
ELK实时日志分析平台
一、ELK
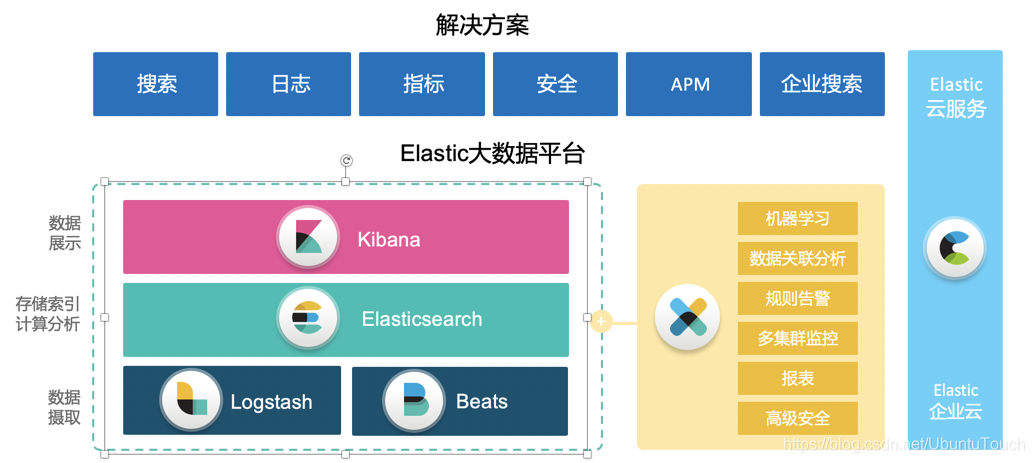
1.ELK 简介
-
Elasticsearch 是一个搜索和分析引擎。
-
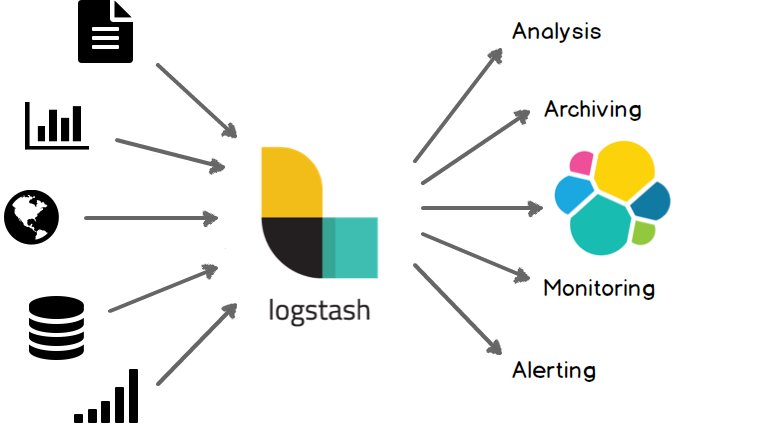
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等存储库中。
-
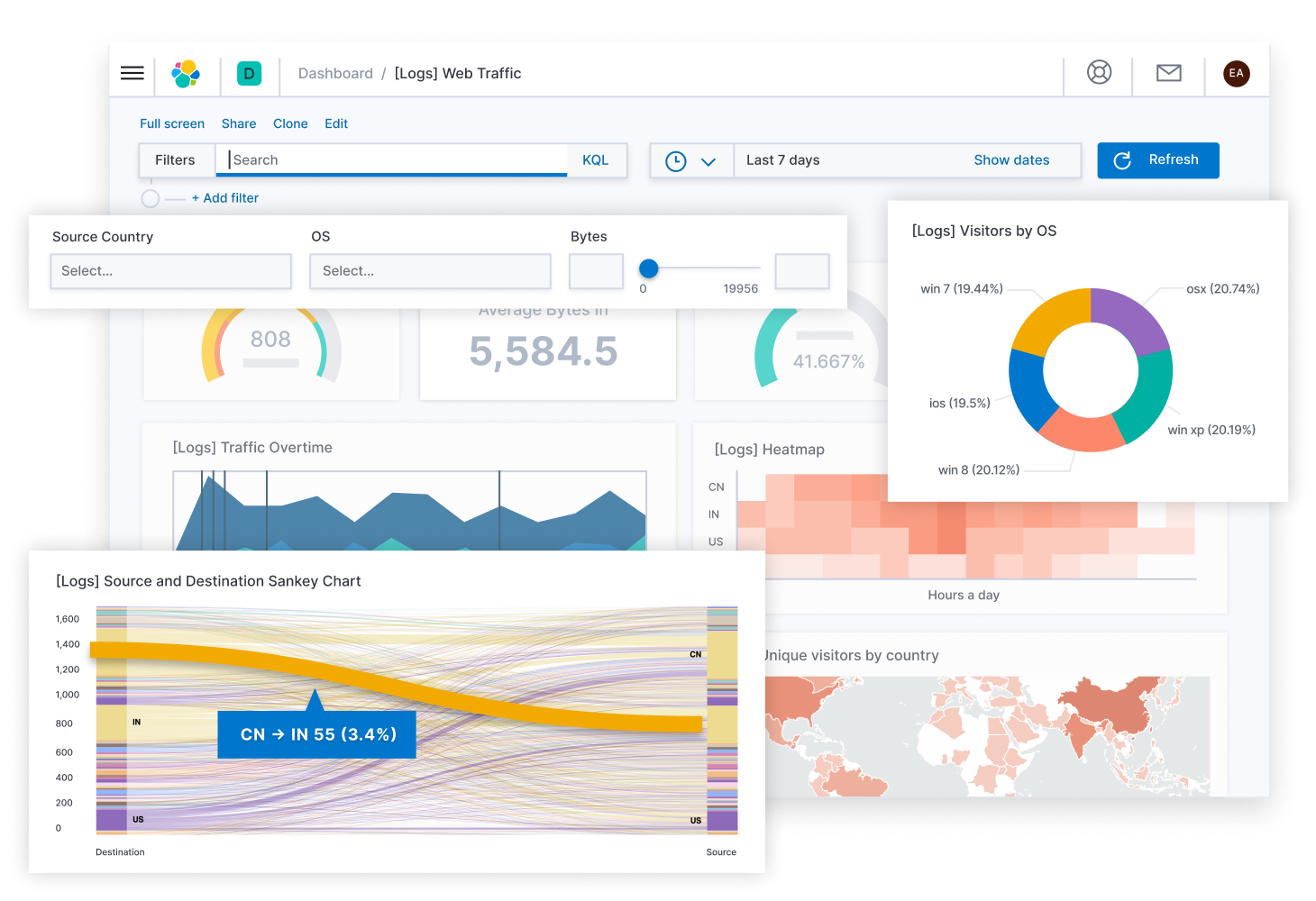
Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
事实上Elasticsearch的完整栈有如下的几个:
- Beats
Filebeat是本地文件的日志数据采集器。 作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,tail file,并将它们转发给Elasticsearch或Logstash进行索引、kafka 等。

- APM Server
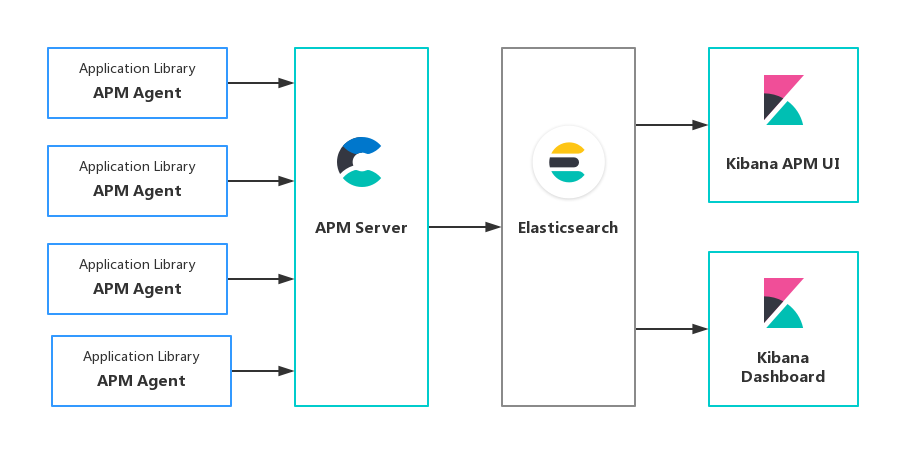
- Elasticsearch
- Elasticsearch Hadoop
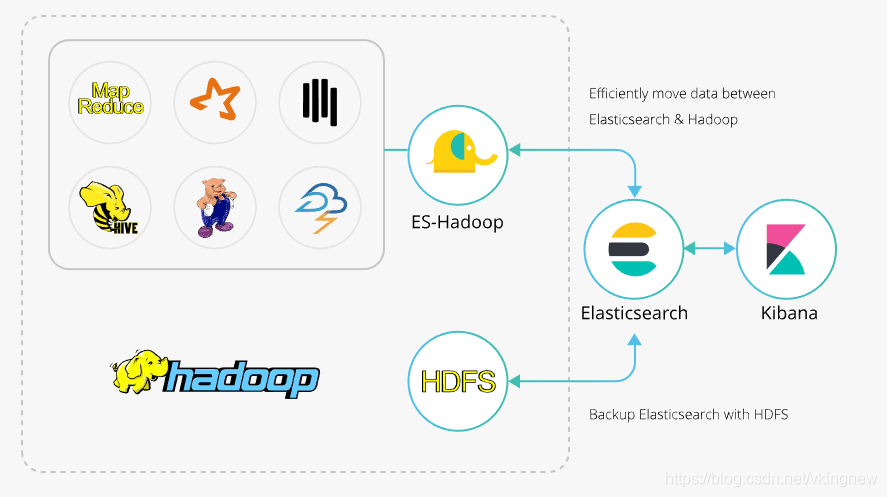
- Logstash
- Kibana
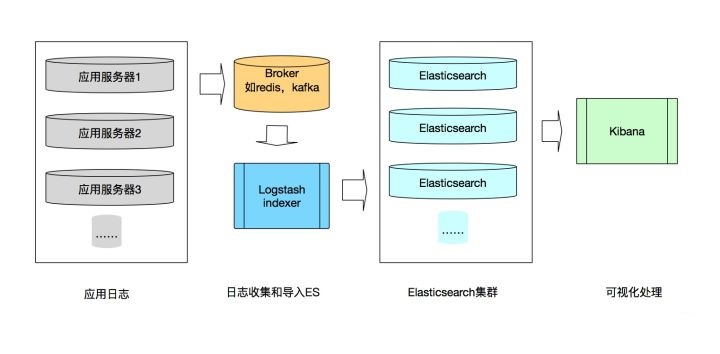
2.ELK日志系统数据流图
3.Elasticsearch
简单地说, Elaaticsearch 是一个分布式的使用REST接口的搜索引擎。Elasticsearch 是一个分布式的基于 REST 接口的为云而设计的搜索引擎,它的功能包括:
Elasticsearch是一个基于Apache Lucene (TM)的开源搜索引擎,无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene 只是一个库。Lucene 本身并不提供高可用性及分布式部署。想要发挥其强大的作用,你需使用 Java 并要将其集成到你的应用中。Lucene 非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
Elasticsearch 也是使用 Java 编写并使用 Lucene 来建立索引并实现搜索功能,但是它的目的是通过简单连贯的 RESTful API 让全文搜索变得简单并隐藏 Lucene 的复杂性。
不过,Elasticsearch 不仅仅是 Lucene 和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。上手 Elasticsearch 非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。Elasticsearch 在 Apache 2 license 下许可使用,可以免费下载、使用和修改。
随着知识的积累,你可以根据不同的问题领域定制 Elasticsearch 的高级特性,这一切都是可配置的,并且配置非常灵活。
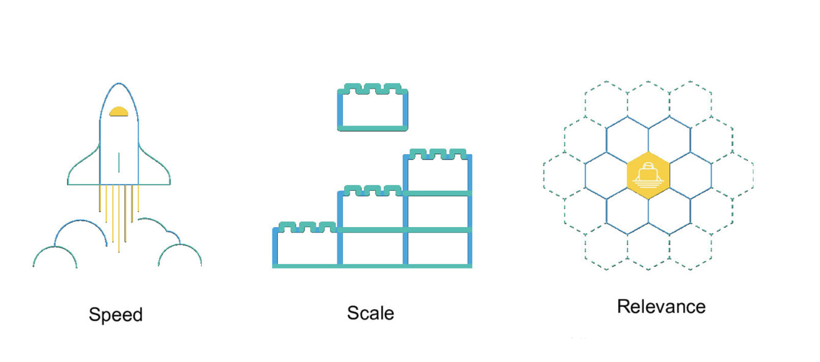
Elasticsearch 的特点是它提供了一个极速的搜索体验。这源于它的高速(speed)。相比较其它的一些大数据引擎,Elasticsearch 可以实现秒级的搜索,但是对于它们来说,可能需要数小时才能完成。Elasticsearch 的 cluster 是一种分布式的部署,极易扩展(scale)。这样很容易使它处理 petabytes 的数据库容量。最重要的是 Elasticsearch 是它搜索的结果可以按照分数进行排序,它能提供我们最相关的搜索结果(relevance)。
4.Elasticsearch中的一些重要概念
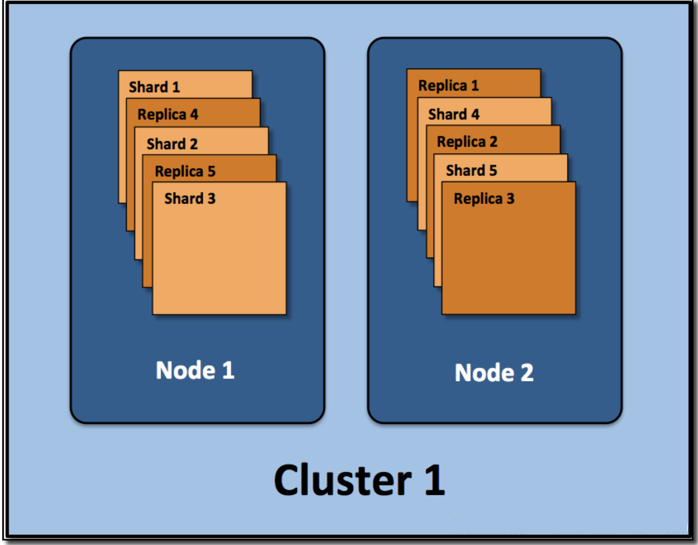
1.Cluster
Cluster 也就是集群的意思。Elasticsearch 集群由一个或多个节点组成,可通过其集群名称进行标识。通常这个 Cluster 的名字是可以在 Elasticsearch 里的配置文件中设置的。
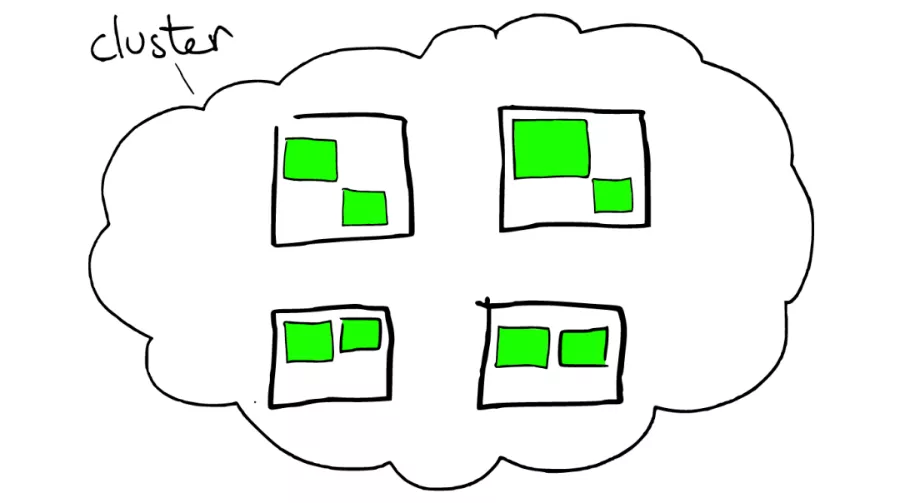
云上的集群如下图所示:
2.node
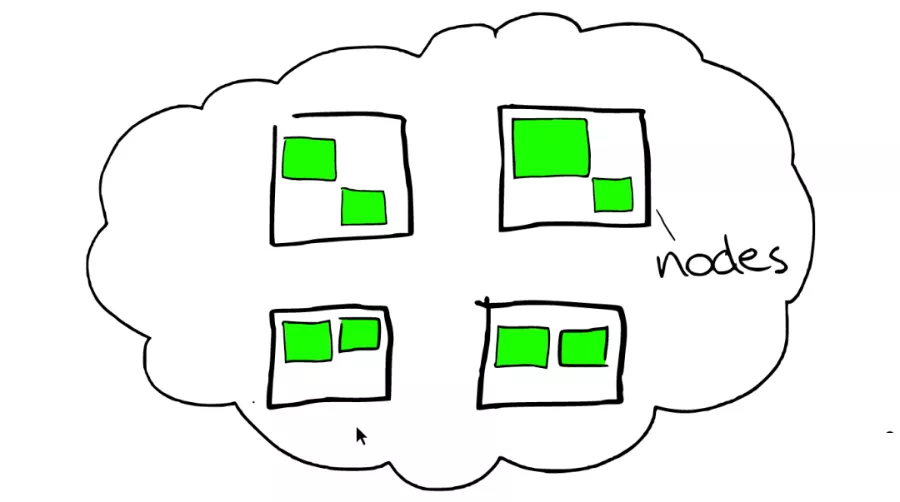
在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。一个集群由一个或多个 node 组成。在测试模拟集群的环境中,我可以把多个 node 运行在一个 server 上。但是在实际的部署中,大多数情况还是需要一个 server 上运行一个 node。
如图所示,云里面的每个白色正方形的盒子代表一个节点——Node。
3.Document
Elasticsearch 是面向文档的,这意味着您索引或搜索的最小数据单元是文档。
文档通常是数据的 JSON 表示形式。JSON over HTTP 是与 Elasticsearch 进行通信的最广泛使用的方式,它是我们在本书中使用的方法。例如,聚会网站中的事件可以在以下文档中表示:
{
"name": "Elasticsearch Denver",
"organizer": "Lee",
"location": "Denver, Colorado, USA"
}

4.type
类型是文档的逻辑容器,类似于表是行的容器。 您将具有不同结构(模式)的文档放在不同类型中。
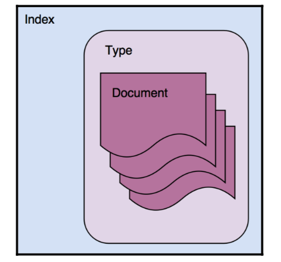
5.index
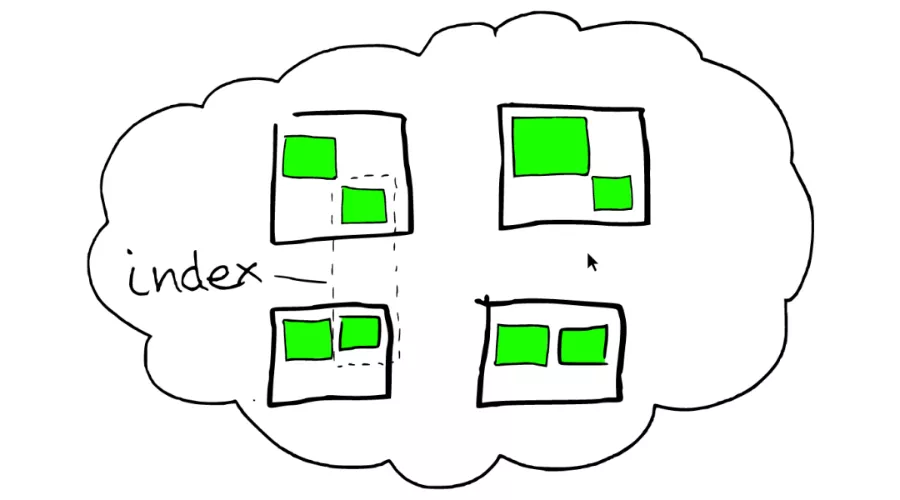
在 Elasticsearch 中,索引是文档的集合。
在一个或者多个节点之间,多个绿色小方块组合在一起形成一个 ElasticSearch 的索引。
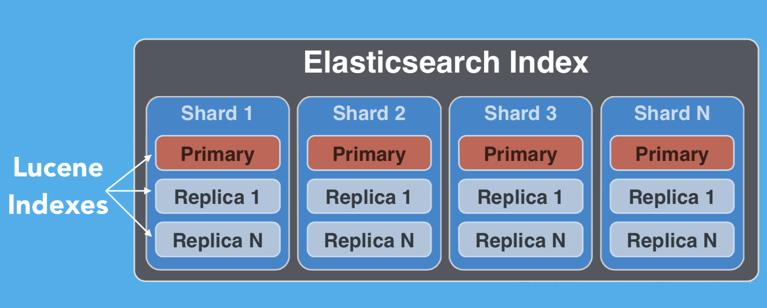
6.shard
在一个索引下,分布在多个节点里的绿色小方块称为分片——Shard。
一个索引可以存储超出单个结点硬件限制的大量数据,但是在处理搜索请求时,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做分片(shard)。由于 Elasticsearch 是一个分布式搜索引擎,当你创建一个索引的时候,你可以指定你想要的分片(shard)的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
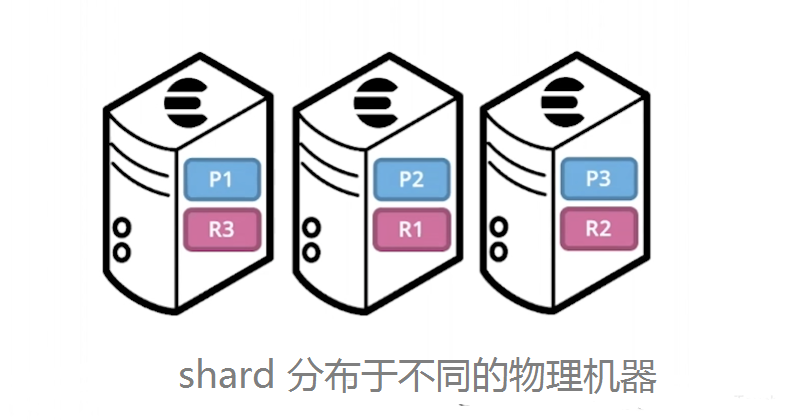
在一个索引下,分布在多个节点里的绿色小方块称为分片——Shard。
7.replica
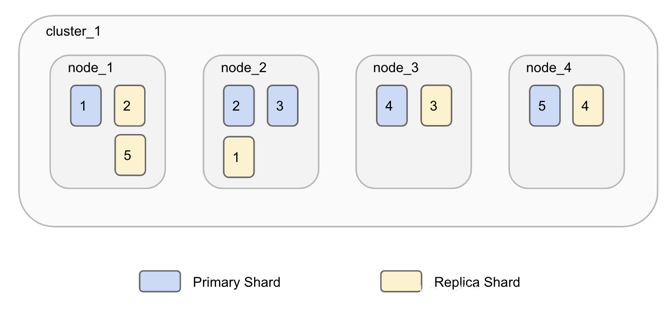
默认情况下,Elasticsearch 为每个索引创建一个主分片和一个副本。这意味着每个索引将包含一个主分片,每个分片将具有一个副本。
分配多个分片和副本是分布式搜索功能设计的本质,提供高可用性和快速访问索引中的文档。主副本和副本分片之间的主要区别在于只有主分片可以接受索引请求。副本和主分片都可以提供查询请求。
二、实验操作步骤

1.从命令运行 Elasticsearch
1.启动elasticsearch
进入elasticsearch安装目录,输入如下命令:
bin/elasticsearch
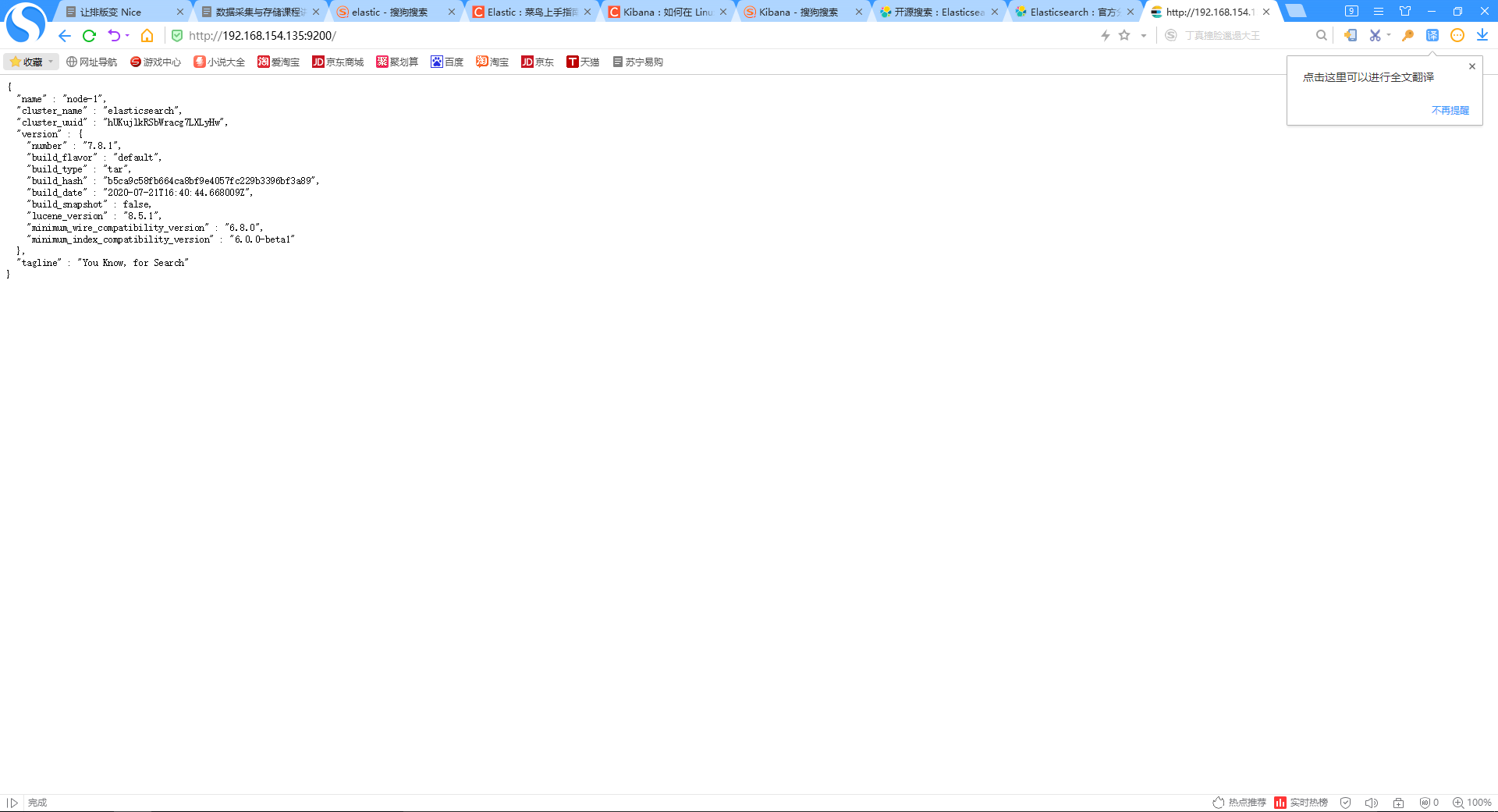
如图所示,浏览器输入http://192.168.154.135:9200/即可看到elasticsearch启动成功。
2.查看集群状况
在浏览器输入如下命令:
http://192.168.154.135:9200/_cat
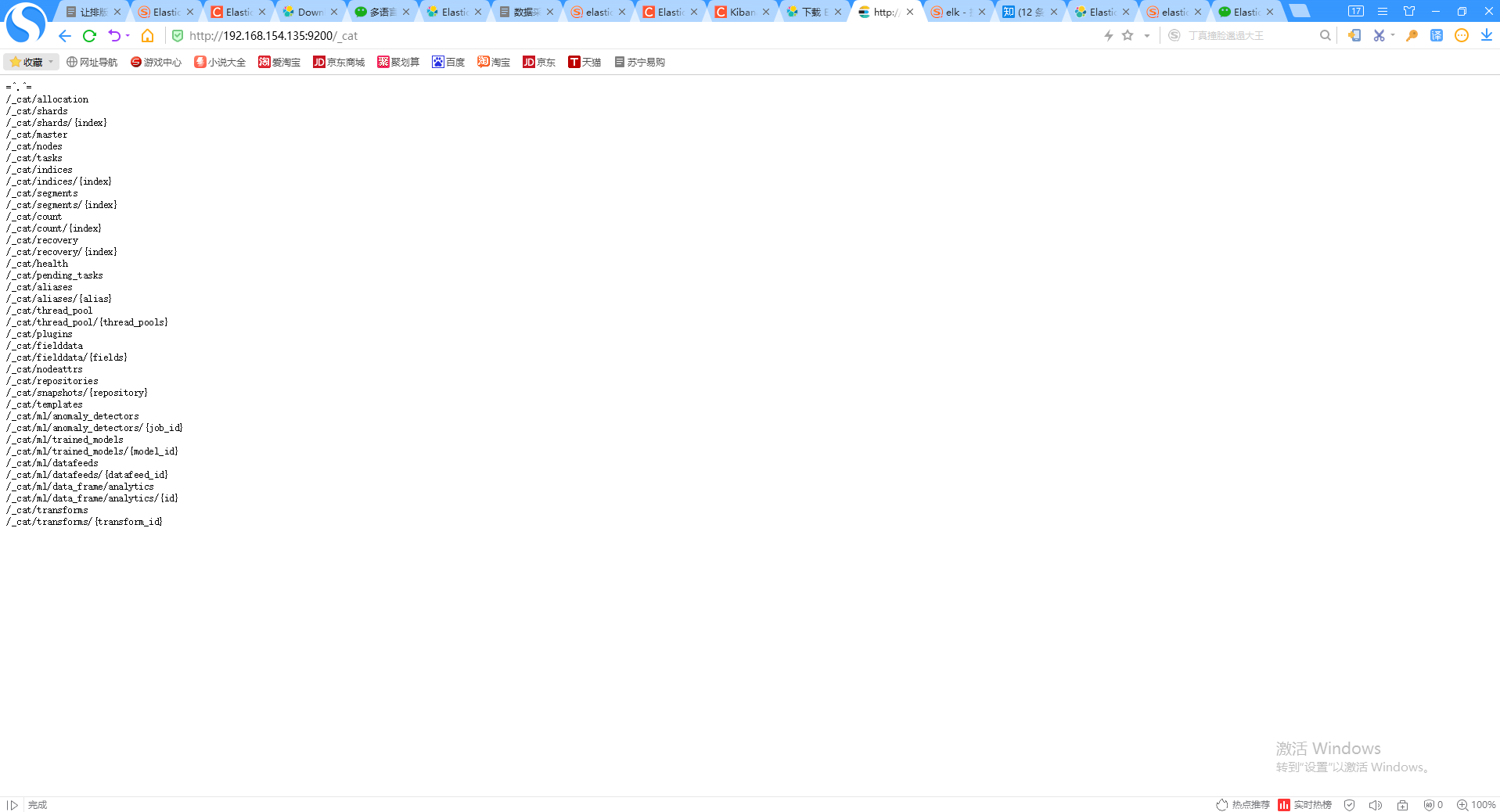
首先,我们需要了解ES中以下几个名词,是做什么的:
集群(cluster):由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node):单个ElasticSearch实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index):在ES中, 索引是一组文档的集合(就是我们所说的一个日志)
分片(shard):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿.
副本(replica):ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.
2.从命令运行 Kibana
1.通过 config 配置Kibana
server.port: 5601
server.host: "192.168.154.135"
server.name: "kibana_1"
elasticsearch.hosts: ["http://192.168.154.135:9200"]
将Kibana 的界面设置为中文的界面,在 kibana.yml 中进行如下的设置:
i18n.locale: "zh-CN"
2.启动Kibana
可以从命令行启动 Kibana,如下所示:
./bin/kibana
默认情况下,Kibana 在前台运行,将其日志打印到标准输出(stdout),按 Ctrl-C 可以停止。
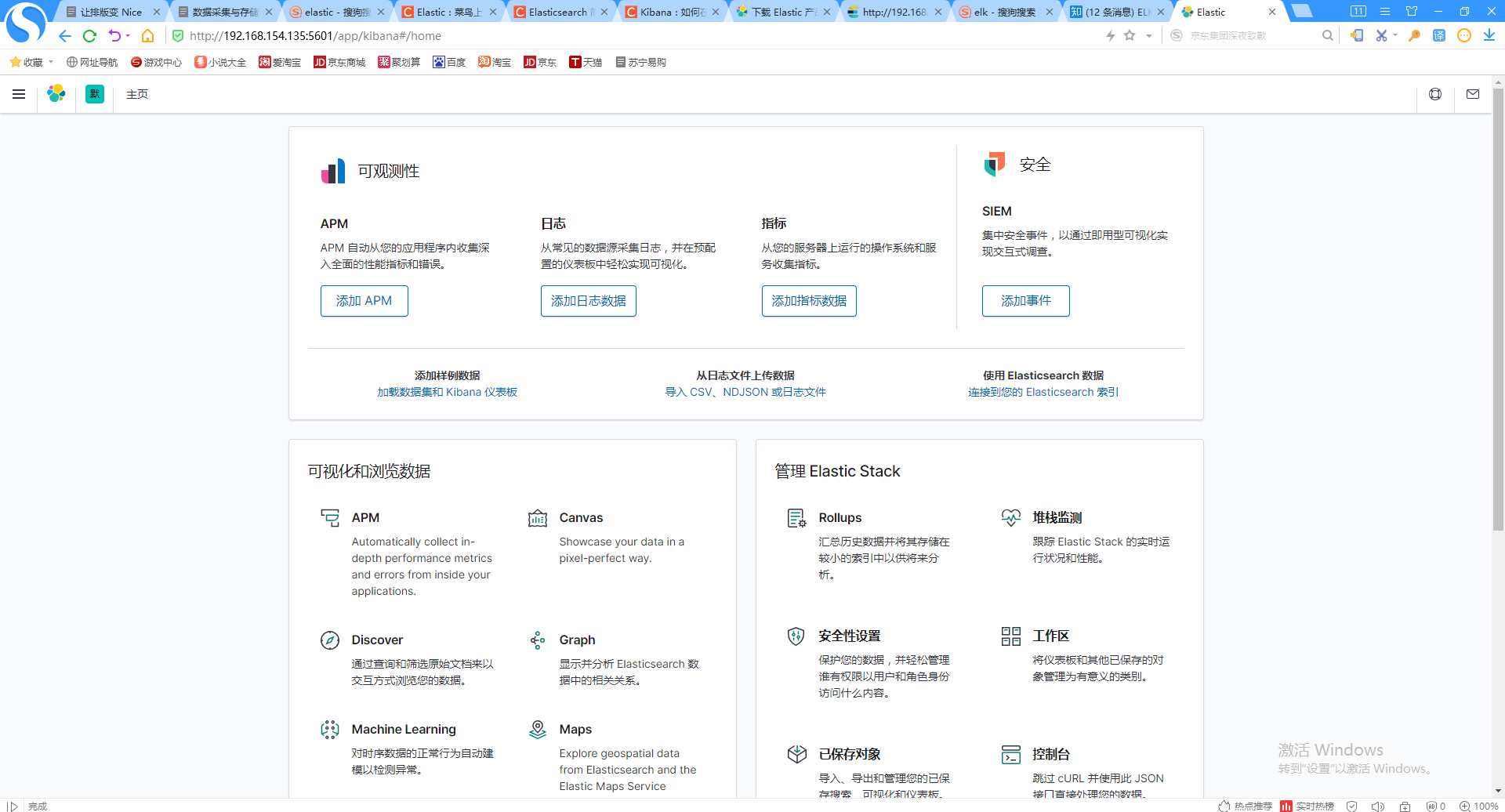
在我们的浏览器中,我们输入地址 http://192.168.154.135:5601。我们可以看到上面的界面。我们可以利用这个界面来对我们的数据进行接下来的分析,展示等。
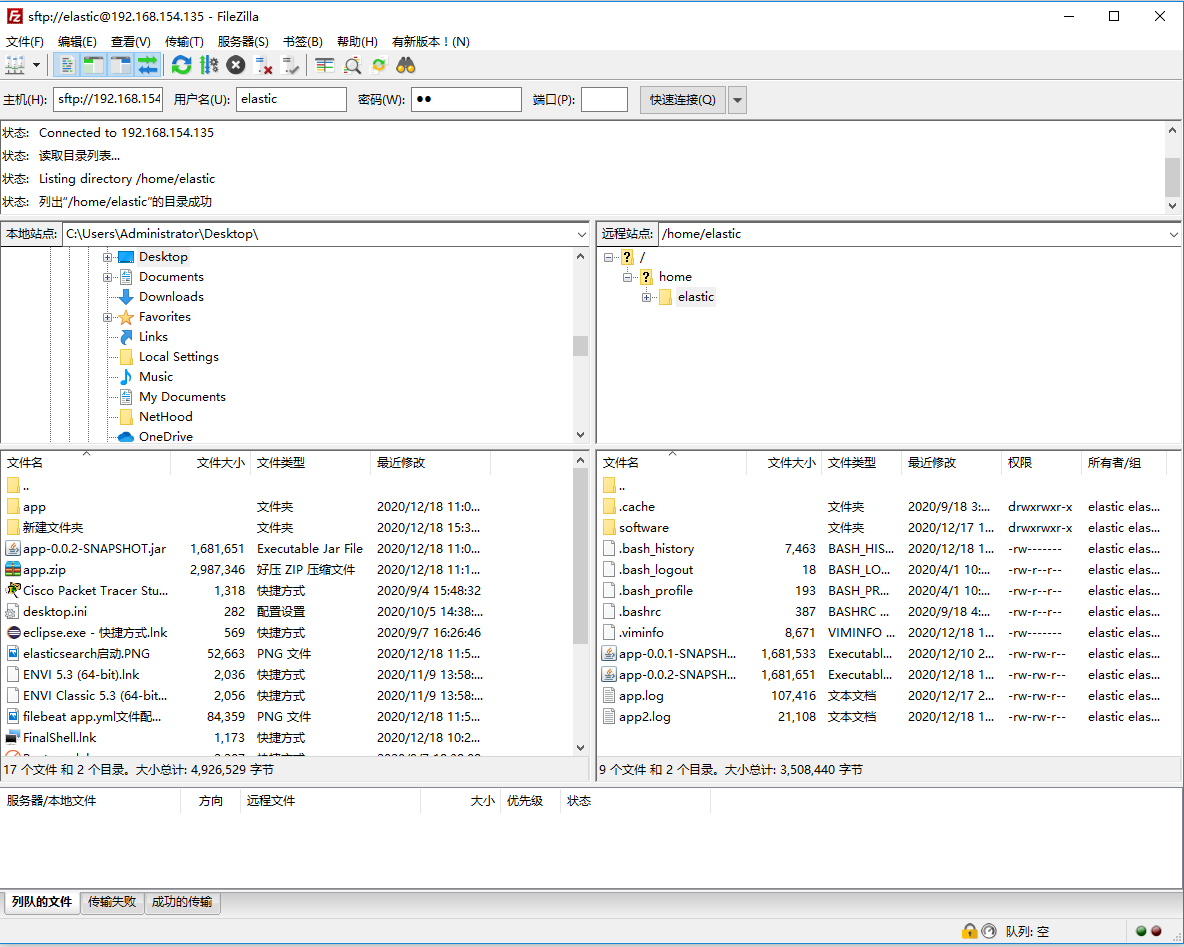
3.将本地日志上传到linux主机
4.Filebeat读取log日志文件
1.编写filebeat配置文件app.yml
在filebeat目录执行如下命令
vi app.yml
添加以下内容信息至app.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/elastic/*.log
setup.template.settings:
index.number_of_shards: 3
output.elasticsearch:
hosts: ["192.168.154.135:5044"]
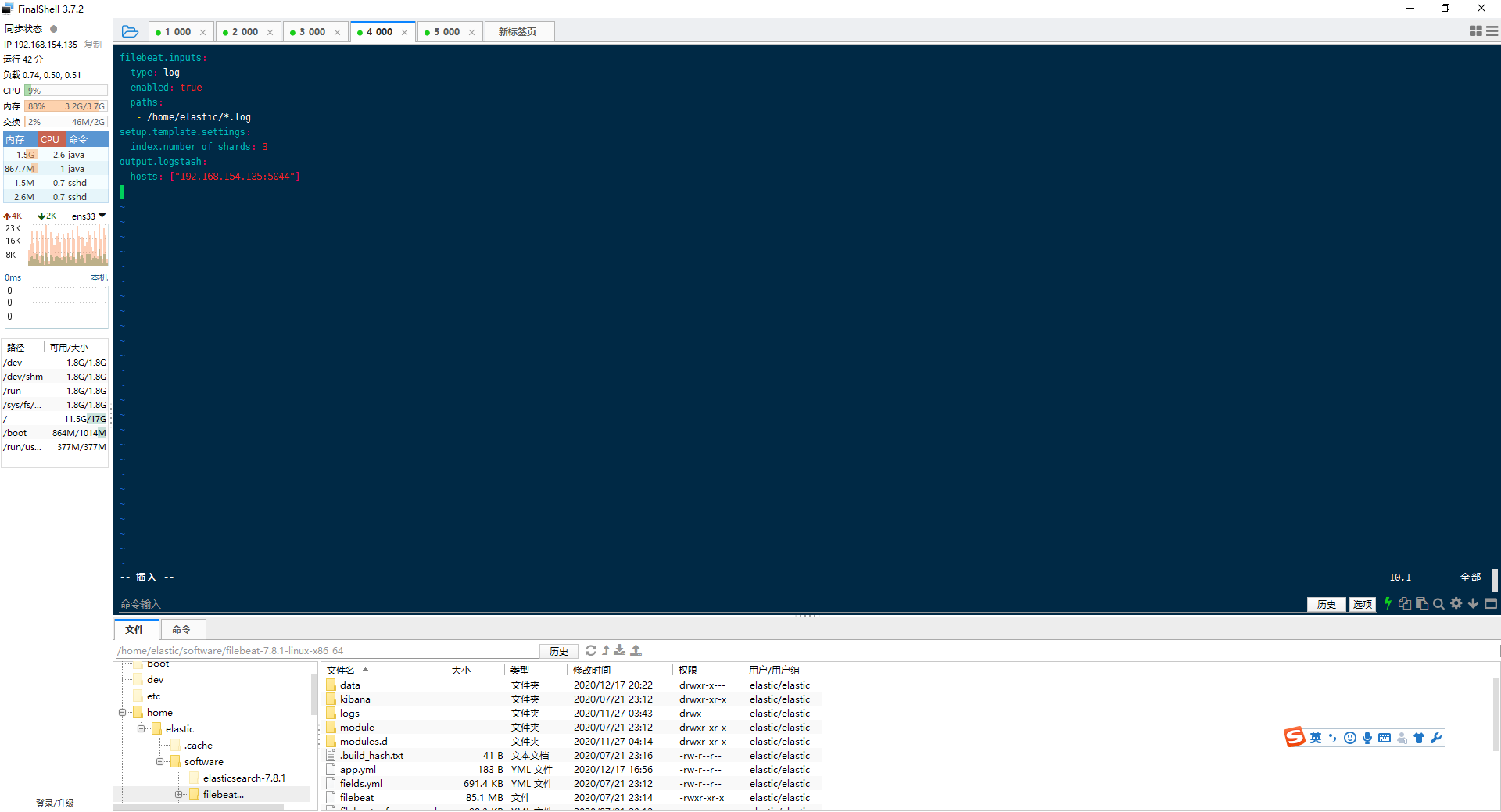
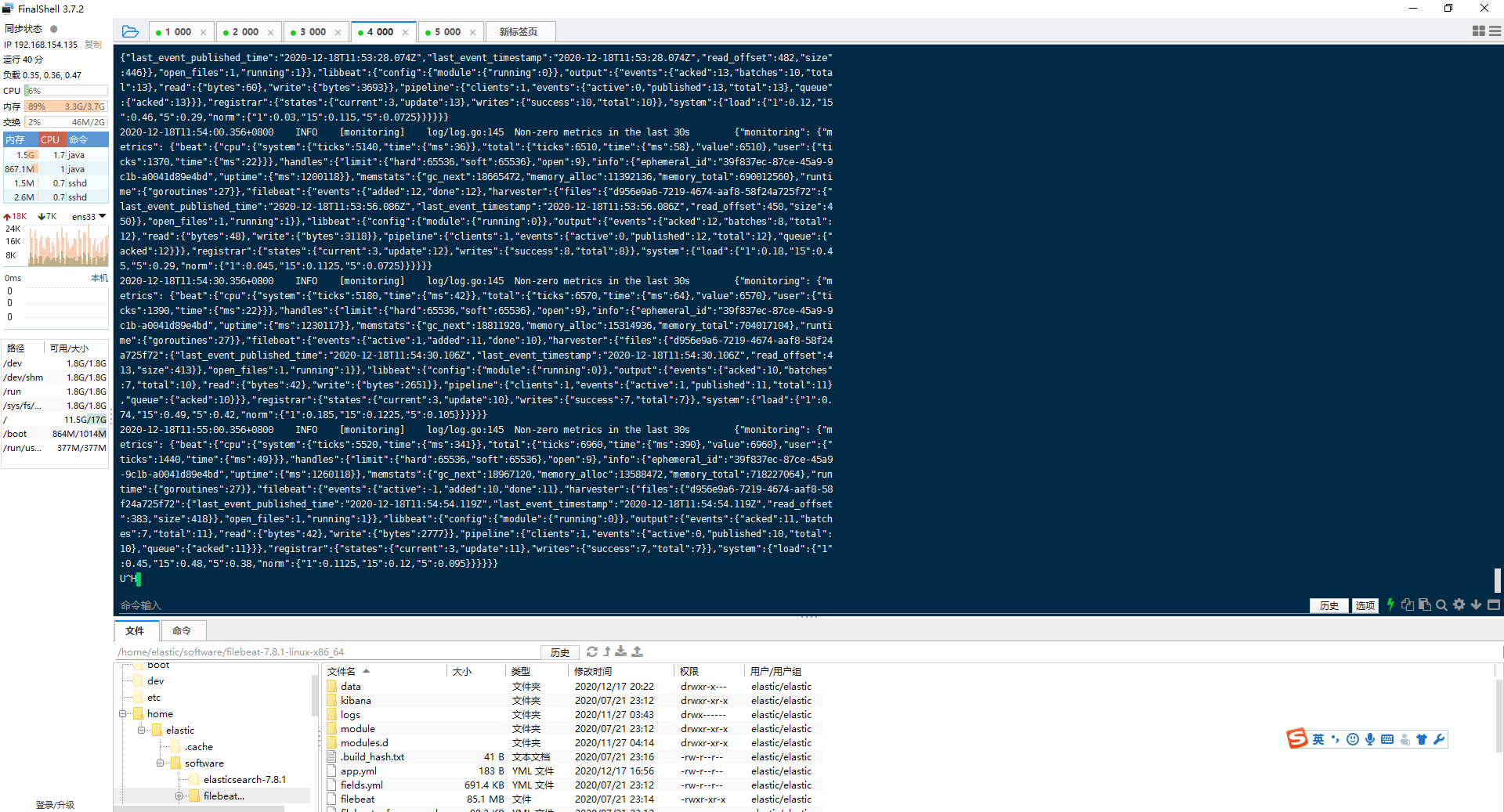
2.将filebeat读取文件提交至elasticsearch
在filebeat目录下执行如下命令
./filebeat -e -c app.yml
5.kibana添加dashboard
1.添加索引到Kibana中:
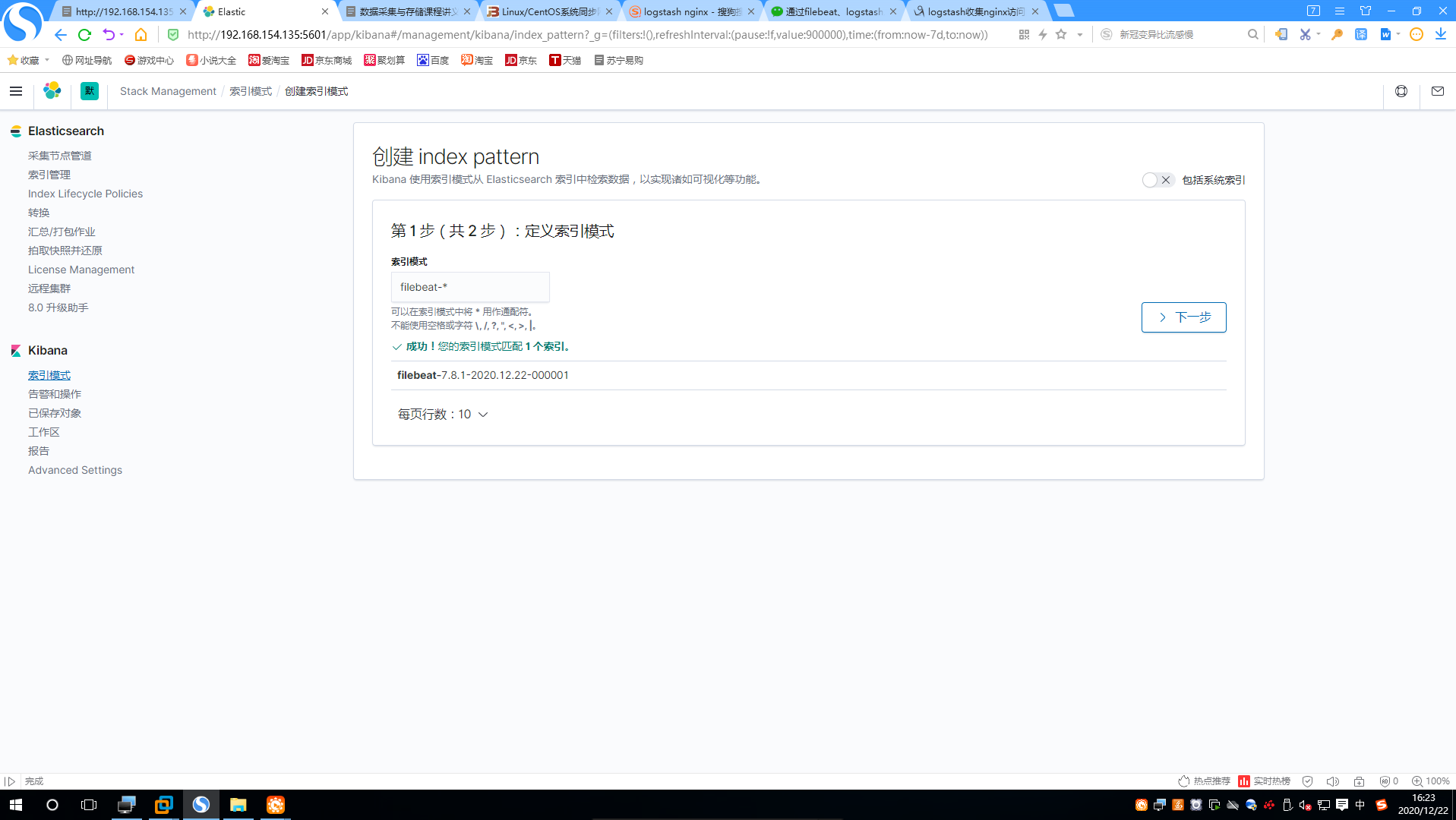
2.设置配置
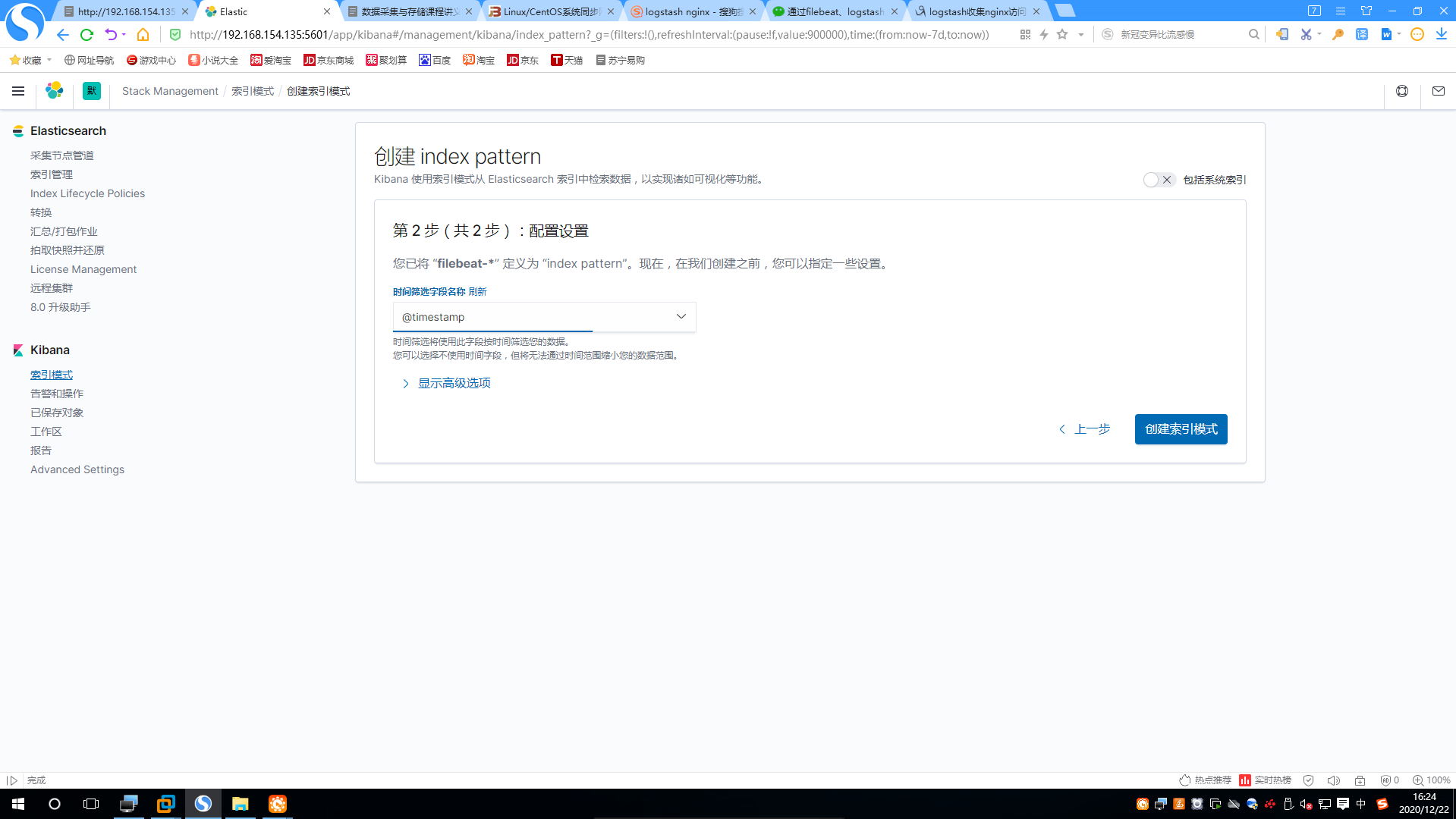
3.查看索引模式
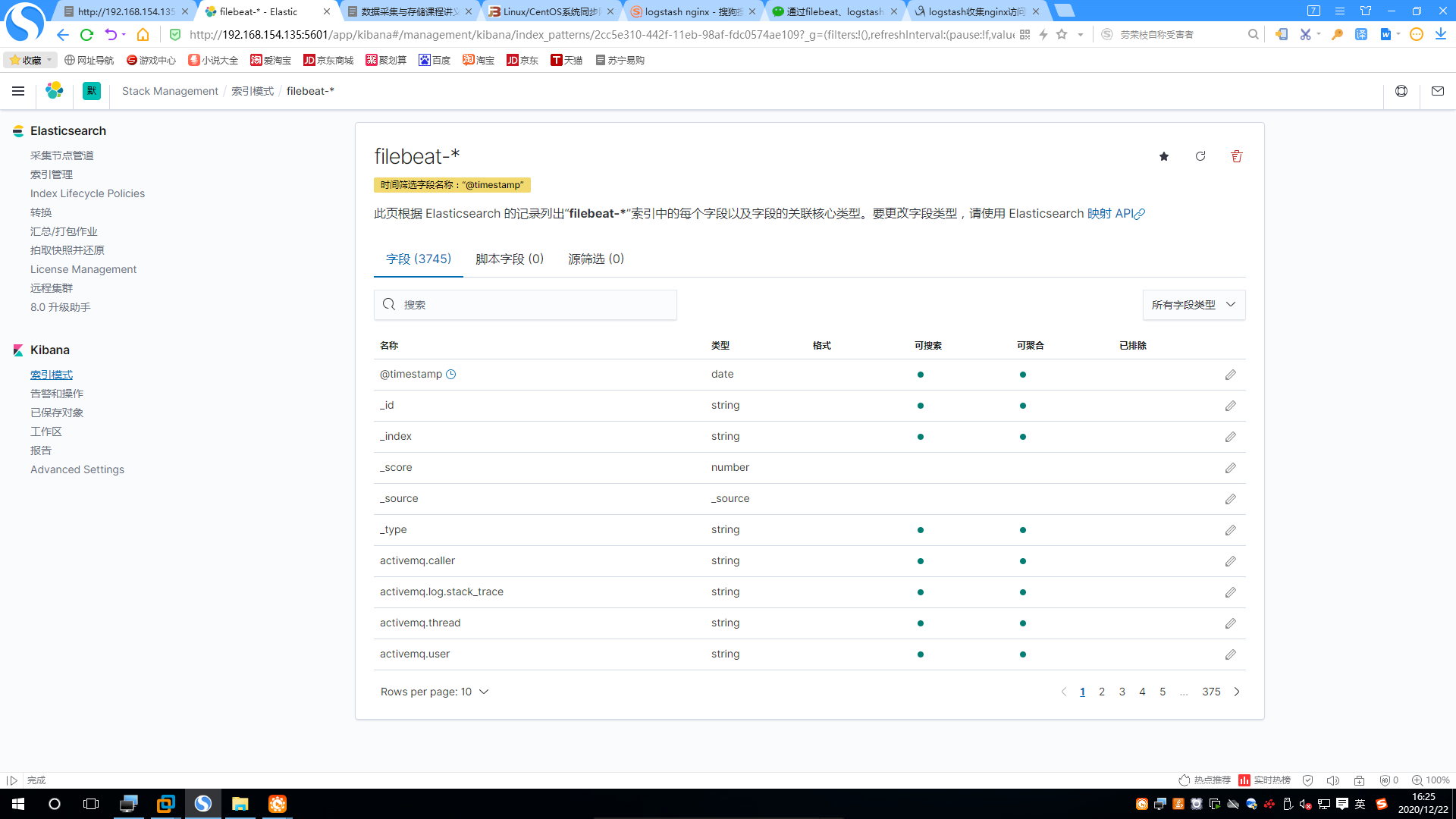
4.查看discover界面
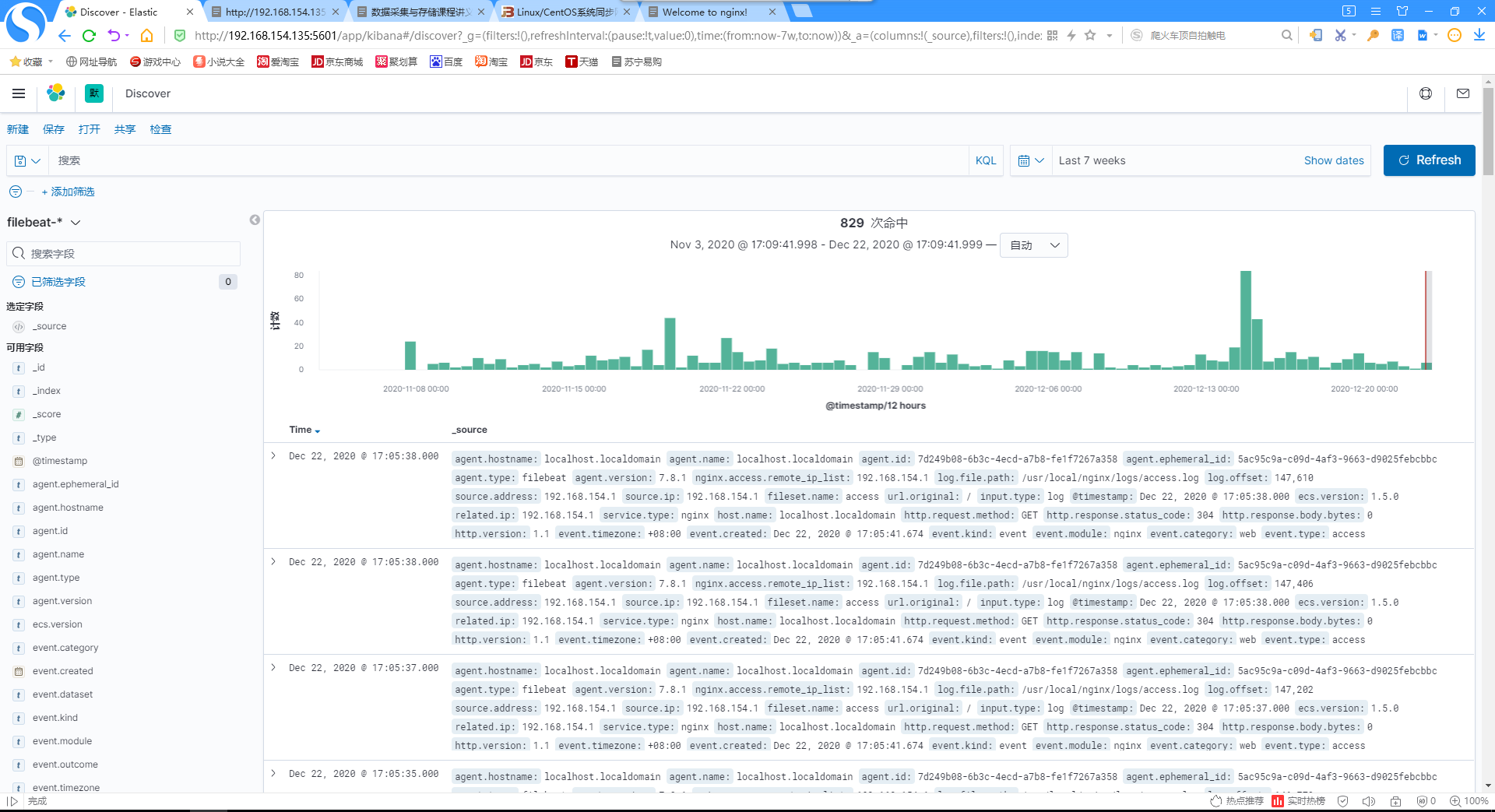
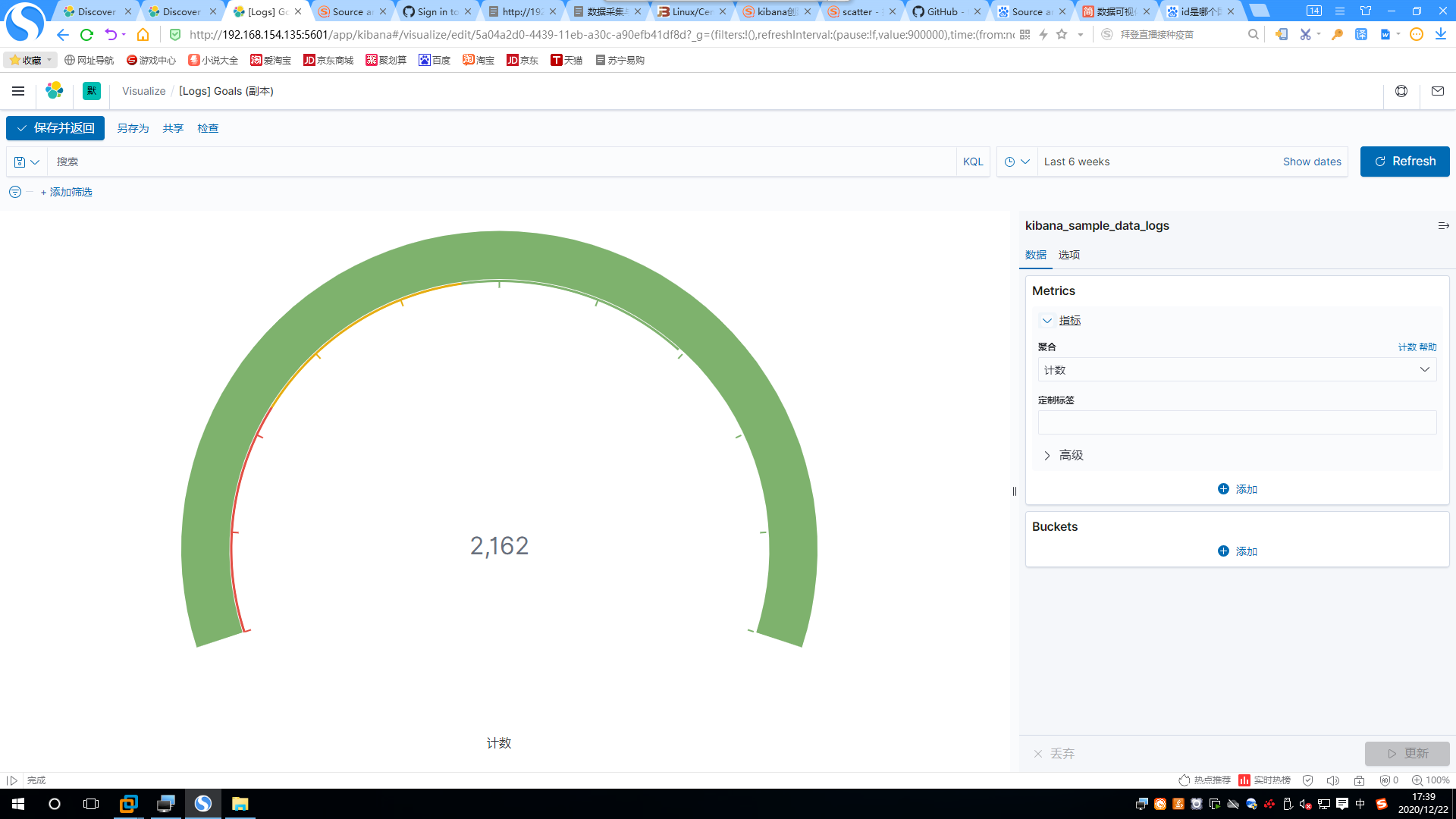
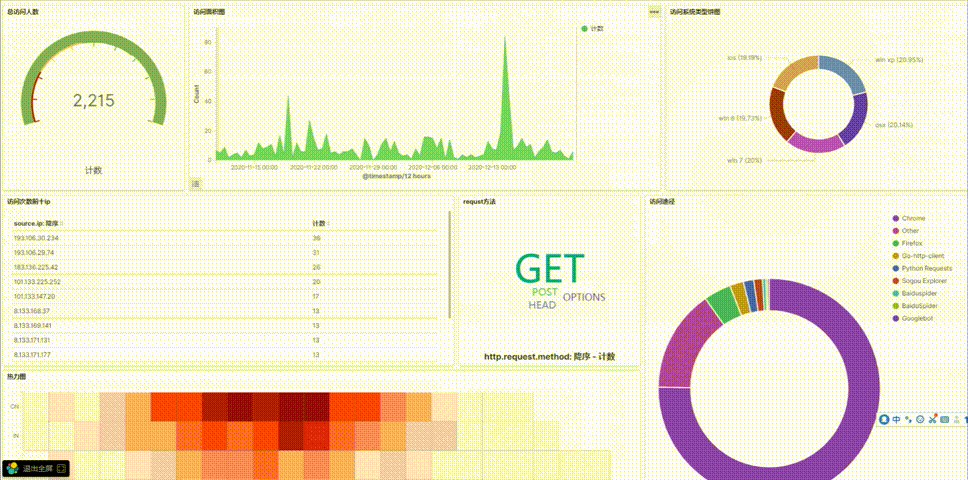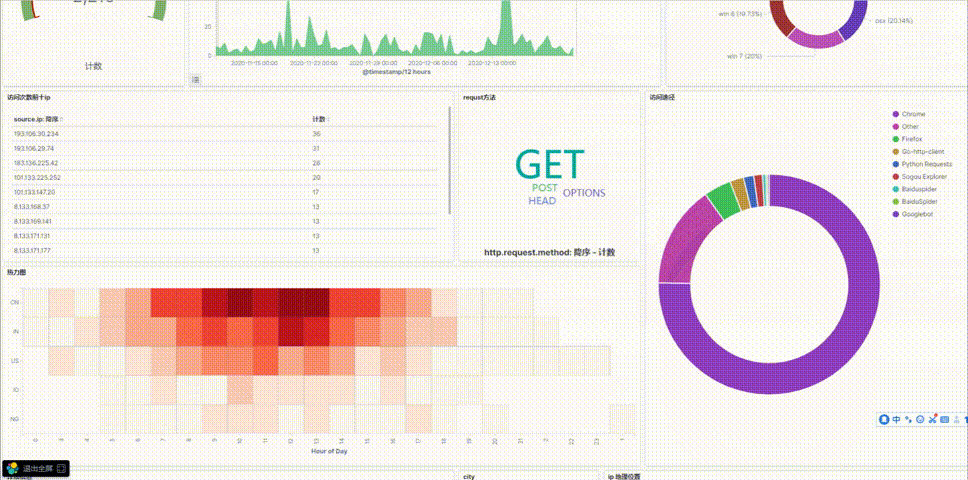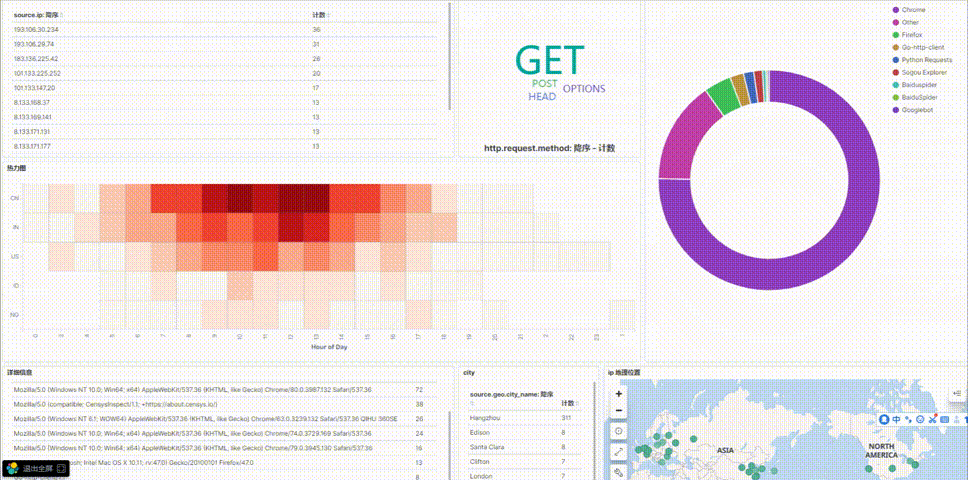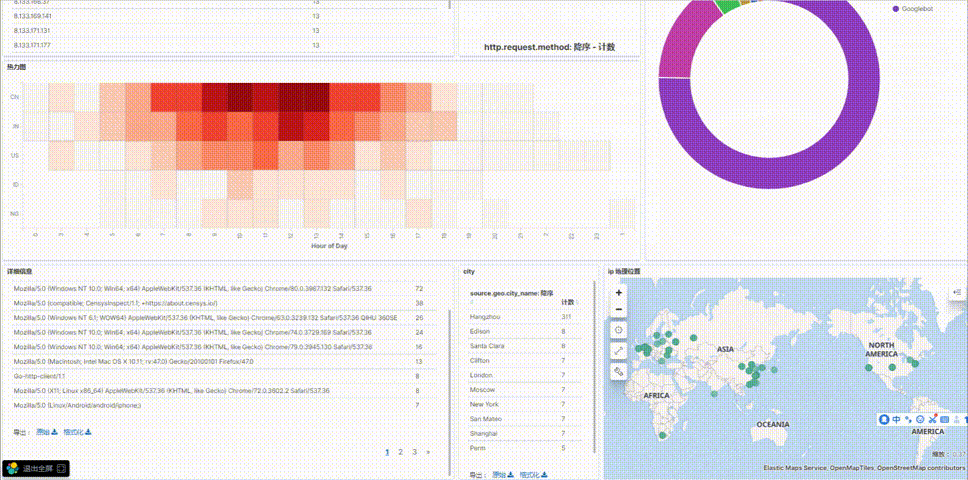
5.添加总访问人数
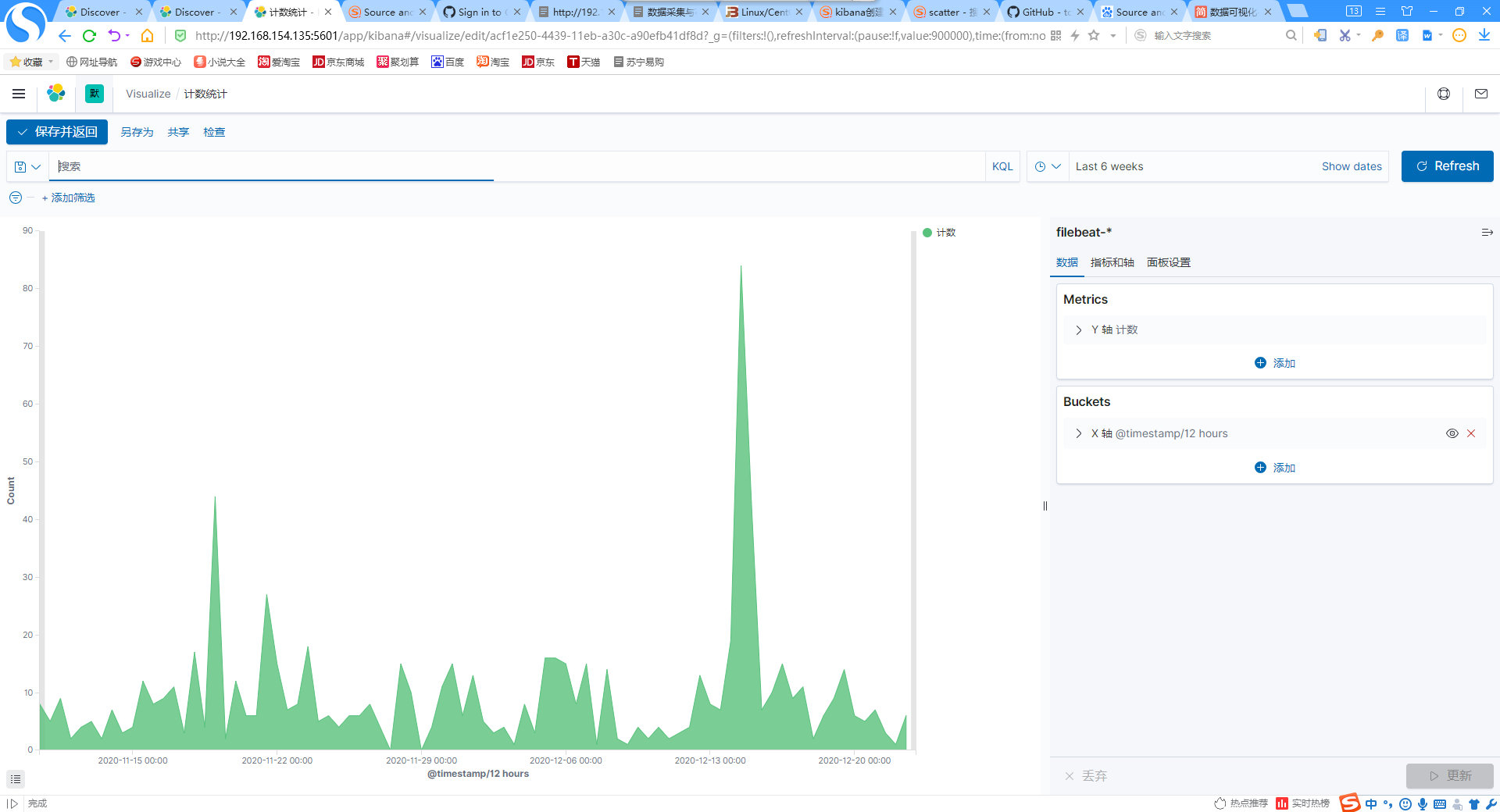
6.添加访问面积图
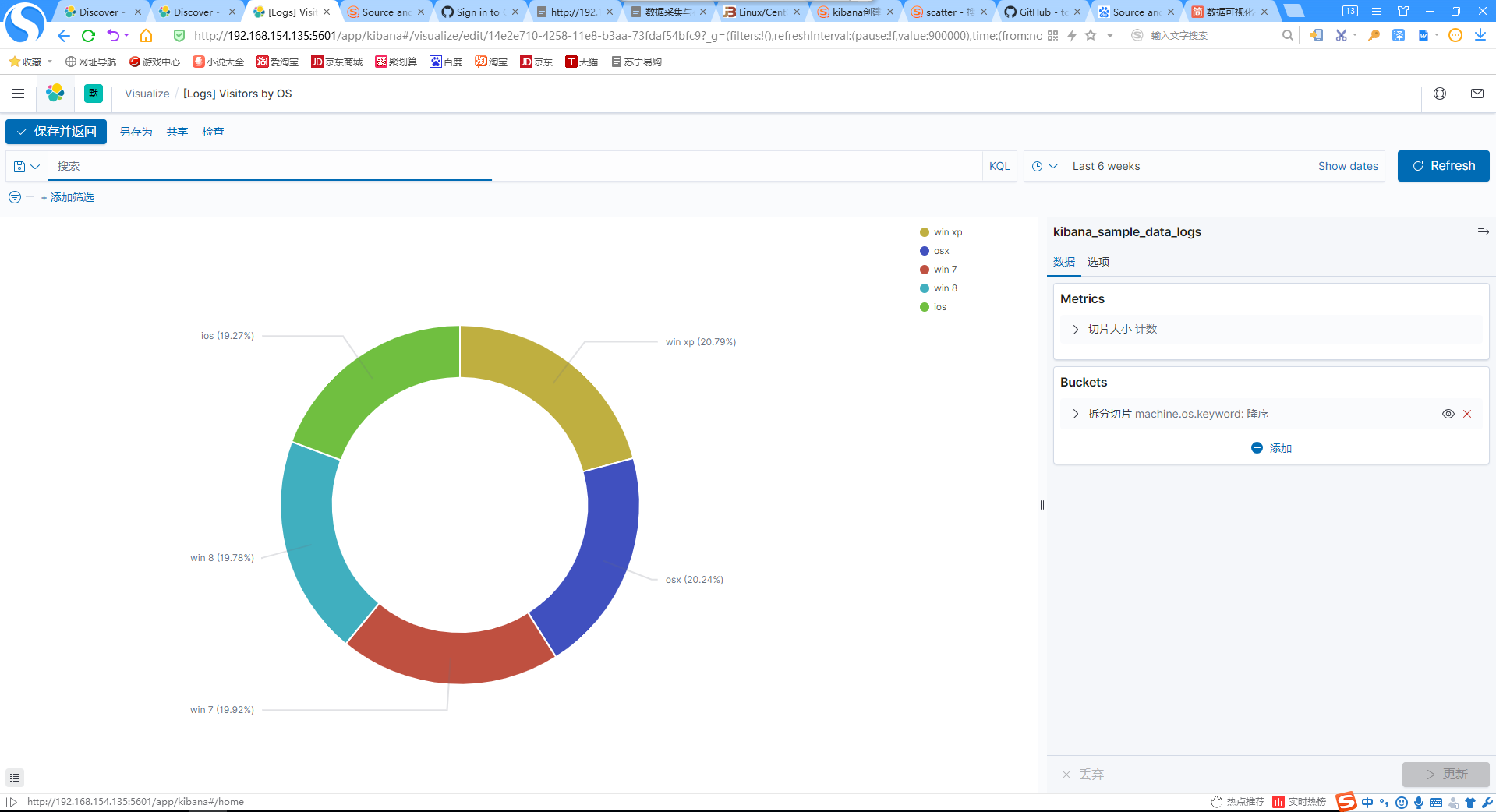
7.添加访问设备系统饼图
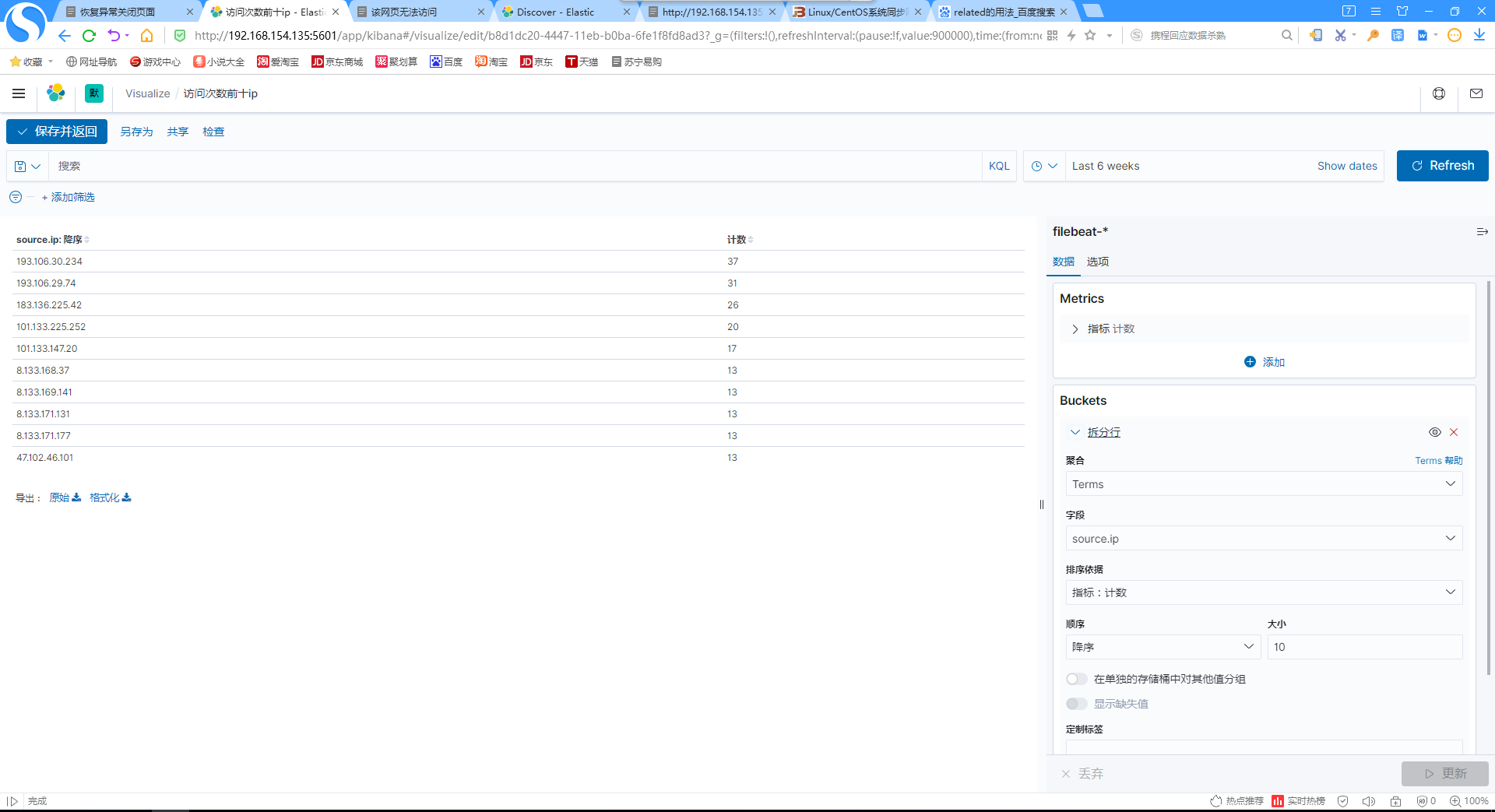
8.添加访问次数前十ip数据表格
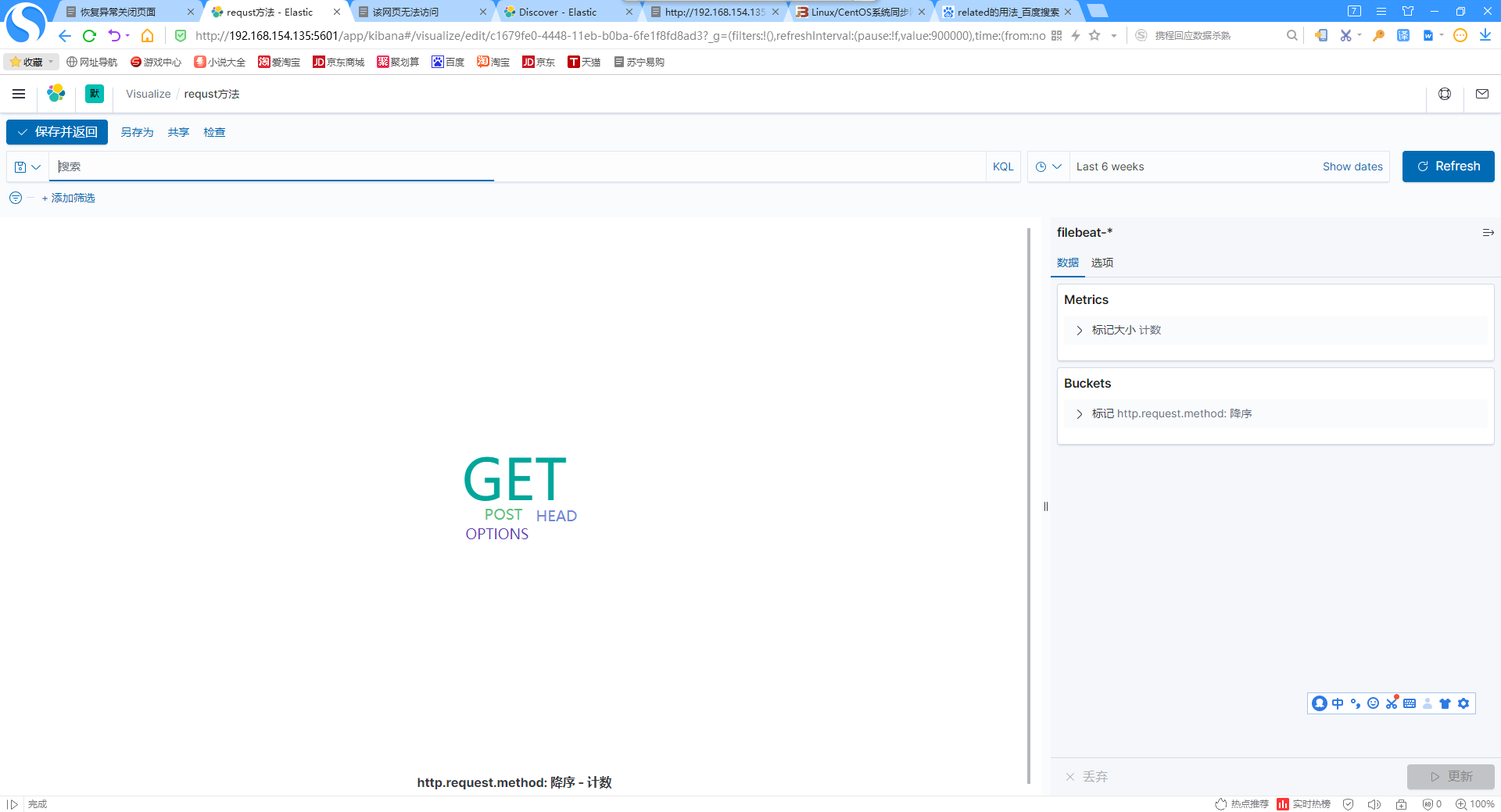
9.添加requst方法标签词云
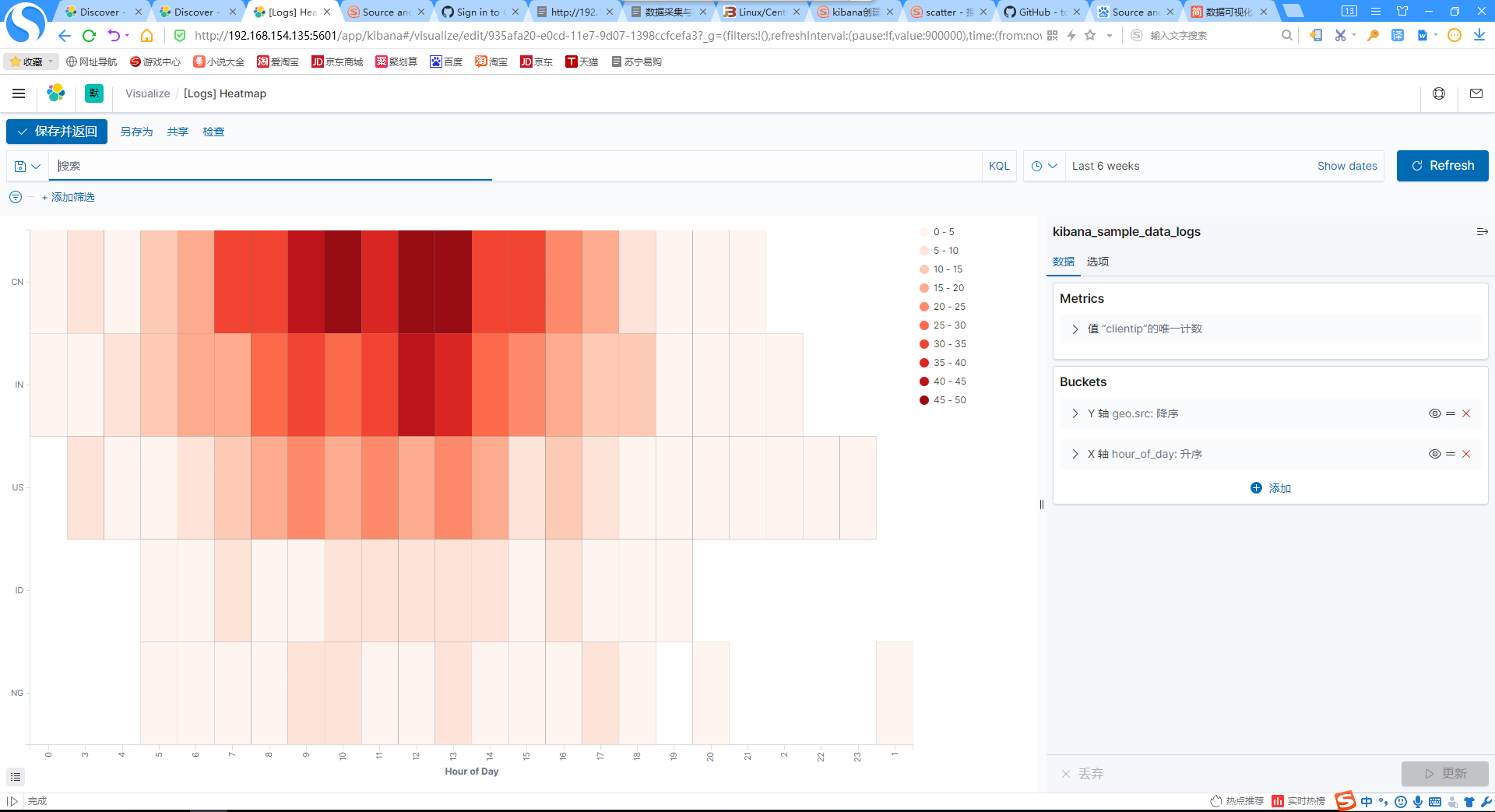
10.添加每天不同时间访问热力图
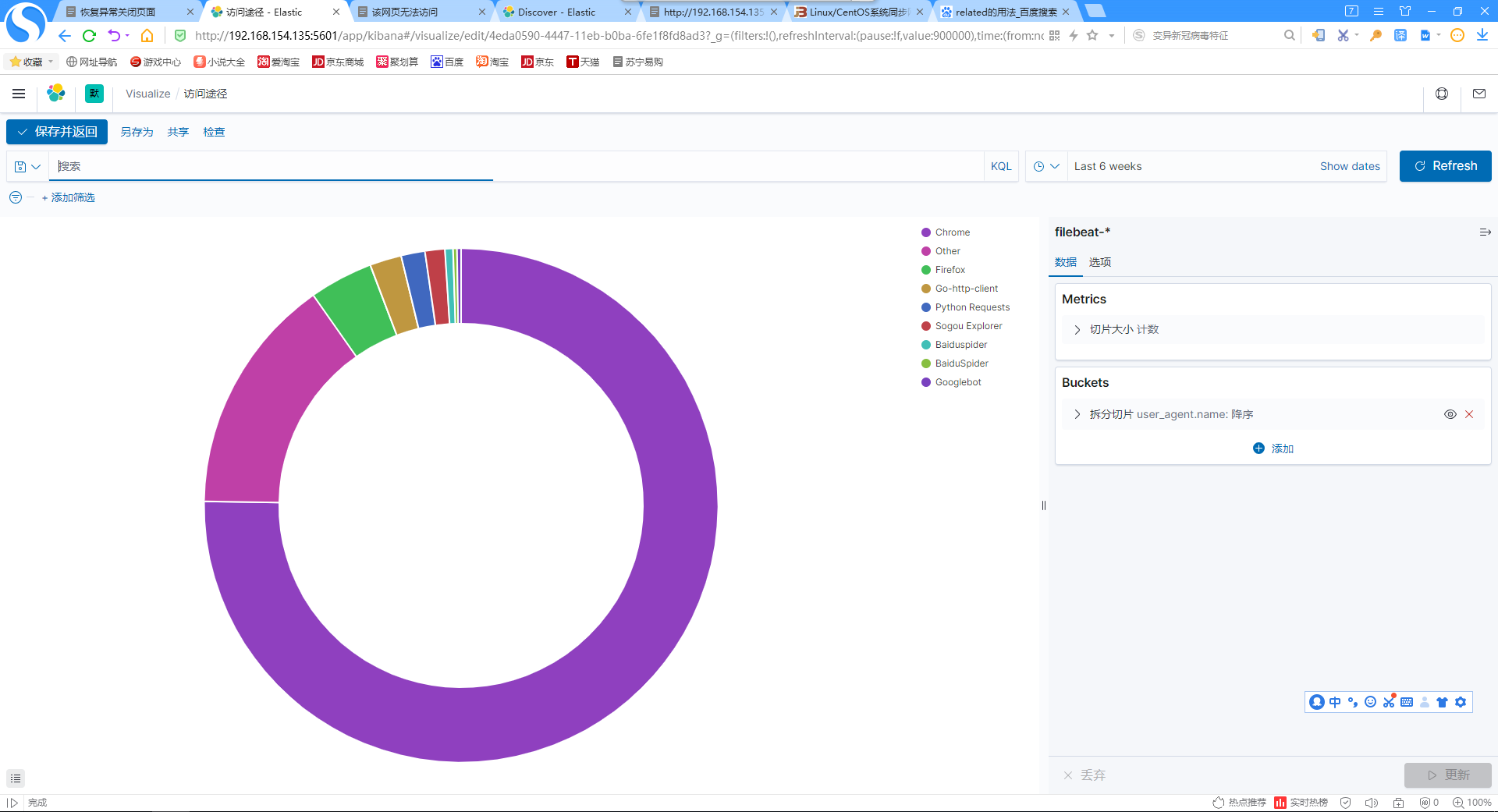
11.添加访问网站途径饼图
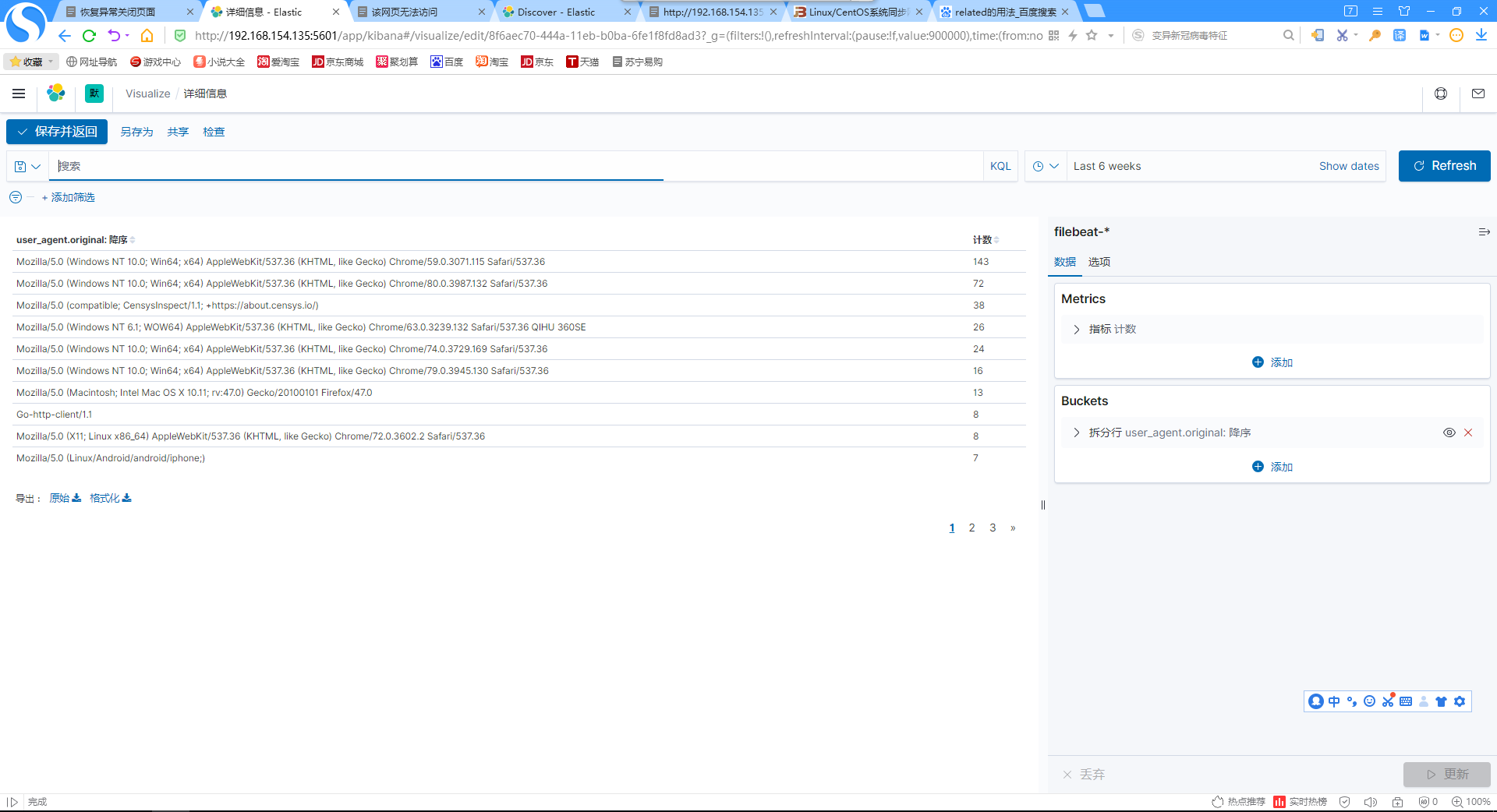
12.添加用户访问详细信息
13.添加访问用户城市表格
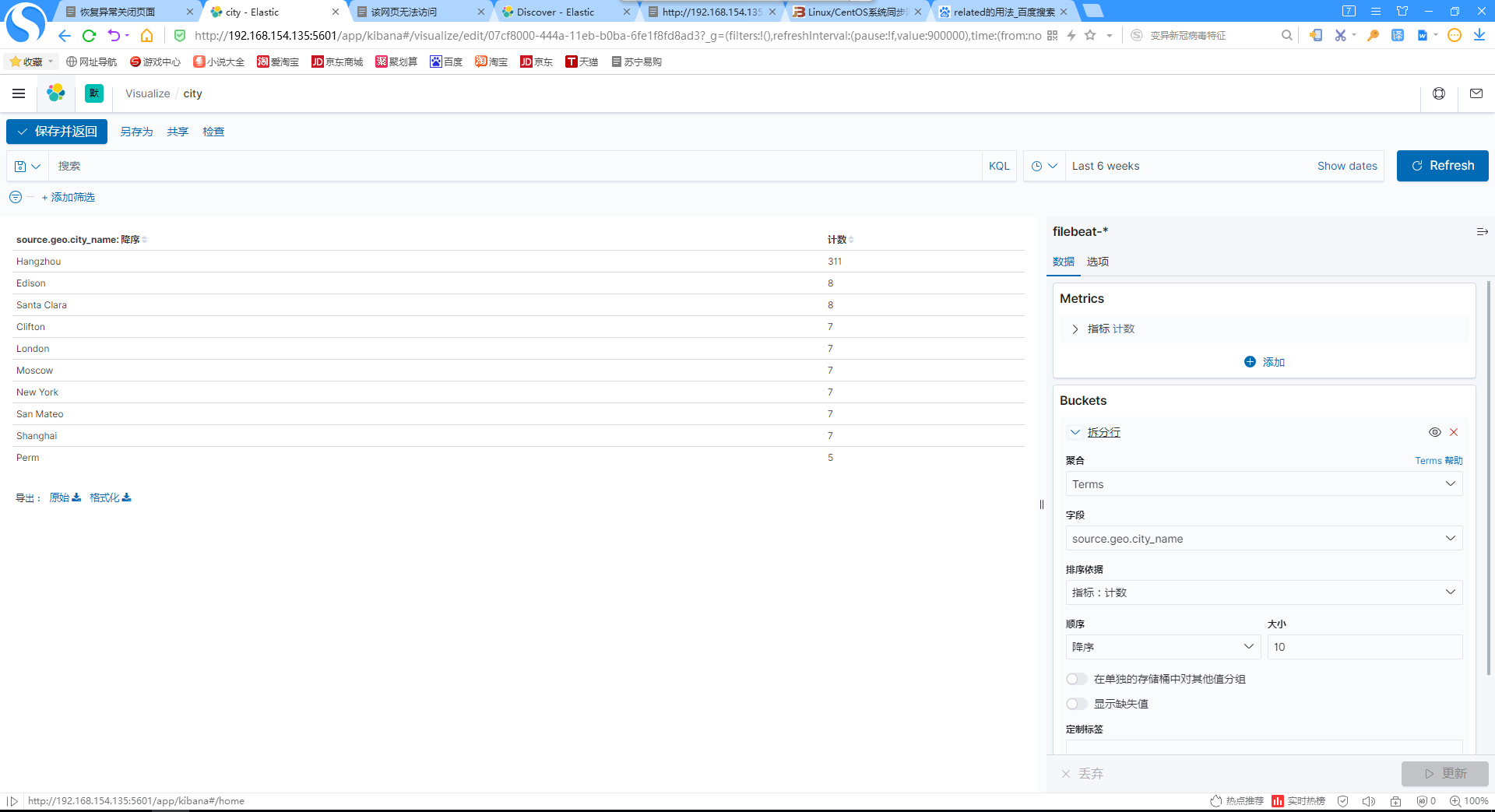
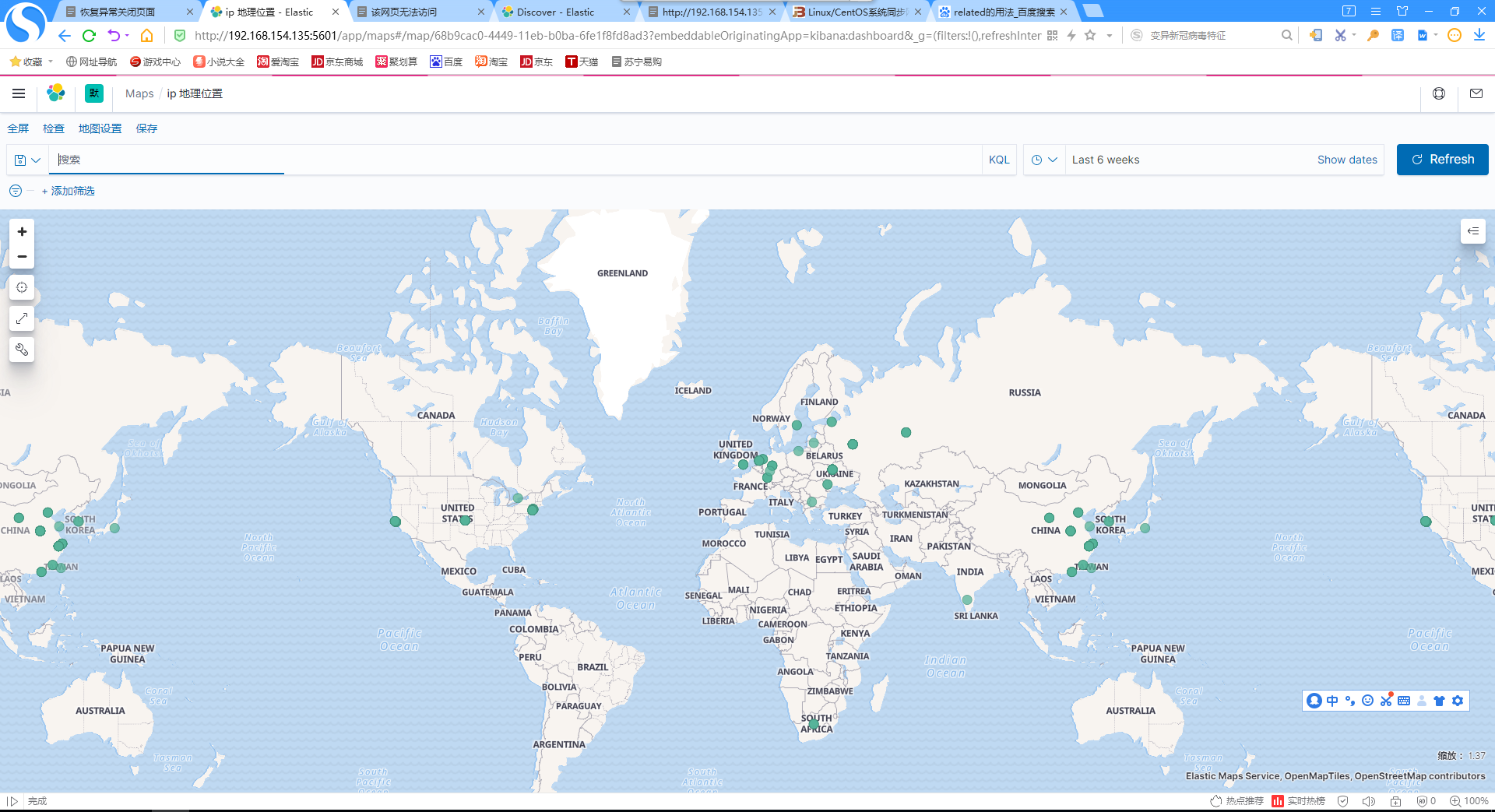
14.添加用户城市分布地图
6.可视化总效果图
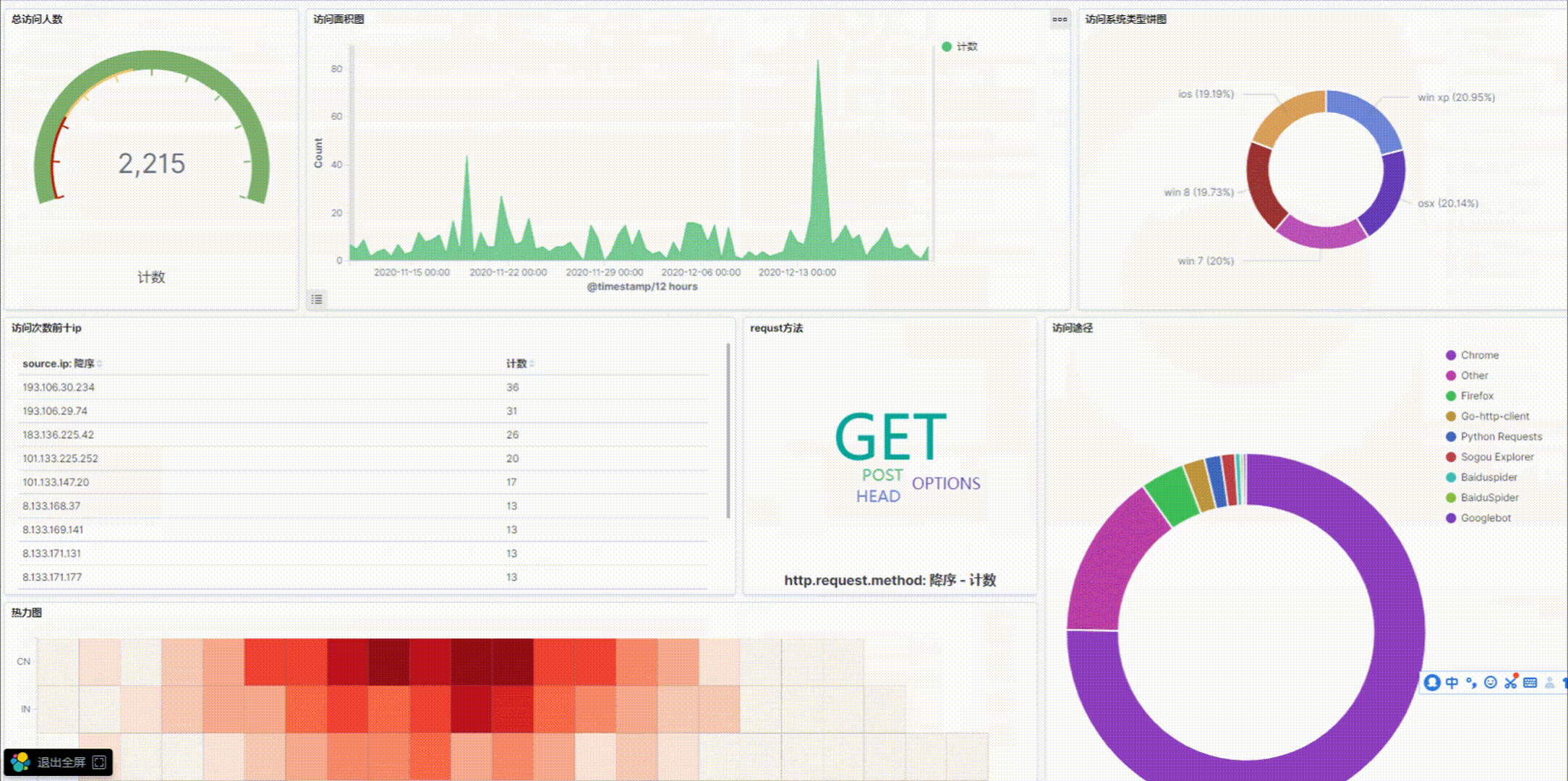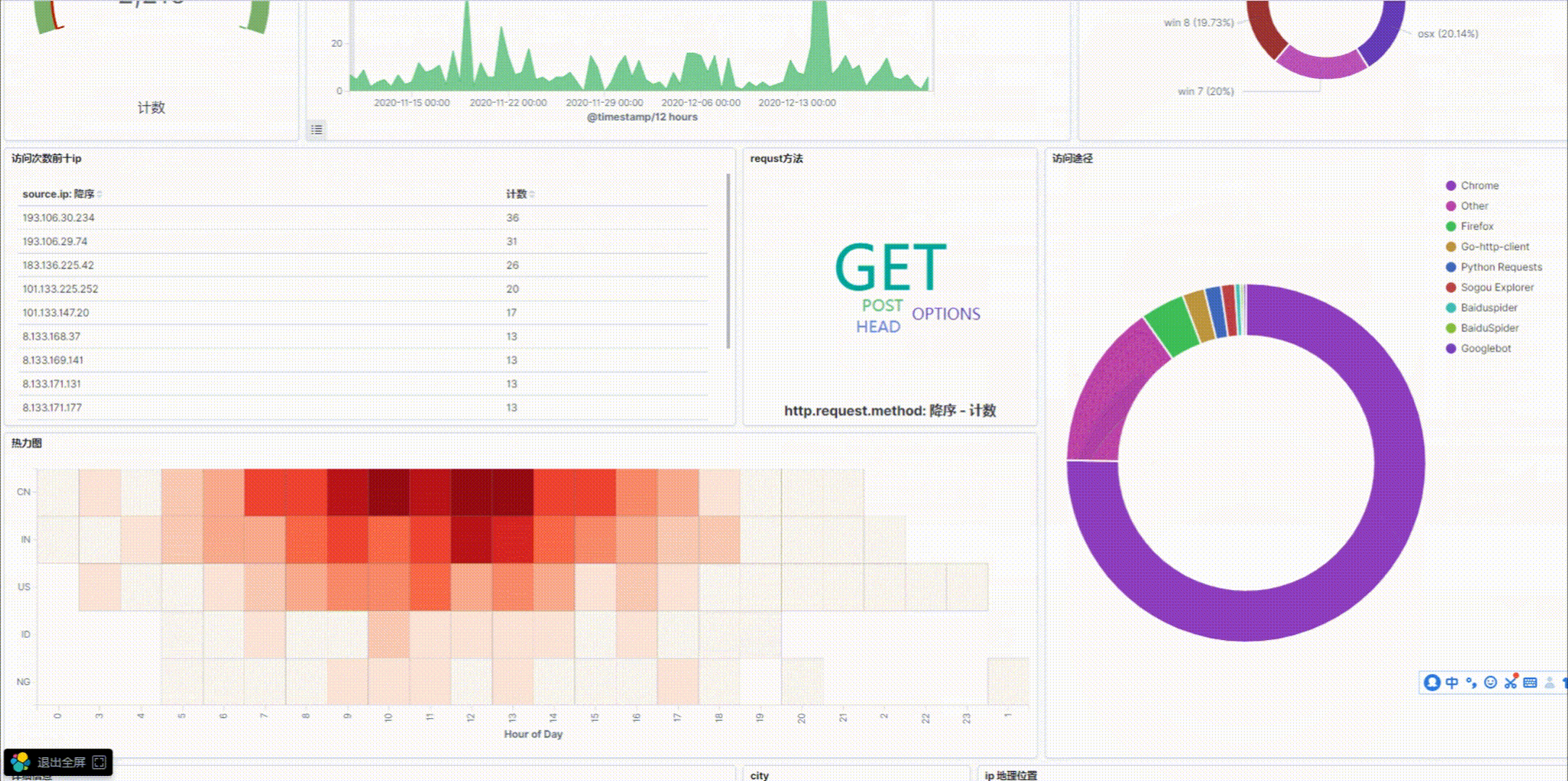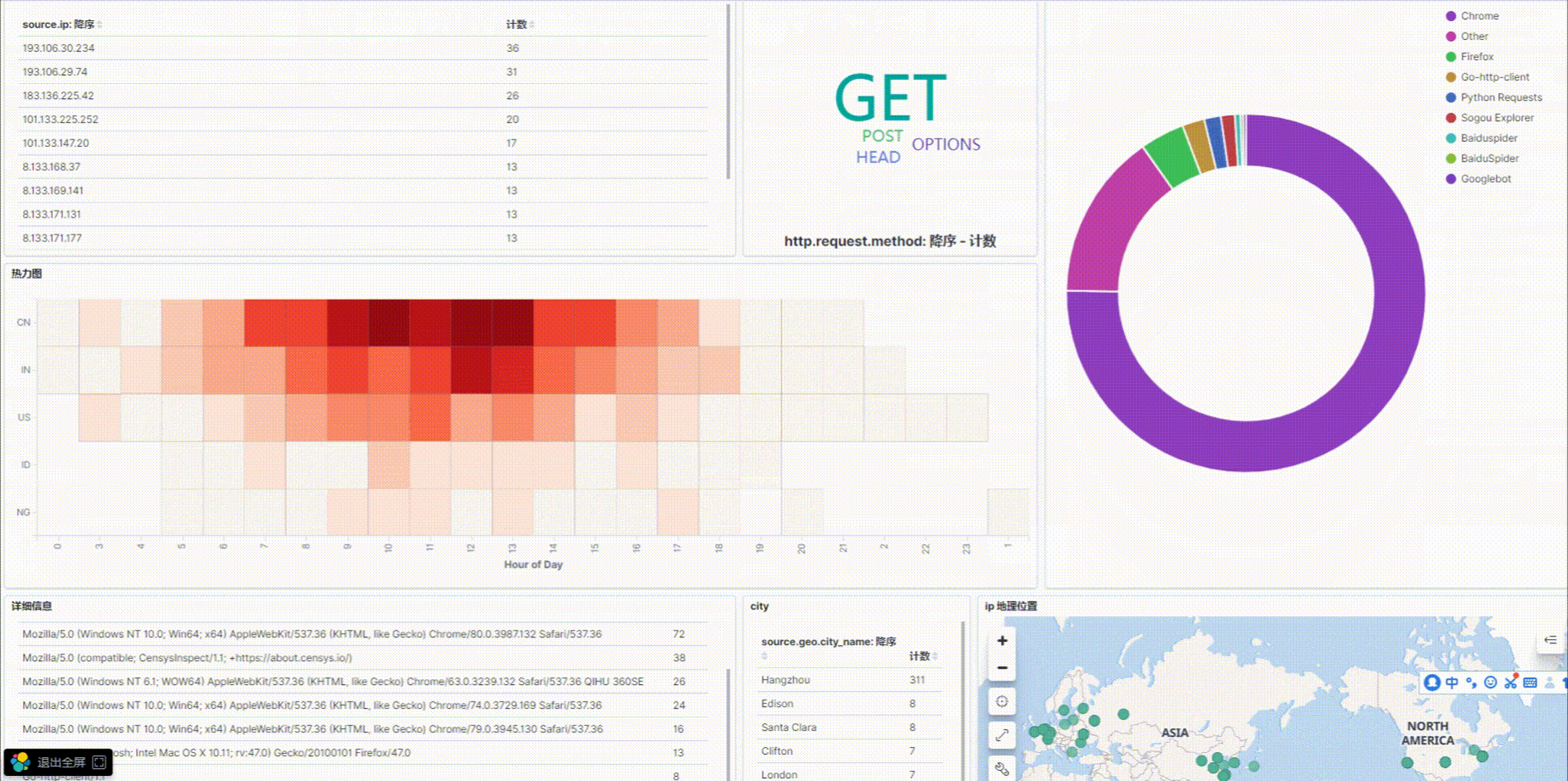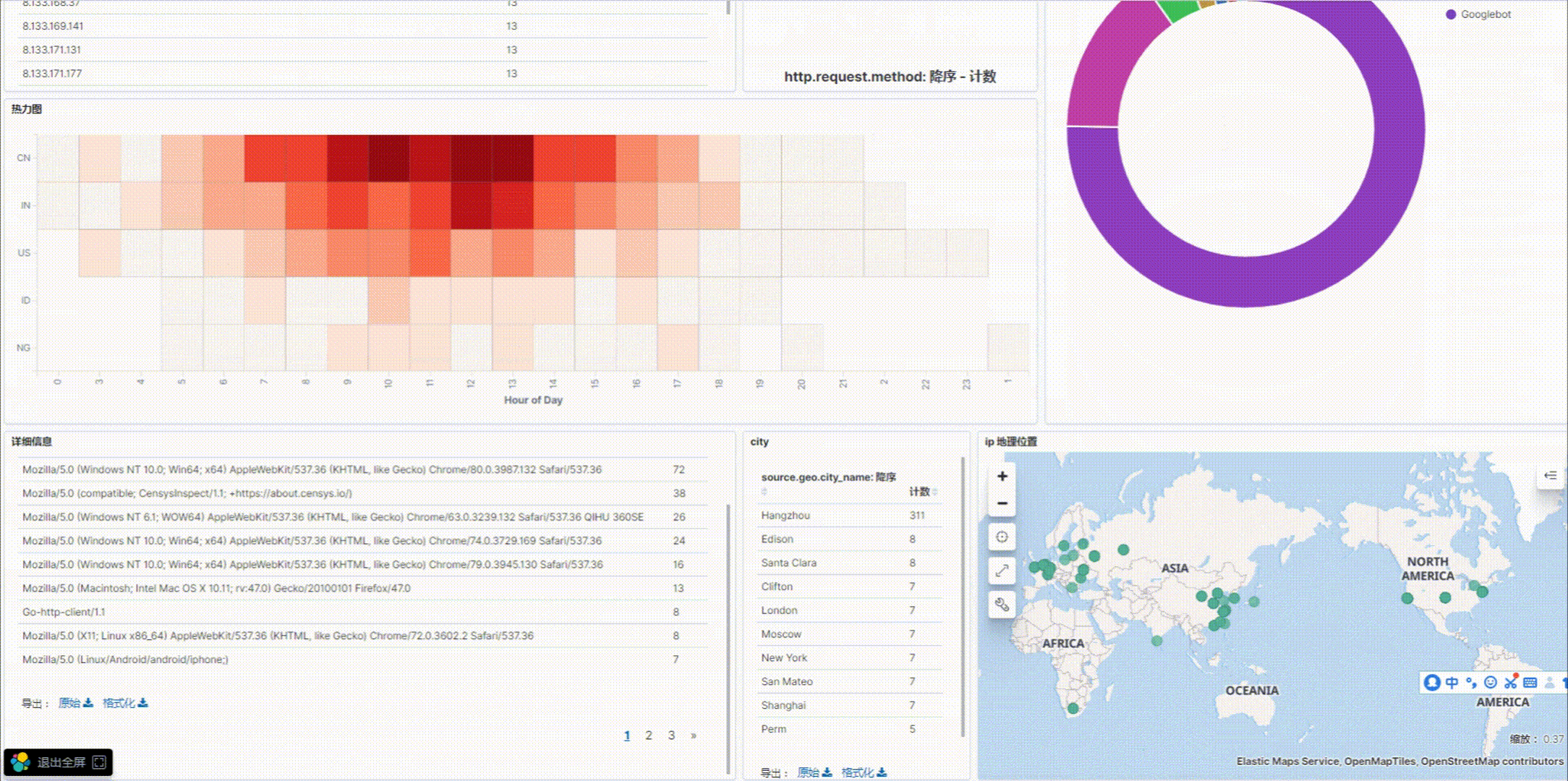
https://picture-store-repository.oss-cn-hangzhou.aliyuncs.com/2020-12-22/1608646231208-001.gif
三、拓展-head插件
1.简介
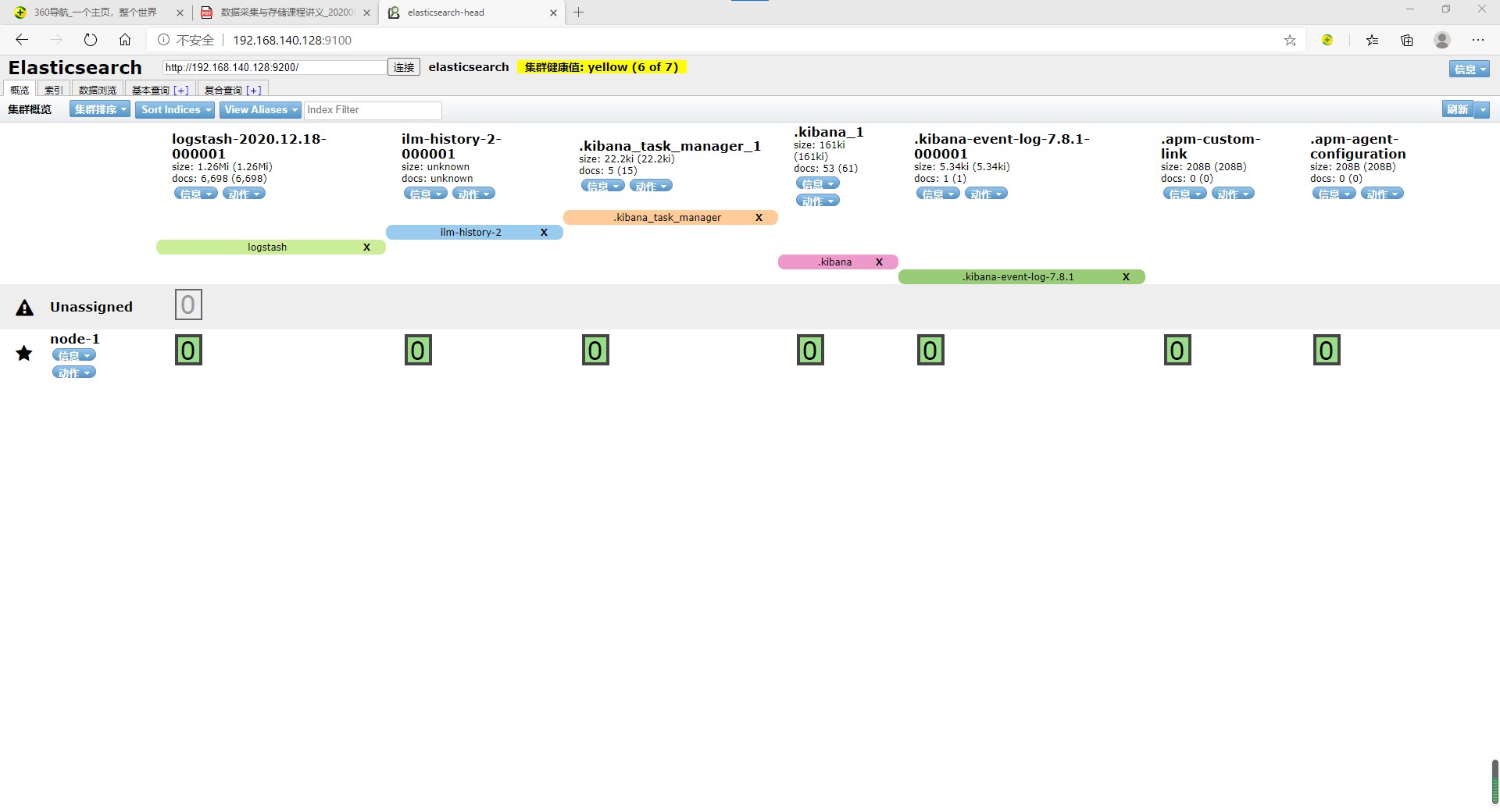
ElasticSearch-head就是一款能连接ElasticSearch搜索引擎,并提供可视化的操作页面对ElasticSearch搜索引擎进行各种设置和数据检索功能的管理插件,如在head插件页面编写RESTful接口风格的请求,就可以对ElasticSearch中的数据进行增删改查、创建或者删除索引等操作。类似于使用navicat工具连接MySQL这种关系型数据库,对数据库做操作。
在登陆和访问head插件地址和ElasticSearch前需要事先在服务器上安装和配置好ElasticSearch以及head插件。安装完后,默认head插件的web端口为9100,ElasticSearch服务的端口为9200,使用浏览器访问head地址,如http://IP地址:9100/,推荐使用Chrome浏览器,head插件对Chrome浏览器兼容更佳。进入head页面后将ElasticSearch连接输入框中填写正确的ElasticSearch服务地址,如http://IP地址:9200/
2.安装
1.安装Node.js
下载并解压
cd /usr/local
wget https://npm.taobao.org/mirrors/node/v14.4.0/node-v14.4.0-linux-x64.tar.xz
tar -xvf node-v14.4.0-linux-x64.tar.xz
cd node-v14.4.0-linux-x64
将nodejs的命令node、npm等添加到PATH环境变量中
export NODE_HOME=/usr/local/node-v14.4.0-linux-x64
export PATH=$PATH:${NODE_HOME}/bin
创建软链接
ln -s /usr/local/nodejs/bin/node /usr/bin/node
ln -s /usr/local/nodejs/bin/npm /usr/bin/npm
验证安装
npm -v
node -v
cnpm -v
2.安装git并拉取ElasticSearch-head代码
yum install –y git #安装git 安装过则更新
git --version #查看是否安装成功
git clone https://github.com/mobz/elasticsearch-head.git#从github上拉取elasticsearch-head代码
cd elasticsearch-head #进入elasticsearch-head文件夹
npm install cnpm -g --registry=https://registry.npm.taobao.org #因为npm安装非常非常慢,所以在这里先安装淘宝源地址
ln -s /usr/local/nodejs/bin/cnpm /usr/local/bin/cnpm #创建cnpm软链接,不然执行下面执行命令会报错
cnpm install #使用cnpm命令下载安装项目所需要的插件
3.配置ElasticSearch-head
修改elasticsearch.yml
cd software/elasticsearch-7.8.1/config
vim elasticsearch.yml
修改以下内容:
http.cors.enabled: true
http.cors.allow-origin: "*" //允许跨域访问
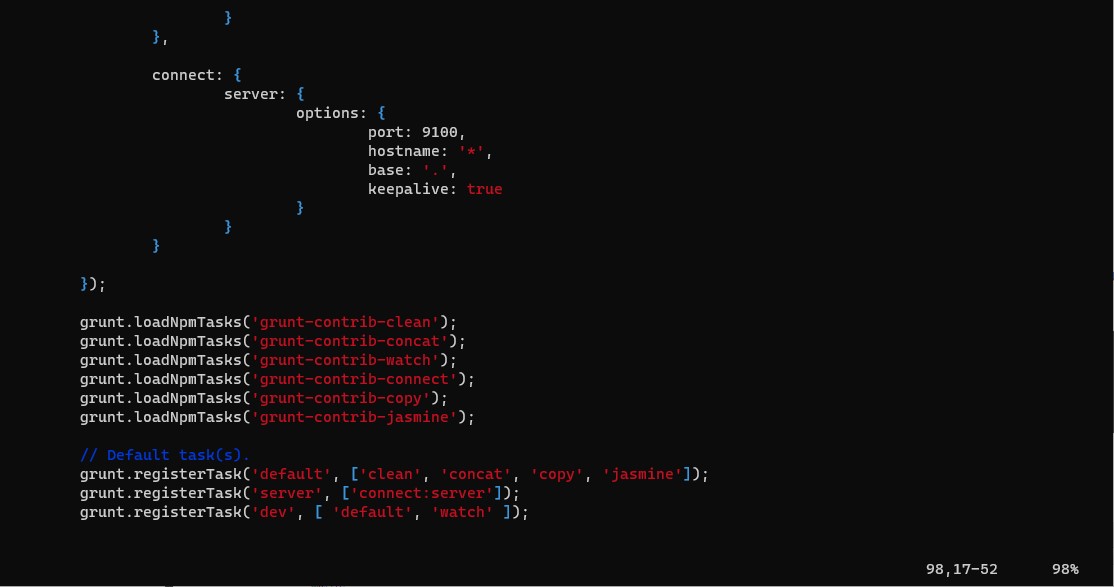
修改Gruntfile.js
cd elasticSearch-head
vim Gruntfile.js
在此添加 hostname="*"
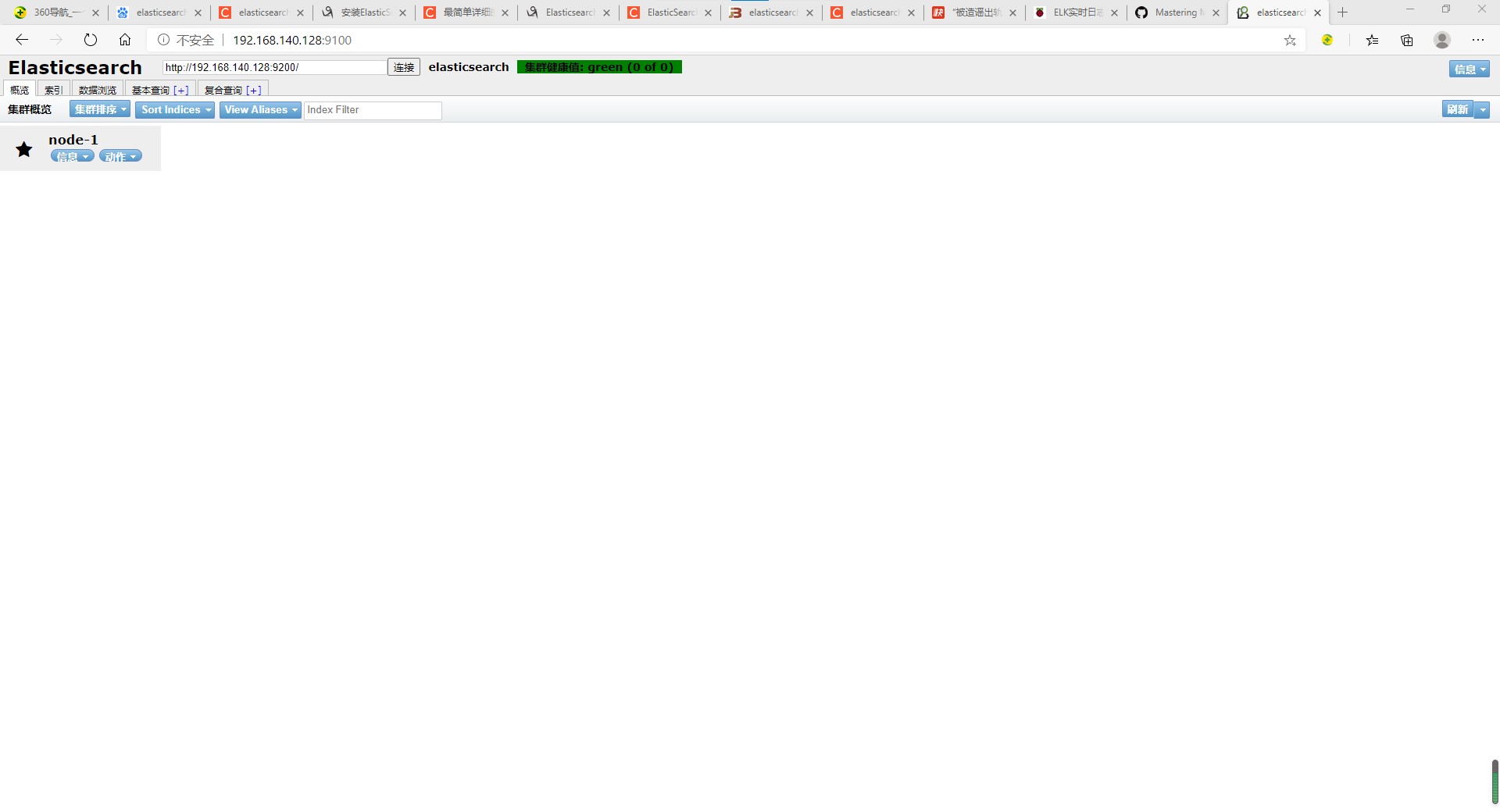
4.启动ElasticSearch-head
grunt server &

3.实验中的具体应用
在这次实验当中,我们用head插件可以很方便的查看到logsearch以及kibana所创建的索引。从而,我们能够清晰的判断出程序是否向elasticsearch中正确写入了数据。以便我们后边数据可视化的构建以及dashboard的构造。
参考
[^1] Elasticsearch官网
[^2] Elasticsearch 简介
[^3] Elastic:菜鸟上手指南
[^4] ELK可以干什么呢?
[^5] Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica
[^6] Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
[^10] ElasticSearch-head插件使用小结
[^11] ElasticSearch-head插件用法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?