概率图模型和半监督学习
一、似然函数
likelihood function
现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x) ),现在要确定里面的一些参数的值,使得由这些参数确定的分布函数生成的这些数据点的概率最大,这个概率即为 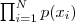 ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和
,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和 ![]() ,得到 log-likelihood function 。
,得到 log-likelihood function 。
Marginal likelihood
n statistics, a marginal likelihood function, or integrated likelihood, is a likelihood function in which some parameter variables have been marginalized. In the context of Bayesian statistics, it may also be referred to as the evidence or model evidence.
Given a set of independent identically distributed data points  where
where 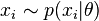 according to some probability distribution parameterized by θ, where θ itself is a random variable described by a distribution, i.e.
according to some probability distribution parameterized by θ, where θ itself is a random variable described by a distribution, i.e.  the marginal likelihood in general asks what the probability
the marginal likelihood in general asks what the probability  is, where θ has been marginalized out (integrated out):
is, where θ has been marginalized out (integrated out):

- 参考:https://en.wikipedia.org/wiki/Marginal_likelihood
二、半监督学习
传统的机器学习技术分为两类,一类是无监督学习,一类是监督学习。
无监督学习只利用未标记的样本集,而监督学习则只利用标记的样本集进行学习。
但在很多实际问题中,只有少量的带有标记的数据,因为对数据进行标记的代价有时很高,比如在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的未标记的数据却很容易得到。
这就促使能同时利用标记样本和未标记样本的半监督学习技术迅速发展起来。
半监督学习理论简述
半监督学习有两个样本集,一个有标记,一个没有标记.分别记作
Lable={(xi,yi)},Unlabled={(xi)}.并且数量上,L<<U.
1. 单独使用有标记样本,我们能够生成有监督分类算法
2. 单独使用无标记样本,我们能够生成无监督聚类算法
3. 两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果.
一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类.也就是在1中加入无标记样本,增强分类效果.
参考:
http://blog.csdn.net/yhdzw/article/details/22733371
三、概率图模型
probability graphcial model
bayesican network and markov random filed
概率图模型主要包括贝叶斯网络和马尔科夫随机场
两者的区别在于贝叶斯网络是有向的,马尔科夫随机场是无向的
MRF CRF 条件随机场 clique 完全连通图
CRF(Conditional random fields),是一种判别式图模型,因为其强大的表达能力和出色的性能,得到了广泛的应用。从最通用角度来看,CRF本质上是给定了观察值集合(observations)的马尔可夫随机场。在这里,我们直接从最通用的角度来认识和理解CRF,最后可以看到,线性CRF和所谓的高阶CRF,都是某种特定结构的CRF。
1. 随机场
简单地讲,随机场可以看成是一组随机变量的集合(这组随机变量对应同一个样本空间)。当然,这些随机变量之间可能有依赖关系,一般来说,也只有当这些变量之间有依赖关系的时候,我们将其单独拿出来看成一个随机场才有实际意义。
2. Markov随机场(MRF)
这是加了Markov性质限制的随机场。首先,一个Markov随机场对应一个无向图。这个无向图上的每一个节点对应一个随机变量,节点之间的边表示节点对应的随机变量之间有概率依赖关系。因此,Markov随机场的结构本质上反应了我们的先验知识——哪些变量之间有依赖关系需要考虑,而哪些可以忽略。Markov性质是指,对Markov随机场中的任何一个随机变量,给定场中其他所有变量下该变量的分布,等同于给定场中该变量的邻居节点下该变量的分布。这让人立刻联想到马式链的定义:它们都体现了一个思想:离当前因素比较遥远(这个遥远要根据具体情况自己定义)的因素对当前因素的性质影响不大。
Markov性质可以看作是Markov随机场的微观属性,那么其宏观属性就是其联合概率的形式。
假设MRF的变量集合为S={y1,...yn}, P(y1,...yn)= 1/Z * exp{-1/T * U(y1,..yn)},其中Z是归一化因子,即对分子的所有y1,..yn求和得到。U(y1,..yn)一般称为energy function, 定义为在MRF上所有clique-potential之和。T称为温度,一般取1。什么是click-potential呢? 就是在MRF对应的图中,每一个clique对应一个函数,称为clique-potential。这个联合概率形式又叫做Gibbs distribution。Hammersleyand Clifford定理表达了这两种属性的等价性。
如果click-potential的定义和clique在图中所处的位置无关,则称该MRF是homogeneous;如果click-potential的定义和clique在图中的朝向(orientation)无关,则称该MRF是isotropic的。一般来说,为了简化计算,都是假定MRF即是homogeneous也是iostropic的。
3.从Markov随机场到CRF
现在,如果给定的MRF中每个随机变量下面还有观察值,我们要确定的是给定观察集合下,这个MRF的分布,也就是条件分布,那么这个MRF就称为CRF(Conditional Random Field)。它的条件分布形式完全类似于MRF的分布形式,只不过多了一个观察集合x,即P(y1,..yn|x) = 1/Z(x) * exp{ -1/T * U(y1,...yn,x)。U(y1,..yn,X)仍旧是click-potential之和。
4.训练
通过一组样本,我们希望能够得到CRF对应的分布形式,并且用这种分布形式对测试样本进行分类。也就是测试样本中每个随机变量的取值。
在实际应用中,clique-potential主要由用户自己定义的特征函数组成,即用户自己定义一组函数,这些函数被认为是可以用来帮助描述随机变量分布的。而这些特征函数的强弱以及正向、负向是通过训练得到的一组权重来表达的,这样,实际应用中我们需要给出特征函数以及权重的共享关系(不同的特征函数可能共享同一个权重),而clicque-potential本质上成了对应特征函数的线性组合。这些权重就成了CRF的参数。因此,本质上,图的结构是用户通过给出特征函数的定义确定的(例如,
只有一维特征函数,对应的图上是没有边的)还有,CRF的分布成了对数线性形式。
看到这个分布形式,我们自然会想到用最大似然准则来进行训练。对其取log之后,会发现,表达式是convex的,也就是具有全局最优解——这是很让人振奋的事情。而且,其梯度具有解析解,这样可以用LBFGS来求解极值。
参考wiki
https://en.wikipedia.org/wiki/Graphical_model
http://blog.sina.com.cn/s/blog_461db08c0101jv5j.html
四、EM算法总结
Given a statistical model which generates a set 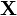 of observed data, a set of unobserved latent data or missing values
of observed data, a set of unobserved latent data or missing values  , and a vector of unknown parameters
, and a vector of unknown parameters 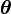 , along with a likelihood function
, along with a likelihood function  , the maximum likelihood estimate (MLE) of the unknown parameters is determined by the marginal likelihood of the observed data
, the maximum likelihood estimate (MLE) of the unknown parameters is determined by the marginal likelihood of the observed data
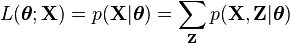
However, this quantity is often intractable (e.g. if is a sequence of events, so that the number of values grows exponentially with the sequence length, making the exact calculation of the sum extremely difficult).
The EM algorithm seeks to find the MLE of the marginal likelihood by iteratively applying the following two steps:
- Expectation step (E step): Calculate the expected value of the log likelihood function, with respect to the conditional distribution of given under the current estimate of the parameters
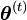 :
:
![Q(\boldsymbol\theta|\boldsymbol\theta^{(t)}) = \operatorname{E}_{\mathbf{Z}|\mathbf{X},\boldsymbol\theta^{(t)}}\left[ \log L (\boldsymbol\theta;\mathbf{X},\mathbf{Z}) \right] \,](https://upload.wikimedia.org/math/c/6/8/c685c42d963edd857fb2103a437b81c8.png)
- Maximization step (M step): Find the parameter that maximizes this quantity:
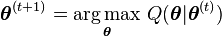
五、GMM算法
EM算法在高斯混合模型聚类中得应用,每一类即为一个高斯分布
高斯分布(正态分布)
GMM的EM算法实现
http://blog.csdn.net/abcjennifer/article/details/8198352

 浙公网安备 33010602011771号
浙公网安备 33010602011771号