保存路径设置在C盘,最好手动建立路径,否则可能会出现premission dennied,抓取的数据保存不成功
- 爬虫运行: 最大抓取页数为990页,由于taptap的设置,单个游戏在990以后的评论数据无法访问。爬取过程中出错,重新运行程序,程序会自动在断点位置续爬
- 爬虫结束: 达到上限,程序报页面无法打开,数据已在csv文件中保存
抓包获取游戏id
-
因为fiddler抓包的原理就是通过代理,所以被测终端需要和安装fiddler的电脑在同一个局域网中。
-
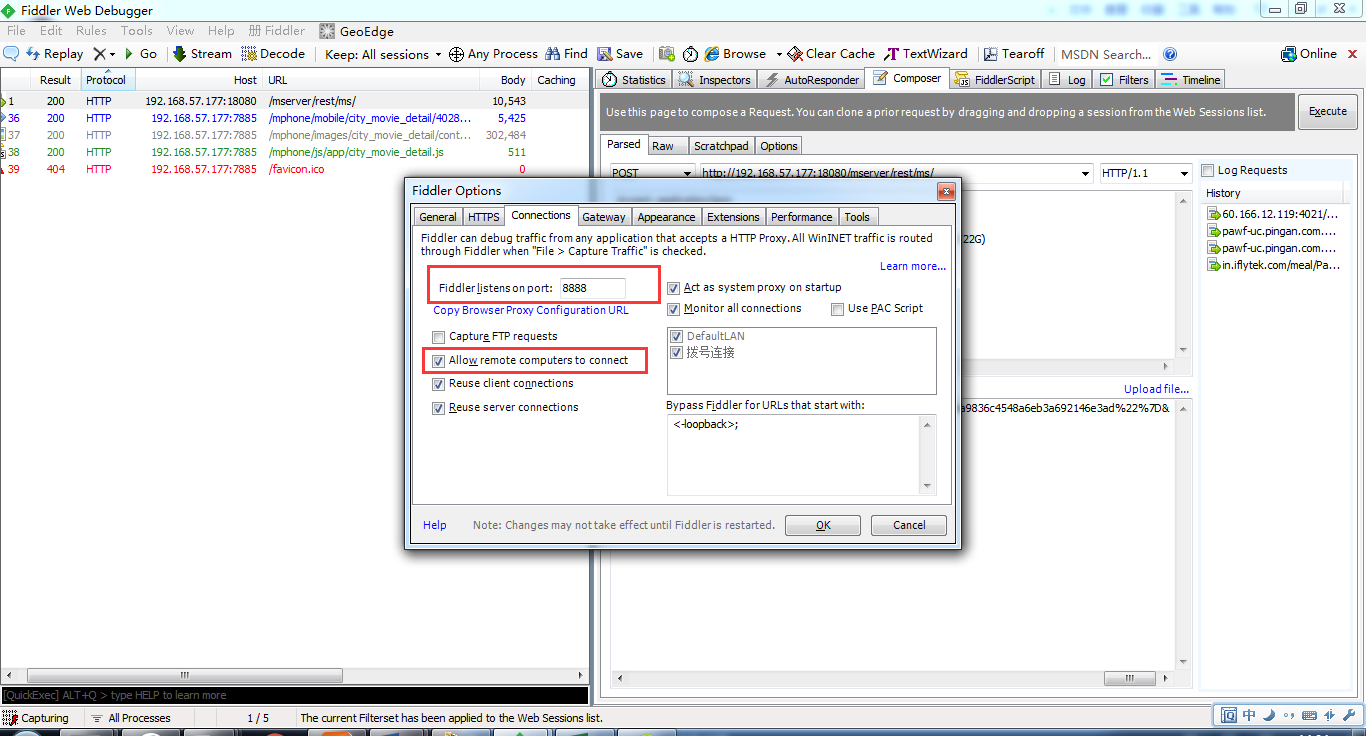
开启Fiddler的远程连接,Fiddler 主菜单 Tools -> Fiddler Options…-> Connections页签,选中Allowremote computers to connect,并记住端口号为8888,等会设置手机代理时需要。设置好后重启fiddler保证设置生效。设置如下:
-
查看电脑IP,在CMD中输入ipconfig或者直接在开热点设备上查看连接设备的ip。
-
在手机侧设置代理
设置-WLAN,找到连接的wifi-选择修改网络-勾选高级选项,选择代理为手动,填入代理服务器为自己电脑IP,端口填入刚刚记住的8888。iPhone则可以在对应wifi的设置中直接配置HTTP代理。
- 开始抓包
在手机上对APP进行操作,从fiddler上即可看到对应的网络请求信息与游戏id。
断点续传
建立断点txt文件,在因网络等原因中断时,重启程序,可以在断点处续爬,在中断时,已缓存的数据将保存至csv
def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from
爬虫休眠
文明爬虫,虽未发现反爬,但爬完每个页面后暂停0-2秒,减轻服务器负担
import random
import time
pause = random.uniform(0, 2)
time.sleep(pause)
编码转换
python中比较容易出现编码问题,在中文环境下更甚,评论里可能会有无法打印的字符,虽然不影响数据下载,但容易影响后续处理。先把数据进行gbk编码,丢弃无法识别的字符,再进行解码,最后将数据保存为utf-8格式,上面的问题就不存在啦~
review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')
其他信息:
每页10条数据,每个游戏的评论最多可爬990页,超过990页,TAPTAP拒绝访问。
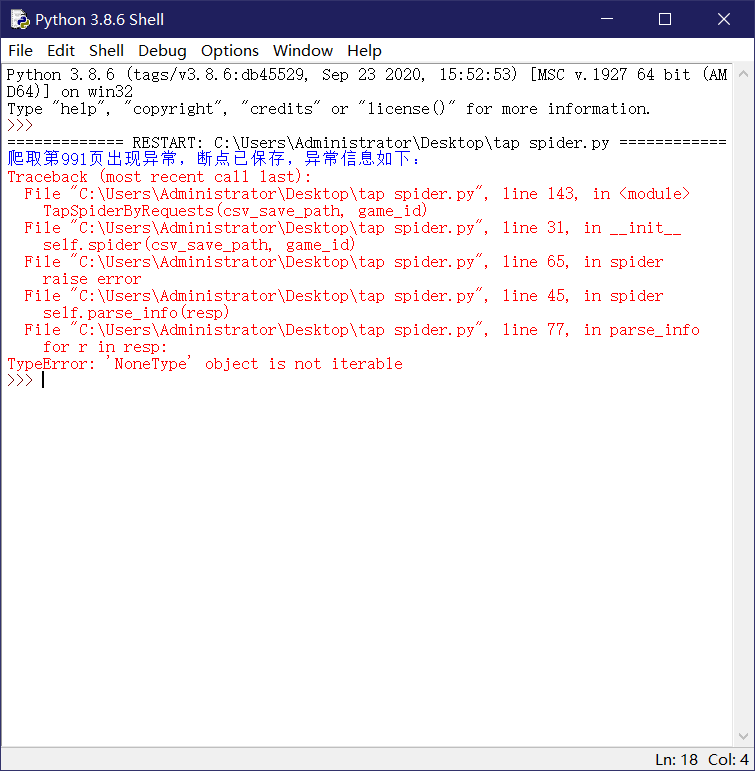
程序将采集到的数据存放至你指定路径的csv中。
爬虫完整代码
import requests
import os
import re
import random
import time
import csv
# 请求头
HEADERS = {'Host': 'api.taptapdada.com',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.10.0'}
# 基础页面 每个页面有10条评论,'from'参数表示评论序号,从0开始,每+10翻页一次
BASE_URL = 'https://api.taptapdada.com/review/v1/by-app?sort=new&app_id={}' \
'&X-UA=V%3D1%26PN%3DTapTap%26VN_CODE%3D593%26LOC%3DCN%26LANG%3Dzh_CN%26CH%3Ddefault' \
'%26UID%3D8a5b2b39-ad33-40f3-8634-eef5dcba01e4%26VID%3D7595643&from={}'
# 保存断点的文件
STOP_POINT_FILE = 'stop_point.txt'
class TapSpiderByRequests:
def __init__(self, csv_save_path, game_id):
"""
获取断点,激活爬虫
"""
# 获取断点
self.start_from = self.resume()
# 重置保存评论的列表
self.reviews = []
# 运行爬虫
self.spider(csv_save_path, game_id)
def spider(self, csv_save_path, game_id):
"""
发送请求,验证访问状态
:return: 网页返回的json数据
"""
end_from = self.start_from + 300
# 循环爬取30页
for i in range(self.start_from, end_from+1, 10):
url = BASE_URL.format(game_id, i)
try:
resp = requests.get(url, headers=HEADERS).json()
resp = resp.get('data').get('list')
self.parse_info(resp)
print('=============已爬取第 %d 页=============' % int(i/10))
# 等待0至2秒,爬下一页
if i != end_from:
print('爬虫等待中...')
pause = random.uniform(0, 2)
time.sleep(pause)
print('等待完成,准备翻页。')
# 顺利爬至末页,则保存断点
else:
with open(STOP_POINT_FILE, 'w') as f:
f.write(str(i+10))
# 出错,则中断爬虫,保存断点
except Exception as error:
with open(STOP_POINT_FILE, 'w') as f:
f.write(str(i))
# 打印异常信息
print('爬取第%i页出现异常,断点已保存,异常信息如下:' % int(i/10))
raise error
# 退出程序
exit()
# 将信息写入csv
self.write_csv(csv_save_path, self.reviews)
def parse_info(self, resp):
"""
:param resp: 本页返回的json数据
:return: 将本页评论信息追加至REVIEWS列表
"""
for r in resp:
review = {}
# id
review['id'] = r.get('id')
# 昵称
review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')
# 评论时间
review['updated_time'] = r.get('updated_time')
# 设备
review['device'] = r.get('device').encode('gbk', 'ignore').decode('gbk')
# 游玩时长(分钟)
review['spent'] = r.get('spent')
# 打分
review['stars'] = r.get('score')
# 评论内容
content = r.get('contents').get('text').strip()
review['contents'] = re.sub('<br />| ', '', content).encode('gbk', 'ignore').decode('gbk')
# 支持度
review['ups'] = r.get('ups')
# 不支持度
review['downs'] = r.get('downs')
self.reviews.append(review)
# 断点续传
def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from
# 追加写入csv
def write_csv(self, full_path, reviews):
"""
:param full_path: csv保存的完整路径
:param reviews: 列表形式的评论信息
"""
title = reviews[0].keys()
path, file_name = os.path.split(full_path)
if os.path.exists(full_path):
with open(full_path, 'a+', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, title)
writer.writerows(reviews)
else:
try:
os.mkdir(path)
except Exception:
print('路径已存在,或未获得建立路径的权限。请检查路径是否存在,或手动建立路径。')
with open(full_path, 'a+', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, title)
writer.writeheader()
writer.writerows(reviews)
if __name__ == '__main__':
# csv保存路径
csv_save_path = r'.\data\tap_reviews.csv'
# 游戏id 王者荣耀:2301;和平精英:70056;原神:168332~更多可以抓包获取
game_id = 2301
# 循环爬取至990页
for i in range(33):
TapSpiderByRequests(csv_save_path, game_id)
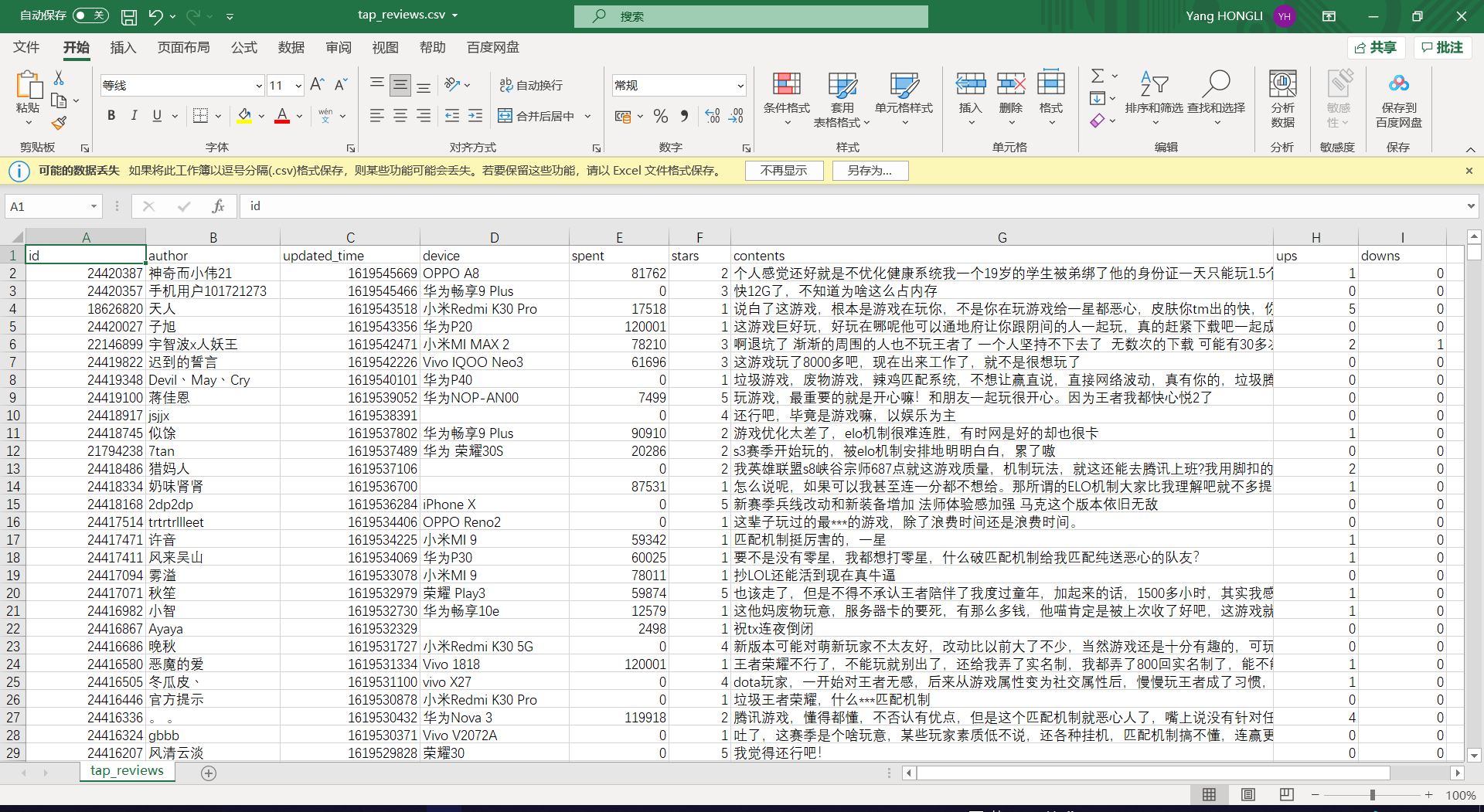
爬虫数据文档
二、数据清洗
这一步主要为数据可视化服务,使用pandas库可以很方便地进行数据清洗。
新增列
评论热度
点赞数和点踩数的总和,进行归一化表示
data['heat'] = data['ups'] + data['downs']
data['heat'] = (data['heat'] - data['heat'].min()) / (data['heat'].max() - data['heat'].min())
评分
评论标星的2倍,标星范围1-5,评分范围2-10
data['score'] = data['stars']*2
评论净支持数
data['net_support'] = data['ups'] - data['downs']
转换
时间戳转换日期
为了让pyecharts识别出时间标签,需要进行日期转换
import time
data['updated_time'] = data['updated_time'].apply(lambda x: time.strftime('%Y-%m-%d', time.localtime(x)))
替换
替换游玩时间中的0值:
实际情况下,玩家不太可能在未游玩的情况下评论(或者说这些评论意义不大),将游玩时间0替换为缺失是合理的,当进行相关维度的可视化,这些缺失值将不会被考虑
data['spent'] = data['spent'].replace(0, np.nan)
删除
用正则表达式删除无意义字符
一些同学发评论比较喜欢用颜表情,但在爬虫过程中,gbk编码下无法全部显示,只能删掉意义不明的那另一半
import re
data['contents'] = data['contents'].apply(lambda x: re.sub('&[\w]+;', '', str(x)))
data['contents'] = data['contents'].apply(lambda x: re.sub('\(\s*\)', '', str(x)))
删除无意义的列数据
import pandas as pd
data.drop(['ups', 'downs'], axis=1, inplace=True)
清洗完整代码
# coding=gbk
import pandas as pd
import time
import re
import numpy as np
# 爬虫获取的数据的所在路径
csv_path = r'.\data\tap_reviews.csv'
# 清洗后的数据的保存路径
clean_path = r'.\data\tap_reviews-extend cleaned.csv'
# 读取数据
data = pd.read_csv(csv_path, header=0, index_col='id')
# # 查看前20条数据和列名
# print(data[:20])
# print(data.columns)
# 将评论时间由时间戳转日期
data['updated_time'] = data['updated_time'].apply(lambda x: time.strftime('%Y-%m-%d', time.localtime(x)))
# 评论净支持数
data['net_support'] = data['ups'] - data['downs']
# 评论热度
data['heat'] = data['ups'] + data['downs']
data['heat'] = (data['heat'] - data['heat'].min()) / (data['heat'].max() - data['heat'].min())
# 评分
data['score'] = data['stars']*2
# 将游玩时间为0的标注为缺失值
data['spent'] = data['spent'].replace(0, np.nan)
# 清除无意义字符
data['contents'] = data['contents'].apply(lambda x: re.sub('&[\w]+;', '', str(x)))
data['contents'] = data['contents'].apply(lambda x: re.sub('\(\s*\)', '', str(x)))
# 删除用不上的列
data.drop(['ups', 'downs'], axis=1, inplace=True)
# 保存数据,转换成utf-8编码
data.to_csv(clean_path, encoding='utf_8_sig')
清洗后数据文档
三、可视化
查看数据分布情况,通过对评论的长度分析,利用星级评论情感分布分析,一定程度上查看玩家对游戏整体的满意度。
从时间、设备、玩家印象维度可视化评论数据,这一步使用pyecharts库。pyecharts库是python生成Eharts图表的轮子,官方文档中就有 丰富的图表实例。颜值高,上手容易,入股不亏。
查看数据分布情况
查看评论长度分布
data['contents_length'] = data['contents'].apply(lambda x: len(str(x)))
len_se = data.groupby('contents_length')['contents_length'].count()
sns.distplot(len_se, bins=20, hist=True, kde=True, rug=True)
plt.title('taptap评论长度分布')
plt.show()
print('评论长度的9/10分位数:', data['contents_length'].quantile(0.9))
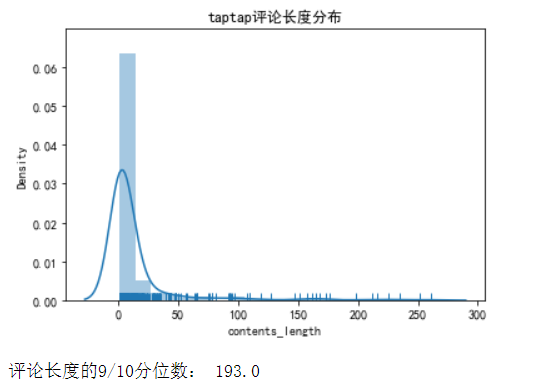
计算分位数发现,90%评论在193字内;密度图表明,评论长度集中在100字以内
查看评论情感分布
positive = len(data['stars'][data['stars'] >= 4])
total = len(data['stars'])
negative = total - positive
sns.distplot(data['stars'], bins=5, kde=False, norm_hist=True)
plt.title('taptap评论情感分布')
plt.show()
print('正面评价: %d,占总数的%.2f%% 负面评价: %d, 占总数的%.2f%%' %
(positive, (positive/total*100), negative, (negative/total*100)))
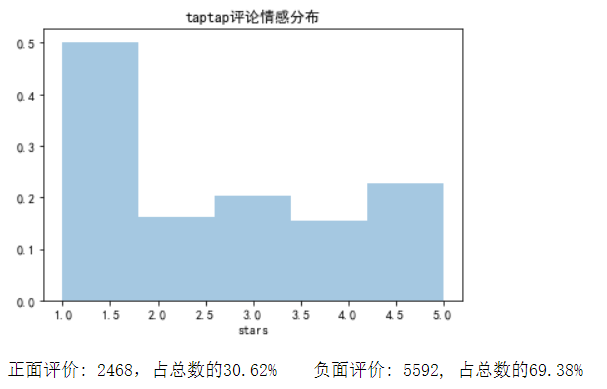
正面评价: 2468,占总数的30.62% ;负面评价: 5592, 占总数的69.38%。
时间维度的考察
王者荣耀每日评分均值变化
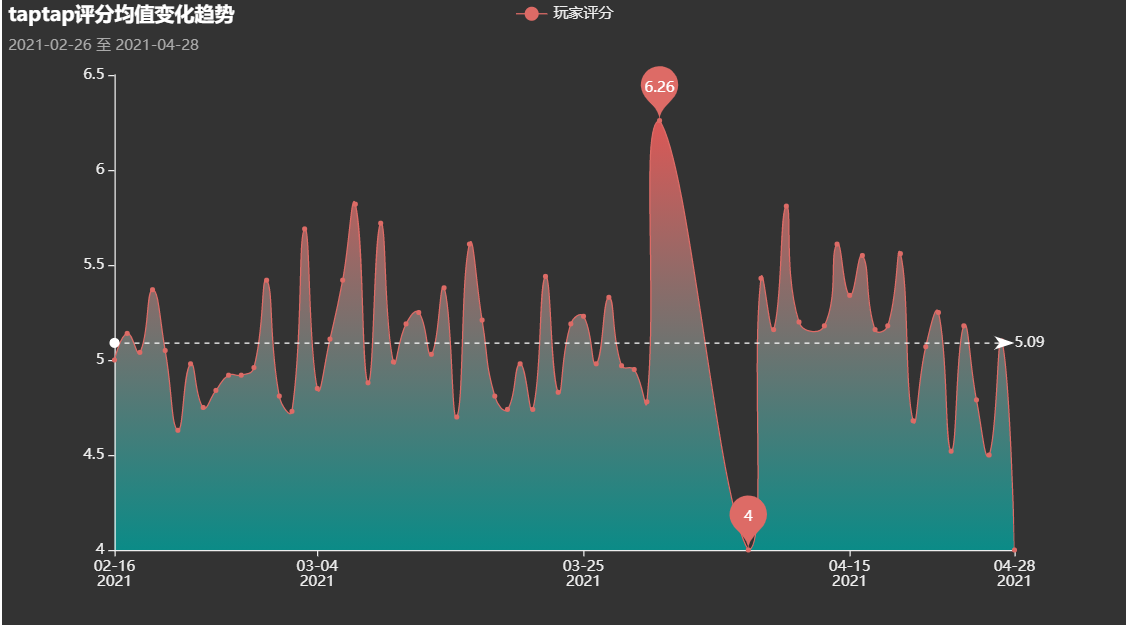
王者荣耀每日评分次数
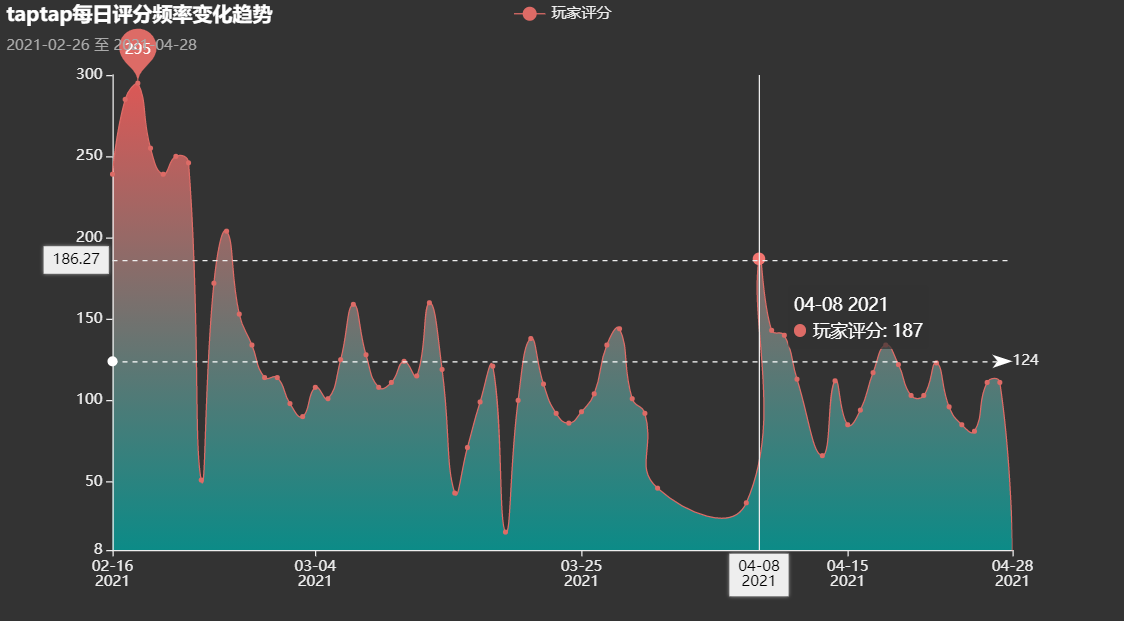
归因:04.08赛季更新

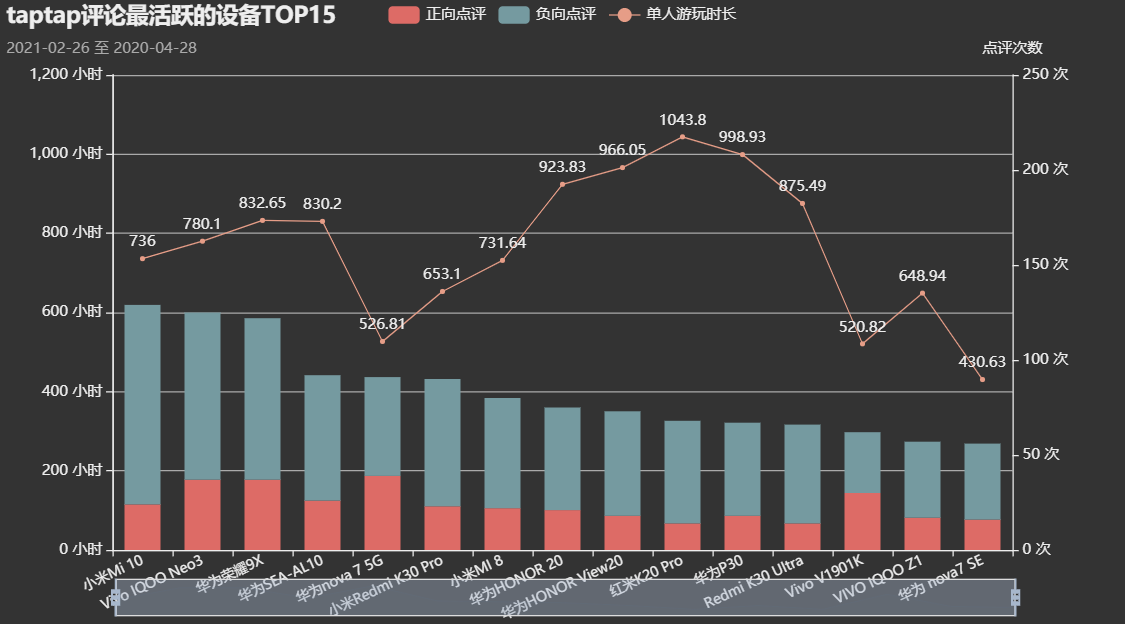
设备维度的考察
评论活跃设备Top15
评分较低设备Top10
玩家印象
使用文本挖掘的预处理方法对TOP500支持度和热度达到0.5的评论进行处理,得到了玩家对这个游戏的关键评价

可视化完整代码
四、后记
对游戏的评价星数并不能真实的反映每个玩家对游戏的感情态度,因此我们还需要对评论数据进行数据挖掘、建立LSTM模型并对模型进行评价。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?