
Class 8 基于WFST的解码器
专有术语
- Grammar fst(G.fst) 语法模型,建模文本的概率,即N-gram语言模型,其实G是个FSA(acceptor),即输入和输出是一样的FST.
- Lexicon fst(L.fst) 词典模型,建模音素序列到词序列之间的关系
- Context-Dependent fst(C.fst)建模上下文相关音素序列到单音素序列的转换关系
- HMM fst(H.fst) 建模上下文相关音素HMM中的边序列到上下文相关音素序列的转换关系。
- self-loop 自跳转,fst中从当前state跳出仍回到该state的边
- ui-gram 一阶语言模型,当前词的条件概率和上下文无关
- bi-gram 二阶语言模型,当前词的条件概率只和前一个词有关
- backoff 语言模型中,对于训练集中缺失的N阶gram,使用N-1阶的概率进行估计
- recipe kaldi里的完成某个任务整个可执行脚本
- mono-phone 上下文无关单音素
- cd-phone 上下文相关音素,音素由于前后的音素不同会产生不同的发音,因此我们使用上下文相关音素建模往往比单音素要好。
- transition-id kaldi解码fst的输入单元,每个transition-id对应一个(phone, HMM-state, pdf-id, transition-index)元组
- pdf-id pdf-id的个数是决策树绑定后的聚类个数,也是声学模型中GMM的个数或者神经网络的输出节点个数。
解码
给定声学观测O = o1 , o2 , … , oT ,找到最可能的词序列W = w1 , w2 , … , wN :
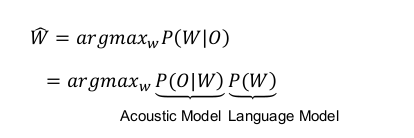
通过Viterbi算法找到了最可能的状态序列,我们就能恢复出最可能的词序列。但是从状态序列到词序列,我们还需要解码范围(HMM、cd-phone、phone)以及LM约束。
公式
给定声学观测O = o1 , o2 , … , oT ,找到最可能的词序列W = w1 , w2 , … , wN :
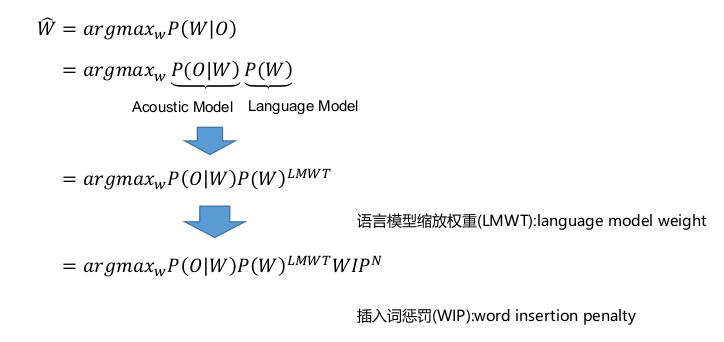
语言模型缩放权重(LMWT,language model weight):P(O|W)是HMM-level;P(W)是word-level;两者颗粒度相差较大,会导致LM几乎对argmax不起作用,即LM地位较低,为此需要LMWT操作,使两者平衡。在kaldi中使用LMST。
插入词惩罚(WIP,word insertion penalty):上面提到的LMWT存在边缘效应的缺点,即他会偏向于寻找短、多的词,也就是一种投机。因此提出了WIP算法。
框架
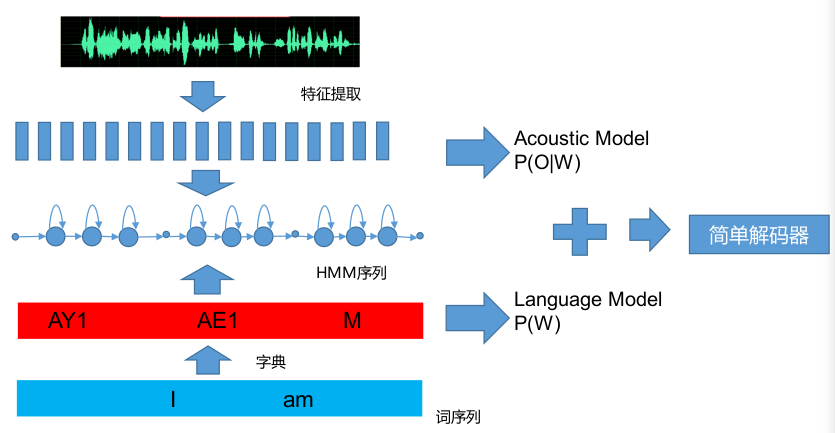
Viterbi算法应用:alignment和decoder。
Token Passing Algorithm(令牌环传递算法)
Token Passing算法就是Viterbi算法的实现
Token的设计:存储经过某状态的最优路径的概率,存储与全局最优路径的距离,以及帮
助寻找其它token或者回溯的指针。

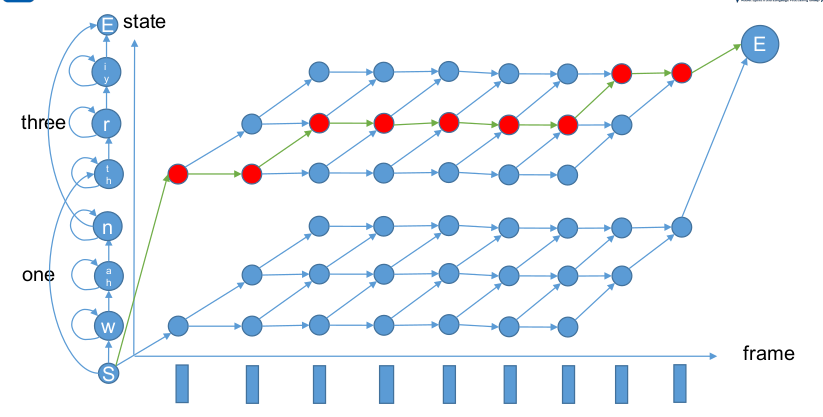
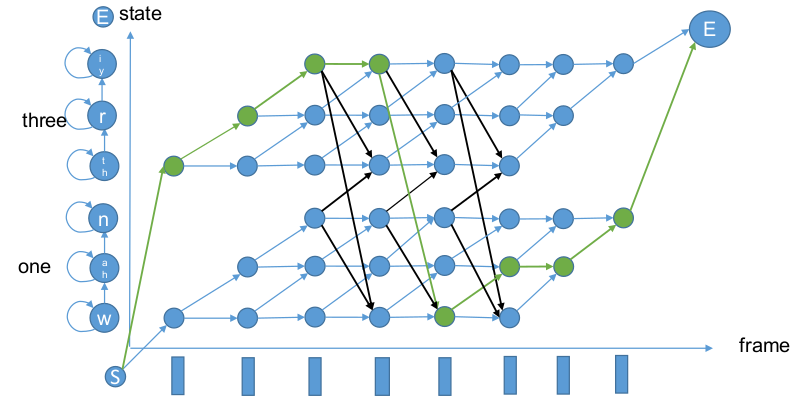
晶格网(trellis)
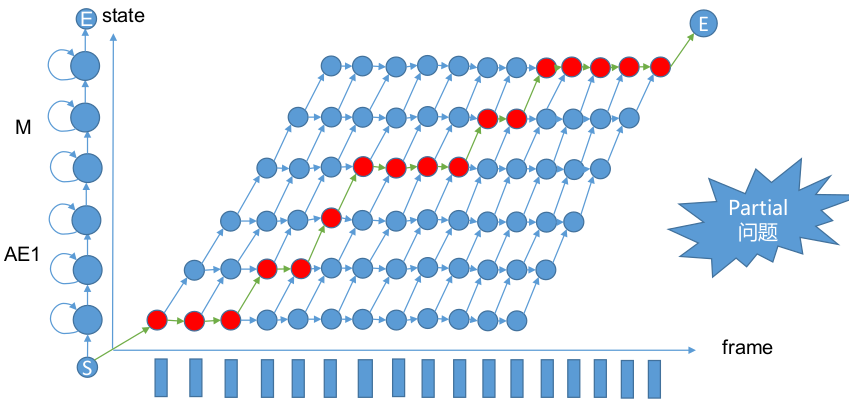
本晶格网以AM为例,采用Token Passing算法寻找最佳路径。
Partial问题(右下角为空)解释:一般终点认为是终止状态。
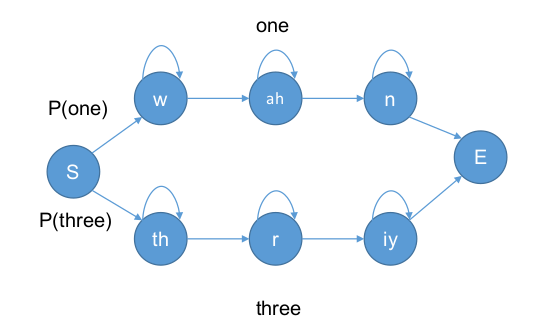
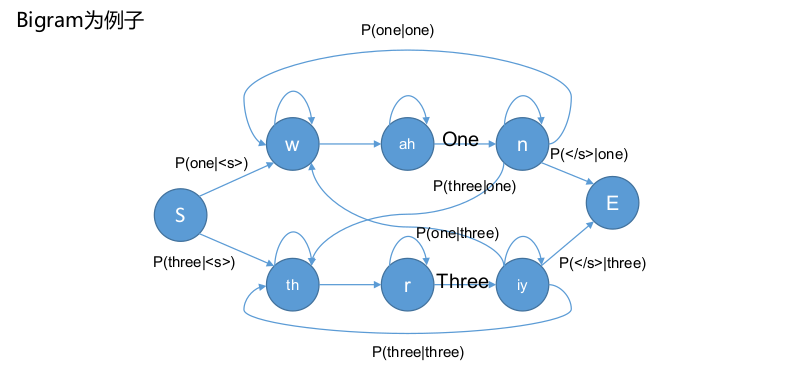
孤立词与LM
计算问题
Viterbi算法理论上准确有效的完成了解码工作,我们可以直接从E(终止状态)找到token,然后不断回溯,最终确定最佳序列W。
但是产生一条最优路径只是解码器的部分工作,对于解码器的研究,更重要的是生成一个准确的lattice,然后再进行后处理,如重打分(Re-scoring)[i.e. 多阶段解码]。我们在较长序列中训练的LM,wordlist会非常大。尤其是在LVCSR实际任务中会出现形成的N-gram条数存在过多的问题。
由于LVCSR实际任务中N-gram,Lexicon和triphone建模导致无法只简单的使用Viterbi算法,需要进行一些工程优化。
解码器

剪枝(Prunning)
思想:去除没有竞争力的路径。
工程使用:Bean Search + Histogram Pruning
kaldi参数:--beam;--max-active
- Beam Search: 每帧只保留Best Path以及与Best Path距离小于beam-threshold的tokens。(在处理逐帧token时同时处理)
- Histogram Pruning: 每帧只处理前Top N个tokens。(Beam Search执行完操作)
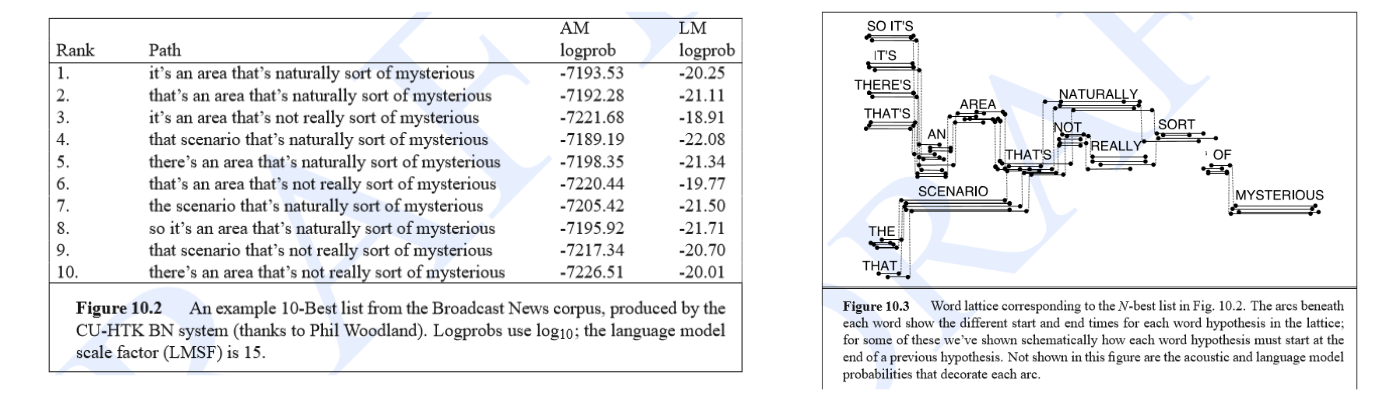
Lattice和N-best List
产生一条最优路径只是解码器的部分工作,对于解码器的研究,更重要的是生成一个准确的lattice,然后再进行后处理,如重打分(Re-scoring)[i.e. 多阶段解码]。
N-best List:解码获得最好的Top N条词序列。
Lattice: 他是一个有向图,有效的表示关于可能词序列的更多信息。[i.e. 把到达终点的
tokens走过路径的信息绘制在一张图里。]
A* decoder思想(简要)
其中f(s)就是purning操作。

字典树(简要)
共享的思想:将具有相同前缀的音素组合在一起表示。
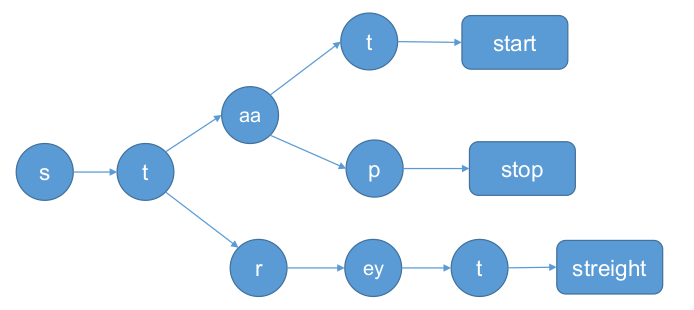
Language Look-ahead(简要)
在Tree Structured decoder中,把LM概率分配到结点上,而不是走到叶子结点才累
积LM概率,从而更早的剪枝。
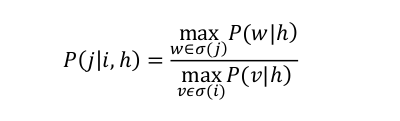
在一个字典树上,N-gram的history是h,i和j为树上两个结点,w为从j结点能到达的所有
词,v为从i结点能到达的所有词。那么从i结点到j结点上的概率由上式计算。
WFST介绍
试想你用高阶N-gram语言模型,一个有数以百万词的字典,构建一个解码图。这个解码图会费长的冗余,因此需要一种高效统一的解决办法:WFST构图
有限状态自动机
有限状态自动机可以表示为一个有向图。主要有两部分组成,分别是state(包含initial state,final state以及other)和arc(input label,output label以及weight)

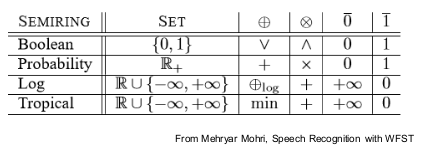
半环
- 有一个元素集合(e.g. R)
- 有两个特殊元素 零元 和 幺元
- 有两个操作⊕(加操作)和⨂ 乘操作 。
- 加操作有交换律,结合律,与零元相加为本身
- 乘操作有结合律,于幺元乘为本身
- 分配律:1 ⨂ 2 ⨁3 = 1 ⨂2 ⨁(1 ⨂3 )
Composition
组合:如果一个转换器A将序列x映射到序列y伴随着权重a,并且转换器B将序列y映射到序列z伴随着权重b,那么组合的转换器将序列x映射到序列z,权重为a ⨂ 。
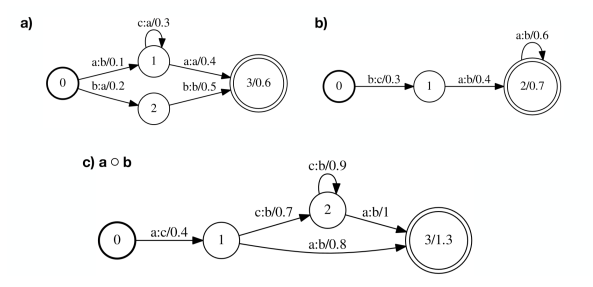
Determinization
确定化:创建等价的FST,任意一个状态都没有两个相同input label的出弧(arc).
条件:这个FST是functional的,即每一个输入序列可以转换成独一无二的输出序列。
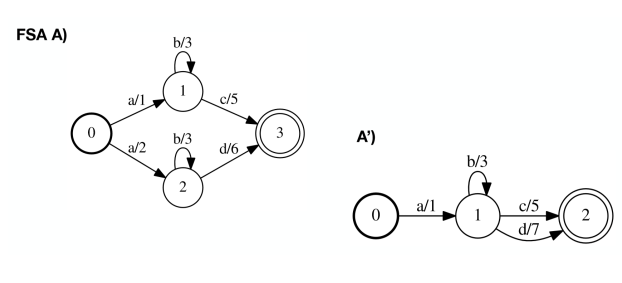
Minimization
最小化:创建等价的FST,拥有最少的状态数和弧数。
其它操作
- 弧排序(ArcSort):根据input label或者output label排序每个state的arcs。
- 链接(Connect): 剪枝FST,去掉所有不在成功路径(从初始状态到终止状态)的state和arcs。
- 相等(Equal): 确定两个FST(A和B)有相同数量和顺序的state,arcs。
- 等价(Equivalent):确定两个不含epsilon的确定化状态机(A和B)等价,即对于相同的输入,有相同输出和权重。
- 推(Push):将权重向初始状态或者终止状态推动
概念梳理图与HCLG
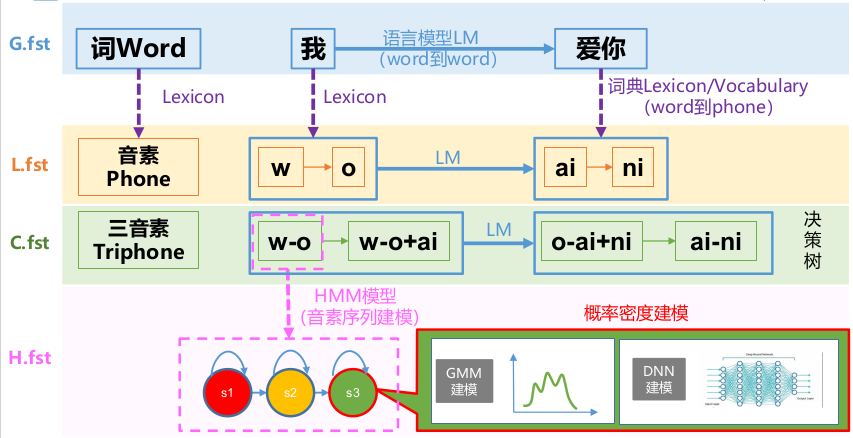
G.Fst示例解析
State 0和1为history=空
State 2-6为history=</s>,<s>,<Cay>,<K>,<ache>
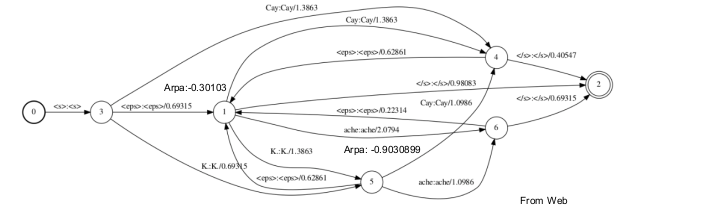
确定化的G.fst
a.用#0替换backoff边的input label
b.用epsilon替换和
c.确定化

L.Fst介绍
a. 消歧义符(disambiguation symbol,#1,#2…):解决发音前缀和同音异形字。
b. 为词前后添加silence。
c. Add-self-loop:为终止状态添加#0的自环,从而和G.fst合并。
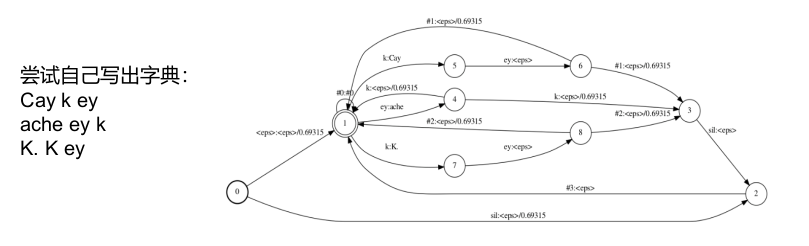
L compose G
addsubsequentialloop由于C的尾处理
Kaldi有一些自己的fst command-line,略不同于Openfst,源于具体问题的处理。使用fst时善用openfst/bin, openfst/src,kaldi/src/fstbin, kaldi/src/fstext
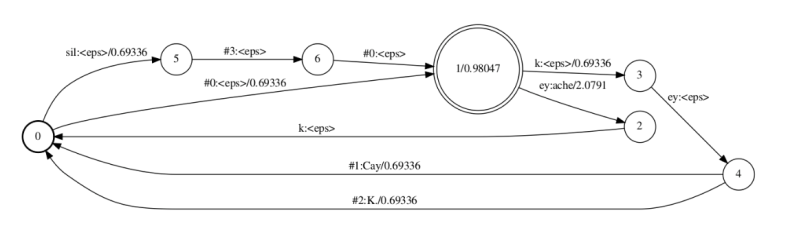
C.fst
a.通常Kaldi里不单独生成C,而是直接与LG进行compose,生成CLG [fstcomposecontext]。
这样可以动态生成,避免穷举所有cd-phone.
b.Kaldi用N表示窗长,P表示中心音素位置。[left-context1/phone/right-context1]=[N=3,P=1]
c.(N=3,P=1为例):每个arc的格式为left/phone/right:right,如a/b/c:c,这里输出的不是中心音
素。
d.用#-1和$处理开头结尾。
e.决策树会将你想的逻辑cd-phone变为绑定后的形式。[make-ilabel-transducer]
Logical cd-phone C的示意图:[Morhi的表示方法不同,格式为phone:phone/left_right]

H.fst
理想化:我们只要把pdf-id到cd-phone就可以了。
但由于kaldi的决策树一个pdf-id可以对应若干cd-phone,所以引入了transition-id
= (transition-state, transition-index)
transition-state = (phone, hmm-state, forward pdf, self-loop pdf)—new
= (phone, hmm-state, pdf)—new

识别中的WFST
对于HCLG:每个arc的ilabel=transition-id, olabel=word-id,weight为transition概率,LM概率等, weight pushing后的值。

识别中的WFST—基于kaldi
生成lattice—基于Viterbi的解码
常用操作:
遍历state:
fst::StateIterator<FST> siter(*fst_); !siter.Done(); siter.Next() {
const StateId &state_id = siter.Value(); ….
}
遍历arc:
fst::ArcIterator<FST> aiter(*fst_, state_id); !aiter.Done(); aiter.Next() {
const Arc &arc = aiter.Value();
BaseFloat graph_cost = arc.weight.Value();
}
识别中的WFST—生成lattice—所需数据结构
Token {
BaseFloat tot_cost;
// 从句子其实到当前位置的cost
BaseFloat extra_cost; // 穿过该状态的best path与全局best path距离
ForwardLinkT *links; // 发出的所有arc
Token *next; // 当前帧的下一个token
}
ForwardLink {
Token *next_token; // 目标token
Label ilabel; // 输入标签
Label olabel; // 输出标签
BaseFloat graph_cost; // wfst图上的weight (LM等)
BaseFloat acoustic_cost; // 发射概率
ForwardLink *next; //下一个link
}
生成lattice—核心函数
ProcessEmitting(): //处理那些需要发射概率的arc,即ilabel != 0。
ProcessNonemitting(): //处理那些不需要发射概率的arc,即ilabel == 0。
FindOrAddToken(): //创立新Token或对同一时刻,到达同一状态的token合并。
再看lattice
对于HCLG:每个arc的ilabel=transition-id, olabel=word-id, weight。
在kaldi里有Lattice和CompactLattice,是一个事物的两种存储形式,可以相互转化,在外观上都和HCLG
相似,由state和arc组成, 从中你可以知道概率分数和时间。
Lattice的arc:ilabel=transition-id, olabel=word-id, weight=(graph_cost, acoustic_cost)
CompactLattice的arc: ilabel=olabel=word-id, weight=(graph_cost, acoustic_cost,transition-idsequence).
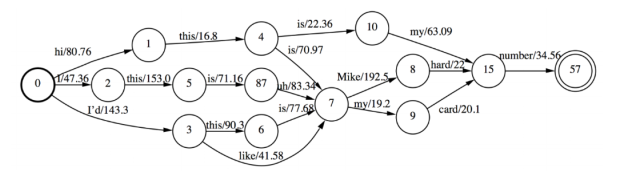
从lattice转换了解基本操作



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?