
Class6 作业-Kaldi的thchs30实例
在处理数据之前,我们要知道thchs30数据集包含三部分:train(训练集)、dev(开发集)和test(测试集)。其中dev的作用是在某些步骤与train进行交叉验证的,如local/nnet/run_dnn.sh同时用到exp/tri4b_ali和exp/tri4b_ali_cv。训练和测试的目标数据也分为两类:word(词)和phone(音素)。
-
local/thchs-30_data_prep.sh主要工作是从$thchs/data_thchs30(下载的数据)三部分分别生成word.txt(词序列),phone.txt(音素序列),text(与word.txt相同),wav.scp(语音),utt2pk(句子与说话人的映射),spk2utt(说话人与句子的映射) -
#produce MFCC features是提取MFCC特征,分为两步,先通过steps/make_mfcc.sh提取MFCC特征,再通过steps/compute_cmvn_stats.sh计算倒谱均值和方差归一化。 -
#prepare language stuff是构建一个包含训练和解码用到的词的词典。而语言模型已经由王东老师处理好了,如果不打算改语言模型,这段代码也不需要修改。
- 基于词的语言模型包含48k基于三元词的词,从gigaword语料库中随机选择文本信息进行训练得到,训练文本包含772000个句子,总计1800万词,1.15亿汉字
- 基于音素的语言模型包含218个基于三元音的中文声调,从只有200万字的样本训练得到,之所以选择这么小的样本是因为在模型中尽可能少地保留语言信息,可以使得到的性能更直接地反映声学模型的质量。
- 这两个语言模型都是由SRILM工具训练得到。
文献1介绍了thchs30示例的主要流程。
- 首先用标准的13维MFCC加上一阶和二阶导数训练单音素GMM系统,采用倒谱均值归一化(CMN)来降低通道效应。然后基于具有由LDA和MLLT变换的特征的单音系统构造三音GMM系统,最后的GMM系统用于为随后的DNN训练生成状态对齐。
- 基于GMM系统提供的对齐来训练DNN系统,特征是40维FBank,并且相邻的帧由11帧窗口(每侧5个窗口)连接。连接的特征被LDA转换,其中维度降低到200。然后应用全局均值和方差归一化以获得DNN输入。DNN架构由4个隐藏层组成,每个层由1200个单元组成,输出层由3386个单元组成。 基线DNN模型用交叉熵的标准训练。 使用随机梯度下降(SGD)算法来执行优化。 将迷你批量大小设定为256,初始学习率设定为0.008。
- 被噪声干扰的语音可以使用基于深度自动编码器(DAE)的噪声消除方法。DAE是自动编码器(AE)的一种特殊实现,通过在模型训练中对输入特征引入随机破坏。已经表明,该模型学习低维度特征的能力非常强大,并且可以用于恢复被噪声破坏的信号。在实践中,DAE被用作前端管道的特定组件。输入是11维Fbank特征(在均值归一化之后),输出是对应于中心帧的噪声消除特征。然后对输出进行LDA变换,提取全局标准化的常规Fbank特征,然后送到DNN声学模型(用纯净语音进行训练)。
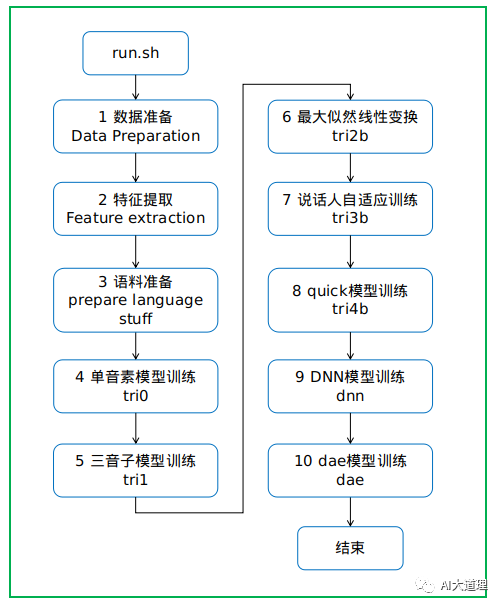
#!/usr/bin/env bash
#run.sh :整体流程控制脚本,主入口脚本
#Steps| Utils| tools:kaldi 脚本工具
#cmd.sh:运行配置目录,并行执行命令,通常分 run.pl, queue.pl 两种
. ./cmd.sh ## You'll want to change cmd.sh to something that will work on your system.
## This relates to the queue.
#path.sh:环境变量相关脚本(kaldi公用的全局PATH变量的设置)
. ./path.sh
#kaldi的源码的根目录,告诉程序kaldi在哪里
H=`pwd` #exp home
n=8 #parallel jobs
#corpus and trans directory
#要训练的thchs30数据的目录
thchs=/home/baixf/kaldi/egs/thchs30/s5/thchs30-openslr
数据准备
#step1:数据准备
#you can obtain the database by uncommting the following lines
#[ -d $thchs ] || mkdir -p $thchs || exit 1
echo "downloading THCHS30 at $thchs ..."
#download_and_untar.sh 功能:下载数据。
local/download_and_untar.sh $thchs http://www.openslr.org/resources/18 data_thchs30 || exit 1
local/download_and_untar.sh $thchs http://www.openslr.org/resources/18 resource || exit 1
local/download_and_untar.sh $thchs http://www.openslr.org/resources/18 test-noise || exit 1
#thchs-30_data_prep.sh 功能:进入thchs30-openslr/data_thchs30/train、dev、test目录,它读取语料库并得到wav.scp和音标,生成文本text,wav.scp,uut3pk,spk2utt。
#data preparation
#generate text, wav.scp, utt2pk, spk2utt
local/thchs-30_data_prep.sh $H $thchs/data_thchs30 || exit 1;
creating data/{train,dev,test}
cleaning data/train
preparing scps and text in data/train
cleaning data/dev
preparing scps and text in data/dev
cleaning data/test
preparing scps and text in data/test
creating test_phone for phone decoding
Thchs30 经过初步处理后得到六种文本文件:wav.scp,每条语音的 ID 及其存储路径;text,每条语音的 ID 及其对应文本;utt2spk,每条语音的 ID 及其说话人 ID; spk2utt,每个说话人的 ID 及其所说语音的所有 ID;phone.txt,每条语音的 ID 及说话内容的声音标注;word.txt,每条语音的 ID 及其对应文本。
特征提取
#step2:特征提取
#produce MFCC features
rm -rf data/mfcc && mkdir -p data/mfcc && cp -R data/{train,dev,test,test_phone} data/mfcc || exit 1;
#make_mfcc.sh 功能:MFCC特征提取。
#其中n是make的cpu线程数目,train_cmd 是cmd.sh里的train_cmd变量,$x就是循环里的{train,dev,test}了。
#data/mfcc:输入数据目录;exp/make_mfcc:输出log目录;mfcc:输出MFCC存放目录
for x in train dev test; do
#make mfcc
#利用Kaldi的compute-mfcc-feats工具计算梅尔倒谱频率特征,然后利用copy-feats工具的参数—compress=true 压缩处理存储为两个文件类型ark和scp。
steps/make_mfcc.sh --nj $n --cmd "$train_cmd" data/mfcc/$x exp/make_mfcc/$x mfcc/$x || exit 1;
#compute cmvn
#计算cmvn倒谱均值方差归一化
#在实际情况下,受不同麦克风及音频通道的影响,会导致相同音素的特征差别比较大,通过CMVN可以得到均值为0,方差为1的标准特征。均值方差可以以一段语音为单位计算,但更好的是在一个较大的数据及上进行计算,这样识别效果会更加robustness。Kaldi中计算均值和方差的代码在compute-cmvn-stats.cc, 归一化在apply-cmvn.cc。
#这里还计算了倒谱均值方差归一化(Cepstral Mean and Variance Normalization,CMVN)系数用于声学特征的规整化,该方法旨在提高声学特征对说话人、录音设备、环境、音量等因素的鲁棒性。
steps/compute_cmvn_stats.sh data/mfcc/$x exp/mfcc_cmvn/$x mfcc/$x || exit 1;
done
#copy feats and cmvn to test.ph, avoid duplicated mfcc & cmvn
cp data/mfcc/test/feats.scp data/mfcc/test_phone && cp data/mfcc/test/cmvn.scp data/mfcc/test_phone || exit 1;
steps/make_mfcc.sh --nj 8 --cmd run.pl data/mfcc/train exp/make_mfcc/train mfcc/train
utils/validate_data_dir.sh: Successfully validated data-directory data/mfcc/train
steps/make_mfcc.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_mfcc.sh: Succeeded creating MFCC features for train
steps/compute_cmvn_stats.sh data/mfcc/train exp/mfcc_cmvn/train mfcc/train
Succeeded creating CMVN stats for train
steps/make_mfcc.sh --nj 8 --cmd run.pl data/mfcc/dev exp/make_mfcc/dev mfcc/dev
utils/validate_data_dir.sh: Successfully validated data-directory data/mfcc/dev
steps/make_mfcc.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_mfcc.sh: Succeeded creating MFCC features for dev
steps/compute_cmvn_stats.sh data/mfcc/dev exp/mfcc_cmvn/dev mfcc/dev
Succeeded creating CMVN stats for dev
steps/make_mfcc.sh --nj 8 --cmd run.pl data/mfcc/test exp/make_mfcc/test mfcc/test
utils/validate_data_dir.sh: Successfully validated data-directory data/mfcc/test
steps/make_mfcc.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_mfcc.sh: Succeeded creating MFCC features for test
steps/compute_cmvn_stats.sh data/mfcc/test exp/mfcc_cmvn/test mfcc/test
Succeeded creating CMVN stats for test
物料准备
#step3:物料准备:准备发音词典L.fst和训练3-gram语言模型G.fst。
#prepare language stuff
#建立一个庞大的词汇库,包括单词的训练和解码
#build a large lexicon that invovles words in both the training and decoding.
(
echo "make word graph ..." #制作词图
cd $H; mkdir -p data/{dict,lang,graph} && \ #在pwd下创建文件夹
#将语音数据库目录的相应文件拷贝到dict目录?
cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict && \
#将两个目录的lexicon.txt文件输出到data_thchs30/lm_word/lexicon.txt,同时过滤掉带<s>或</s>的行,并且删除相同的重复信息
cat $thchs/resource/dict/lexicon.txt $thchs/data_thchs30/lm_word/lexicon.txt | \
grep -v '<s>' | grep -v '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
#调用utils下的prepare_lang.sh构建字典L.fst文件,来准备语言模型。即读取input的资源文件,生成data/lang目录,是Kaldi的标准语言文件夹。
utils/prepare_lang.sh --position_dependent_phones false data/dict "<SPOKEN_NOISE>" data/local/lang data/lang || exit 1;
#将word.3gram.lm压缩为word.3gram.lm.gz并保留文件
gzip -c $thchs/data_thchs30/lm_word/word.3gram.lm > data/graph/word.3gram.lm.gz || exit 1;
#调用utils下的format_lm.sh来格式化语言模型,就是把arpa的language model 转换成 FST格式。
#format_lm.sh的主要目标就是根据语言模型生成G.fst文件。方便与之前的L.fst结合,发挥fst的优势。脚本最后会检测G.fst中是否存没有单词的空环,如果存在就会报错,这回这会导致后续HLG的determinization出现错误。其程序核心就是arpa2fst
#data/lang:输入,语言文件夹;data/graph/word.3gram.lm.gz:输入,ARPA格式的语言模型;$thchs/data_thchs30/lm_word/lexicon.txt:输入,词典;data/graph/lang:输出,G.fst语言模型
utils/format_lm.sh data/lang data/graph/word.3gram.lm.gz $thchs/data_thchs30/lm_word/lexicon.txt data/graph/lang || exit 1;
)
#make_phone_graph #制作音素图
(
echo "make phone graph ..."
#在本目录下创建以下文件夹
cd $H; mkdir -p data/{dict_phone,graph_phone,lang_phone} && \
#将语音数据库的目录的相应文件拷贝到dict目录?
cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict_phone && \
#将lexicon.txt文件输出到data/dict_phone/lexicon.txt,同时过滤掉带<eps>的行,并且删除相同的重复信息
cat $thchs/data_thchs30/lm_phone/lexicon.txt | grep -v '<eps>' | sort -u > data/dict_phone/lexicon.txt && \
echo "<SPOKEN_NOISE> sil " >> data/dict_phone/lexicon.txt || exit 1;
#调用utils下的prepare_lang.sh构建字典L.fst文件,来准备语言模型。即读取input的资源文件,生成data/lang目录,是Kaldi的标准语言文件夹。
utils/prepare_lang.sh --position_dependent_phones false data/dict_phone "<SPOKEN_NOISE>" data/local/lang_phone data/lang_phone || exit 1;
#将phone.3gram.lm压缩为phone.3gram.lm.gz并保留文件
gzip -c $thchs/data_thchs30/lm_phone/phone.3gram.lm > data/graph_phone/phone.3gram.lm.gz || exit 1;
#调用utils下的format_lm.sh来格式化语言模型,就是把arpa的language model 转换成 FST格式。
#data/lang_phone:输入,语言文件夹;data/graph_phone/word.3gram.lm.gz:输入,ARPA格式的语言模型;$thchs/data_thchs30/lm_phone/lexicon.txt:输入,词典;data/graph_phone/lang:输出,G.fst语言模型
utils/format_lm.sh data/lang_phone data/graph_phone/phone.3gram.lm.gz $thchs/data_thchs30/lm_phone/lexicon.txt \
data/graph_phone/lang || exit 1;
)
ARPA是常用的语言模型存储格式, 由主要由两部分构成。模型文件头和模型文件体构成。

在基于WFST框架的语音识别解码器静态构图中,使用WFST的Compose算法组合各个层次的信息,最终生成解码图HCLG, H/C/L/G分别表示不同层级的FST,其中:
H表示HMM层级的FST,输入为senone状态,输出为context-dependent phone。
C表示Context层级的FST,语音识别中的音素建模时考虑当前音素的上一个音素和下一个音素,C的输入为context-dependent phones,输出为phone。
L表示Lexicon层级的FST,对单个的词来讲,输入为该词的phone序列,输出为该词。
G表示Grammar层级的FST,一般Grammar用n-gram的语言模型表示,arpa的语言模型可以表示为等价的FST的形式,输入输出均为词。
从H->C->L->G,低层次的FST的输出粒度刚好对应高一层次FST的输入粒度,通过Compose HCLG(表示Compose),即可将HMM/Context/Lexicon/Grammar所有层次的信息构建在一个FST HCLG中,该HCLG输入为语音识别声学模型的建模单元senone,输出为词。
解码时,解码器直接使用已经构建好的HCLG,该HCLG已经全部展开,称之为静态图。
make word graph ...
utils/prepare_lang.sh --position_dependent_phones false data/dict <SPOKEN_NOISE> data/local/lang data/lang
Checking data/dict/silence_phones.txt ...
--> reading data/dict/silence_phones.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict/silence_phones.txt is OK
Checking data/dict/optional_silence.txt ...
--> reading data/dict/optional_silence.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict/optional_silence.txt is OK
Checking data/dict/nonsilence_phones.txt ...
--> reading data/dict/nonsilence_phones.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict/nonsilence_phones.txt is OK
Checking disjoint: silence_phones.txt, nonsilence_phones.txt
--> disjoint property is OK.
Checking data/dict/lexicon.txt
--> reading data/dict/lexicon.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict/lexicon.txt is OK
Checking data/dict/extra_questions.txt ...
--> reading data/dict/extra_questions.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict/extra_questions.txt is OK
--> SUCCESS [validating dictionary directory data/dict]
**Creating data/dict/lexiconp.txt from data/dict/lexicon.txt
fstaddselfloops data/lang/phones/wdisambig_phones.int data/lang/phones/wdisambig_words.int
prepare_lang.sh: validating output directory
utils/validate_lang.pl data/lang
Checking existence of separator file
separator file data/lang/subword_separator.txt is empty or does not exist, deal in word case.
Checking data/lang/phones.txt ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/lang/phones.txt is OK
Checking words.txt: #0 ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/lang/words.txt is OK
Checking disjoint: silence.txt, nonsilence.txt, disambig.txt ...
--> silence.txt and nonsilence.txt are disjoint
--> silence.txt and disambig.txt are disjoint
--> disambig.txt and nonsilence.txt are disjoint
--> disjoint property is OK
Checking sumation: silence.txt, nonsilence.txt, disambig.txt ...
--> found no unexplainable phones in phones.txt
Checking data/lang/phones/context_indep.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang/phones/context_indep.txt
--> data/lang/phones/context_indep.int corresponds to data/lang/phones/context_indep.txt
--> data/lang/phones/context_indep.csl corresponds to data/lang/phones/context_indep.txt
--> data/lang/phones/context_indep.{txt, int, csl} are OK
Checking data/lang/phones/nonsilence.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 217 entry/entries in data/lang/phones/nonsilence.txt
--> data/lang/phones/nonsilence.int corresponds to data/lang/phones/nonsilence.txt
--> data/lang/phones/nonsilence.csl corresponds to data/lang/phones/nonsilence.txt
--> data/lang/phones/nonsilence.{txt, int, csl} are OK
Checking data/lang/phones/silence.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang/phones/silence.txt
--> data/lang/phones/silence.int corresponds to data/lang/phones/silence.txt
--> data/lang/phones/silence.csl corresponds to data/lang/phones/silence.txt
--> data/lang/phones/silence.{txt, int, csl} are OK
Checking data/lang/phones/optional_silence.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang/phones/optional_silence.txt
--> data/lang/phones/optional_silence.int corresponds to data/lang/phones/optional_silence.txt
--> data/lang/phones/optional_silence.csl corresponds to data/lang/phones/optional_silence.txt
--> data/lang/phones/optional_silence.{txt, int, csl} are OK
Checking data/lang/phones/disambig.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 57 entry/entries in data/lang/phones/disambig.txt
--> data/lang/phones/disambig.int corresponds to data/lang/phones/disambig.txt
--> data/lang/phones/disambig.csl corresponds to data/lang/phones/disambig.txt
--> data/lang/phones/disambig.{txt, int, csl} are OK
Checking data/lang/phones/roots.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 218 entry/entries in data/lang/phones/roots.txt
--> data/lang/phones/roots.int corresponds to data/lang/phones/roots.txt
--> data/lang/phones/roots.{txt, int} are OK
Checking data/lang/phones/sets.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 218 entry/entries in data/lang/phones/sets.txt
--> data/lang/phones/sets.int corresponds to data/lang/phones/sets.txt
--> data/lang/phones/sets.{txt, int} are OK
Checking data/lang/phones/extra_questions.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 7 entry/entries in data/lang/phones/extra_questions.txt
--> data/lang/phones/extra_questions.int corresponds to data/lang/phones/extra_questions.txt
--> data/lang/phones/extra_questions.{txt, int} are OK
Checking optional_silence.txt ...
--> reading data/lang/phones/optional_silence.txt
--> data/lang/phones/optional_silence.txt is OK
Checking disambiguation symbols: #0 and #1
--> data/lang/phones/disambig.txt has "#0" and "#1"
--> data/lang/phones/disambig.txt is OK
Checking topo ...
Checking word-level disambiguation symbols...
--> data/lang/phones/wdisambig.txt exists (newer prepare_lang.sh)
Checking data/lang/oov.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang/oov.txt
--> data/lang/oov.int corresponds to data/lang/oov.txt
--> data/lang/oov.{txt, int} are OK
--> data/lang/L.fst is olabel sorted
--> data/lang/L_disambig.fst is olabel sorted
--> SUCCESS [validating lang directory data/lang]
Converting 'data/graph/word.3gram.lm.gz' to FST
arpa2fst --disambig-symbol=#0 --read-symbol-table=data/graph/lang/words.txt - data/graph/lang/G.fst
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:94) Reading \data\ section.
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:149) Reading \1-grams: section.
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:149) Reading \2-grams: section.
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:149) Reading \3-grams: section.
LOG (arpa2fst[5.5.1050~1-0fb50]:RemoveRedundantStates():arpa-lm-compiler.cc:359) Reduced num-states from 3076353 to 454251
fstisstochastic data/graph/lang/G.fst
-7.27093e-08 -0.832396
Succeeded in formatting LM: 'data/graph/word.3gram.lm.gz'
make phone graph ...
utils/prepare_lang.sh --position_dependent_phones false data/dict_phone <SPOKEN_NOISE> data/local/lang_phone data/lang_phone
Checking data/dict_phone/silence_phones.txt ...
--> reading data/dict_phone/silence_phones.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict_phone/silence_phones.txt is OK
Checking data/dict_phone/optional_silence.txt ...
--> reading data/dict_phone/optional_silence.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict_phone/optional_silence.txt is OK
Checking data/dict_phone/nonsilence_phones.txt ...
--> reading data/dict_phone/nonsilence_phones.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict_phone/nonsilence_phones.txt is OK
Checking disjoint: silence_phones.txt, nonsilence_phones.txt
--> disjoint property is OK.
Checking data/dict_phone/lexicon.txt
--> reading data/dict_phone/lexicon.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict_phone/lexicon.txt is OK
Checking data/dict_phone/extra_questions.txt ...
--> reading data/dict_phone/extra_questions.txt
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/dict_phone/extra_questions.txt is OK
--> SUCCESS [validating dictionary directory data/dict_phone]
**Creating data/dict_phone/lexiconp.txt from data/dict_phone/lexicon.txt
fstaddselfloops data/lang_phone/phones/wdisambig_phones.int data/lang_phone/phones/wdisambig_words.int
prepare_lang.sh: validating output directory
utils/validate_lang.pl data/lang_phone
Checking existence of separator file
separator file data/lang_phone/subword_separator.txt is empty or does not exist, deal in word case.
Checking data/lang_phone/phones.txt ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/lang_phone/phones.txt is OK
Checking words.txt: #0 ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> data/lang_phone/words.txt is OK
Checking disjoint: silence.txt, nonsilence.txt, disambig.txt ...
--> silence.txt and nonsilence.txt are disjoint
--> silence.txt and disambig.txt are disjoint
--> disambig.txt and nonsilence.txt are disjoint
--> disjoint property is OK
Checking sumation: silence.txt, nonsilence.txt, disambig.txt ...
--> found no unexplainable phones in phones.txt
Checking data/lang_phone/phones/context_indep.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang_phone/phones/context_indep.txt
--> data/lang_phone/phones/context_indep.int corresponds to data/lang_phone/phones/context_indep.txt
--> data/lang_phone/phones/context_indep.csl corresponds to data/lang_phone/phones/context_indep.txt
--> data/lang_phone/phones/context_indep.{txt, int, csl} are OK
Checking data/lang_phone/phones/nonsilence.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 217 entry/entries in data/lang_phone/phones/nonsilence.txt
--> data/lang_phone/phones/nonsilence.int corresponds to data/lang_phone/phones/nonsilence.txt
--> data/lang_phone/phones/nonsilence.csl corresponds to data/lang_phone/phones/nonsilence.txt
--> data/lang_phone/phones/nonsilence.{txt, int, csl} are OK
Checking data/lang_phone/phones/silence.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang_phone/phones/silence.txt
--> data/lang_phone/phones/silence.int corresponds to data/lang_phone/phones/silence.txt
--> data/lang_phone/phones/silence.csl corresponds to data/lang_phone/phones/silence.txt
--> data/lang_phone/phones/silence.{txt, int, csl} are OK
Checking data/lang_phone/phones/optional_silence.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang_phone/phones/optional_silence.txt
--> data/lang_phone/phones/optional_silence.int corresponds to data/lang_phone/phones/optional_silence.txt
--> data/lang_phone/phones/optional_silence.csl corresponds to data/lang_phone/phones/optional_silence.txt
--> data/lang_phone/phones/optional_silence.{txt, int, csl} are OK
Checking data/lang_phone/phones/disambig.{txt, int, csl} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 4 entry/entries in data/lang_phone/phones/disambig.txt
--> data/lang_phone/phones/disambig.int corresponds to data/lang_phone/phones/disambig.txt
--> data/lang_phone/phones/disambig.csl corresponds to data/lang_phone/phones/disambig.txt
--> data/lang_phone/phones/disambig.{txt, int, csl} are OK
Checking data/lang_phone/phones/roots.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 218 entry/entries in data/lang_phone/phones/roots.txt
--> data/lang_phone/phones/roots.int corresponds to data/lang_phone/phones/roots.txt
--> data/lang_phone/phones/roots.{txt, int} are OK
Checking data/lang_phone/phones/sets.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 218 entry/entries in data/lang_phone/phones/sets.txt
--> data/lang_phone/phones/sets.int corresponds to data/lang_phone/phones/sets.txt
--> data/lang_phone/phones/sets.{txt, int} are OK
Checking data/lang_phone/phones/extra_questions.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 7 entry/entries in data/lang_phone/phones/extra_questions.txt
--> data/lang_phone/phones/extra_questions.int corresponds to data/lang_phone/phones/extra_questions.txt
--> data/lang_phone/phones/extra_questions.{txt, int} are OK
Checking optional_silence.txt ...
--> reading data/lang_phone/phones/optional_silence.txt
--> data/lang_phone/phones/optional_silence.txt is OK
Checking disambiguation symbols: #0 and #1
--> data/lang_phone/phones/disambig.txt has "#0" and "#1"
--> data/lang_phone/phones/disambig.txt is OK
Checking topo ...
Checking word-level disambiguation symbols...
--> data/lang_phone/phones/wdisambig.txt exists (newer prepare_lang.sh)
Checking data/lang_phone/oov.{txt, int} ...
--> text seems to be UTF-8 or ASCII, checking whitespaces
--> text contains only allowed whitespaces
--> 1 entry/entries in data/lang_phone/oov.txt
--> data/lang_phone/oov.int corresponds to data/lang_phone/oov.txt
--> data/lang_phone/oov.{txt, int} are OK
--> data/lang_phone/L.fst is olabel sorted
--> data/lang_phone/L_disambig.fst is olabel sorted
--> SUCCESS [validating lang directory data/lang_phone]
Converting 'data/graph_phone/phone.3gram.lm.gz' to FST
arpa2fst --disambig-symbol=#0 --read-symbol-table=data/graph_phone/lang/words.txt - data/graph_phone/lang/G.fst
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:94) Reading \data\ section.
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:149) Reading \1-grams: section.
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:149) Reading \2-grams: section.
LOG (arpa2fst[5.5.1050~1-0fb50]:Read():arpa-file-parser.cc:149) Reading \3-grams: section.
LOG (arpa2fst[5.5.1050~1-0fb50]:RemoveRedundantStates():arpa-lm-compiler.cc:359) Reduced num-states from 5709 to 4848
fstisstochastic data/graph_phone/lang/G.fst
1.86678e-07 -3.76792
Succeeded in formatting LM: 'data/graph_phone/phone.3gram.lm.gz'
单音素模型训练
#step4:单音素模型训练(tri0)、解码、对齐
#monophone
#train_mono.sh:用来训练单音素隐马尔科夫模型,一共进行40次迭代,每两次迭代进行一次对齐操作。
#过程之道:初始化模型->生成训练图HCLG.fst->对标签进行初始化对齐->统计估计模型所需的统计量->估计参数得到新模型->迭代训练->最后的模型final.mdl。
#data/mfcc/train:输入,用于训练的数据;data/lang:输入,语言模型。monophone模型的训练需要用到phones.txt这个文件;exp/mono:输出,单音素模型,一些日志和对齐文件,主要输出为final.mdl和tree
steps/train_mono.sh --boost-silence 1.25 --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/mono || exit 1;
#test monophone model
#thchs-30_decode.sh:测试单音素模型,解码和测试部分,它采用刚刚训练得到的模型来对测试数据集进行解码并计算准确率等信息,实际使用mkgraph.sh建立完全的识别网络,并输出一个有限状态转换器,最后使用decode.sh以语言模型和测试数据为输入计算WER。
local/thchs-30_decode.sh --mono true --nj $n "steps/decode.sh" exp/mono data/mfcc &
#monophone_ali
#align_si.sh:这一步是为了三音素训练提供对齐基础。用指定src-dir中的模型对指定data-dir中的数据进行对齐,一般在训练新模型前进行,以上一版本模型作为输入,输出在<align-dir>。
#--boost-silence 1.25:在对齐过程中提高静音的比例;data/mfcc/train:输入,标注文本text;data/lang:输入,词典L.fst;exp/mono:输入,模型,tree文件;输出:对齐序列
steps/align_si.sh --boost-silence 1.25 --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/mono exp/mono_ali || exit 1;
steps/train_mono.sh --boost-silence 1.25 --nj 8 --cmd run.pl data/mfcc/train data/lang exp/mono
steps/train_mono.sh: Initializing monophone system.
steps/train_mono.sh: Compiling training graphs
steps/train_mono.sh: Aligning data equally (pass 0)
steps/train_mono.sh: Pass 1
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 2
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 3
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 4
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 5
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 6
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 7
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 8
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 9
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 10
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 11
steps/train_mono.sh: Pass 12
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 13
steps/train_mono.sh: Pass 14
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 15
steps/train_mono.sh: Pass 16
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 17
steps/train_mono.sh: Pass 18
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 19
steps/train_mono.sh: Pass 20
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 21
steps/train_mono.sh: Pass 22
steps/train_mono.sh: Pass 23
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 24
steps/train_mono.sh: Pass 25
steps/train_mono.sh: Pass 26
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 27
steps/train_mono.sh: Pass 28
steps/train_mono.sh: Pass 29
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 30
steps/train_mono.sh: Pass 31
steps/train_mono.sh: Pass 32
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 33
steps/train_mono.sh: Pass 34
steps/train_mono.sh: Pass 35
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 36
steps/train_mono.sh: Pass 37
steps/train_mono.sh: Pass 38
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 39
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/mono
steps/diagnostic/analyze_alignments.sh: see stats in exp/mono/log/analyze_alignments.log
3976 warnings in exp/mono/log/align.*.*.log
56 warnings in exp/mono/log/acc.*.*.log
1053 warnings in exp/mono/log/update.*.log
exp/mono: nj=8 align prob=-100.09 over 25.49h [retry=0.2%, fail=0.0%] states=656 gauss=990
steps/train_mono.sh: Done training monophone system in exp/mono
steps/align_si.sh --boost-silence 1.25 --nj 8 --cmd run.pl data/mfcc/train data/lang exp/mono exp/mono_ali
using monophone to generate graph
WARNING: the --mono, --left-biphone and --quinphone options are now deprecated and ignored.
tree-info exp/mono/tree
tree-info exp/mono/tree
steps/align_si.sh: feature type is delta
steps/align_si.sh: aligning data in data/mfcc/train using model from exp/mono, putting alignments in exp/mono_ali
fstminimizeencoded
fstpushspecial
fstdeterminizestar --use-log=true
fsttablecompose data/graph/lang/L_disambig.fst data/graph/lang/G.fst
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/mono_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/mono_ali/log/analyze_alignments.log
steps/align_si.sh: done aligning data.
三音素模型训练
#triphone
#steps/train_deltas.sh就是三音素模型的训练部分,三音素的训练和单音素模型的主要区别是状态绑定部分
#Usage: steps/train_deltas.sh <num-leaves> <tot-gauss> <data-dir> <lang-dir> <alignment-dir> <exp-dir>
#num-leaves:叶子节点数目;tot-gauss:总高斯数目;data-dir:数据文件夹;lang-dir:存放语言的文件夹;alignment-dir:存放之前单音素对齐后结果的文件夹;exp-dir是存放三音素模型结果的文件夹。
steps/train_deltas.sh --boost-silence 1.25 --cmd "$train_cmd" 2000 10000 data/mfcc/train data/lang exp/mono_ali exp/tri1 || exit 1;
#test tri1 model
#解码测试部分,可以看到该代码和单音素的解码测试是一样的,只是少了–mono选项
local/thchs-30_decode.sh --nj $n "steps/decode.sh" exp/tri1 data/mfcc &
#triphone_ali
#利用第一行训练得到的三音素模型来做强制对齐。代码也是和单音素时是一样的,只是输出模型的变化
steps/align_si.sh --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/tri1 exp/tri1_ali || exit 1;
steps/train_deltas.sh --boost-silence 1.25 --cmd run.pl 2000 10000 data/mfcc/train data/lang exp/mono_ali exp/tri1
steps/train_deltas.sh: accumulating tree stats
steps/train_deltas.sh: getting questions for tree-building, via clustering
steps/train_deltas.sh: building the tree
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 109 with no stats; corresponding phone list: 110
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 121 with no stats; corresponding phone list: 122
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 163 with no stats; corresponding phone list: 164
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 175 with no stats; corresponding phone list: 176
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 176 with no stats; corresponding phone list: 177
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 177 with no stats; corresponding phone list: 178
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 182 with no stats; corresponding phone list: 183
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 203 with no stats; corresponding phone list: 204
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 208 with no stats; corresponding phone list: 209
** The warnings above about 'no stats' generally mean you have phones **
** (or groups of phones) in your phone set that had no corresponding data. **
** You should probably figure out whether something went wrong, **
** or whether your data just doesn't happen to have examples of those **
** phones. **
steps/train_deltas.sh: converting alignments from exp/mono_ali to use current tree
steps/train_deltas.sh: compiling graphs of transcripts
steps/train_deltas.sh: training pass 1
steps/train_deltas.sh: training pass 2
steps/train_deltas.sh: training pass 3
steps/train_deltas.sh: training pass 4
steps/train_deltas.sh: training pass 5
steps/train_deltas.sh: training pass 6
steps/train_deltas.sh: training pass 7
steps/train_deltas.sh: training pass 8
steps/train_deltas.sh: training pass 9
steps/train_deltas.sh: training pass 10
steps/train_deltas.sh: aligning data
steps/train_deltas.sh: training pass 11
steps/train_deltas.sh: training pass 12
steps/train_deltas.sh: training pass 13
steps/train_deltas.sh: training pass 14
fstisstochastic data/graph/lang/tmp/LG.fst
-0.0480882 -0.0488869
[info]: LG not stochastic.
fstcomposecontext --context-size=1 --central-position=0 --read-disambig-syms=data/graph/lang/phones/disambig.int --write-disambig-syms=data/graph/lang/tmp/disambig_ilabels_1_0.int data/graph/lang/tmp/ilabels_1_0.499669 data/graph/lang/tmp/LG.fst
steps/train_deltas.sh: training pass 15
steps/train_deltas.sh: training pass 16
steps/train_deltas.sh: training pass 17
steps/train_deltas.sh: training pass 18
steps/train_deltas.sh: training pass 19
steps/train_deltas.sh: training pass 20
steps/train_deltas.sh: aligning data
fstisstochastic data/graph/lang/tmp/CLG_1_0.fst
-0.0480882 -0.0488869
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/mono/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_1_0 exp/mono/tree exp/mono/final.mdl
fsttablecompose exp/mono/graph_word/Ha.fst data/graph/lang/tmp/CLG_1_0.fst
fstminimizeencoded
fstrmepslocal
fstrmsymbols exp/mono/graph_word/disambig_tid.int
fstdeterminizestar --use-log=true
steps/train_deltas.sh: training pass 21
steps/train_deltas.sh: training pass 22
steps/train_deltas.sh: training pass 23
steps/train_deltas.sh: training pass 24
steps/train_deltas.sh: training pass 25
steps/train_deltas.sh: training pass 26
steps/train_deltas.sh: training pass 27
steps/train_deltas.sh: training pass 28
steps/train_deltas.sh: training pass 29
steps/train_deltas.sh: training pass 30
steps/train_deltas.sh: aligning data
steps/train_deltas.sh: training pass 31
steps/train_deltas.sh: training pass 32
steps/train_deltas.sh: training pass 33
steps/train_deltas.sh: training pass 34
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri1
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri1/log/analyze_alignments.log
9 warnings in exp/tri1/log/questions.log
1 warnings in exp/tri1/log/compile_questions.log
9 warnings in exp/tri1/log/init_model.log
74 warnings in exp/tri1/log/acc.*.*.log
93 warnings in exp/tri1/log/align.*.*.log
281 warnings in exp/tri1/log/update.*.log
1 warnings in exp/tri1/log/build_tree.log
exp/tri1: nj=8 align prob=-96.76 over 25.48h [retry=0.4%, fail=0.0%] states=1680 gauss=10026 tree-impr=4.80
steps/train_deltas.sh: Done training system with delta+delta-delta features in exp/tri1
steps/align_si.sh --nj 8 --cmd run.pl data/mfcc/train data/lang exp/tri1 exp/tri1_ali
tree-info exp/tri1/tree
tree-info exp/tri1/tree
steps/align_si.sh: feature type is delta
steps/align_si.sh: aligning data in data/mfcc/train using model from exp/tri1, putting alignments in exp/tri1_ali
fstcomposecontext --context-size=3 --central-position=1 --read-disambig-syms=data/graph/lang/phones/disambig.int --write-disambig-syms=data/graph/lang/tmp/disambig_ilabels_3_1.int data/graph/lang/tmp/ilabels_3_1.506942 data/graph/lang/tmp/LG.fst
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri1_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri1_ali/log/analyze_alignments.log
steps/align_si.sh: done aligning data.
最大似然线性变换
#lda_mllt
#最大似然线性变换
#用来做特征调整并训练新模型
steps/train_lda_mllt.sh --cmd "$train_cmd" --splice-opts "--left-context=3 --right-context=3" 2500 15000 data/mfcc/train data/lang exp/tri1_ali exp/tri2b || exit 1;
#test tri2b model
#解码测试
local/thchs-30_decode.sh --nj $n "steps/decode.sh" exp/tri2b data/mfcc &
#lda_mllt_ali
#根据模型对数据进行对齐
steps/align_si.sh --nj $n --cmd "$train_cmd" --use-graphs true data/mfcc/train data/lang exp/tri2b exp/tri2b_ali || exit 1;
steps/train_lda_mllt.sh --cmd run.pl --splice-opts --left-context=3 --right-context=3 2500 15000 data/mfcc/train data/lang exp/tri1_ali exp/tri2b
steps/train_lda_mllt.sh: Accumulating LDA statistics.
fstisstochastic data/graph/lang/tmp/CLG_3_1.fst
steps/train_lda_mllt.sh: Accumulating tree stats
0 -0.0488869
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/tri1/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri1/tree exp/tri1/final.mdl
fstminimizeencoded
fstrmepslocal
fstrmsymbols exp/tri1/graph_word/disambig_tid.int
fsttablecompose exp/tri1/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
fstdeterminizestar --use-log=true
steps/train_lda_mllt.sh: Getting questions for tree clustering.
steps/train_lda_mllt.sh: Building the tree
steps/train_lda_mllt.sh: Initializing the model
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 109 with no stats; corresponding phone list: 110
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 121 with no stats; corresponding phone list: 122
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 163 with no stats; corresponding phone list: 164
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 175 with no stats; corresponding phone list: 176
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 176 with no stats; corresponding phone list: 177
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 177 with no stats; corresponding phone list: 178
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 203 with no stats; corresponding phone list: 204
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 208 with no stats; corresponding phone list: 209
This is a bad warning.
steps/train_lda_mllt.sh: Converting alignments from exp/tri1_ali to use current tree
steps/train_lda_mllt.sh: Compiling graphs of transcripts
Training pass 1
fstisstochastic exp/mono/graph_word/HCLGa.fst
Training pass 2
steps/train_lda_mllt.sh: Estimating MLLT
0.644531 -0.0974261
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/mono/final.mdl exp/mono/graph_word/HCLGa.fst
Training pass 3
Training pass 4
steps/train_lda_mllt.sh: Estimating MLLT
Training pass 5
Training pass 6
steps/train_lda_mllt.sh: Estimating MLLT
Training pass 7
Training pass 8
Training pass 9
Training pass 10
Aligning data
steps/decode.sh --cmd run.pl --mem 4G --nj 8 exp/mono/graph_word data/mfcc/test exp/mono/decode_test_word
decode.sh: feature type is delta
Training pass 11
Training pass 12
steps/train_lda_mllt.sh: Estimating MLLT
Training pass 13
Training pass 14
Training pass 15
Training pass 16
Training pass 17
Training pass 18
Training pass 19
Training pass 20
Aligning data
Training pass 21
Training pass 22
Training pass 23
Training pass 24
Training pass 25
Training pass 26
Training pass 27
Training pass 28
Training pass 29
Training pass 30
Aligning data
Training pass 31
Training pass 32
Training pass 33
Training pass 34
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri2b
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri2b/log/analyze_alignments.log
272 warnings in exp/tri2b/log/update.*.log
9 warnings in exp/tri2b/log/init_model.log
147 warnings in exp/tri2b/log/align.*.*.log
3 warnings in exp/tri2b/log/lda_acc.*.log
1 warnings in exp/tri2b/log/compile_questions.log
102 warnings in exp/tri2b/log/acc.*.*.log
1 warnings in exp/tri2b/log/build_tree.log
8 warnings in exp/tri2b/log/questions.log
exp/tri2b: nj=8 align prob=-48.15 over 25.48h [retry=0.5%, fail=0.0%] states=2080 gauss=15034 tree-impr=4.34 lda-sum=23.95 mllt:impr,logdet=1.18,1.68
steps/train_lda_mllt.sh: Done training system with LDA+MLLT features in exp/tri2b
steps/align_si.sh --nj 8 --cmd run.pl --use-graphs true data/mfcc/train data/lang exp/tri2b exp/tri2b_ali
tree-info exp/tri2b/tree
tree-info exp/tri2b/tree
steps/align_si.sh: feature type is lda
steps/align_si.sh: aligning data in data/mfcc/train using model from exp/tri2b, putting alignments in exp/tri2b_ali
make-h-transducer --disambig-syms-out=exp/tri2b/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri2b/tree exp/tri2b/final.mdl
fstrmsymbols exp/tri2b/graph_word/disambig_tid.int
fstrmepslocal
fsttablecompose exp/tri2b/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
fstminimizeencoded
fstdeterminizestar --use-log=true
utils/mkgraph.sh: line 145: 507716 Done fsttablecompose $dir/Ha.fst "$clg"
507717 | fstdeterminizestar --use-log=true
507718 | fstrmsymbols $dir/disambig_tid.int
507719 | fstrmepslocal
507720 Killed | fstminimizeencoded > $dir/HCLGa.fst.$$
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri2b_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri2b_ali/log/analyze_alignments.log
steps/align_si.sh: done aligning data.
steps/train_sat.sh --cmd run.pl 2500 15000 data/mfcc/train data/lang exp/tri2b_ali exp/tri3b
steps/train_sat.sh: feature type is lda
steps/train_sat.sh: obtaining initial fMLLR transforms since not present in exp/tri2b_ali
steps/train_sat.sh: Accumulating tree stats
steps/train_sat.sh: Getting questions for tree clustering.
steps/train_sat.sh: Building the tree
steps/train_sat.sh: Initializing the model
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 109 with no stats; corresponding phone list: 110
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 121 with no stats; corresponding phone list: 122
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 163 with no stats; corresponding phone list: 164
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 175 with no stats; corresponding phone list: 176
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 176 with no stats; corresponding phone list: 177
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 177 with no stats; corresponding phone list: 178
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 203 with no stats; corresponding phone list: 204
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmm():gmm-init-model.cc:55) Tree has pdf-id 208 with no stats; corresponding phone list: 209
This is a bad warning.
steps/train_sat.sh: Converting alignments from exp/tri2b_ali to use current tree
steps/train_sat.sh: Compiling graphs of transcripts
ERROR: VectorFst::Read: Read failed: <unspecified>
ERROR (fstdeterminizestar[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:40) Could not read fst from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f78f14ef1ce]
fstdeterminizestar(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x55575df6e59d]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x370) [0x7f78f1553680]
fstdeterminizestar(main+0x244) [0x55575df6c47c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f78f0df9d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f78f0df9e40]
fstdeterminizestar(_start+0x25) [0x55575df6c165]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmsymbols[5.5.1050~1-0fb50]:ReadFstKaldiGeneric():kaldi-fst-io.cc:59) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7ff8b14a71ce]
fstrmsymbols(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x560291e95761]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldiGeneric(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool)+0x1c5) [0x7ff8b150abd1]
fstrmsymbols(main+0x30d) [0x560291e94bb6]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7ff8b0e98d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7ff8b0e98e40]
fstrmsymbols(_start+0x25) [0x560291e947e5]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmepslocal[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f1c1e8481ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7f1c1e8ad5fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7f1c1e8ac4ca]
fstrmepslocal(main+0x1b3) [0x557ea3dd9b7c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f1c1e152d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f1c1e152e40]
fstrmepslocal(_start+0x25) [0x557ea3dd9905]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstminimizeencoded[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f4e659871ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7f4e659ec5fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7f4e659eb4ca]
fstminimizeencoded(main+0x111) [0x558b27419b5a]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f4e65378d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f4e65378e40]
fstminimizeencoded(_start+0x25) [0x558b27419985]
kaldi::KaldiFatalErrorPass 1
Pass 2
Estimating fMLLR transforms
Pass 3
Pass 4
Estimating fMLLR transforms
Pass 5
Pass 6
Estimating fMLLR transforms
Pass 7
Pass 8
Pass 9
Pass 10
Aligning data
Pass 11
Pass 12
Estimating fMLLR transforms
Pass 13
Pass 14
Pass 15
Pass 16
Pass 17
Pass 18
Pass 19
Pass 20
Aligning data
Pass 21
Pass 22
Pass 23
Pass 24
Pass 25
Pass 26
Pass 27
Pass 28
Pass 29
Pass 30
Aligning data
Pass 31
Pass 32
Pass 33
Pass 34
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri3b
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri3b/log/analyze_alignments.log
273 warnings in exp/tri3b/log/update.*.log
9 warnings in exp/tri3b/log/init_model.log
8 warnings in exp/tri3b/log/questions.log
137 warnings in exp/tri3b/log/acc.*.*.log
1 warnings in exp/tri3b/log/compile_questions.log
17 warnings in exp/tri3b/log/fmllr.*.*.log
1 warnings in exp/tri3b/log/build_tree.log
8 warnings in exp/tri3b/log/est_alimdl.log
184 warnings in exp/tri3b/log/align.*.*.log
steps/train_sat.sh: Likelihood evolution:
-49.6847 -49.47 -49.3759 -49.1992 -48.6433 -48.0719 -47.7074 -47.4761 -47.3067 -46.8607 -46.6761 -46.4768 -46.3598 -46.2623 -46.1698 -46.0852 -46.0069 -45.9349 -45.8688 -45.714 -45.6215 -45.5655 -45.513 -45.4636 -45.4176 -45.372 -45.3275 -45.2854 -45.2456 -45.1544 -45.0968 -45.0729 -45.0593 -45.05
exp/tri3b: nj=8 align prob=-47.86 over 25.48h [retry=0.6%, fail=0.0%] states=2096 gauss=15027 fmllr-impr=2.42 over 18.96h tree-impr=6.40
说话人自适应训练
#sat
#说话人自适应训练
#对特征进行FMLLR,而后训练GMM模型
steps/train_sat.sh --cmd "$train_cmd" 2500 15000 data/mfcc/train data/lang exp/tri2b_ali exp/tri3b || exit 1;
#test tri3b model
#对自适应模型的解码及测试
local/thchs-30_decode.sh --nj $n "steps/decode_fmllr.sh" exp/tri3b data/mfcc &
#sat_ali
#根据FMLLR模型对数据进行对齐可以看出核心任务是对特征码本做FMLLR以达到说话人自适应的目的
steps/align_fmllr.sh --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/tri3b exp/tri3b_ali || exit 1;
steps/train_sat.sh: done training SAT system in exp/tri3b
steps/align_fmllr.sh --nj 8 --cmd run.pl data/mfcc/train data/lang exp/tri3b exp/tri3b_ali
tree-info exp/tri3b/tree
tree-info exp/tri3b/tree
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
make-h-transducer --disambig-syms-out=exp/tri3b/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri3b/tree exp/tri3b/final.mdl
fstrmepslocal
fstrmsymbols exp/tri3b/graph_word/disambig_tid.int
fstdeterminizestar --use-log=true
fstminimizeencoded
fsttablecompose exp/tri3b/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
steps/align_fmllr.sh: aligning data in data/mfcc/train using exp/tri3b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
ERROR: VectorFst::Read: Read failed: <unspecified>
ERROR (fstdeterminizestar[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:40) Could not read fst from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7feaa1b411ce]
fstdeterminizestar(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x5570571aa59d]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x370) [0x7feaa1ba5680]
fstdeterminizestar(main+0x244) [0x5570571a847c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7feaa144bd90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7feaa144be40]
fstdeterminizestar(_start+0x25) [0x5570571a8165]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmsymbols[5.5.1050~1-0fb50]:ReadFstKaldiGeneric():kaldi-fst-io.cc:59) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f88614231ce]
fstrmsymbols(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x55a985f28761]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldiGeneric(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool)+0x1c5) [0x7f8861486bd1]
fstrmsymbols(main+0x30d) [0x55a985f27bb6]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f8860e14d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f8860e14e40]
fstrmsymbols(_start+0x25) [0x55a985f277e5]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmepslocal[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7fc71e2011ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7fc71e2665fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7fc71e2654ca]
fstrmepslocal(main+0x1b3) [0x56487be61b7c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7fc71db0bd90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7fc71db0be40]
fstrmepslocal(_start+0x25) [0x56487be61905]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstminimizeencoded[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f90cf9541ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7f90cf9b95fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7f90cf9b84ca]
fstminimizeencoded(main+0x111) [0x55649f117b5a]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f90cf345d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f90cf345e40]
fstminimizeencoded(_start+0x25) [0x55649f117985]
kaldi::KaldiFatalErrorsteps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri3b_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri3b_ali/log/analyze_alignments.log
3 warnings in exp/tri3b_ali/log/fmllr.*.log
61 warnings in exp/tri3b_ali/log/align_pass2.*.log
45 warnings in exp/tri3b_ali/log/align_pass1.*.log
quick模型训练
#quick
#quick模型训练
steps/train_quick.sh --cmd "$train_cmd" 4200 40000 data/mfcc/train data/lang exp/tri3b_ali exp/tri4b || exit 1;
#对quick训练得到的模型进行解码测试
#test tri4b model
local/thchs-30_decode.sh --nj $n "steps/decode_fmllr.sh" exp/tri4b data/mfcc &
#采用quick训练得到的模型对数据进行对齐
#quick_ali
steps/align_fmllr.sh --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/tri4b exp/tri4b_ali || exit 1;
#对开发数据集进行对齐
#quick_ali_cv
steps/align_fmllr.sh --nj $n --cmd "$train_cmd" data/mfcc/dev data/lang exp/tri4b exp/tri4b_ali_cv || exit 1;
steps/train_quick.sh --cmd run.pl 4200 40000 data/mfcc/train data/lang exp/tri3b_ali exp/tri4b
steps/train_quick.sh: feature type is lda
steps/train_quick.sh: using transforms from exp/tri3b_ali
steps/train_quick.sh: accumulating tree stats
steps/train_quick.sh: Getting questions for tree clustering.
steps/train_quick.sh: Building the tree
steps/train_quick.sh: Initializing the model
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 109 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 121 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 163 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 175 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 176 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 177 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 203 of new tree has no stats.
WARNING (gmm-init-model[5.5.1050~1-0fb50]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 208 of new tree has no stats.
steps/train_quick.sh: This is a bad warning.
steps/train_quick.sh: mixing up old model.
steps/train_quick.sh: converting old alignments
steps/train_quick.sh: compiling training graphs
steps/train_quick.sh: pass 1
steps/train_quick.sh: pass 2
steps/train_quick.sh: pass 3
steps/train_quick.sh: pass 4
steps/train_quick.sh: pass 5
steps/train_quick.sh: pass 6
steps/train_quick.sh: pass 7
steps/train_quick.sh: pass 8
steps/train_quick.sh: pass 9
steps/train_quick.sh: pass 10
steps/train_quick.sh: aligning data
steps/train_quick.sh: pass 11
steps/train_quick.sh: pass 12
steps/train_quick.sh: pass 13
steps/train_quick.sh: pass 14
steps/train_quick.sh: pass 15
steps/train_quick.sh: aligning data
steps/train_quick.sh: pass 16
steps/train_quick.sh: pass 17
steps/train_quick.sh: pass 18
steps/train_quick.sh: pass 19
steps/train_quick.sh: estimating alignment model
Done
steps/align_fmllr.sh --nj 8 --cmd run.pl data/mfcc/train data/lang exp/tri4b exp/tri4b_ali
tree-info exp/tri4b/tree
tree-info exp/tri4b/tree
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
make-h-transducer --disambig-syms-out=exp/tri4b/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri4b/tree exp/tri4b/final.mdl
fstrmsymbols exp/tri4b/graph_word/disambig_tid.int
fstrmepslocal
fstminimizeencoded
fstdeterminizestar --use-log=true
fsttablecompose exp/tri4b/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
steps/align_fmllr.sh: aligning data in data/mfcc/train using exp/tri4b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
ERROR: VectorFst::Read: Read failed: <unspecified>
ERROR (fstdeterminizestar[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:40) Could not read fst from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f4d1b6ad1ce]
fstdeterminizestar(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x55ab2291f59d]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x370) [0x7f4d1b711680]
fstdeterminizestar(main+0x244) [0x55ab2291d47c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f4d1afb7d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f4d1afb7e40]
fstdeterminizestar(_start+0x25) [0x55ab2291d165]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmsymbols[5.5.1050~1-0fb50]:ReadFstKaldiGeneric():kaldi-fst-io.cc:59) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f1cacd2d1ce]
fstrmsymbols(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x55761aba4761]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldiGeneric(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool)+0x1c5) [0x7f1cacd90bd1]
fstrmsymbols(main+0x30d) [0x55761aba3bb6]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f1cac71ed90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f1cac71ee40]
fstrmsymbols(_start+0x25) [0x55761aba37e5]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmepslocal[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7fd966e901ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7fd966ef55fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7fd966ef44ca]
fstrmepslocal(main+0x1b3) [0x56524d4f7b7c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7fd96679ad90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7fd96679ae40]
fstrmepslocal(_start+0x25) [0x56524d4f7905]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstminimizeencoded[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f2f0aba41ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7f2f0ac095fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7f2f0ac084ca]
fstminimizeencoded(main+0x111) [0x5628315c1b5a]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f2f0a595d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f2f0a595e40]
fstminimizeencoded(_start+0x25) [0x5628315c1985]
kaldi::KaldiFatalErrorsteps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri4b_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri4b_ali/log/analyze_alignments.log
3 warnings in exp/tri4b_ali/log/fmllr.*.log
55 warnings in exp/tri4b_ali/log/align_pass2.*.log
47 warnings in exp/tri4b_ali/log/align_pass1.*.log
steps/align_fmllr.sh --nj 8 --cmd run.pl data/mfcc/dev data/lang exp/tri4b exp/tri4b_ali_cv
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
steps/align_fmllr.sh: aligning data in data/mfcc/dev using exp/tri4b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
steps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri4b_ali_cv
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri4b_ali_cv/log/analyze_alignments.log
5 warnings in exp/tri4b_ali_cv/log/align_pass1.*.log
6 warnings in exp/tri4b_ali_cv/log/align_pass2.*.log
DNN training: stage 0: feature generation
producing fbank for train
steps/make_fbank.sh --nj 8 --cmd run.pl data/fbank/train exp/make_fbank/train fbank/train
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/train
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for train
steps/compute_cmvn_stats.sh data/fbank/train exp/fbank_cmvn/train fbank/train
Succeeded creating CMVN stats for train
producing fbank for dev
steps/make_fbank.sh --nj 8 --cmd run.pl data/fbank/dev exp/make_fbank/dev fbank/dev
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/dev
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for dev
steps/compute_cmvn_stats.sh data/fbank/dev exp/fbank_cmvn/dev fbank/dev
Succeeded creating CMVN stats for dev
producing fbank for test
Succeeded creating CMVN stats for test
producing test_fbank_phone
# steps/nnet/train.sh --copy_feats false --cmvn-opts "--norm-means=true --norm-vars=false" --hid-layers 4 --hid-dim 1024 --learn-rate 0.008 data/fbank/train data/fbank/dev data/lang exp/tri4b_ali exp/tri4b_ali_cv exp/tri4b_dnn
# Started at Wed Aug 31 17:50:20 CST 2022
#
steps/nnet/train.sh --copy_feats false --cmvn-opts --norm-means=true --norm-vars=false --hid-layers 4 --hid-dim 1024 --learn-rate 0.008 data/fbank/train data/fbank/dev data/lang exp/tri4b_ali exp/tri4b_ali_cv exp/tri4b_dnn
# INFO
steps/nnet/train.sh : Training Neural Network
dir : exp/tri4b_dnn
Train-set : data/fbank/train 10000, exp/tri4b_ali
CV-set : data/fbank/dev 893 exp/tri4b_ali_cv
LOG ([5.5.1050~1-0fb50]:main():cuda-gpu-available.cc:61)
### IS CUDA GPU AVAILABLE? 'baixf-G3-3579' ###
WARNING ([5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:243) Not in compute-exclusive mode. Suggestion: use 'nvidia-smi -c 3' to set compute exclusive mode
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:438) Selecting from 1 GPUs
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:453) cudaSetDevice(0): NVIDIA GeForce GTX 1050 free:3992M, used:47M, total:4040M, free/total:0.98815
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:501) Device: 0, mem_ratio: 0.98815
LOG ([5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:382) Trying to select device: 0
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:511) Success selecting device 0 free mem ratio: 0.98815
LOG ([5.5.1050~1-0fb50]:FinalizeActiveGpu():cu-device.cc:338) The active GPU is [0]: NVIDIA GeForce GTX 1050free:3788M, used:251M, total:4040M, free/total:0.937657 version 6.1
### HURRAY, WE GOT A CUDA GPU FOR COMPUTATION!!! ##
### Testing CUDA setup with a small computation (setup = cuda-toolkit + gpu-driver + kaldi):
### Test OK!
# PREPARING ALIGNMENTS
Using PDF targets from dirs 'exp/tri4b_ali' 'exp/tri4b_ali_cv'
hmm-info exp/tri4b_ali/final.mdl
copy-transition-model --binary=false exp/tri4b_ali/final.mdl exp/tri4b_dnn/final.mdl
LOG (copy-transition-model[5.5.1050~1-0fb50]:main():copy-transition-model.cc:62) Copied transition model.
# PREPARING FEATURES
# + 'apply-cmvn' with '--norm-means=true --norm-vars=false' using statistics : data/fbank/train/cmvn.scp, data/fbank/dev/cmvn.scp
feat-to-dim 'ark:copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- |' -
copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:-
apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:-
WARNING (feat-to-dim[5.5.1050~1-0fb50]:Close():kaldi-io.cc:515) Pipe copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | had nonzero return status 36096
# feature dim : 40 (input of 'feature_transform')
# + default 'feature_transform_proto' with splice +/-5 frames,
nnet-initialize --binary=false exp/tri4b_dnn/splice5.proto exp/tri4b_dnn/tr_splice5.nnet
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Splice> <InputDim> 40 <OutputDim> 440 <BuildVector> -5:5 </BuildVector>
LOG (nnet-initialize[5.5.1050~1-0fb50]:main():nnet-initialize.cc:63) Written initialized model to exp/tri4b_dnn/tr_splice5.nnet
# feature type : plain
# compute normalization stats from 10k sentences
compute-cmvn-stats ark:- exp/tri4b_dnn/cmvn-g.stats
nnet-forward --print-args=true --use-gpu=yes exp/tri4b_dnn/tr_splice5.nnet 'ark:copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- |' ark:-
WARNING (nnet-forward[5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:243) Not in compute-exclusive mode. Suggestion: use 'nvidia-smi -c 3' to set compute exclusive mode
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:438) Selecting from 1 GPUs
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:453) cudaSetDevice(0): NVIDIA GeForce GTX 1050 free:3992M, used:47M, total:4040M, free/total:0.98815
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:501) Device: 0, mem_ratio: 0.98815
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:382) Trying to select device: 0
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:511) Success selecting device 0 free mem ratio: 0.98815
LOG (nnet-forward[5.5.1050~1-0fb50]:FinalizeActiveGpu():cu-device.cc:338) The active GPU is [0]: NVIDIA GeForce GTX 1050 free:3788M, used:251M, total:4040M, free/total:0.937657 version 6.1
copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:-
apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:-
LOG (copy-feats[5.5.1050~1-0fb50]:main():copy-feats.cc:143) Copied 10000 feature matrices.
LOG (apply-cmvn[5.5.1050~1-0fb50]:main():apply-cmvn.cc:162) Applied cepstral mean normalization to 10000 utterances, errors on 0
LOG (nnet-forward[5.5.1050~1-0fb50]:main():nnet-forward.cc:192) Done 10000 files in 0.841963min, (fps 181658)
LOG (compute-cmvn-stats[5.5.1050~1-0fb50]:main():compute-cmvn-stats.cc:168) Wrote global CMVN stats to exp/tri4b_dnn/cmvn-g.stats
LOG (compute-cmvn-stats[5.5.1050~1-0fb50]:main():compute-cmvn-stats.cc:171) Done accumulating CMVN stats for 10000 utterances; 0 had errors.
# + normalization of NN-input at 'exp/tri4b_dnn/tr_splice5_cmvn-g.nnet'
nnet-concat --binary=false exp/tri4b_dnn/tr_splice5.nnet 'cmvn-to-nnet --std-dev=1.0 exp/tri4b_dnn/cmvn-g.stats -|' exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:53) Reading exp/tri4b_dnn/tr_splice5.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:65) Concatenating cmvn-to-nnet --std-dev=1.0 exp/tri4b_dnn/cmvn-g.stats -|
cmvn-to-nnet --std-dev=1.0 exp/tri4b_dnn/cmvn-g.stats -
LOG (cmvn-to-nnet[5.5.1050~1-0fb50]:main():cmvn-to-nnet.cc:114) Written cmvn in 'nnet1' model to: -
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:82) Written model to exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
### Showing the final 'feature_transform':
nnet-info exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
num-components 3
input-dim 40
output-dim 440
number-of-parameters 0.00088 millions
component 1 : <Splice>, input-dim 40, output-dim 440,
frame_offsets [ -5 -4 -3 -2 -1 0 1 2 3 4 5 ]
component 2 : <AddShift>, input-dim 440, output-dim 440,
shift_data ( min -0.00404477, max 0.0024458, mean -0.000288983, stddev 0.000940905, skewness -0.818492, kurtosis 1.721 ) , lr-coef 0
component 3 : <Rescale>, input-dim 440, output-dim 440,
scale_data ( min 0.236916, max 0.392197, mean 0.289203, stddev 0.0389445, skewness 0.623488, kurtosis -0.290958 ) , lr-coef 0
LOG (nnet-info[5.5.1050~1-0fb50]:main():nnet-info.cc:57) Printed info about exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
###
# NN-INITIALIZATION
# getting input/output dims :
feat-to-dim 'ark:copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | nnet-forward "exp/tri4b_dnn/final.feature_transform" ark:- ark:- |' -
copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:-
apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:-
nnet-forward exp/tri4b_dnn/final.feature_transform ark:- ark:-
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:168) Manually selected to compute on CPU.
WARNING (feat-to-dim[5.5.1050~1-0fb50]:Close():kaldi-io.cc:515) Pipe copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | nnet-forward "exp/tri4b_dnn/final.feature_transform" ark:- ark:- | had nonzero return status 36096
# genrating network prototype exp/tri4b_dnn/nnet.proto
# initializing the NN 'exp/tri4b_dnn/nnet.proto' -> 'exp/tri4b_dnn/nnet.init'
nnet-initialize --seed=777 exp/tri4b_dnn/nnet.proto exp/tri4b_dnn/nnet.init
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 440 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.037344 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.109375 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.109375 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.109375 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 3392 <BiasMean> 0.000000 <BiasRange> 0.000000 <ParamStddev> 0.074485 <LearnRateCoef> 1.000000 <BiasLearnRateCoef> 0.100000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Softmax> <InputDim> 3392 <OutputDim> 3392
LOG (nnet-initialize[5.5.1050~1-0fb50]:main():nnet-initialize.cc:63) Written initialized model to exp/tri4b_dnn/nnet.init
# RUNNING THE NN-TRAINING SCHEDULER
steps/nnet/train_scheduler.sh --feature-transform exp/tri4b_dnn/final.feature_transform --learn-rate 0.008 exp/tri4b_dnn/nnet.init ark:copy-feats scp:exp/tri4b_dnn/train.scp ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | ark:copy-feats scp:exp/tri4b_dnn/cv.scp ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/dev/utt2spk scp:data/fbank/dev/cmvn.scp ark:- ark:- | ark:ali-to-pdf exp/tri4b_ali/final.mdl "ark:gunzip -c exp/tri4b_ali/ali.*.gz |" ark:- | ali-to-post ark:- ark:- | ark:ali-to-pdf exp/tri4b_ali/final.mdl "ark:gunzip -c exp/tri4b_ali_cv/ali.*.gz |" ark:- | ali-to-post ark:- ark:- | exp/tri4b_dnn
CROSSVAL PRERUN AVG.LOSS 8.4100 (Xent),
ITERATION 01: TRAIN AVG.LOSS 2.0844, (lrate0.008), CROSSVAL AVG.LOSS 2.2329, nnet accepted (nnet_iter01_learnrate0.008_tr2.0844_cv2.2329)
ITERATION 02: TRAIN AVG.LOSS 1.4095, (lrate0.008), CROSSVAL AVG.LOSS 2.0038, nnet accepted (nnet_iter02_learnrate0.008_tr1.4095_cv2.0038)
ITERATION 03: TRAIN AVG.LOSS 1.2454, (lrate0.008), CROSSVAL AVG.LOSS 1.9345, nnet accepted (nnet_iter03_learnrate0.008_tr1.2454_cv1.9345)
ITERATION 04: steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/mono/graph_word exp/mono/decode_test_word
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_word/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(3,36,179) and mean=70.2
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_word/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test exp/mono/graph_word exp/mono/decode_test_word
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
Traceback (most recent call last):
File "local/wer_output_filter", line 15, in <module>
v = v.encode('utf-8').decode('utf-8')
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
steps/decode.sh: Error: scoring failed. (ignore by '--skip-scoring true')
TRAIN AVG.LOSS 1.1448, (lrate0.008), CROSSVAL AVG.LOSS 1.9161, nnet accepted (nnet_iter04_learnrate0.008_tr1.1448_cv1.9161)
ITERATION 05: TRAIN AVG.LOSS 1.0634, (lrate0.004), CROSSVAL AVG.LOSS 1.7115, nnet accepted (nnet_iter05_learnrate0.004_tr1.0634_cv1.7115)
ITERATION 06: TRAIN AVG.LOSS 1.0256, (lrate0.002), CROSSVAL AVG.LOSS 1.5842, nnet accepted (nnet_iter06_learnrate0.002_tr1.0256_cv1.5842)
ITERATION 07: TRAIN AVG.LOSS 1.0191, (lrate0.001), CROSSVAL AVG.LOSS 1.5023, nnet accepted (nnet_iter07_learnrate0.001_tr1.0191_cv1.5023)
ITERATION 08: TRAIN AVG.LOSS 1.0233, (lrate0.0005), CROSSVAL AVG.LOSS 1.4487, nnet accepted (nnet_iter08_learnrate0.0005_tr1.0233_cv1.4487)
ITERATION 09: TRAIN AVG.LOSS 1.0284, (lrate0.00025), CROSSVAL AVG.LOSS 1.4156, nnet accepted (nnet_iter09_learnrate0.00025_tr1.0284_cv1.4156)
ITERATION 10: TRAIN AVG.LOSS 1.0315, (lrate0.000125), CROSSVAL AVG.LOSS 1.3976, nnet accepted (nnet_iter10_learnrate0.000125_tr1.0315_cv1.3976)
ITERATION 11: TRAIN AVG.LOSS 1.0327, (lrate6.25e-05), CROSSVAL AVG.LOSS 1.3882, nnet accepted (nnet_iter11_learnrate6.25e-05_tr1.0327_cv1.3882)
ITERATION 12: TRAIN AVG.LOSS 1.0327, (lrate3.125e-05), CROSSVAL AVG.LOSS 1.3837, nnet accepted (nnet_iter12_learnrate3.125e-05_tr1.0327_cv1.3837)
ITERATION 13: TRAIN AVG.LOSS 1.0323, (lrate1.5625e-05), CROSSVAL AVG.LOSS 1.3816, nnet accepted (nnet_iter13_learnrate1.5625e-05_tr1.0323_cv1.3816)
ITERATION 14: TRAIN AVG.LOSS 1.0318, (lrate7.8125e-06), CROSSVAL AVG.LOSS 1.3806, nnet accepted (nnet_iter14_learnrate7.8125e-06_tr1.0318_cv1.3806)
finished, too small rel. improvement 0.000752729
steps/nnet/train_scheduler.sh: Succeeded training the Neural Network : 'exp/tri4b_dnn/final.nnet'
steps/nnet/train.sh: Successfuly finished. 'exp/tri4b_dnn'
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --srcdir exp/tri4b_dnn --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn/decode_test_phone
steps/nnet/align.sh --nj 8 --cmd run.pl data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_ali
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --srcdir exp/tri4b_dnn --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn/decode_test_word
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/align.sh: aligning data 'data/fbank/train' using nnet/model 'exp/tri4b_dnn', putting alignments in 'exp/tri4b_dnn_ali'
# Accounting: time=6894 threads=1
# Ended (code 0) at Wed Aug 31 19:45:14 CST 2022, elapsed time 6894 seconds
steps/nnet/align.sh: done aligning data.
steps/nnet/make_denlats.sh --nj 8 --cmd run.pl --mem 4G --config conf/decode_dnn.config --acwt 0.1 data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_denlats
Making unigram grammar FST in exp/tri4b_dnn_denlats/lang
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: not warning for OOVs any more times
** Replaced 22 instances of OOVs with 2
Compiling decoding graph in exp/tri4b_dnn_denlats/dengraph
tree-info exp/tri4b_dnn/tree
tree-info exp/tri4b_dnn/tree
fstpushspecial
fstminimizeencoded
fstdeterminizestar --use-log=true
fsttablecompose exp/tri4b_dnn_denlats/lang/L_disambig.fst exp/tri4b_dnn_denlats/lang/G.fst
fstisstochastic exp/tri4b_dnn_denlats/lang/tmp/LG.fst
-0.0323879 -0.0325606
[info]: LG not stochastic.
fstcomposecontext --context-size=3 --central-position=1 --read-disambig-syms=exp/tri4b_dnn_denlats/lang/phones/disambig.int --write-disambig-syms=exp/tri4b_dnn_denlats/lang/tmp/disambig_ilabels_3_1.int exp/tri4b_dnn_denlats/lang/tmp/ilabels_3_1.541227 exp/tri4b_dnn_denlats/lang/tmp/LG.fst
fstisstochastic exp/tri4b_dnn_denlats/lang/tmp/CLG_3_1.fst
0 -0.0325606
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/tri4b_dnn_denlats/dengraph/disambig_tid.int --transition-scale=1.0 exp/tri4b_dnn_denlats/lang/tmp/ilabels_3_1 exp/tri4b_dnn/tree exp/tri4b_dnn/final.mdl
fsttablecompose exp/tri4b_dnn_denlats/dengraph/Ha.fst exp/tri4b_dnn_denlats/lang/tmp/CLG_3_1.fst
fstminimizeencoded
fstdeterminizestar --use-log=true
fstrmepslocal
fstrmsymbols exp/tri4b_dnn_denlats/dengraph/disambig_tid.int
fstisstochastic exp/tri4b_dnn_denlats/dengraph/HCLGa.fst
0.661133 -0.0799874
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/tri4b_dnn/final.mdl exp/tri4b_dnn_denlats/dengraph/HCLGa.fst
steps/nnet/make_denlats.sh: generating denlats from data 'data/fbank/train', putting lattices in 'exp/tri4b_dnn_denlats'
steps/nnet/make_denlats.sh: done generating denominator lattices.
steps/nnet/train_mpe.sh --cmd run.pl --gpu 1 --num-iters 3 --acwt 0.1 --do-smbr false data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_ali exp/tri4b_dnn_denlats exp/tri4b_dnn_mpe
Pass 1 (learnrate 0.00001)
TRAINING FINISHED; Time taken = 6.98081 min; processed 21905.1 frames per second.
Done 9998 files, 2 with no reference alignments, 0 with no lattices, 0 with other errors.
Overall average frame-accuracy is 0.977291 over 9174910 frames.
Pass 2 (learnrate 1e-05)
TRAINING FINISHED; Time taken = 7.42708 min; processed 20588.9 frames per second.
Done 9998 files, 2 with no reference alignments, 0 with no lattices, 0 with other errors.
Overall average frame-accuracy is 0.978551 over 9174910 frames.
Pass 3 (learnrate 1e-05)
TRAINING FINISHED; Time taken = 7.18205 min; processed 21291.3 frames per second.
Done 9998 files, 2 with no reference alignments, 0 with no lattices, 0 with other errors.
Overall average frame-accuracy is 0.979353 over 9174910 frames.
MPE/sMBR training finished
Re-estimating priors by forwarding 10k utterances from training set.
steps/nnet/make_priors.sh --cmd run.pl --nj 8 data/fbank/train exp/tri4b_dnn_mpe
Accumulating prior stats by forwarding 'data/fbank/train' with 'exp/tri4b_dnn_mpe'
Succeeded creating prior counts 'exp/tri4b_dnn_mpe/prior_counts' from 'data/fbank/train'
steps/nnet/train_mpe.sh: Done. 'exp/tri4b_dnn_mpe'
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/3.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn_mpe/decode_test_phone_it3
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/2.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn_mpe/decode_test_phone_it2
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/2.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn_mpe/decode_test_word_it2
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/1.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn_mpe/decode_test_word_it1
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/1.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn_mpe/decode_test_phone_it1
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/3.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn_mpe/decode_test_word_it3
DAE: switching to per-utterance CMVN mode
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/compute_cmvn_stats.sh data/fbank/train exp/fbank_cmvn/train.per_utt fbank/per_utt
Succeeded creating CMVN stats for train
steps/compute_cmvn_stats.sh data/fbank/dev exp/fbank_cmvn/dev.per_utt fbank/per_utt
Succeeded creating CMVN stats for dev
steps/compute_cmvn_stats.sh data/fbank/test exp/fbank_cmvn/test.per_utt fbank/per_utt
Succeeded creating CMVN stats for test
steps/compute_cmvn_stats.sh data/fbank/test_phone exp/fbank_cmvn/test_phone.per_utt fbank/per_utt
Succeeded creating CMVN stats for test_phone
DAE: generate training data...
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/train exp/dae/gendata fbank/dae/train
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/train
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for train
steps/compute_cmvn_stats.sh data/dae/train exp/dae/cmvn fbank/dae/train
Succeeded creating CMVN stats for train
DAE: generating dev data...
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/dev/0db exp/dae/gendata fbank/dae/dev/0db
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/dev/0db
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for 0db
steps/compute_cmvn_stats.sh data/dae/dev/0db exp/dae/cmvn fbank/dae/dev/0db
Succeeded creating CMVN stats for 0db
DAE: generating test data...
producing fbanks for car
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/test/0db/car exp/dae/gendata fbank/dae/test/0db/car
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/test/0db/car
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for car
generating cmvn for test data car
steps/compute_cmvn_stats.sh data/dae/test/0db/car exp/dae/cmvn fbank/dae/test/0db/car
Succeeded creating CMVN stats for car
producing fbanks for white
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/test/0db/white exp/dae/gendata fbank/dae/test/0db/white
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/test/0db/white
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for white
generating cmvn for test data white
steps/compute_cmvn_stats.sh data/dae/test/0db/white exp/dae/cmvn fbank/dae/test/0db/white
Succeeded creating CMVN stats for white
producing fbanks for cafe
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/test/0db/cafe exp/dae/gendata fbank/dae/test/0db/cafe
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/test/0db/cafe
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for cafe
generating cmvn for test data cafe
steps/compute_cmvn_stats.sh data/dae/test/0db/cafe exp/dae/cmvn fbank/dae/test/0db/cafe
Succeeded creating CMVN stats for cafe
feat-to-dim scp:exp/tri4b_dnn_dae/tgt_feats.scp -
num_fea = 40
nnet-concat exp/tri4b_dnn_dae/final.feature_transform exp/tri4b_dnn_dae/final.nnet exp/tri4b_dnn_mpe/final.feature_transform exp/tri4b_dnn_dae/dae.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:53) Reading exp/tri4b_dnn_dae/final.feature_transform
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:65) Concatenating exp/tri4b_dnn_dae/final.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:65) Concatenating exp/tri4b_dnn_mpe/final.feature_transform
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:82) Written model to exp/tri4b_dnn_dae/dae.nnet
DAE: switch bach to per-speaker CMVN mode
steps/nnet/decode.sh --cmd run.pl --mem 4G --nj 8 --srcdir exp/tri4b_dnn_mpe exp/tri4b/graph_word data/dae/test/0db/car exp/tri4b_dnn_mpe/decode_word_0db/car
steps/nnet/decode.sh --cmd run.pl --mem 4G --nj 8 --srcdir exp/tri4b_dnn_mpe exp/tri4b/graph_word data/dae/test/0db/white exp/tri4b_dnn_mpe/decode_word_0db/white
steps/nnet/decode.sh --cmd run.pl --mem 4G --nj 8 --srcdir exp/tri4b_dnn_mpe exp/tri4b/graph_word data/dae/test/0db/cafe exp/tri4b_dnn_mpe/decode_word_0db/cafe
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
dnn模型训练
#train dnn model
#dnn模型训练,采用DNN来训练一个声学模型
local/nnet/run_dnn.sh --stage 0 --nj $n exp/tri4b exp/tri4b_ali exp/tri4b_ali_cv || exit 1;
dae模型训练
#train dae model
#dae模型训练,通过对语音数据添加噪声来得到有噪音的数据,而后调用nnet1/train_dnn.sh来对其进行训练,训练细节和dnn部分一样
#python2.6 or above is required for noisy data generation.
#To speed up the process, pyximport for python is recommeded.
local/dae/run_dae.sh $thchs || exit 1;
补充
执行run.sh的时候,要先执行cmd.sh和path.sh
#cmd.sh
export train_cmd="queue.pl -q wolf.cpu.q"
export decode_cmd="queue.pl -q wolf.cpu.q"
export cuda_cmd="queue.pl -q wolf.gpu.q"
运行环境,不同的并行处理方案要调用不同的脚本
我们首先需要配置是在单机还是在Oracle GridEngine集群上训练,这可以通过cmd.sh来配置。如果我们没有GridEngine(通常没有),那么需要把所有的queue.pl改成run.pl。(GPU CPU参与)
queue.ql: GridEngine多机运行,一种多cpu(gpu)的并行处理方案。
run.ql: 本地多进程。
e.g.如果出问题把queue,pl换成run.pl
steps/make_mfcc.sh --nj 8 --cmd queue.pl data/mfcc/train exp/make_mfcc/train mfcc/train
utils/validate_data_dir.sh: Successfully validated data-directory data/mfcc/train
steps/make_mfcc.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
queue.pl: Error submitting jobs to queue (return status was 32512)
queue log file is exp/make_mfcc/train/q/make_mfcc_train.log, command was qsub -v PATH -cwd -S /bin/bash -j y -l arch=*64* -o exp/make_mfcc/train/q/make_mfcc_train.log -t 1:8 /home/baixf/kaldi/egs/thchs30/s5/exp/make_mfcc/train/q/make_mfcc_train.sh >>exp/make_mfcc/train/q/make_mfcc_train.log 2>&1
Output of qsub was: sh: 1: qsub: not found


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?