
Class5 基于GMM-HMM的语音识别系统
1. 基于孤立词的GMM-HMM语音识别系统
问题简化,我们考虑(0-9)数字识别。整体思路:

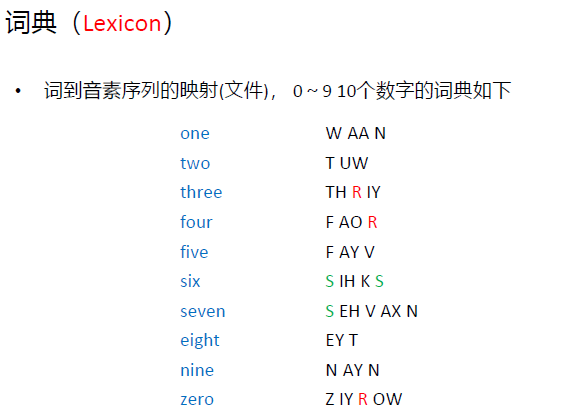
- 训练阶段,对于每个词用不同的音频作为训练样本,构建一个生成模型P ( X ∣ W ) P(X|W),W是词,X是音频特征
- 解码阶段:给定一段音频特征,经过训练得到的模型,看哪个词生成这段音频的概率最大,取最大的那个词作为识别结果。

假设我们给每个词建立了一个模型,P1、P2计算在每个词上的概率,选择所有词中概率最大的词作为识别结果。用什么方法进行建模:DNN,GMM?这些够可以进行建模,但是语音任务的特点是序列性,不定长性,很难使用DNN、GMM直接进行建模。为了解决这些问题,我们可以利用HMM来进行序列建模。
语音是一个序列,P(X)可以用HMM的概率问题来描述,并且其中的观测是连续概率密度分布,我们可以为每个词建立一个GMM-HMM模型。
建模
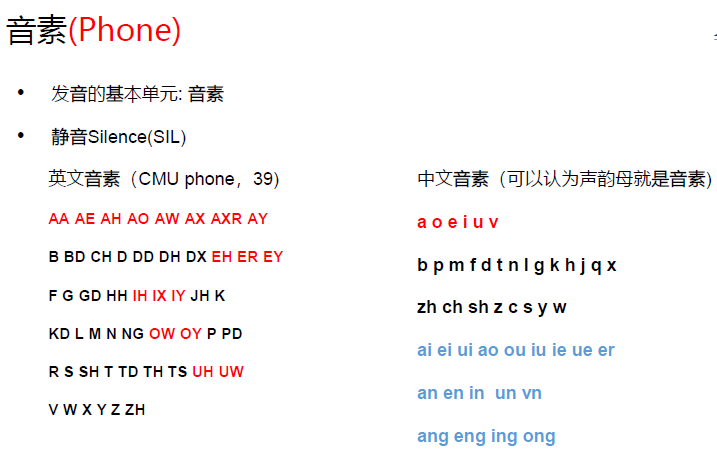
语音识别中的GMM,采用对角GMM(协方差为对角阵),因为一般我们使用MFCC特征,MFCC特征各维之间已经做了去相关处理,各维之间相互独立,直接使用对角阵就可以描述,而且对角GMM参数量小。
语音识别中的HMM,采用3状态,左右模型的HMM:
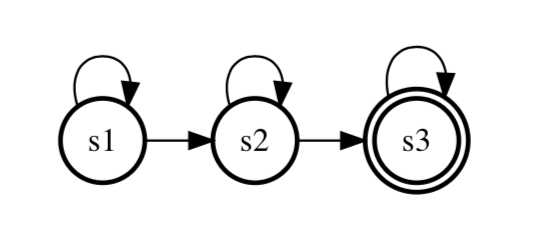
- 为什么采用3状态?这是前人大量实验给出的经验值;
- 左右模型的HMM:对于每个状态,它只能跳转到自身或者下一个状态。类似于人的发音过程,连续不可逆。
HMM、GMM语音识别中如何结合?
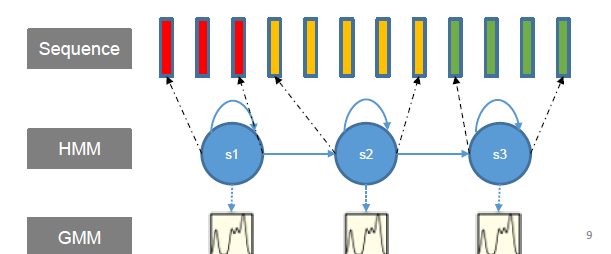
对于每个状态有一个GMM模型,对于每个词有一个HMM模型,当一段语音输入后,根据Viterbi算法得到一个序列在GMM-HMM上的概率,然后通过Viterbi回溯得到每帧属于HMM的哪个状态(对齐)。
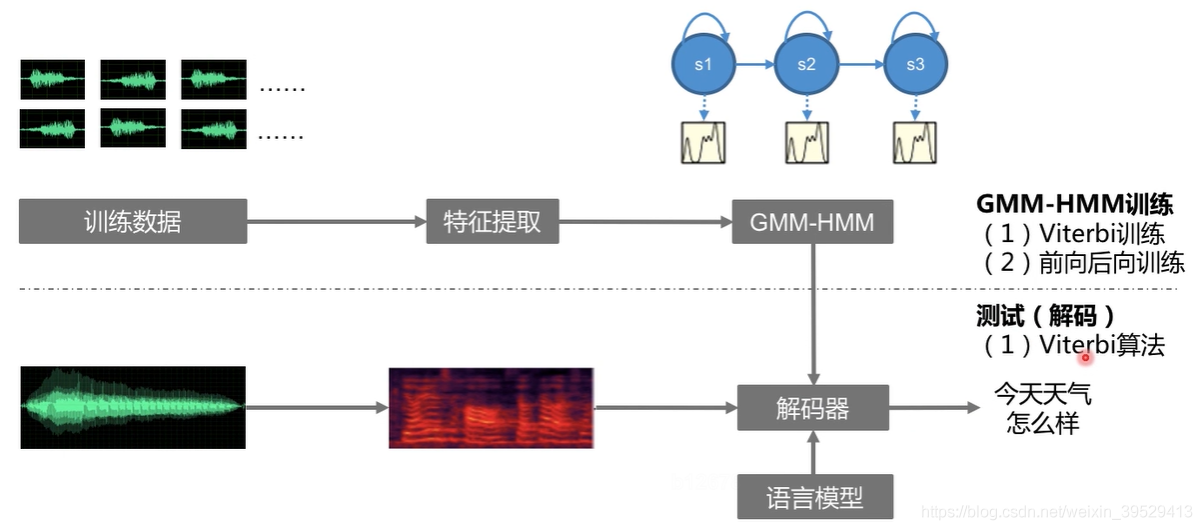
训练
Viterbi算法与Baum-Welch算法区别就在于对于时刻t状态为i的概率如何去估计。
Viterbi训练
- E步(hard count)
- Viterbi算法得到最优的状态序列(对齐),也就是在t时刻处于状态i上的概率(非0即1)
- GMM模型中在t时刻处于状态i第k个GMM分量的概率
- M步
- 更新转移参数、GMM参数(混合系数、均值、方差)
- 重复E、M步
如何初始化GMM-HMM模型的参数?把语音进行均等切分,给每个状态分配对应的特征,然后去估计初始化的参数。
前向后向训练(Baum-Welch训练)
- E步
- 通过前向后向算法得到在时刻t处于状态i的概率
- 在时刻t处于状态i且为GMM第k个分量的概率
- M步
- 更新转移参数、GMM参数(混合系数、均值、方差)
- 重复E、M步
解码
输入:各个词的GMM-HMM模型,未知的测试语音特征。
输出:哪个词。
关键点:对所有的词,如果计算P(X_test)。
方法:前向算法,或者Viterbi算法(可以回溯到最优的状态序列),一般采用Viterbi算法。
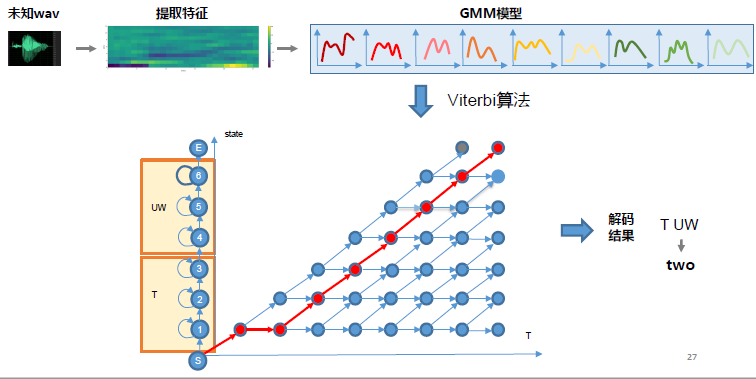
解码主要在图上做,我们现在看one two两个数字识别问题:

构建HMM模型的拓扑图以及紧凑的解码图:
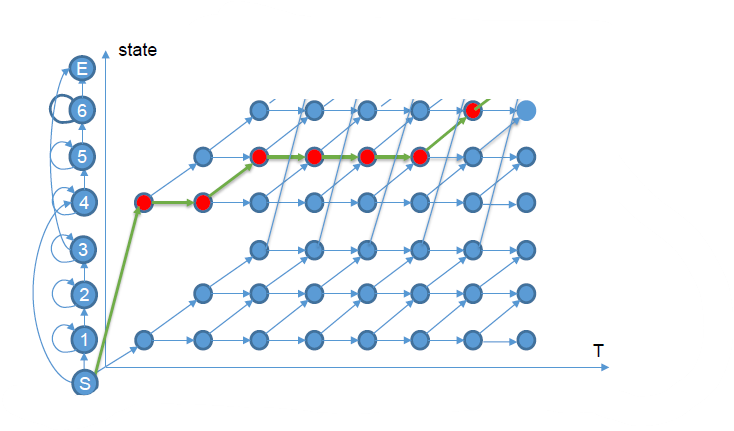

通过Viterbi算法,找过最优的路径得到最终输出的词(eg.one one one two two two)。那么如果我们需要对连续的多个词识别,需要如何建模?
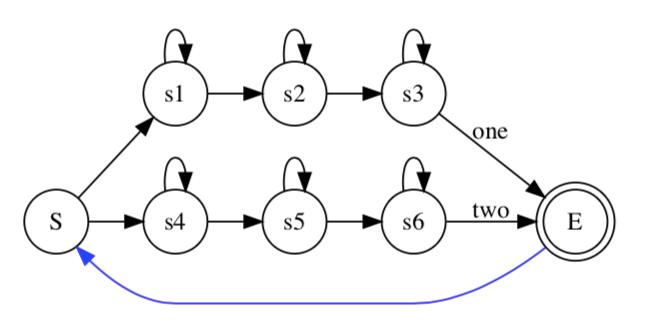
我们只需要再拓扑图上加一个循环连接,对于孤立词,如果达到了识别状态就结束了,对于连续词,如果达到了结束状态,就继续识别下一个词。
每个HMM内部还是采用Viterbi算法,在每个时刻对于每个状态选择一条最大概率的路径。因为是并行的,在某个时刻,可能同时会有多个词达到结束状态,分别对应着一段路径,然后又要同时进行下一个词的识别,那么为了避免多余的计算,采用和Viterbi一样的思路,只选取最大概率的路径,扔掉其他。
2. 基于单音素的GMM-HMM语音识别系统
孤立词系统的缺点:
- 建模单元数、计算量和词典大小成正比
- 词的状态数对每个词不用,长词使用的状态数更多
- OOV(out of Vocabulary)问题,训练中没有这个词,测试中存在这个词;
- 词并不是一个语言的基本发音单元
为了克服上边的问题,采用音素(Phone)和词典(Lexicon)建模。
每个音素使用经典的3状态左右模型的HMM拓扑结构:因为对于音素单元建模,科学家不断尝试和探索发现3状态的左右模型已经足够表达一个因素的变换。
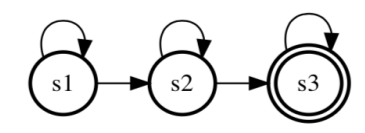
简化问题:假设一句话中包含一个单词,比如one(W AA N),即我们得到的是一个音素序列,我们可以很容易得到三个音素的HMM状态图,将状态图进行平滑连接(上图到下图)得到one的一整个HMM,然后进行和上述孤立词相同的过程。


问题:如果一句话中包含多个单词?如一个数字串。假设里面有多音字,如何处理?
这个采用和上述相同的方法,加入循环结构,当到达结束状态时进行下一个词的识别。对于多音字,通过词典(lexicon)和语言模型(language model)来解决。本质上是把多音字的每个读音(以及它们所组成的每个词)当成不同的词。
训练
对于一个单词里面包含多个音素的处理的本质就是对每一个音素做一个3状态的HMM建模,然后对多个因素做HMM的连接,把小的HMM变成大的HMM,在大的HMM上进行前行后向或者Viterbi。

解码
同以上基于孤义词的解码,是一个基于音素的解码架构,对于one two,分别对其因素序列做展开并连接起来,并同上一样做相应的Viterbi算法,只不过就是所对应的状态数量变为了针对音素的状态。

eg.一段未知音频,先经过特征提取,然后按帧去在所有状态的GMM上进行打分。
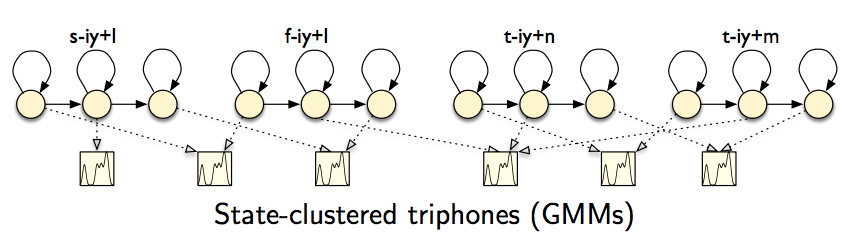
3. 基于三音素的GMM-HMM语音识别系统
单音素缺点:
- 建模单元数少,一般英文系统的音素数30-60个,中文的音素数100个左右;(整体表达能力少)
- 音素的发音受上下文影响(协同发音),比如:连读(not at all)、吞音(fist time)。
解决方案:可以考虑音素的上下文(Contex),一般考虑前一个/后一个,称为三音素,表示为A-B+C。
比如:KEEP(K IY P) ==> # - K + IY , K - IY + P, IY - P + #
问题1:假设有N个音素,一共有多少个三音素?N^3
问题2:有的三音素训练数据少或者不存在,怎么办?eg.连续辅音B-B+B,Z-Z+Z
问题3:有的三音素在训练中不存在,但在测试中有怎么办?
问题2和问题3通过参数共享解决,下文将介绍决策树。
参数共享
共享可以在不同层面:
- 共享高斯模型:所有状态都用同样的高斯模型,只是混合权重不一样;
- 共享状态:允许不同的HMM模型使用一些相同的状态;
- 共享模型:相似的三音素使用同样的HMM模型。
可以采用自顶向下的拆分,建立决策树来聚类。
三音素决策树

决策树是一个二叉树,每个非叶子节点上会有一个问题,叶子节点是一个绑定三音素的集合。绑定的粒度为状态(A-B+C和A-B+D的第1个状态绑定在一起,并不表示其第二第三个状态也要绑定在一起),也就是B的每个状态都有一颗小的决策树。
问题解决:
问题1:假设有N个音素,一共有N^3个三音素。绑定减少了建模单元。
问题2:有的三音素训练数据少或者不存在。绑定之后训练数据增多了。
问题3:有的三音素在训练中不存在,但在测试中有。对于任何三音素在决策树中都可以找到其位置。eg. zh-zh+zh会找到上图决策树的最右下面叶子节点,与其他三音素共享。
问题集
常见的有:
-
元音 AA AE AH AO AW AX AXR AY EH ER …
-
爆破音 B D G P T K
-
鼻音 M N NG
-
摩擦音 CH DH F JH S SH TH V Z ZH
-
流音 L R W Y
位置:左/右
问题集的构建:语言学家定义,Kaldi中通过自顶向下的聚类自动构建问题集。
决策树是基于状态的绑定
共享是一个基于状态的共享和绑定。
- Contextdependent State(CD-State)
- Senone
决策树的构建(最优问题)
- 初始状态(单因素系统对齐,一个根节点)
- 选择一个结点
- 从问题集中选择似然增益最大的问题作为该节点问题
- 建立该节点左右子节点,并将该节点上的统计量分为两部分
- 重复2,直至
- 达到一定数量的叶子结点
- 似然增益小于某个阈值
4. 基于GMM-HMM语音识别系统流程
- 数据准备:音素列表、词典、训练数据
- 特征提取:MFCC特征
- 单音素GMM-HMM:Viterbi训练
- 三音素GMM-HMM:三音素决策树、Viterbi训练
- 解码

问题:为什么先做单音素训练?
通过单音素模型上Viterbi算法得到与输入对应的最佳状态序列(对齐)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?