
Class7 LM作业-基于srilm的语言模型训练
零、SRILM安装与使用
一、准备
srilm是一个语言模型训练工具,SRILM的主要目标是支持语言模型的估计和评测。估计是从训练数据(训练集)中得到一个模型,包括最大似然估计及相应的平滑算法;而评测则是从测试集中计算其困惑度。其最基础和最核心的模块是n-gram模块,这也是最早实现的模块,包括两个工 具:ngram-count和ngram,相应的被用来估计语言模型和计算语言模型的困惑度。
在训练模型之前需要对文本数据进行处理,得到分好词的文本数据。
同时,我们还需要准备一个词典lexicon.txt,大家可以自行建立自己的词典或者获取其他已经建立好的词典作为lexicon。词典在这里的作用是我们在训练模型之前需要对文本数据中出现的词进行一个统计。统计每一个词在文本中出现的频率。
然后我们还需要测试数据集,我们需要准备一些测试数据集用于测试我们训练的模型性能。
二、词频统计
在得到了分好词的文本后,需要对文本中的每个词进行一个词频统计,具体的步骤如下:
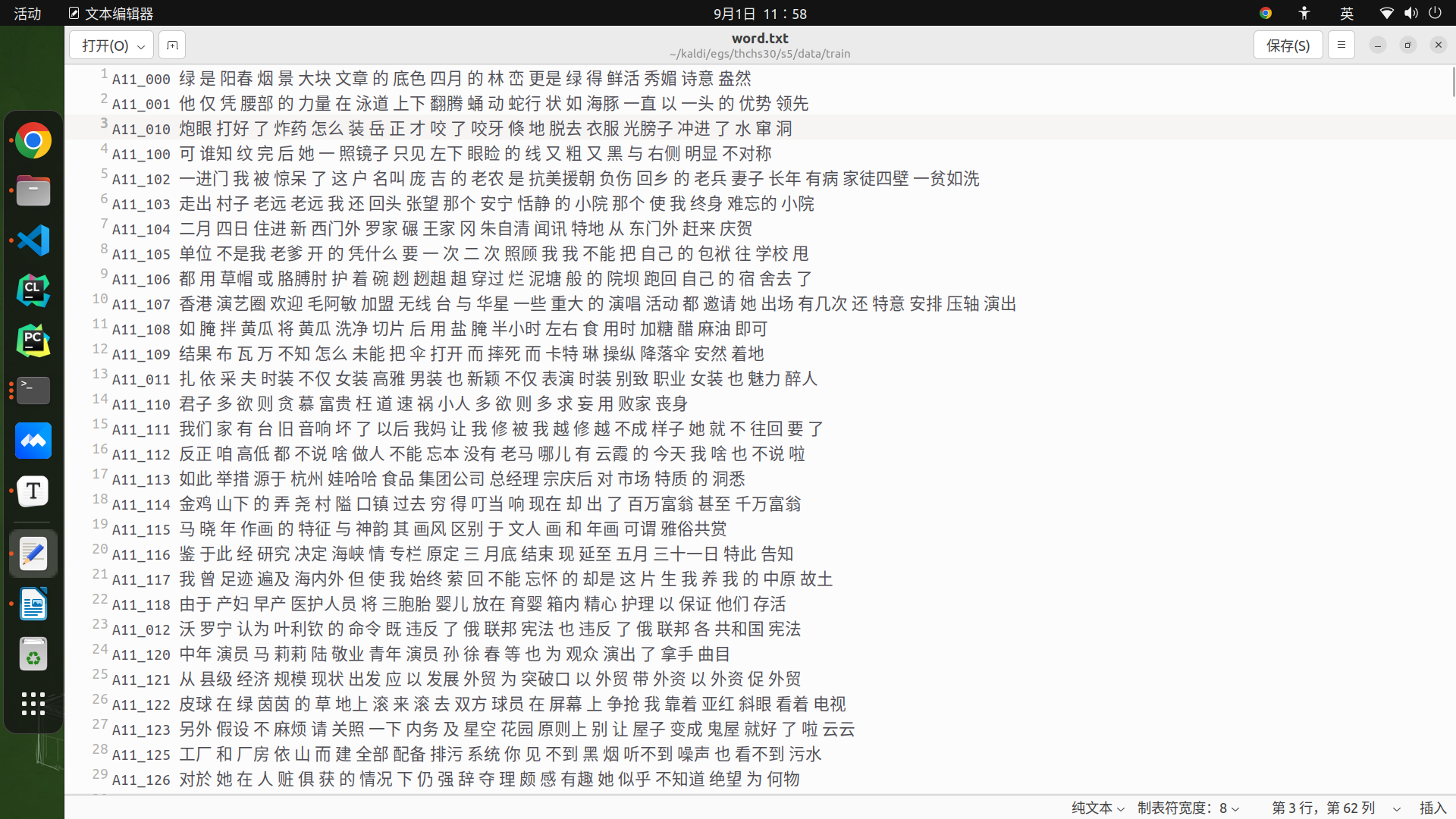
1.处理输入文本:将输入文本(分好词)中没有出现在lexicon中的词替换成,然后生成文件text.no_oov。生成的文本大概如下图。
实现这一步所需要的shell代码:$text代表我们的文本数据的路径,$lexicon是词典的路径。
cat $text | awk -v lex=$lexicon 'BEGIN{while((getline<lex) >0){ seen[$1]=1; } }
{for(n=1; n<=NF;n++) { if (seen[$n]) { printf("%s ", $n); } else {printf("<UNK> ");} } printf("\n");}' > $cleantext || exit 1;
2.统计text.no_oov (cleantxt)中出现的词的词频并按词频降序排列,生成word.counts。结果如下图:
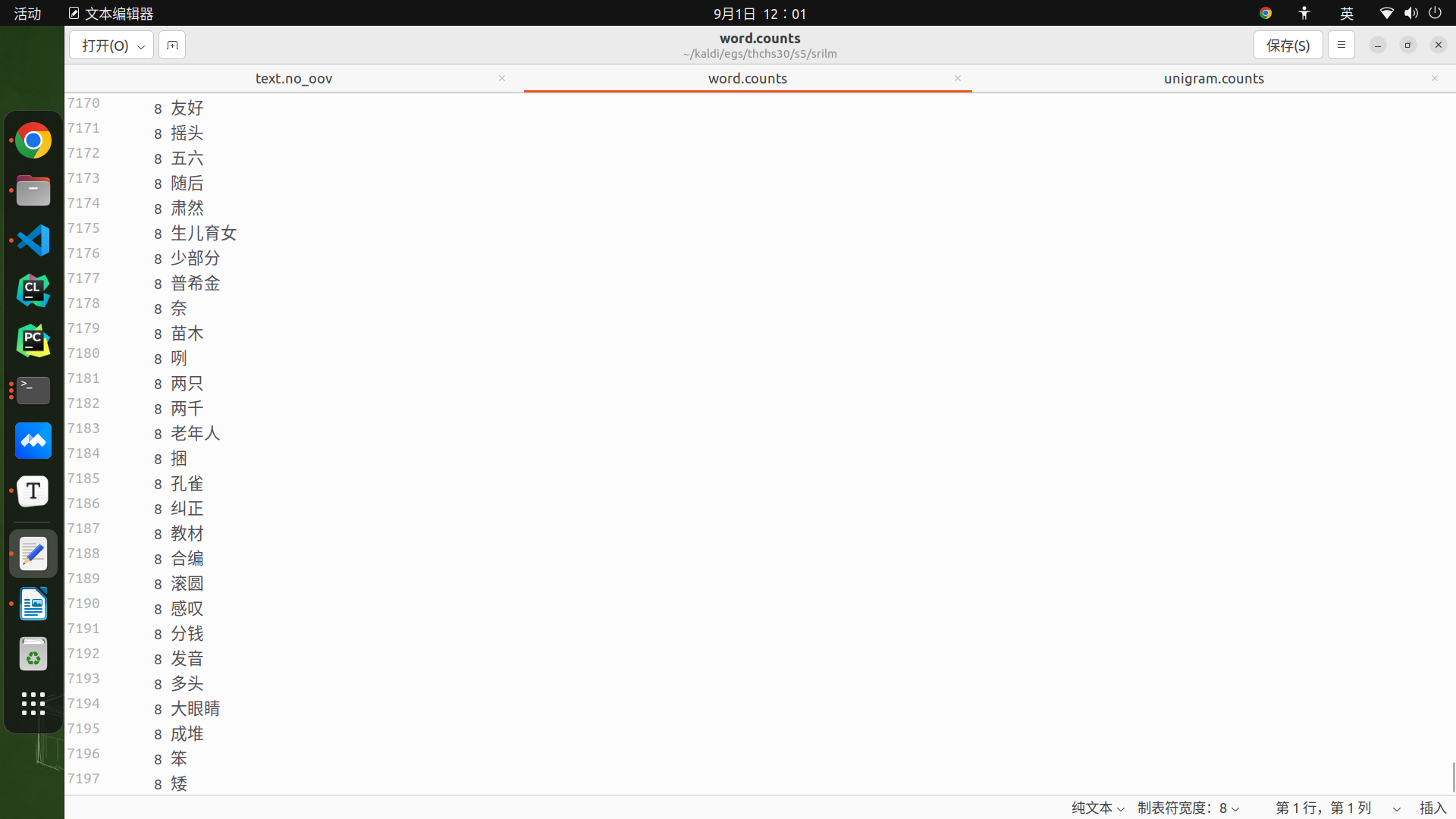
从图中可以看到第一列为我们的词频,第二列为文本中所有出现过的词。都已经按照降序排好顺序了。代码如下,这步我指定了一个临时文件夹$tmp, 用于存储中间过程的临时文件,使用之前需要创建。
cat $cleantext | awk '{for(n=1;n<=NF;n++) print $n; }' | sort -T $tmp | uniq -c | sort -T $tmp -nr > $dir/word.counts || exit 1;
3.把text.no_oov(cleantext)中的所有词和lexicon中的非静音词合并,统计词频,按照词频降序排列,生成unigram.counts。

cat $cleantext | awk '{for(n=1;n<=NF;n++) print $n; }' | cat - <(grep -w -v '!SIL' $lexicon | awk '{print $1}') | sort -T $tmp | uniq -c | sort -nr > $dir/unigram.counts || exit 1;
4.用kaldi/tools/kaldi_lm中的get_word_map.pl工具将unigram.counts中的词改成一种简短的形式,生成word_map
cat $dir/unigram.counts | awk '{print $2}' | kaldi/tools/kaldi_lm/get_word_map.pl "<s>" "</s>" "<UNK>" > $dir/word_map || exit 1;
至此我们就得到了word_map,可以用它来进行ngram语言模型的训练了。
代码
#!/usr/bin/env bash
text=./data/train/word.txt
lexicon=./data/train/lexicon.txt
dir=srilm
mkdir $dir
cleantext=$dir/text.no_oov
cat $text | awk -v lex=$lexicon 'BEGIN{while((getline<lex) >0){ seen[$1]=1; } }
{for(n=1; n<=NF;n++) { if (seen[$n]) { printf("%s ", $n); } else {printf("<UNK> ");} } printf("\n");}' > $cleantext || exit 1;
cat $cleantext | awk '{for(n=2;n<=NF;n++) print $n; }' | sort | uniq -c | sort -nr > $dir/word.counts || exit 1;
cat $cleantext | awk '{for(n=2;n<=NF;n++) print $n; }' | \
cat - <(grep -w -v '!SIL' $lexicon | awk '{print $1}') | \
sort | uniq -c | sort -nr > $dir/unigram.counts || exit 1;
cat $dir/unigram.counts | awk '{print $2}' | get_word_map.pl "<s>" "</s>" "<UNK>" > $dir/word_map || exit 1;
cat $cleantext | awk -v wmap=$dir/word_map 'BEGIN{while((getline<wmap)>0)map[$1]=$2;}
{ for(n=2;n<=NF;n++) { printf map[$n]; if(n<NF){ printf " "; } else { print ""; }}}' | gzip -c >$dir/train.gz \
|| exit 1;
三、训练
详情代码见github:https://github.com/baixf-xyz/ASR_work/tree/master/07-LM
在针对小文本数据量的语言模型训练中,我们可以直接调用srilm中的n-gram-count工具进行训练,但针对大数据量文本数据进行训练时,可能会造成内存溢出的问题,所以针对这个问题,srilm工具箱同时集成了另一个工具make-big-lm,它可以达到把文本数据分块进行处理的功能,节省了内存空间提升了训练效率。
ngram-count
##功能
#读取分词后的text文件或者count文件,然后用来输出最后汇总的count文件或者语言模型
##参数
#输入文本:
# -read 读取count文件
# -text 读取分词后的文本文件
#词典文件:
# -vocab 限制text和count文件的单词,没有出现在词典的单词替换为<unk>;
# 如果没有加该选项,所有的单词将会被自动加入词典
# -limit-vocab 只限制count文件的单词(对text文件无效);
# 没有出现在词典里面的count将会被丢弃
# -write-vocab 输出词典
#语言模型:
# -lm 输出语言模型
# -write-binary-lm 输出二进制的语言模型
# -sort 输出语言模型gram排序
ngram
##功能
#用于评估语言模型的好坏,或者是计算特定句子的得分,用于语音识别的识别结果分析。
##参数
#计算得分:
# -order 模型阶数,默认使用3阶
# -lm 使用的语言模型
# -ppl 后跟需要打分的句子(一行一句,已经分词),ppl表示所有单词,ppl1表示除了</s>以外的单词
# -debug 0 只输出整体情况
# -debug 1 具体到句子
# -debug 2 具体每个词的概率
#产生句子:
# -gen 产生句子的个数
# -seed 产生句子用到的random seed
ngram -lm ${lm} -order 3 -ppl ${file} -debug 1 > ${ppl}
运行THCHS30的kaldi 代码,在数据准备阶段,data/train 和 test文件夹中会生成 word.txt 文件,去除第一列 id 标识,使用train作LM model的计数和训练文件,Test做测试。
- 问题1:使用SRILM 获得经过 interpolation 式的 Kneser Ney 平滑的 3gram 以上的语言模型执行
共有两种训练方法:
- 训练文本 ——> count文件 ——> lm模型
- 训练文本——> lm模型
#计数功能——生成计数文件
ngram-count -text -order 3 newtrainword.txt -limit-vocab lexicon.txt -no-sos -no-eos -write trainword.text.count –debug 1
#从计数文件构建语言模型
ngram-count -read trainword.text.count -order 3 -lm LM_train -interpolate –kndiscount –debug 1
#直接结合上面两步,接利用训练语料构建语言模型
ngram-count -text newtrainword.txt -order 3 -lm train.lm -interpolate –kndiscount –debug 1
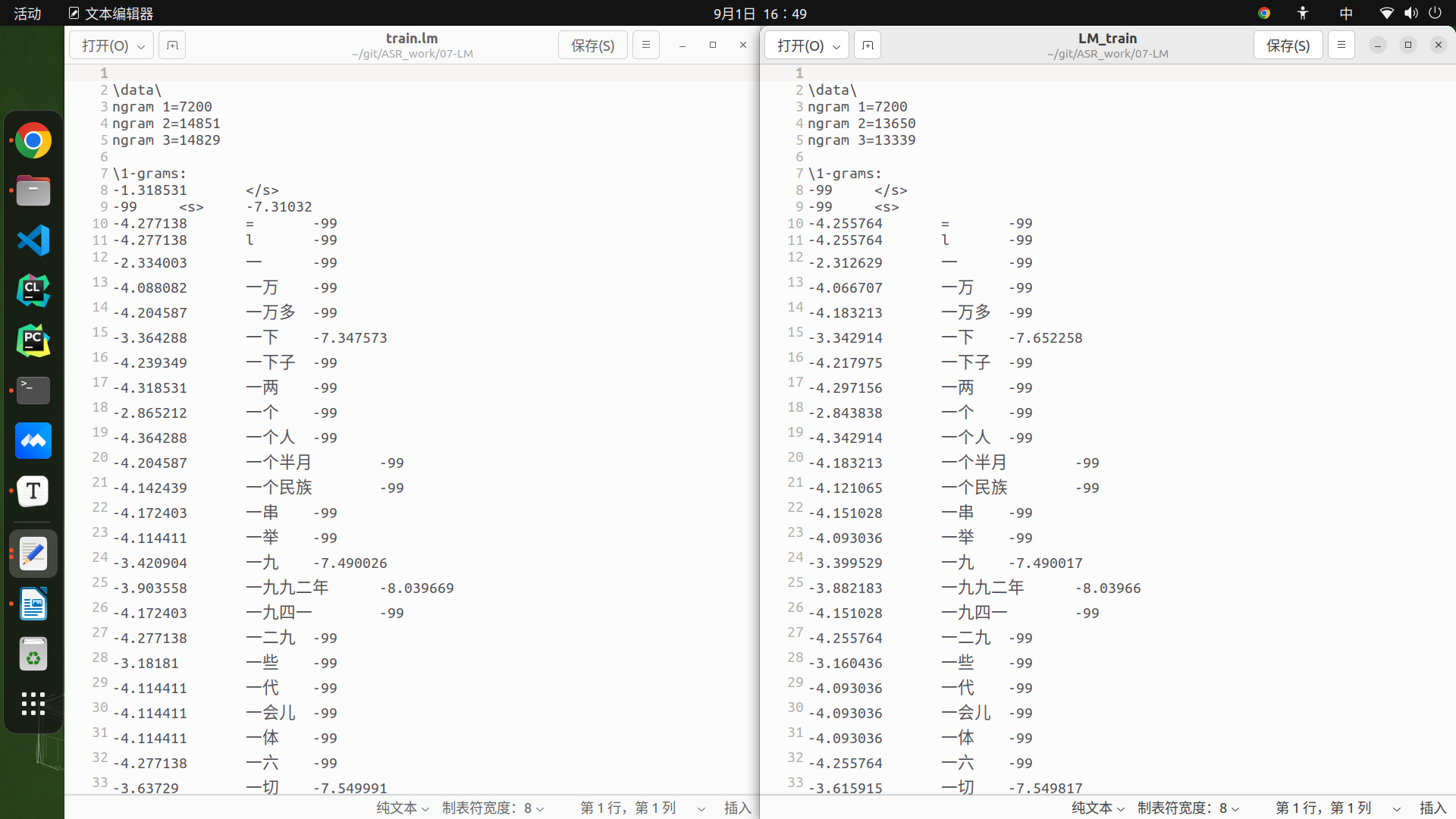
- 问题2:使用 SRILM SRILM 计算在识别测试集上计算计算在识别测试集上计算 PPL=32266.1
ngram -ppl testword.text.count -order 3 -lm train.lm
file testword.text.count: 12025 sentences, 37441 words, 22213 OOVs
2577 zeroprobs, logprob= -111258 ppl= 32266.1 ppl1= 6.22859e+08
四、Tips
使用nrgam-count,主要是三要素:训练文件,计数文件,语言模型,流程都是“训练文件–>计数文件–>语言模型”。
先将训练文件进行计数,通过-gtnmin mincount来控制哪些计数丢弃,即计数为0,然后再得到中间计数文件,再针对中间计数文件进行折扣算法,得到最终的语言模型。计数文件是一个中间文件,可以通过-write count_file来输出保存。
较为常用的使用方法如下:
- 最简单(Good-Turing折扣算法)
ngram-count -text train -lm LM.ARPA
- 输出词典和计数文件:
ngram-count -text train -write-vocab VOCAB -write COUNT -lm LM.ARPA
- 对语言模型剪枝:
ngram-count -text train -prune 0.2 -lm LM.ARPA
- 设置计数最小阈值:
ngram-count -text train -gt1min 1 -gt2min 1 -gt3min 2 -lm LM.ARPA
- 使用经过插值的修正Kneser-Ney折扣算法:
ngram-count -text train -kndiscount -interpolate -lm LM.ARPA
- 将debug信息输出来:
ngram-count -text train -kndiscount -interpolate -lm LM.ARPA -debug 1 2>DEBUG


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?