第一次编程作业
第一次编程作业
作者:@baiweidou
github链接:https://github.com/baiweidou/doucang
作业要求
题目:论文查重
1. 描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
2.样例:
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
3.额外要求:
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。 从命令行参数给出:抄袭版论文的文件的绝对路径。 从命令行参数给出:输出的答案文件的绝对路径。
使用的语言和思路
第一次独立完成一个项目(作业),本以为这是我难以完成的任务,一开始连对这次作业的思路都没有,但最后磕磕绊绊还是把程序写了出来。
参考了大佬们的思路,开始去了解NLP,翻阅gensim官方文档,不断的对怎样建立模型进行探索,对代码修修改改,都让我受益良多。
主要使用的是两个库:
中文分词jieba库
gensim模型库
主要思路如下:
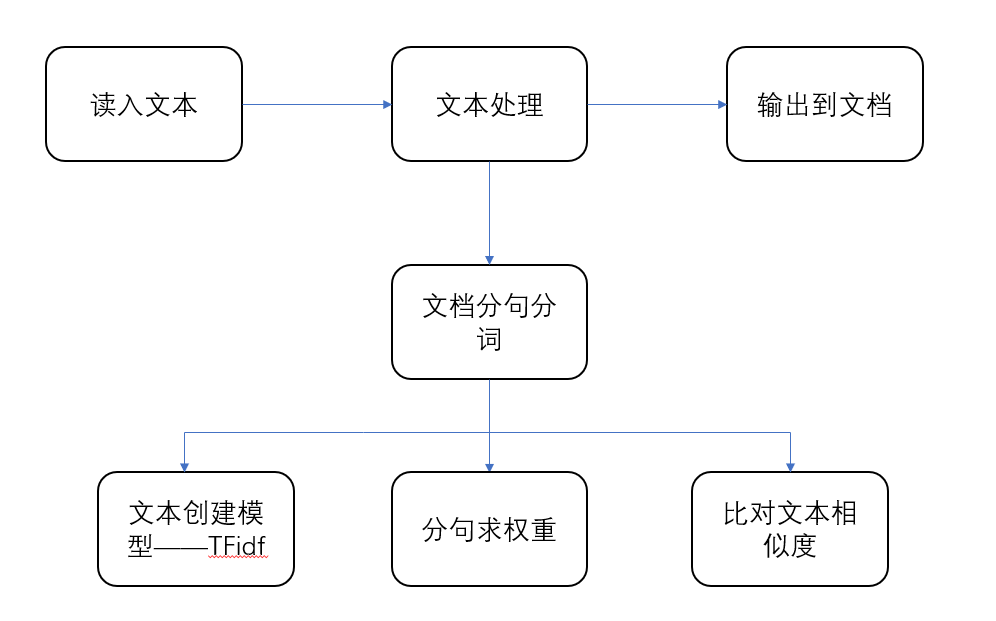
句相似度计算:每句话的权重weight*每句话在模型中的相似度sim
总相似度:句相似度之和
TF-IDF模型——一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
对文章进行分词,再将分词转换为向量,利用TF-IDF模型得到词的权重
最后通过对句子余弦值计算得到相似度
模块分析
1.文本处理模块creat_sencence
分句模块:
这里把文档中除了中文之外的符号都去掉,并且在遇到逗号时分句
def creat_sentence(file_data):
file_sentence = []
s = ''
for word in file_data:
#中文编码范围
if '\u4e00'<=word<='\u9fff':
s += word
#逗号分句
elif word == ',':
file_sentence.append(s)
s = ''
return file_sentence
分词模块:
将每句话利用jieba库分词
orig_word = [[word for word in jieba.lcut(sentence)] for sentence in orig_sentence]
2.求权重模块get_weight
将每句话占全文的权重求出
核心思想很简单,就是拿句子的长度除以全文的长度
def get_weight(file_data,file_sentence):
#权重列表
weight = []
#计算文章总字词长度
file_len = 0
#w用来留存每句话的权重
w = 0
for word in file_data:
if '\u4e00'<=word<='\u9fff':
file_len +=1
for sentence in file_sentence:
for word in sentence:
if '\u4e00' <= word <= '\u9fff':
w += 1
weight.append(w/file_len)
w = 0
return weight
3.计算相似度模块tfidf_model
def tfidf_model(orig_items,orig_sim_items):
#生成词典
dictionary = corpora.Dictionary(orig_items)
#生成稀疏向量库
corpus = [dictionary.doc2bow(text) for text in orig_items]
#利用TFidf模型建模
tf = models.TfidfModel(corpus)
#通过token2id得到特征数(字典里面的键的个数)
num_features = len(dictionary.token2id.keys())
#建立索引
index = similarities.MatrixSimilarity(tf[corpus],num_features=num_features)
#索引持久性
index.save('index.txt')
#求相似度列表
sim_value = []
for i in range(0,len(orig_sim_items)):
orig_sim_vec = dictionary.doc2bow(orig_sim_items[i])
sim = index[tf[orig_sim_vec]]
#取相似度最大的值
sim_max = max(sim)
sim_value.append(sim_max)
return sim_value
4.文档读入读出原理
通过对sys库的调用写入文档
import sys
orig_file = open(sys.argv[1],'r', encoding='UTF-8')
orig_data = orig_file.read()
orig_file.close()
文档读出:
file = open('test_ans.txt','w', encoding='UTF-8')
file.write(ans)
file.close()
单元测试结果
代码:
import unittest
import calculation
class Test(unittest.TestCase):
def test_txt_add(self):
print("orig_0.8_add.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_add.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_del(self):
print("orig_0.8_del.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_del.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_1(self):
print("orig_0.8_dis_1.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_dis_1.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_3(self):
print("orig_0.8_dis_3.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_dis_3.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_7(self):
print("orig_0.8_dis_7.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_dis_7.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_10(self):
print("orig_0.8_dis_10.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_dis_10.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_15(self):
print("orig_0.8_dis_15.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_dis_15.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_mix(self):
print("orig_0.8_mix.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_mix.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_rep(self):
print("orig_0.8_rep.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig_0.8_rep.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_ori(self):
print("orig.txt的相似度 ")
file = open("orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("orig.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
if __name__ == '__main__':
unittest.main()
运行结果
运行结果如下:
orig_0.8_add.txt查询结果:
0.83
orig_0.8_del.txt查询结果:
0.76
orig_0.8_dis_1.txt查询结果:
0.94
orig_0.8_dis_3.txt查询结果:
0.90
orig_0.8_dis_7.txt查询结果:
0.86
orig_0.8_dis_10.txt查询结果:
0.78
orig_0.8_dis_15.txt查询结果:
0.55
orig_0.8_mix.txt查询结果:
0.85
orig_0.8_rep.txt查询结果:
0.75
性能分析
使用了pycharm自带的性能分析工具profile
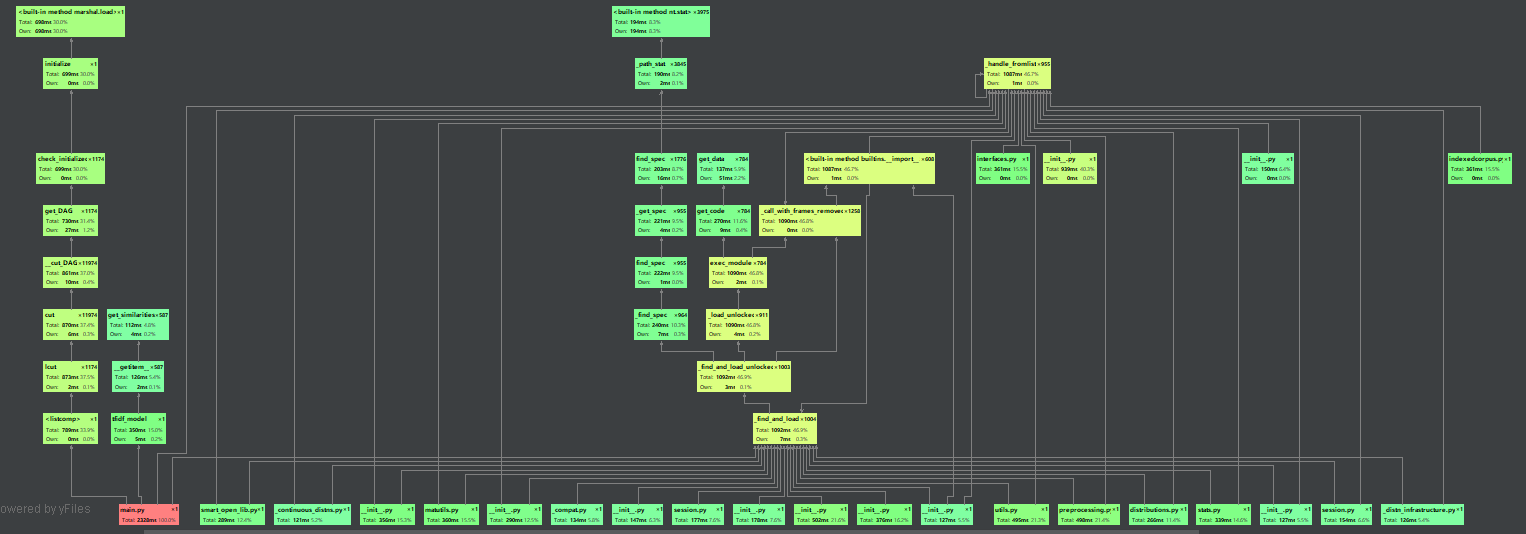
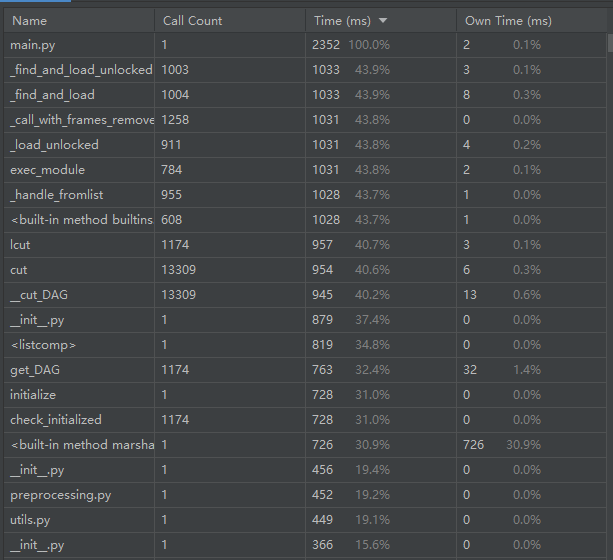
main函数的用时在2500ms左右,由于停用词去除不是用jieba分词的函数,所以会稍微快一些
文本预处理和特征向量计算模块耗费时间比较多
计算模块异常处理
写了一个空文本判断是否异常的模块,因为曾经orig文本突然变为空了,建模时出错但找不到原因,最后才发现
#空文本判断异常
if len(orig_data) == 0:
print("原始文本为空")
raise
elif len(orig_sim_data) == 0:
print("相似文本为空")
raise
p2p表格
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 1200 | 1680 |
| · Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | 750 | 1410 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 120 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | 180 |
| · Design | · 具体设计 | 120 | 180 |
| · Coding | · 具体编码 | 120 | 600 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 120 | 180 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| · 合计 | 1050 | 1680 |
收获与改进
- 一开始觉得自己不能独立完成这份作业,但到最后也磕磕绊绊的完成了程序,感谢python的便捷性,让我能够完成这次的作业,在此之后我也会更加努力的提升自己的编程水平,争取在以后的作业自己想出解题思路,也会慢慢提升自己使用git,python的能力
(加强面向github的本领) - 对于这次的程序还有很多的瑕疵,我在今后的学习过程中会不断的对此程序进行改进
附上代码
#-*-codeing = utf-8 -*-
#@Time :2020/9/15 22:25
#@Author : baiweidou
#@File : Edit distance calculation.py
#@Software :PyCharm
#第一份编程作业
import jieba
import sys
import time
from gensim import corpora,models,similarities
#文档分句,删除符号,保留中文
def creat_sentence(file_data):
file_sentence = []
s = ''
for word in file_data:
#中文编码范围
if '\u4e00'<=word<='\u9fff':
s += word
#逗号分句
elif word == ',':
file_sentence.append(s)
s = ''
return file_sentence
def tfidf_model(orig_items,orig_sim_items):
#生成词典
dictionary = corpora.Dictionary(orig_items)
#生成稀疏向量库
corpus = [dictionary.doc2bow(text) for text in orig_items]
#利用TFidf模型建模
tf = models.TfidfModel(corpus)
#通过token2id得到特征数(字典里面的键的个数)
num_features = len(dictionary.token2id.keys())
#建立索引
index = similarities.MatrixSimilarity(tf[corpus],num_features=num_features)
#索引持久性
index.save('index.txt')
#求相似度列表
sim_value = []
for i in range(0,len(orig_sim_items)):
orig_sim_vec = dictionary.doc2bow(orig_sim_items[i])
sim = index[tf[orig_sim_vec]]
#取相似度最大的值
sim_max = max(sim)
sim_value.append(sim_max)
return sim_value
#求每段话在文章中的权重
def get_weight(file_data,file_sentence):
#权重列表
weight = []
#计算文章总字词长度
file_len = 0
#w用来留存每句话的权重
w = 0
for word in file_data:
if '\u4e00'<=word<='\u9fff':
file_len +=1
for sentence in file_sentence:
for word in sentence:
if '\u4e00' <= word <= '\u9fff':
w += 1
weight.append(w/file_len)
w = 0
return weight
if __name__ == '__main__':
time_start = time.time()
#原始文档打开
orig_file = open("sys.argv[1]",'r', encoding='UTF-8')
#相似文档打开
orig_sim_file = open("sys.argv[2]",'r',encoding='utf-8')
#原始文档写入
orig_data = orig_file.read()
#相似文档写入
orig_sim_data = orig_sim_file.read()
#原始文档相似文档关闭
orig_file.close()
orig_sim_file.close()
#原始文档分句分词
orig_sentence =creat_sentence(orig_data)
orig_word = [[word for word in jieba.lcut(sentence)] for sentence in orig_sentence]
#相似文档分句分词
orig_sim_sentence = creat_sentence(orig_sim_data)
orig_sim_word = [[word for word in jieba.lcut(sentence)] for sentence in orig_sim_sentence]
#获取相似文档权重列表
weight = get_weight(orig_sim_data,orig_sim_sentence)
#获取相似文档相似度列表
sim_value = tfidf_model(orig_word,orig_sim_word)
#ans用于存放最后总相似度,为每句权重和相似度的积
ans = 0
for i in range(len(weight)):
ans += weight[i]*sim_value[i]
#保留两位数
ans = (str("%.2f") % ans)
print(ans)
#写入文件
file = open('sys.argv[3]','w', encoding='UTF-8')
file.write(ans)
file.close()
#计时
time_end = time.time()
time = time_end-time_start
print("time = ",time)
